기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
SageMaker AI의 분산형 데이터 병렬화 라이브러리 알아보기
SageMaker AI 분산형 데이터 병렬화(SMDDP) 라이브러리는 분산 데이터 병렬 훈련의 컴퓨팅 성능을 개선하는 집합 통신 라이브러리입니다. SMDDP 라이브러리는 다음을 제공하여 키 집합 통신 작업의 통신 오버헤드를 해결합니다.
-
라이브러리는에
AllReduce최적화된를 제공합니다 AWS.AllReduce는 분산 데이터 훈련 중에 각 훈련 반복이 끝날 때 GPUs 간에 그라데이션을 동기화하는 데 사용되는 주요 작업입니다. -
라이브러리는에
AllGather최적화된를 제공합니다 AWS.AllGather는 샤딩된 데이터 병렬 훈련에 사용되는 또 다른 키 작업으로, SageMaker AI 모델 병렬 처리(SMP) 라이브러리, DeepSpeed Zero Redundancy Optimizer(ZeRO) 및 PyTorch 완전 샤딩된 데이터 병렬 처리(FSDP)와 같은 인기 있는 라이브러리에서 제공하는 메모리 효율적인 데이터 병렬 처리 기법입니다. -
라이브러리는 AWS 네트워크 인프라와 Amazon EC2 인스턴스 토폴로지를 완전히 활용하여 최적화된 node-to-node 통신을 수행합니다.
SMDDP 라이브러리는 거의 선형적인 조정 효율성과 함께 훈련 클러스터를 확장할 때 성능을 개선하여 훈련 속도를 높일 수 있습니다.
참고
SageMaker AI 분산 훈련 라이브러리는 SageMaker 훈련 플랫폼 내의 PyTorch 및 Hugging Face용 AWS 딥 러닝 컨테이너를 통해 사용할 수 있습니다. 이 라이브러리를 사용하려면 Python(Boto3)용 SDK 또는 AWS Command Line Interface을 통해 SageMaker Python SDK 또는 SageMaker API를 사용해야 합니다. 지침과 예제는 설명서 전반에 걸쳐 SageMaker Python SDK를 사용하여 분산형 훈련 라이브러리를 사용하는 방법에 중점을 둡니다.
AWS 컴퓨팅 리소스 및 네트워크 인프라에 최적화된 SMDDP 집합 통신 작업
SMDDP 라이브러리는 AWS 컴퓨팅 리소스 AllReduce 및 네트워크 인프라에 최적화된 및 AllGather 집합 작업의 구현을 제공합니다.
SMDDP AllReduce 집합 작업
SMDDP 라이브러리는 역방향 패스와 AllReduce 작업을 최적으로 중첩하여 GPU 사용률을 크게 개선합니다. CPU와 GPU 간 커널 작업을 최적화하여 선형에 가까운 스케일링 효율과 보다 빠른 훈련 속도를 달성합니다. GPU가 추가 GPU 사이클을 제거하지 않고 그래디언트를 계산하는 동안 이 라이브러리는 병렬로 AllReduce를 수행하므로 라이브러리가 더 빠른 학습을 달성할 수 있습니다.
-
CPU 활용: 라이브러리는 CPU를 사용하여 그래디언트를 하여 GPU에서 이 작업을 오프로드합니다.
-
향상된 GPU 사용: 클러스터의 GPU가 컴퓨팅 그래디언트에 집중하여 훈련 전반에 걸쳐 활용도를 높입니다.
다음은 SMDDP AllReduce 작업의 상위 수준 워크플로입니다.
-
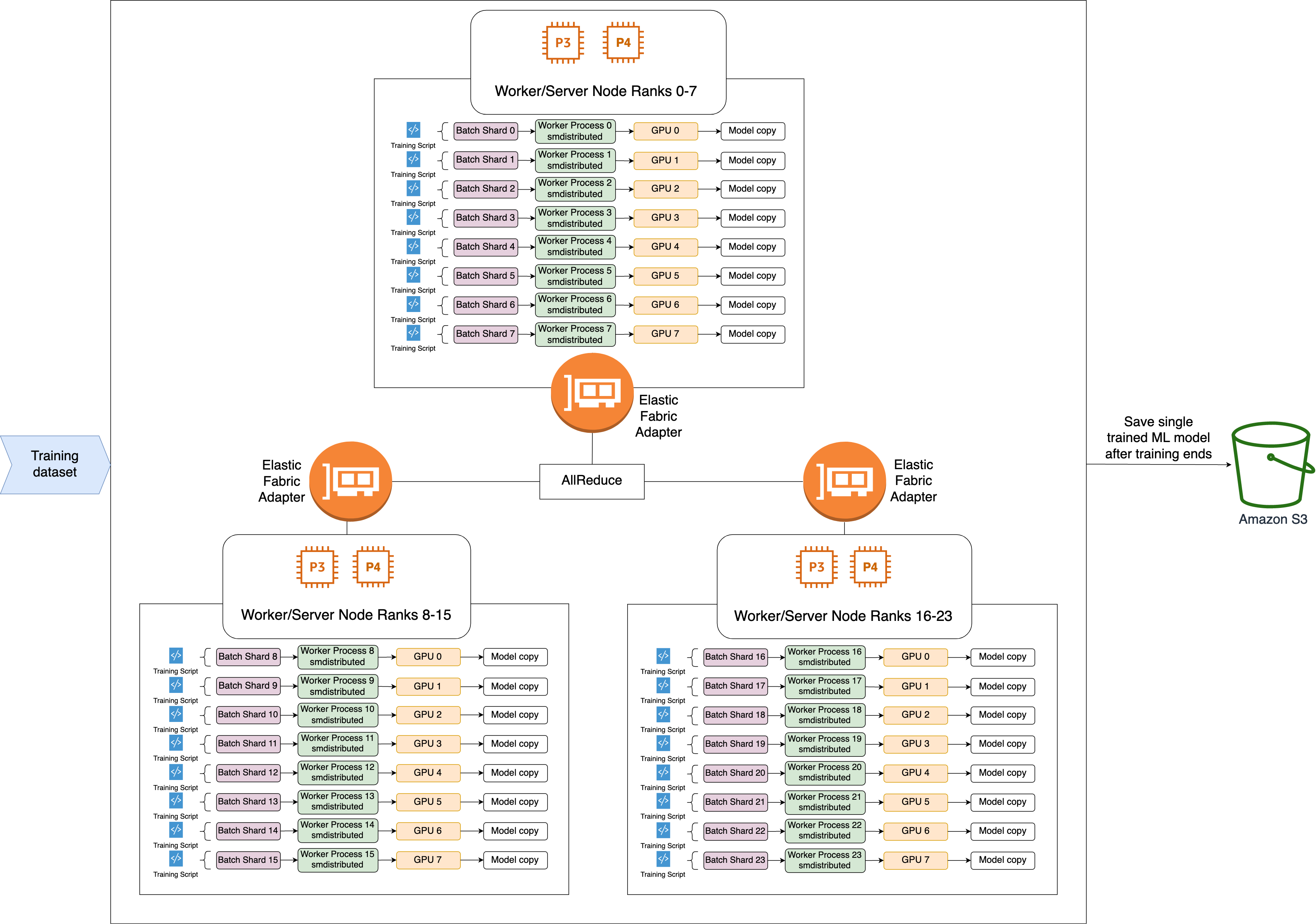
이 라이브러리는 GPU(작업자)에 순위를 할당합니다.
-
각 반복에서 이 라이브러리는 각 글로벌 배치를 총 워커 수(월드 사이즈)로 나누고 작업자에게 작은 배치(배치 샤드)를 할당합니다.
-
글로벌 배치의 크기는
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard)입니다. -
배치 샤드(소규모 배치)는 반복별로 각 GPU(작업자)에 할당되는 데이터세트의 하위 집합입니다.
-
-
이 라이브러리는 각 작업자에 대해 훈련 스크립트를 실행합니다.
-
이 라이브러리는 모든 반복이 끝날 때마다 작업자의 모델 가중치 및 그래디언트 사본을 관리합니다.
-
이 라이브러리는 작업자 전체의 모델 가중치와 그래디언트를 동기화하여 훈련된 단일 모델을 집계합니다.
아래의 아키텍처 다이어그램은 이 라이브러리가 3개 노드로 구성된 클러스터에 대해 데이터 병렬화를 설정하는 방법의 예를 보여줍니다.
SMDDP AllGather 집합 작업
AllGather는 각 작업자가 입력 버퍼로 시작한 다음 다른 모든 작업자의 입력 버퍼를 출력 버퍼로 연결하거나 수집하는 집합 작업입니다.
참고
SMDDP AllGather 집합 작업은 smdistributed-dataparallel>=2.0.1 및 PyTorch v2.0.1 이상용 AWS DLC(Deep Learning Containers)에서 사용할 수 있습니다.
AllGather는 각 개별 작업자가 모델의 일부를 보유하거나 샤딩된 계층을 보유하는 샤딩된 데이터 병렬 처리와 같은 분산 훈련 기법에 많이 사용됩니다. 작업자는 전달 및 역방향 전달하기 전에 AllGather를 호출하여 샤딩된 계층을 재구성합니다. 파라미터가 모두 수집된 후 순방향 및 역방향 패스는 계속됩니다. 백워드 패스 중에 각 작업자는 ReduceScatter를 호출하여 그라데이션을 수집(감소)하고 그라데이션 샤드로 분할(산란)하여 해당 샤딩된 계층을 업데이트합니다. 샤딩된 데이터 병렬 처리에서 이러한 집합 작업의 역할에 대한 자세한 내용은 샤딩된 데이터 병렬 처리에 대한 SMP 라이브러리의 구현, DeepSpeed 설명서의 ZeRO
AllGather와 같은 공동 작업은 모든 반복에서 호출되므로 GPU 통신 오버헤드의 주요 기여자입니다. 이러한 집합 작업을 더 빠르게 계산하면 수렴에 대한 부작용 없이 훈련 시간이 단축됩니다. 이를 위해 SMDDP 라이브러리는 P4d 인스턴스AllGather를 제공합니다.
SMDDPAllGather는 다음 기법을 사용하여 P4d 인스턴스의 계산 성능을 개선합니다.
-
메시 토폴로지를 사용하여 EFA(Elastic Fabric Adapter)
네트워크를 통해 인스턴스(노드 간) 간에 데이터를 전송합니다. EFA는 지연 시간이 AWS 짧고 처리량이 많은 네트워크 솔루션입니다. 노드 간 네트워크 통신을 위한 메시 토폴로지는 EFA 및 AWS 네트워크 인프라의 특성에 더 잘 맞게 조정됩니다. 여러 패킷 홉이 포함된 NCCL 링 또는 트리 토폴로지와 비교하여 SMDDP는 하나의 홉만 필요하므로 여러 홉의 지연 시간을 축적하지 않습니다. SMDDP는 메시 토폴로지에서 각 통신 피어에 대한 워크로드의 균형을 맞추고 더 높은 글로벌 네트워크 처리량을 달성하는 네트워크 속도 제어 알고리즘을 구현합니다. -
NVIDIA GPUDirect RDMA 기술(GDRCopy)을 기반으로 지연 시간이 짧은 GPU 메모리 복사 라이브러리 GDRCopy
를 채택하여 로컬 NVLink 및 EFA 네트워크 트래픽을 조정합니다. NVIDIA에서 제공하는 지연 시간이 짧은 GPU 메모리 복사 라이브러리인 GDRCopy는 CPU 프로세스와 GPU CUDA 커널 간의 지연 시간이 짧은 통신을 제공합니다. 이 기술을 사용하면 SMDDP 라이브러리가 노드 내 및 노드 간 데이터 이동을 파이프라인화할 수 있습니다. -
GPU 스트리밍 멀티프로세서의 사용량을 줄여 모델 커널을 실행하기 위한 컴퓨팅 성능을 높입니다. P4d 및 P4de 인스턴스에는 각각 108개의 스트리밍 멀티프로세서가 있는 NVIDIA A100 GPUs가 탑재되어 있습니다. NCCL은 집합 작업을 실행하는 데 최대 24개의 스트리밍 멀티프로세서를 사용하지만 SMDDP는 9개 미만의 스트리밍 멀티프로세서를 사용합니다. 모델 컴퓨팅 커널은 더 빠른 계산을 위해 저장된 스트리밍 멀티프로세서를 선택합니다.
