Amazon Redshift는 패치 198부터 새 Python UDF 생성을 더 이상 지원하지 않습니다. 기존 Python UDF는 2026년 6월 30일까지 계속 작동합니다. 자세한 내용은 블로그 게시물
SVL_QUERY_REPORT 뷰 사용
SVL_QUERY_REPORT를 사용한 조각의 쿼리 요약 정보를 분석하려면 다음과 같이 수행합니다.
-
다음과 같이 실행하여 쿼리 ID를 확인합니다.
select query, elapsed, substring from svl_qlog order by query desc limit 5;substring필드에서 잘려있는 쿼리 텍스트를 검사하여 쿼리를 표현할query값을 결정합니다. 쿼리를 한 번 넘게 실행한 경우에는query값이 더 낮은 행의elapsed값을 사용하세요. 이 행이 컴파일 버전의 행입니다. 다수의 쿼리를 실행한 경우 쿼리의 포함 여부를 확인하는 데 사용하는 LIMIT 절에서 사용되는 값을 높일 수도 있습니다. -
SVL_QUERY_REPORT에서 쿼리에 사용할 행을 선택합니다. 결과 순서는 segment, step, elapsed_time 및 rows의 순으로 정하세요.
select * from svl_query_report where query = MyQueryID order by segment, step, elapsed_time, rows; -
각 단계마다 모든 조각이 대략적으로 동일한 수의 행을 처리하는지 확인합니다.
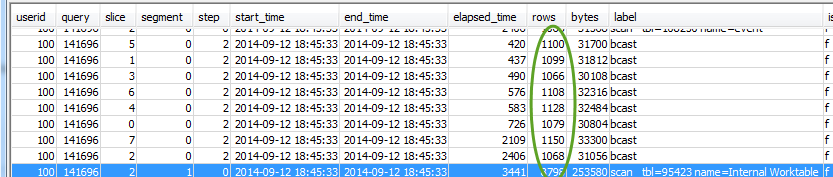
또한 모든 조각에서 대략적으로 동일한 시간이 걸리는지도 확인합니다.
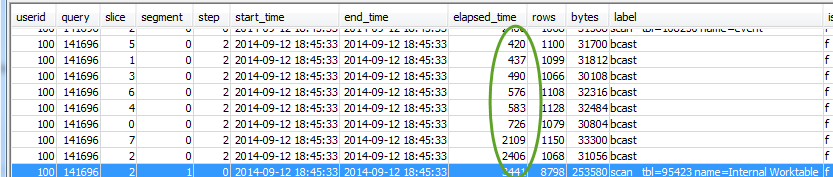
두 값의 차이가 클 경우에는 위의 특정 쿼리에 최적화되지 않은 분산 스타일로 인한 데이터 분산 스큐를 나타낼 수 있습니다. 권장 솔루션은 최적이 아닌 데이터 분산 섹션을 참조하세요.
