기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
분석 결과
SageMaker Clarify 처리 작업이 완료되면 출력 파일을 다운로드하여 검사하거나 SageMaker Studio Classic에서 결과를 시각화할 수 있습니다. 다음 주제에서는 편향 분석, 분석, SHAP 컴퓨터 비전 설명 가능성 분석 및 부분 종속성 플롯(PDPs) 분석으로 생성된 스키마 및 보고서와 같이 SageMaker Clarify가 생성하는 분석 결과를 설명합니다. 구성 분석에 여러 분석을 계산하기 위한 매개변수가 포함된 경우, 해당 결과는 하나의 분석 파일과 하나의 보고서 파일로 집계됩니다.
SageMaker Clarify 처리 작업 출력 디렉터리에는 다음 파일이 포함되어 있습니다.
-
analysis.json- 편향 지표와 특성 중요도를 JSON 형식으로 포함하는 파일입니다. -
report.ipynb- 편향 지표와 특징 중요도를 시각화할 수 있도록 해주는 코드가 포함된 정적 노트북입니다. -
explanations_shap/out.csv- 특정 분석 구성을 기반으로 만들어진 디렉터리로, 해당 구성에 따라 자동 생성되는 파일이 포함되어 있습니다. 예를 들어save_local_shap_values파라미터를 활성화하면 인스턴스당 로컬 SHAP 값이explanations_shap디렉터리에 저장됩니다. 또 다른 예로, 에 SHAP 기준 파라미터에 대한 값이 포함되어 있지analysis configuration않은 경우 SageMaker Clarify 설명 가능성 작업은 입력 데이터 세트를 클러스터링하여 기준을 계산합니다. 그런 다음에는 생성된 기준을 디렉터리에 저장합니다.
자세한 내용은 다음 섹션을 참조하세요.
편향 분석
Amazon SageMaker Clarify는 에 설명된 용어편향 및 공정성에 대한 Amazon SageMaker Clarify 용어를 사용하여 편향과 공정성을 논의합니다.
분석 파일의 스키마
분석 파일은 JSON 형식이며 훈련 전 편향 지표와 훈련 후 편향 지표의 두 섹션으로 구성됩니다. 훈련 전 및 훈련 후 편향 지표를 위한 매개변수는 다음과 같습니다.
-
pre_training_bias_metrics - 훈련 전 편향 지표을 위한 매개변수입니다. 자세한 정보는 훈련 전 편향 지표및 분석 구성 파일섹션을 참조하세요.
-
label - 분석 구성의
label매개변수에 의해 정의된 실측 레이블의 이름입니다. -
label_value_or_threshold - 분석 구성의
label_values_or_threshold매개변수에 의해 정의된 레이블 값 또는 간격을 포함하고 있는 문자열입니다. 예를 들어, 바이너리 분류 문제에 값1이 제공되었다면 해당 문자열은1이 됩니다. 만약 멀티클래스 문제에[1,2]처럼 여러 값이 제공되었다면 해당 문자열은1,2가 됩니다. 만약 회귀 문제에 임계값40이 제공되었다면 해당 문자열은(40, 68]과 같은 내부 문자열이 됩니다.여기서68은 해당 입력 데이터 세트에 포함된 레이블의 최대값입니다. -
facets - 해당 섹션에는 여러 개의 키-값 쌍이 포함되어 있습니다.여기서 키는 패싯 구성의
name_or_index매개변수에 의해 정의된 패싯의 이름에 해당하고, 값은 패싯 객체의 배열에 해당합니다. 각각의 객체에는 다음 멤버가 있습니다.-
value_or_threshold - 패싯 구성의
value_or_threshold매개변수에 의해 정의된 패싯 값 또는 간격을 포함하고 있는 문자열입니다. -
metrics - 해당 섹션에는 편향 지표 요소의 배열이 포함되어 있으며, 각각의 편향 지표 요소에는 다음과 같은 속성이 포함됩니다.
-
name - 편향 지표의 약식 이름입니다. 예:
CI. -
description - 편향 지표의 전체 이름입니다. 예:
Class Imbalance (CI). -
값 - 특정 이유로 바이어스 지표가 계산되지 않은 경우 바이어스 지표 값 또는 JSON null 값입니다. ±∞ 값은 각각 문자열
∞과-∞의 형태로 표시됩니다. -
error - 편향 지표가 계산되지 않은 이유를 설명하는 선택적 오류 메시지입니다.
-
-
-
-
post_training_bias_metrics - 해당 섹션에는 훈련 후 편향 지표가 포함되어 있으며, 이는 훈련 전 섹션과 유사한 레이아웃 및 구조를 따릅니다. 자세한 내용은 훈련 후 데이터 및 모델 편향 지표섹션을 참조하세요.
다음은 훈련 전 편향 지표와 훈련 후 편향 지표를 모두 계산하게 되는 분석 구성의 예제입니다.
{ "version": "1.0", "pre_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "CDDL", "description": "Conditional Demographic Disparity in Labels (CDDL)", "value": -0.06 }, { "name": "CI", "description": "Class Imbalance (CI)", "value": 0.6 }, ... ] }] } }, "post_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "AD", "description": "Accuracy Difference (AD)", "value": -0.13 }, { "name": "CDDPL", "description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)", "value": 0.04 }, ... ] }] } } }
편향 분석 보고서
편향 분석 보고서에는 자세한 설명과 서술이 기재된 여러 테이블과 다이어그램이 포함되어 있습니다. 여기에는 레이블 값의 분포, 패싯 값의 분포, 상위 수준 모델 성능 다이어그램, 편향 지표 테이블 및 관련 설명이 포함되지만, 이에 국한되지는 않습니다. 편향 지표와 이를 해석하는 방법에 대한 자세한 내용은 Amazon SageMaker Clarify가 편향을 감지하는 데 도움이 되는 방법 알아보기 섹션을
SHAP 분석
SageMaker 처리 작업은 커널 SHAP 알고리즘을 사용하여 특성 속성을 계산합니다. SageMaker Clarify 처리 작업은 로컬 및 전역 SHAP 값을 모두 생성합니다. 이는 모델 예측에 대한 각 특징의 기여도를 결정하는 데 도움이 됩니다. 로컬 SHAP 값은 각 개별 인스턴스의 기능 중요도를 나타내는 반면, 전역 SHAP 값은 데이터 세트의 모든 인스턴스에서 로컬 SHAP 값을 집계합니다. SHAP 값 및 해석 방법에 대한 자세한 내용은 섹션을 참조하세요Shapley 값을 사용하는 기능 특성.
SHAP 분석 파일의 스키마
글로벌 SHAP 분석 결과는 분석 파일의 설명 섹션에 kernel_shap 메서드 아래에 저장됩니다. SHAP 분석 파일의 다양한 파라미터는 다음과 같습니다.
-
explanations - 특징 중요도 분석 결과를 포함하고 있는 분석 파일의 섹션입니다.
-
kernal_shap - 글로벌 분석 결과가 포함된 SHAP 분석 파일의 섹션입니다.
-
global_shap_values - 여러 키-값 쌍을 포함하고 있는 분석 파일의 섹션입니다. 키-값 쌍의 개별 키는 입력 데이터 세트에서의 특징 이름을 나타냅니다. 키-값 페어의 각 값은 기능의 전역 SHAP 값에 해당합니다. 전역 SHAP 값은
agg_method구성을 사용하여 기능의 인스턴스당 SHAP 값을 집계하여 가져옵니다. 만약use_logit구성이 활성화되었다면, 해당 값의 계산은 로그-승산비로 해석될 수 있는 로지스틱 회귀 계수를 사용하여 수행됩니다. -
expected_value - 기준 데이터 세트의 평균 예측값입니다. 만약
use_logit구성이 활성화되었다면, 해당 값의 계산은 로지스틱 회귀 계수를 사용하여 수행됩니다. -
global_top_shap_text – NLP 설명 가능성 분석에 사용됩니다. 키-값 페어 세트를 포함하는 분석 파일의 섹션입니다. 처리 작업을 SageMaker 명확히 하면 각 토큰의 SHAP 값을 집계한 다음 전역 SHAP 값을 기반으로 최상위 토큰을 선택합니다.
max_top_tokens구성은 선택되는 토큰의 수를 정의합니다.선택된 각각의 상위 토큰에는 키-값 쌍이 있습니다. 키-값 쌍에 포함된 키는 상위 토큰의 텍스트 특징 이름에 해당합니다. 키-값 페어의 각 값은 최상위 토큰의 전역 SHAP 값입니다.
global_top_shap_text키-값 페어의 예는 다음 출력을 참조하세요.
-
-
다음 예제는 테이블 형식의 데이터 세트 SHAP 분석의 출력을 보여줍니다.
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Age": 0.022486410860333206, "Gender": 0.007381025261958729, "Income": 0.006843906804137847, "Occupation": 0.006843906804137847, ... }, "expected_value": 0.508233428001 } } } }
다음 예제는 텍스트 데이터 세트 SHAP 분석의 출력을 보여줍니다. Comments 열에 해당하는 출력은 텍스트 특징을 분석한 후 생성된 출력의 예시입니다.
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Rating": 0.022486410860333206, "Comments": 0.058612104851485144, ... }, "expected_value": 0.46700941970297033, "global_top_shap_text": { "charming": 0.04127962903247833, "brilliant": 0.02450240786522321, "enjoyable": 0.024093569652715457, ... } } } } }
생성된 기준 파일의 스키마
SHAP 기준 구성이 제공되지 않으면 SageMaker Clarify 처리 작업은 기준 데이터 세트를 생성합니다. SageMaker Clarify는 거리 기반 클러스터링 알고리즘을 사용하여 입력 데이터 세트에서 생성된 클러스터에서 기준 데이터 세트를 생성합니다. 결과 기준 데이터 세트는 에 있는 CSV 파일에 저장됩니다explanations_shap/baseline.csv. 이 출력 파일에는 헤더 행 그리고 해당 분석 구성에서 지정된 num_clusters매개변수에 기반하는 여러 인스턴스가 포함되어 있습니다. 기준 데이터 세트는 특징 열로만 구성됩니다. 다음 예제는 입력 데이터 세트를 클러스터링하여 생성된 기준을 보여줍니다.
Age,Gender,Income,Occupation 35,0,2883,1 40,1,6178,2 42,0,4621,0
표 형식 데이터 세트 설명 가능성 분석의 로컬 SHAP 값에 대한 스키마
표 형식 데이터 세트의 경우 단일 컴퓨팅 인스턴스를 사용하는 경우 SageMaker Clarify 처리 작업은 로컬 SHAP 값을 라는 CSV 파일에 저장합니다explanations_shap/out.csv. 여러 컴퓨팅 인스턴스를 사용하는 경우 explanations_shap 디렉터리의 여러 CSV 파일에 로컬 SHAP 값이 저장됩니다.
로컬 SHAP 값이 포함된 출력 파일에는 헤더로 정의된 각 열의 로컬 SHAP 값이 포함된 행이 있습니다. 이 헤더는 특징 이름에 밑줄이 추가되고 그 뒤에 목표 변수 이름이 추가되는 형태인 Feature_Label의 명명 규칙을 따르게 됩니다.
멀티클래스 문제인 경우, 헤더에 있는 특징의 이름이 먼저 바뀌고 레이블 이름은 그 다음에 바뀝니다. 예를 들어 헤더에 2개의 특징(F1, F2)과 2개의 클래스(L1, L2)가 있는 경우, 이는 F1_L1, F2_L1, F1_L2, F2_L2가 됩니다. 분석 구성에 joinsource_name_or_index매개변수 값이 포함된 경우, 해당 조인에 사용된 키 열이 헤더 이름의 끝에 추가됩니다. 이렇게 하면 로컬 SHAP 값을 입력 데이터 세트의 인스턴스에 매핑할 수 있습니다. SHAP 값이 포함된 출력 파일의 예는 다음과 같습니다.
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
NLP 설명 가능성 분석의 로컬 SHAP 값 스키마
NLP 설명 가능성 분석을 위해 단일 컴퓨팅 인스턴스를 사용하는 경우 SageMaker Clarify 처리 작업은 로컬 SHAP 값을 라는 JSON 행 파일에 저장합니다explanations_shap/out.jsonl. 여러 컴퓨팅 인스턴스를 사용하는 경우 로컬 SHAP 값은 explanations_shap 디렉터리의 여러 JSON 행 파일에 저장됩니다.
로컬 SHAP 값을 포함하는 각 파일에는 여러 데이터 줄이 있으며 각 줄은 유효한 JSON 객체입니다. JSON 객체에는 다음과 같은 속성이 있습니다.
-
설명 - 단일 인스턴스에 대한 커널 SHAP 설명 배열이 포함된 분석 파일의 섹션입니다. 배열의 각 요소에는 다음과 같은 멤버가 있습니다.
-
feature_name - 헤더 구성에 의해 제공되는 특징의 헤더 이름입니다.
-
data_type - SageMaker Clarify 처리 작업에서 추론한 특성 유형입니다. 텍스트 특징에 대해 유효한 값에는
numerical,categorical및free_text(텍스트 특징용)가 있습니다. -
attributions - 속성 객체의 특징별 배열입니다. 텍스트 특징에는
granularity구성에 정의된 단위마다 각각 여러 개의 속성 객체가 있을 수 있습니다. 이 특성 객체에는 다음 멤버가 있습니다.-
attribution - 클래스별 확률 값의 배열입니다.
-
description - (텍스트 특징용) 텍스트 단위에 대한 설명입니다.
-
partial_text - SageMaker Clarify 처리 작업에서 설명하는 텍스트 부분입니다.
-
start_idx – 부분적인 텍스트 조각의 시작 부분을 나타내는 배열의 위치를 파악하기 위한 제로 기반 인덱스입니다.
-
-
-
다음은 가독성을 높이기 위해 정성화된 로컬 SHAP 값 파일의 단일 줄의 예입니다.
{ "explanations": [ { "feature_name": "Rating", "data_type": "categorical", "attributions": [ { "attribution": [0.00342270632248735] } ] }, { "feature_name": "Comments", "data_type": "free_text", "attributions": [ { "attribution": [0.005260534499999983], "description": { "partial_text": "It's", "start_idx": 0 } }, { "attribution": [0.00424190349999996], "description": { "partial_text": "a", "start_idx": 5 } }, { "attribution": [0.010247314500000014], "description": { "partial_text": "good", "start_idx": 6 } }, { "attribution": [0.006148907500000005], "description": { "partial_text": "product", "start_idx": 10 } } ] } ] }
SHAP 분석 보고서
SHAP 분석 보고서는 최대 10 상위 전역 SHAP 값의 막대 차트를 제공합니다. 다음 차트 예제는 상위 4 기능의 SHAP 값을 보여줍니다.
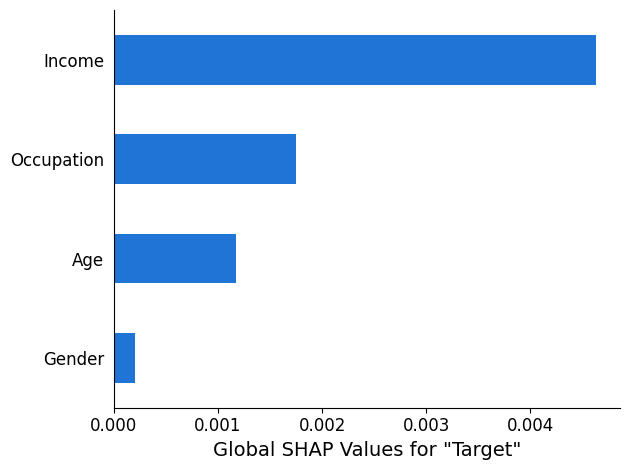
컴퓨터 비전(CV) 설명 가능성 분석
SageMaker 컴퓨터 비전 설명 가능성 명료화는 이미지로 구성된 데이터 세트를 가져와 각 이미지를 슈퍼 픽셀 모음으로 취급합니다. 분석 후 SageMaker Clarify 처리 작업은 각 이미지가 슈퍼 픽셀의 히트 맵을 표시하는 이미지 데이터 세트를 출력합니다.
다음 예제는 왼쪽에 입력 속도 제한 기호를 보여주고 열 지도는 오른쪽에 SHAP 값의 크기를 보여줍니다. 이러한 SHAP 값은 독일 교통 신호

자세한 내용은 SageMaker Clarify로 이미지 분류를 설명하고
부분 종속성 플롯(PDPs) 분석
부분 종속성 도표는 예측된 목표 응답이 관심 입력 특징의 집합에 대해 가지는 종속성을 보여줍니다. 이러한 특징은 다른 모든 입력 특징의 값과 대비하여 한계화되며, 이를 보완 특징이라고 합니다. 즉, 부분 종속성은 각각의 관심 입력 특성의 함수일 것으로 예상되는 목표 응답이라고 직관적으로 해석될 수 있습니다.
분석 파일의 스키마
PDP 값은 분석 파일의 explanations 섹션에 pdp 메서드 아래에 저장됩니다. explanations을 위한 매개변수는 다음과 같습니다.
-
explanations - 특징 중요도 분석 결과를 포함하고 있는 분석 파일들의 섹션입니다.
-
pdp - 단일 인스턴스에 대한 PDP 설명 배열이 포함된 분석 파일의 섹션입니다. 배열의 각 요소에는 다음과 같은 멤버가 있습니다.
-
feature_name -
headers구성에 의해 제공되는 특징의 헤더 이름입니다. -
data_type - SageMaker Clarify 처리 작업에서 추론한 특성 유형입니다.
data_type의 유효한 값에는 숫자 및 범주 유형이 포함됩니다. -
feature_values - 해당 특징에 나와 있는 값들을 포함합니다. SageMaker Clarify에서
data_type추론한 가 범주형인 경우 에는 해당 기능이 있을 수 있는 모든 고유 값이feature_values포함됩니다. SageMaker Clarify에서data_type추론한 이 숫자인 경우 에는 생성된 버킷의 중앙 값 목록이feature_values포함되어 있습니다.grid_resolution매개변수는 해당 특징 열의 값을 그룹화하는 데 사용되는 버킷의 수를 결정합니다. -
data_distribution - 백분율로 구성된 배열로, 여기서 각 값은 버킷이 포함하고 있는 인스턴스의 백분율입니다.
grid_resolution매개변수는 버킷의 수를 결정합니다. 특징 열의 값은 이러한 버킷의 형태로 그룹화됩니다. -
model_predictions - 모델 예측으로 구성된 배열로, 해당 배열의 각 요소는 모델 출력의 1개 클래스에 해당하는 예측의 배열입니다.
label_headers -
label_headers구성에서 제공하는 레이블 헤더입니다. -
오류 - 특정 이유로 PDP 값이 계산되지 않은 경우 생성되는 오류 메시지입니다. 이 오류 메시지는
feature_values,data_distributions및model_predictions필드에 포함된 내용을 대체합니다.
-
-
다음은 분석 결과가 포함된 PDP 분석 파일의 예제 출력입니다.
{ "version": "1.0", "explanations": { "pdp": [ { "feature_name": "Income", "data_type": "numerical", "feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1], "data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01], "model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]], "label_headers": ["Target"] }, ... ] } }
PDP 분석 보고서
각 기능에 대한 PDP 차트가 포함된 분석 보고서를 생성할 수 있습니다. PDP 차트는 x축을 feature_values 따라 플롯되고 y축을 model_predictions 따라 플롯됩니다. 멀티클래스 모델의 경우 model_predictions는 배열이고, 이 배열의 각 요소는 모델 예측 클래스 중 하나에 해당합니다.
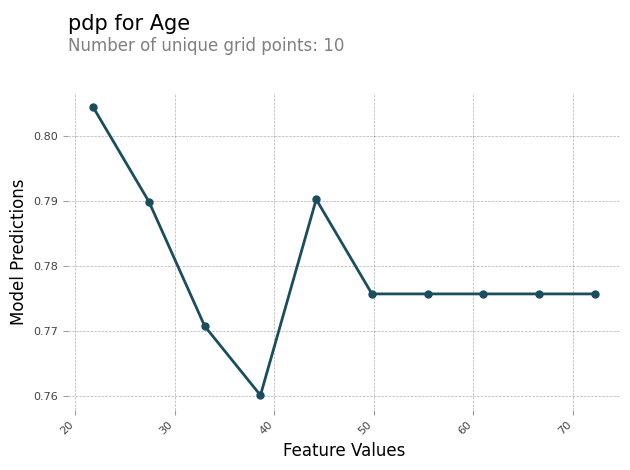
다음은 기능 에 대한 PDP 차트의 예입니다Age. 예제 출력에서 는 버킷으로 그룹화된 특성 값의 수를 PDP 보여줍니다. 버킷의 수는 grid_resolution에 의해 결정됩니다. 특징 값의 버킷은 모델 예측과 비교하여 도표화됩니다. 이 예제에서는 특징 값이 높을수록 모델 예측 값과 동일해집니다.
비대칭 Shapley 값
SageMaker 처리 작업은 비대칭 Shapley 값 알고리즘을 사용하여 시계열 예측 모델 설명 속성을 계산합니다. 이 알고리즘은 예측 예측에 대한 각 시간 단계에서 입력 기능의 기여도를 결정합니다.
비대칭 Shapley 값 분석 파일의 스키마
비대칭 Shapley 값 결과는 Amazon S3 버킷에 저장됩니다. 분석 파일의 섹션 설명에서 이 버킷의 위치를 찾을 수 있습니다. 이 섹션에는 특성 중요도 분석 결과가 포함되어 있습니다. 비대칭 Shapley 값 분석 파일에는 다음 파라미터가 포함됩니다.
asymmetric_shapley_value - 다음을 포함하여 설명 작업 결과에 대한 메타데이터가 포함된 분석 파일의 섹션입니다.
explanation_results_path — 설명 결과가 있는 Amazon S3 위치
방향 - 의 구성 값에 대한 사용자 제공 구성입니다.
direction세분화 - 의 구성 값에 대한 사용자 제공 구성입니다.
granularity
다음 조각은 예제 분석 파일에서 이전에 언급한 파라미터를 보여줍니다.
{ "version": "1.0", "explanations": { "asymmetric_shapley_value": { "explanation_results_path": EXPLANATION_RESULTS_S3_URI, "direction": "chronological", "granularity": "timewise", } } }
다음 섹션에서는 설명 결과 구조가 granularity 구성의 값에 따라 어떻게 달라지는지 설명합니다.
시간별 세분화
세분화가 인 경우 timewise 출력은 다음 구조로 표시됩니다. scores 값은 각 타임스탬프의 속성을 나타냅니다. offset 값은 기준 데이터에 대한 모델의 예측을 나타내며 데이터를 수신하지 않을 때 모델의 동작을 설명합니다.
다음 코드 조각은 두 시간 단계에 대한 예측을 수행하는 모델의 출력 예제를 보여줍니다. 따라서 모든 속성은 첫 번째 항목이 첫 번째 예상 시간 단계를 참조하는 두 요소의 목록입니다.
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]}, ] } { "item_id": "item2", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]}, ] }
세분화된 세분화
다음 예제에서는 세분화가 인 경우의 속성 결과를 보여줍니다fine_grained. offset 값은 이전 섹션에 설명된 것과 동일한 의미를 갖습니다. 가능한 경우 대상 시계열 및 관련 시계열의 각 타임스탬프의 각 입력 기능과 사용 가능한 경우 각 정적 공변량에 대해 속성이 계산됩니다.
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]}, {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "static_covariate_1", "scores": [0.6, 0.1]}, {"feature_name": "static_covariate_2", "scores": [0.1, 0.3]}, ] }
timewise 및 fine-grained 사용 사례 모두 결과는 JSON 행(.jsonl) 형식으로 저장됩니다.
