기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
클러스터 용량 조정
작업이 너무 오래 걸리지만 실행기가 충분한 리소스를 소비하고 Spark가 사용 가능한 코어에 비해 대량의 작업을 생성하고 있는 경우 클러스터 용량 조정을 고려하세요. 이것이 적절한지 평가하려면 다음 지표를 사용합니다.
CloudWatch 지표
-
CPU Load 및 Memory Utilization을 확인하여 실행기가 충분한 리소스를 사용하고 있는지 확인합니다.
-
작업 실행 시간을 확인하여 처리 시간이 성능 목표를 달성하기에 너무 긴지 평가합니다.
다음 예제에서는 4개의 실행기가 97% 이상의 CPU 로드에서 실행되고 있지만 약 3시간 후에도 처리가 완료되지 않았습니다.
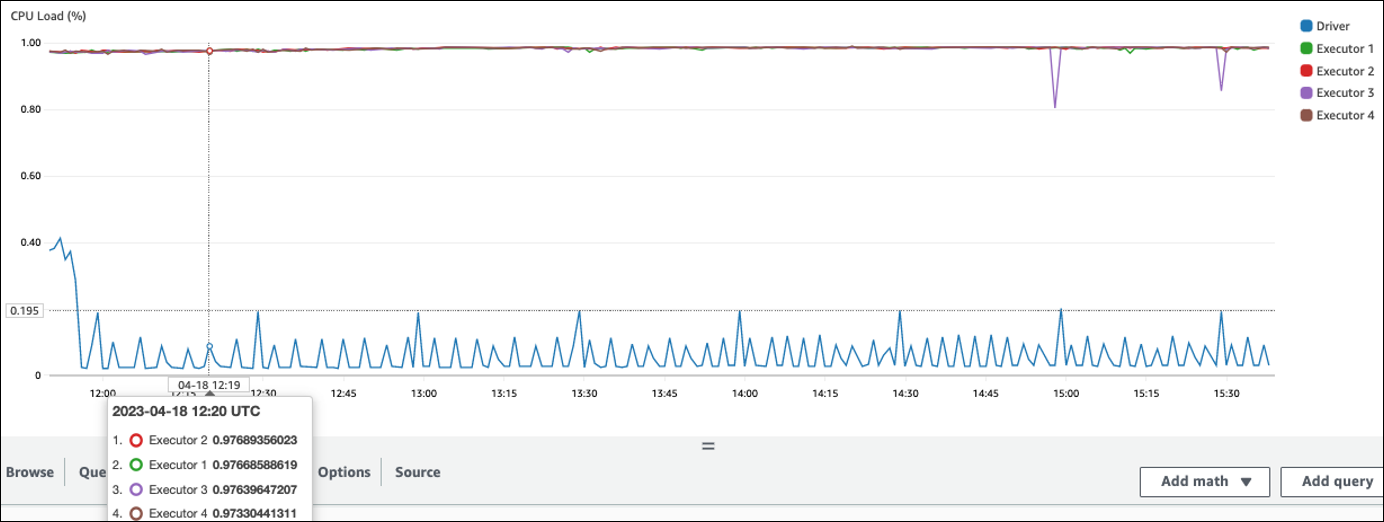
참고
CPU 부하가 낮으면 클러스터 용량 조정의 이점이 없을 것입니다.
Spark UI
작업 탭 또는 단계 탭에서 각 작업 또는 단계의 작업 수를 볼 수 있습니다. 다음 예제에서는 Spark가 58100 태스크를 생성했습니다.

실행기 탭에서 총 실행기 및 작업 수를 볼 수 있습니다. 다음 스크린샷에서는 각 Spark 실행기에 4개의 코어가 있으며 4개의 작업을 동시에 수행할 수 있습니다.
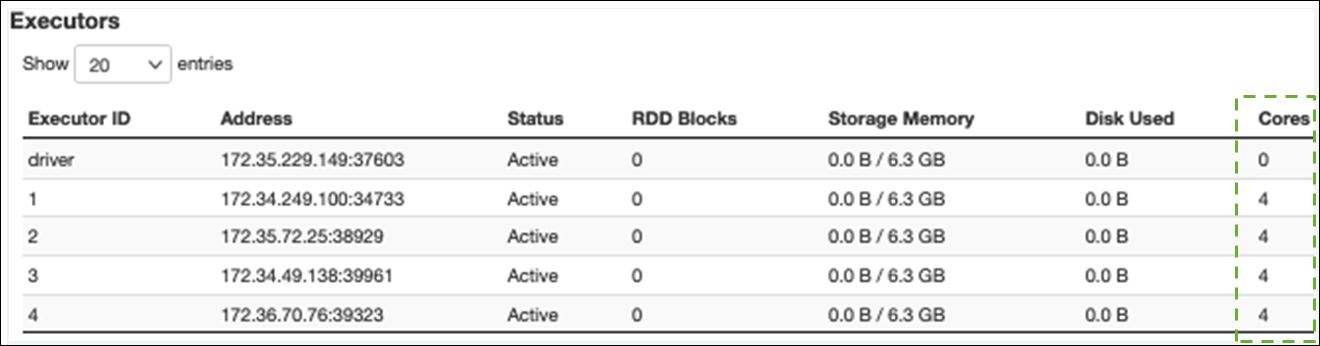
이 예제에서는 Spark 작업 수(58100)는 실행기가 동시에 처리할 수 있는 16개의 작업(4개의 실행기 × 4개의 코어)보다 훨씬 큽니다.
이러한 증상이 관찰되면 클러스터 크기 조정을 고려하세요. 다음 옵션을 사용하여 클러스터 용량을 확장할 수 있습니다.
-
Enable AWS Glue Auto Scaling - Auto Scaling은 AWS Glue 버전 3.0 이상의 AWS Glue 추출, 변환, 로드(ETL) 및 스트리밍 작업에 사용할 수 있습니다.는 각 단계의 파티션 수 또는 작업 실행 시 마이크로배치가 생성되는 속도에 따라 클러스터에서 작업자를 AWS Glue 자동으로 추가하고 제거합니다.
Auto Scaling이 활성화되어 있더라도 작업자 수가 증가하지 않는 상황이 관찰되면 작업자를 수동으로 추가하는 것이 좋습니다. 그러나 한 단계에 대해 수동으로 조정하면 후기 단계에서 많은 작업자가 유휴 상태가 될 수 있으므로 성능 향상이 0이 되면 비용이 더 많이 들 수 있습니다.
Auto Scaling을 활성화하면 CloudWatch 실행기 지표에서 실행기 수를 볼 수 있습니다. 다음 지표를 사용하여 Spark 애플리케이션의 실행기 수요를 모니터링합니다.
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
지표에 대한 자세한 내용은 Amazon CloudWatch 지표 AWS Glue 를 사용한 모니터링을 참조하세요.
-
-
스케일 아웃: 작업자 수 AWS Glue 증가 - 작업자 수 AWS Glue 를 수동으로 늘릴 수 있습니다. 유휴 작업자를 관찰할 때까지만 작업자를 추가합니다. 이때 작업자를 더 추가하면 결과를 개선하지 않고도 비용이 증가합니다. 자세한 내용은 작업 병렬화를 참조하세요.
-
스케일 업: 더 큰 작업자 유형 사용 - 코어, 메모리 및 스토리지가 더 많은 작업자를 사용하도록 AWS Glue 작업자의 인스턴스 유형을 수동으로 변경할 수 있습니다. 작업자 유형이 클수록 메모리 집약적인 데이터 변환, 왜곡된 집계, 페타바이트의 데이터와 관련된 개체 감지 확인과 같은 집약적인 데이터 통합 작업을 수직적으로 확장하고 실행할 수 있습니다.
스케일 업은 작업 쿼리 계획이 상당히 크기 때문에 Spark 드라이버에 더 큰 용량이 필요한 경우에도 도움이 됩니다. 작업자 유형 및 성능에 대한 자세한 내용은 AWS 빅 데이터 블로그 게시물 새로운 대형 작업자 유형 G.4X 및 G.8X로 Apache Spark 작업 AWS Glue 용 스케일 조정을 참조하세요
. 또한 더 큰 작업자를 사용하면 필요한 총 작업자 수를 줄일 수 있으므로 조인과 같은 집약적인 작업에서 셔플을 줄여 성능이 향상됩니다.
