기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
다중 모델 엔드포인트 생성
SageMaker AI 콘솔 또는를 사용하여 다중 모델 엔드포인트를 AWS SDK for Python (Boto) 생성할 수 있습니다. 콘솔을 통해 CPU 또는 GPU 지원 엔드포인트를 생성하려면 다음 섹션의 콘솔 절차를 참조하세요. 를 사용하여 다중 모델 엔드포인트를 생성하려면 다음 섹션의 CPU 또는 GPU 절차를 AWS SDK for Python (Boto)사용합니다. CPU 및 GPU 워크플로는 비슷하지만 컨테이너 요구 사항 등 몇 가지 차이점이 있습니다.
주제
다중 모델 엔드포인트 생성(콘솔)
콘솔을 통해 CPU 및 GPU 지원 다중 모델 엔드포인트를 모두 생성할 수 있습니다. 다음 절차에 따라 SageMaker AI 콘솔을 통해 다중 모델 엔드포인트를 만듭니다.
다중 모델 엔드포인트를 생성하려면(콘솔)
-
https://console.aws.amazon.com/sagemaker/
에서 Amazon SageMaker AI 콘솔을 엽니다. -
모델을 선택한 다음 추론 그룹에서 모델 생성을 선택합니다.
-
모델 이름에 이름을 입력합니다.
-
IAM 역할의 경우
AmazonSageMakerFullAccessIAM 정책이 연결된 IAM 역할을 선택하거나 생성합니다. -
Container definition(컨테이너 정의) 섹션의 모델 아티팩트 및 추론 이미지 옵션 제공에 대해 다중 모델 사용를 선택합니다.
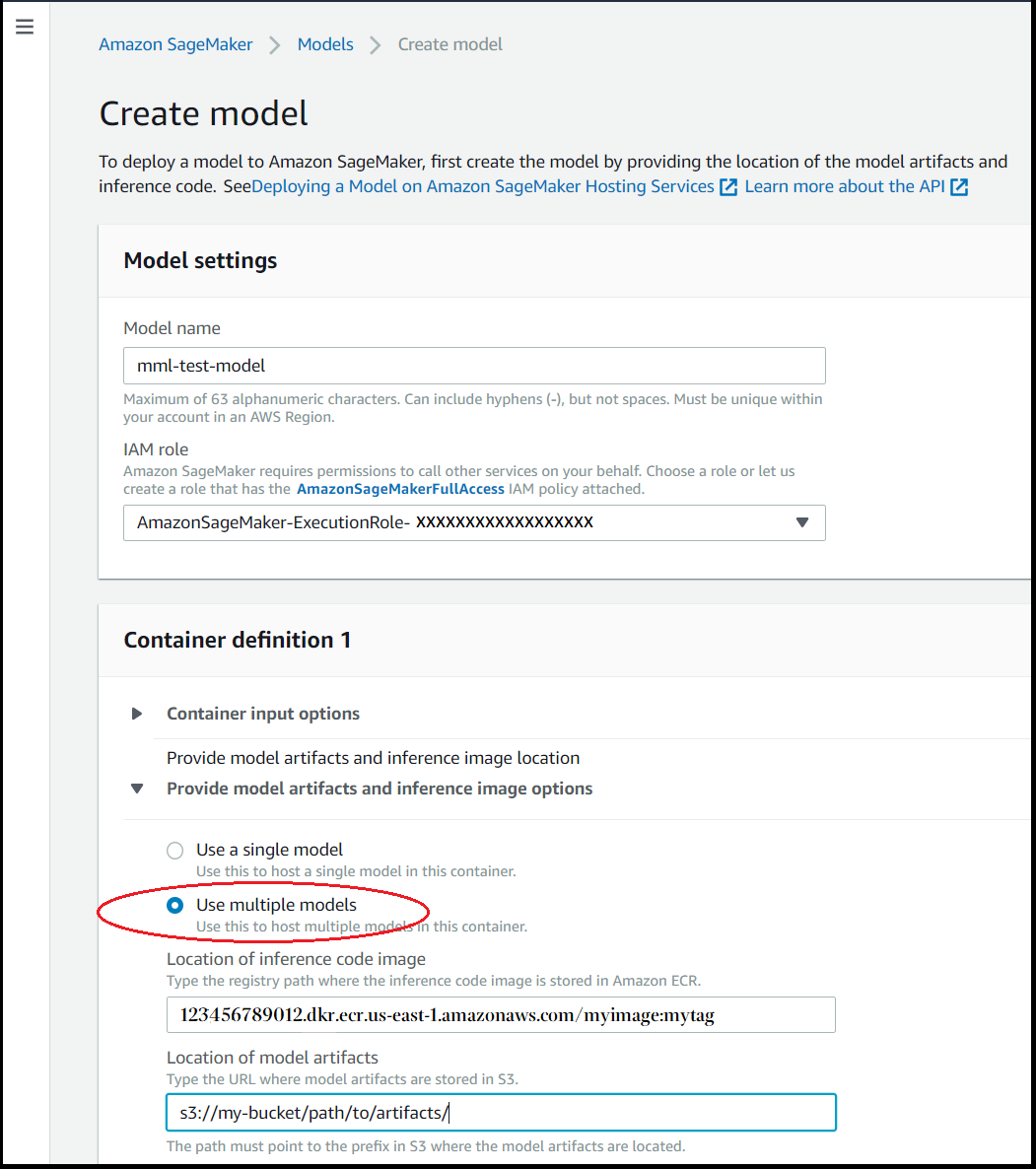
-
추론 컨테이너 이미지의 경우 원하는 컨테이너 이미지의 Amazon ECR 경로를 입력합니다.
GPU 모델의 경우 NVIDIA Triton 추론 서버가 지원하는 컨테이너를 사용해야 합니다. GPU 지원 엔드포인트에서 작동하는 컨테이너 이미지 목록은 NVIDIA Triton 추론 컨테이너(SM 지원만 해당)
를 참조하세요. NVIDIA Triton 추론 서버에 대한 자세한 내용은 Use Triton Inference Server with SageMaker AI를 참조하세요. -
Create model(모델 생성)을 선택합니다.
-
단일 모델 엔드포인트와 마찬가지로 다중 모델 엔드포인트를 배포합니다. 지침은 SageMaker AI 호스팅 서비스에 모델 배포 섹션을 참조하세요.
에서 CPUs를 사용하여 다중 모델 엔드포인트 생성 AWS SDK for Python (Boto3)
다음 섹션을 사용하여 CPU 인스턴스로 지원되는 다중 모델 엔드포인트를 생성합니다. 단일 모델 엔드포인트를 만들 때와 마찬가지로 Amazon SageMaker AI create_modelcreate_endpoint_configcreate_endpointMode 파라미터 값인 MultiModel을 전달해야 합니다. 또한 단일 모델을 배포할 때와 마찬가지로 단일 모델 아티팩트에 대한 경로 대신 모델 아티팩트가 위치한 Amazon S3의 접두사를 지정하는 ModelDataUrl 필드로도 이 값을 전달해야 합니다.
SageMaker AI를 사용하여 여러 XGBoost 모델을 엔드포인트에 배포하는 샘플 노트북에 대한 내용은 다중 모델 엔드포인트 XGBoost 샘플 노트북
다음 절차에서는 CPU 지원 다중 모델 엔드포인트를 생성하기 위해 해당 샘플에서 사용되는 주요 단계를 간략하게 설명합니다.
모델을 배포하려면(Python용AWS SDK(Boto 3))
-
다중 모델 엔드포인트 배포를 지원하는 이미지가 포함된 컨테이너를 가져오세요. 다중 모델 엔드포인트를 지원하는 기본 제공 알고리즘 및 프레임워크 컨테이너 목록은 다중 모델 엔드포인트용으로 지원되는 알고리즘, 프레임워크, 인스턴스 섹션을 참조하세요. 이 예제에서는 K-Nearest Neighbors(k-NN) 알고리즘 기본 제공 알고리즘을 사용합니다. SageMaker Python SDK
유틸리티 함수 image_uris.retrieve()를 호출하여 K-Nearest Neighbors 기본 제공 알고리즘 이미지의 주소를 가져옵니다.import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
AWS SDK for Python (Boto3) SageMaker AI 클라이언트를 가져와이 컨테이너를 사용하는 모델을 생성합니다.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(선택 사항) 직렬 추론 파이프라인을 사용하는 경우 파이프라인에 포함할 추가 컨테이너를 가져와서
CreateModel의Containers인수에 포함시킵니다.preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )참고
직렬 추론 파이프라인에서는 다중 모델 지원 엔드포인트를 하나만 사용할 수 있습니다.
-
(선택 사항) 사용 사례에서 모델 캐싱의 이점을 누리지 못할 경우
MultiModelConfig파라미터의ModelCacheSetting필드 값을Disabled로 설정하고create_model에 대한 호출의Container인수에 포함하세요.ModelCacheSetting필드의 값은 기본적으로Enabled입니다.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
모델에 대한 다중 모델 엔드포인트를 구성합니다. 최소 두 개의 인스턴스로 엔드포인트를 구성하는 것이 좋습니다. 이렇게 하면 SageMaker AI가 모델에서 여러 가용 영역에 걸쳐 고가용성 예측 세트를 제공할 수 있습니다.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )참고
직렬 추론 파이프라인에서는 다중 모델 지원 엔드포인트를 하나만 사용할 수 있습니다.
-
EndpointName및EndpointConfigName파라미터를 사용하여 다중 모델 엔드포인트를 생성합니다.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
에서 GPUs를 사용하여 다중 모델 엔드포인트 생성 AWS SDK for Python (Boto3)
다음 섹션을 사용하여 CPU 지원 다중 모델 엔드포인트를 생성합니다. 단일 모델 엔드포인트를 만들 때와 마찬가지로 Amazon SageMaker AI create_modelcreate_endpoint_configcreate_endpointMode 파라미터 값인 MultiModel을 전달해야 합니다. 또한 단일 모델을 배포할 때와 마찬가지로 단일 모델 아티팩트에 대한 경로 대신 모델 아티팩트가 위치한 Amazon S3의 접두사를 지정하는 ModelDataUrl 필드로도 이 값을 전달해야 합니다. GPU 지원 다중 모델 엔드포인트의 경우 GPU 인스턴스에서 실행하도록 최적화된 NVIDIA Triton 추론 서버가 포함된 컨테이너도 사용해야 합니다. GPU 지원 엔드포인트에서 작동하는 컨테이너 이미지 목록은 NVIDIA Triton 추론 컨테이너(SM 지원만 해당)
GPU로 지원되는 다중 모델 엔드포인트를 만드는 방법을 보여주는 예시 노트북은 Amazon SageMaker 다중 모델 엔드포인트를 사용하여 GPU에서 여러 딥 러닝 모델 실행
다음 절차에서는 GPU 지원 다중 모델 엔드포인트를 생성하는 주요 단계를 간략하게 설명합니다.
모델을 배포하려면(Python용AWS SDK(Boto 3))
-
컨테이너 이미지를 정의합니다. ResNet 모델에 대한 GPU 지원이 포함된 다중 모델 엔드포인트를 생성하려면 NVIDIA Triton Server 이미지를 사용할 컨테이너를 정의하세요. 이 컨테이너는 다중 모델 엔드포인트를 지원하며 GPU 인스턴스에서 실행하도록 최적화되었습니다. SageMaker AI Python SDK
유틸리티 함수( image_uris.retrieve())를 직접적으로 호출하여 이미지의 주소를 가져옵니다. 예제:import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
AWS SDK for Python (Boto3) SageMaker AI 클라이언트를 가져와이 컨테이너를 사용하는 모델을 생성합니다.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(선택 사항) 직렬 추론 파이프라인을 사용하는 경우 파이프라인에 포함할 추가 컨테이너를 가져와서
CreateModel의Containers인수에 포함시킵니다.preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )참고
직렬 추론 파이프라인에서는 다중 모델 지원 엔드포인트를 하나만 사용할 수 있습니다.
-
(선택 사항) 사용 사례에서 모델 캐싱의 이점을 누리지 못할 경우
MultiModelConfig파라미터의ModelCacheSetting필드 값을Disabled로 설정하고create_model에 대한 호출의Container인수에 포함하세요.ModelCacheSetting필드의 값은 기본적으로Enabled입니다.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
모델에 대한 GPU 지원 인스턴스로 다중 모델 엔드포인트를 구성합니다. 고가용성과 더 높은 캐시 적중 수를 허용하려면 두 개 이상의 인스턴스로 엔드포인트를 구성하는 것이 좋습니다.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
EndpointName및EndpointConfigName파라미터를 사용하여 다중 모델 엔드포인트를 생성합니다.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
