기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon QuickSight에서의 평가 순서
분석을 열거나 업데이트하면 Amazon QuickSight는 분석을 표시하기 전에 분석에서 구성되는 모든 것을 특정 순서로 평가합니다. Amazon QuickSight는 구성을 데이터베이스 엔진이 실행할 수 있는 쿼리로 변환합니다. 쿼리는 데이터베이스, 서비스형 소프트웨어(SaaS) 소스, Amazon QuickSight 분석 엔진(SPICE) 중 무엇에 연결하든 상관없이 비슷한 방식으로 데이터를 반환합니다.
구성이 평가되는 순서를 이해하면 특정 필터 또는 계산이 데이터에 언제 적용되는지를 결정하는 순서를 알 수 있습니다.
다음 그림은 평가 순서를 보여줍니다. 왼쪽 열에는 레벨 인식 계산 창(LAC-W)이나 집계(LAC-A) 함수가 포함되지 않은 경우의 평가 순서가 표시됩니다. 두 번째 열에는 사전 필터(PRE_FILTER) 수준에서 LAC-W 표현식을 컴퓨팅 할 계산된 필드가 포함된 분석에 대한 평가 순서가 표시됩니다. 세 번째 열에는 사전 집계(PRE_AGG) 수준에서 LAC-W 표현식을 컴퓨팅 할 계산된 필드가 포함된 분석에 대한 평가 순서가 표시됩니다. 마지막 열에는 LAC-A 표현식을 컴퓨팅 할 계산된 필드가 포함된 분석에 대한 평가 순서가 표시됩니다. 그림 다음에는 평가 순서에 대한 더 자세한 설명이 있습니다. 레벨 인식 계산에 대한 자세한 내용은 Amazon QuickSight에서 레벨 인식 계산 사용을(를) 참조하십시오.
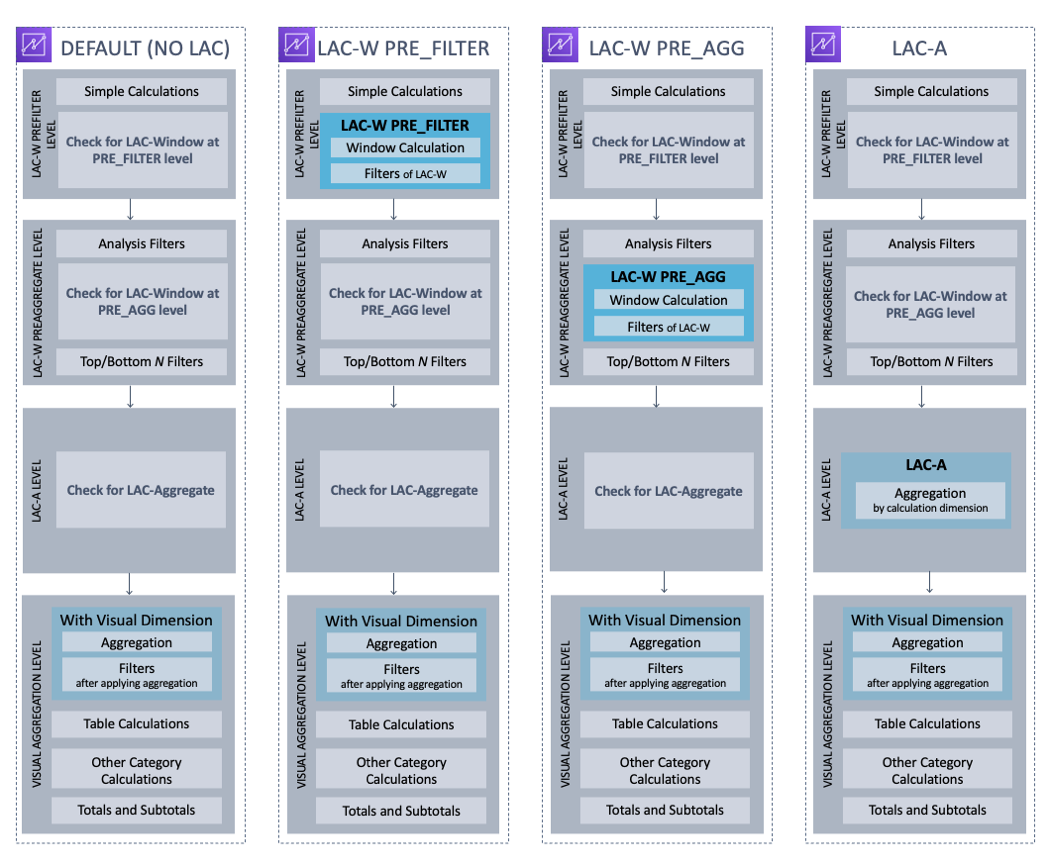
다음 목록은 Amazon QuickSight가 분석에서 구성을 적용하는 순서를 보여줍니다. 데이터 세트에서 설정하는 모든 항목(예: 데이터 세트 수준의 계산, 필터 및 보안 설정)은 분석 외부에서 수행됩니다. 이러한 항목은 모두 기본 데이터에 적용됩니다. 다음 목록은 분석 내부에서 수행되는 항목만 다룹니다.
-
LAC-W 사전 필터 수준: 분석 필터 이전에 원래 테이블 카디널리티에서 데이터를 평가합니다.
-
단순 계산: 집계 또는 창 계산 없이 스칼라 수준에서 계산합니다. 예:
date_metric/60, parseDate(date, 'yyyy/MM/dd'), ifelse(metric > 0, metric, 0), split(string_column, '|' 0). -
LAC-W 함수 PRE_FILTER: 시각화에 LAC-W PRE_FILTER 표현식이 포함된 경우 Amazon QuickSight는 필터보다 먼저 원래 테이블 수준에서 창 함수를 계산합니다. LAC-W PRE_FILTER 표현식을 필터에 사용하는 경우 이 시점에서 적용됩니다. 예:
maxOver(Population, [State, County], PRE_FILTER) > 1000.
-
-
LAC-W PRE_AGG: 집계 전에 원래 테이블 카디널리티에서 데이터를 평가합니다.
-
분석 중에 추가된 필터: 시각 자료의 집계되지 않은 필드에 대해 생성된 필터는 이 시점에서 적용되며, 이는 WHERE 절과 유사합니다. 예:
year > 2020. -
LAC-W 함수 PRE_AGG: 시각화에 LAC-W PRE_AGG 표현식이 포함된 경우 Amazon QuickSight는 집계를 적용하기 전에 창 함수를 계산합니다. LAC-W PRE_AGG 표현식을 필터에 사용하는 경우 이 시점에서 적용됩니다. 예:
maxOver(Population, [State, County], PRE_AGG) > 1000. -
상위/하위 N 필터: 상위/하위 N개 항목을 표시하도록 차원에 구성된 필터입니다.
-
-
LAC-A 수준: 시각적 집계 전에 사용자 지정 수준에서 집계를 평가합니다.
-
사용자 지정 수준 집계: 시각적 객체에 포함된 LAC-A 표현식이 있는 경우 이 시점에서 계산됩니다. Amazon QuickSight는 위에서 언급한 필터 뒤에 있는 표를 기반으로 계산된 필드에 지정된 차원별로 그룹화하여 집계를 계산합니다. 예:
max(Sales, [Region]).
-
-
시각적 객체 수준: 시각적 객체 수준에서 집계를 평가하고 나머지 구성을 시각적 객체에 적용하여 집계 후 테이블 계산을 평가합니다.
-
시각적 객체 수준 집계: 테이블 형식 테이블(차원이 비어 있는 경우)을 제외하고는 항상 시각적 객체의 집계를 적용해야 합니다. 이 설정을 사용하면 필드 모음의 필드를 기반으로 한 집계가 시각적 객체에 포함된 차원별로 그룹화되어 계산됩니다. 집계를 기반으로 하는 필터가 있으면 HAVING 절과 마찬가지로 이 시점에서 필터가 적용됩니다. 예:
min(distance) > 100. -
테이블 계산: 시각에서 참조되는 집계 후 테이블 계산(집계 표현식을 피연산자로 사용해야 함)이 있는 경우 이 시점에서 계산됩니다. Amazon QuickSight는 시각적 집계 후 윈도우 계산을 수행합니다. 마찬가지로 이러한 계산을 기반으로 구축된 필터가 적용됩니다.
-
기타 카테고리 계산: 이 유형의 계산은 선형/막대/파이/도넛형 차트에서만 사용할 수 있습니다. 자세한 내용은 표시 제한 단원을 참조하십시오.
-
총계 및 소계: 총계 및 소계는 요청 시 도넛형 차트(총계만), 테이블(총계만) 및 피벗 테이블로 계산됩니다.
-
