기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
모델 호스팅 FAQ
SageMaker AI 추론 호스팅에 대해 자주 묻는 질문에 대한 답변은 다음 FAQ 항목을 참조하세요.
일반 호스팅
다음 FAQ 항목은 SageMaker AI 추론에 대한 일반적인 질문에 답합니다.
A: 모델을 빌드하고 훈련한 후 Amazon SageMaker AI는 모델을 배포하는 네 가지 옵션을 제공하므로 예측을 시작할 수 있습니다. 실시간 추론(Real-Time Inference)은 밀리초 지연 시간이 필요하고 페이로드 크기가 최대 6MB이고 처리 시간이 최대 60초인 워크로드에 적합합니다. 배치 변환(Batch Transform)은 미리 사용할 수 있는 대규모 데이터 배치에 대한 오프라인 예측에 이상적입니다. 비동기 추론(Asynchronous Inference)은 1초 미만의 지연 시간 요구 사항이 없고 페이로드 크기가 최대 1GB이고 처리 시간이 최대 15분인 워크로드에 맞게 설계되었습니다. 서버리스 추론(Serverless Inference)을 사용하면 기본 인프라를 구성하거나 관리할 필요 없이 추론을 위한 기계 학습 모델을 빠르게 배포할 수 있으며, 추론 요청을 처리하는 데 사용한 컴퓨팅 용량에 대해서만 비용을 지불하면 되므로 간헐적인 워크로드에 적합합니다.
A: 다음 다이어그램은 SageMaker AI 호스팅 모델 배포 옵션을 선택하는 데 도움이 될 수 있습니다.
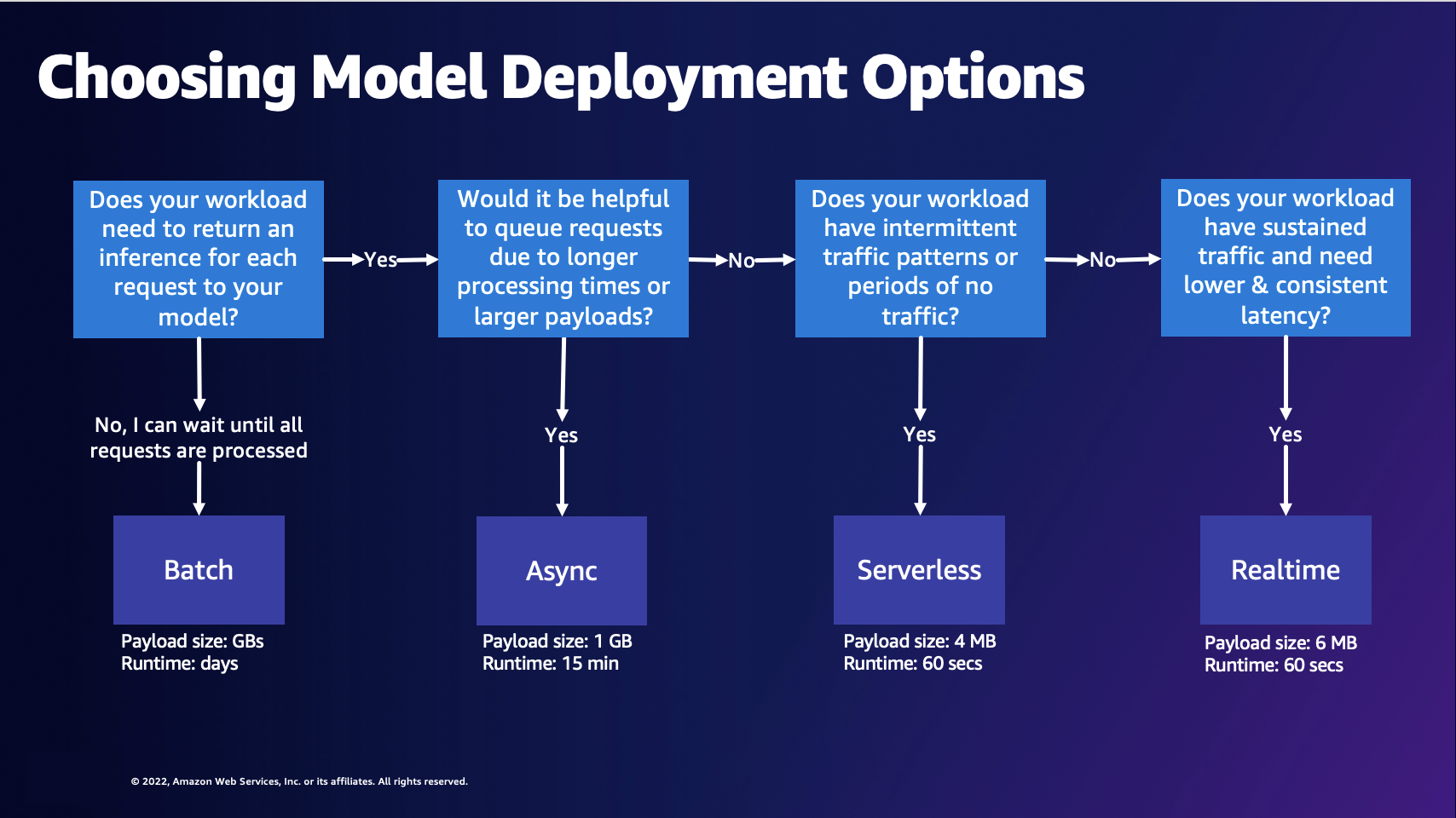
위 다이어그램은 다음 결정 프로세스를 안내합니다. 요청을 일괄적으로 처리하려면 배치 변환을 선택하는 것이 좋습니다. 그렇지 않으면, 모델에 대한 각각의 요청에 대한 추론을 수신하려면 비동기 추론, 서버리스 추론 또는 실시간 추론을 선택하는 것이 좋습니다. 처리 시간이 길거나 페이로드가 크고 요청을 대기열에 추가하려는 경우 비동기 추론을 선택할 수 있습니다. 워크로드가 예측할 수 없거나 간헐적인 트래픽을 가지고 있는 경우 서버리스 추론을 선택할 수 있습니다. 트래픽이 지속되고 요청에 대해 더 짧고 일관된 지연 시간이 필요한 경우 실시간 추론을 선택할 수 있습니다.
A: SageMaker AI 추론을 사용하여 비용을 최적화하려면 사용 사례에 적합한 호스팅 옵션을 선택해야 합니다. Amazon SageMaker AI Savings Plans
A: 성능을 개선하고 비용을 절감하기 위해 올바른 엔드포인트 구성에 대한 추천이 필요한 경우 Amazon SageMaker Inference Recommender를 사용해야 합니다. 이전에는 모델을 배포하려는 데이터 과학자가 수동 벤치마크를 실행하여 올바른 엔드포인트 구성을 선택해야 했습니다. 먼저, 모델의 리소스 요구 사항과 샘플 페이로드를 기반으로 70개 이상의 사용 가능한 인스턴스 유형 중에서 적절한 기계 학습 인스턴스 유형을 선택한 다음 다양한 하드웨어에 맞게 모델을 최적화해야 했습니다. 그런 다음 광범위한 부하 테스트를 수행하여 지연 시간 및 처리량 요구 사항이 충족되고 비용이 낮은지 검증해야 했습니다. 추론 추천은 다음을 지원함으로써 이같은 복잡함을 제거했습니다.
-
인스턴스 추천으로 몇 분 만에 시작할 수 있습니다.
-
여러 인스턴스 유형에 대한 부하 테스트를 수행하여 몇 시간 내에 엔드포인트 구성에 대한 권장 사항을 얻을 수 있습니다.
-
컨테이너 및 모델 서버 파라미터를 자동으로 튜닝하고 지정된 인스턴스 유형에 대한 모델 최적화를 수행합니다.
A: SageMaker AI 엔드포인트는 모델 서버를 포함하는 컨테이너화된 웹 서버를 사용하는 HTTP REST 엔드포인트입니다. 이러한 컨테이너는 기계 학습 모델에 대한 요청을 로드하고 서비스를 제공하는 역할을 합니다. 컨테이너는 포트 8080에서 /invocations 및 /ping에 응답하는 웹 서버를 구현합니다.
일반적인 모델 서버로는 TensorFlow Serving, TorchServe, Multi Model Server가 있습니다. SageMaker AI 프레임워크 컨테이너에는 이러한 모델 서버가 내장되어 있습니다.
A: SageMaker AI 추론의 모든 것이 컨테이너화됩니다. SageMaker AI는 TensorFlow, SKlearn 및 HuggingFace와 같은 인기 프레임워크를 위한 관리형 컨테이너를 제공합니다. 이러한 이미지의 업데이트된 종합 목록은 사용 가능한 이미지
컨테이너를 빌드해야 하는 사용자 지정 프레임워크가 있는 경우가 있습니다. 이 접근 방식을 Bring Your Own Container 또는 BYOC라고 합니다. BYOC 접근 방식에서는 프레임워크 또는 라이브러리를 설정하는 데 필요한 도커 이미지를 제공합니다. 그런 다음 이미지를 Amazon Elastic Container Registry(Amazon ECR)로 푸시하여 SageMaker AI와 함께 이미지를 사용할 수 있습니다. BYOC 접근 방식의 예는 Amazon SageMaker AI용 컨테이너의 오버리브를 참조하세요
또는 이미지를 처음부터 새로 만드는 대신 컨테이너를 확장할 수 있습니다. SageMaker AI가 제공하는 기본 이미지 중 하나를 가져와서 Dockerfile에서 여기에 종속성을 추가할 수 있습니다.
A: SageMaker AI는 SageMaker AI 외부에서 훈련한 자체 훈련된 프레임워크 모델을 가져와서 SageMaker AI 호스팅 옵션에 배포할 수 있는 용량을 제공합니다.
SageMaker AI를 사용하려면 모델을 model.tar.gz 파일로 패키징하고 특정 디렉터리 구조를 보유해야 합니다. 각 프레임워크는 고유한 모델 구조를 가지고 있습니다 (구조 예제는 다음 질문 참조). 자세한 내용은 TensorFlow
TensorFlow, PyTorch 및 MXNet과 같은 사전 구축된 프레임워크 이미지 중에서 선택하여 훈련된 모델을 호스팅할 수 있지만, 자체 컨테이너를 구축하여 SageMaker AI 엔드포인트에서 훈련된 모델을 호스팅할 수도 있습니다. 자세한 내용은 Jupyter notebook 자체 알고리즘 컨테이너 구축
A: SageMaker AI를 사용하려면 모델 아티팩트를 .tar.gz 파일 또는 tarball로 압축해야 합니다. SageMaker AI는이 .tar.gz 파일을 컨테이너의 /opt/ml/model/ 디렉터리로 자동으로 추출합니다. 타르볼에는 symlink나 불필요한 파일이 포함되어서는 안 됩니다. TensorFlow, PyTorch 또는 MXNet과 같은 프레임워크 컨테이너 중 하나를 사용하는 경우 컨테이너는 TAR 구조가 다음과 같을 것으로 예상합니다.
TensorFlow
model.tar.gz/ |--[model_version_number]/ |--variables |--saved_model.pb code/ |--inference.py |--requirements.txt
PyTorch
model.tar.gz/ |- model.pth |- code/ |- inference.py |- requirements.txt # only for versions 1.3.1 and higher
MXNet
model.tar.gz/ |- model-symbol.json |- model-shapes.json |- model-0000.params |- code/ |- inference.py |- requirements.txt # only for versions 1.6.0 and higher
A: ContentType은 요청 본문에 있는 입력 데이터의 MIME 유형(엔드포인트로 보내는 데이터의 MIME 유형)입니다. 모델 서버는 ContentType을 사용하여 제공된 유형을 처리할 수 있는지 여부를 결정합니다.
Accept는 추론 응답의 MIME 유형(엔드포인트가 반환하는 데이터의 MIME 유형)입니다. 모델 서버는 Accept 유형을 사용하여 제공된 유형의 반환을 처리할 수 있는지 여부를 결정합니다.
일반적인 MIME 유형에는 text/csv, application/json, application/jsonlines 등이 있습니다.
A: SageMaker AI는 수정 없이 모델 컨테이너에 요청을 전달합니다. 컨테이너에는 요청을 역직렬화하기 위한 로직이 포함되어 있어야 합니다. 내장 알고리즘에 정의된 형식에 대한 자세한 내용은 추론을 위한 일반 데이터 형식을 참조하세요. 자체 컨테이너를 빌드하거나 SageMaker AI 프레임워크 컨테이너를 사용하는 경우 선택한 요청 형식을 수락하는 로직을 포함할 수 있습니다.
마찬가지로 SageMaker AI는 수정 없이 응답을 반환한 다음 클라이언트는 응답을 역직렬화해야 합니다. 내장된 알고리즘의 경우 특정 형식으로 응답을 반환합니다. 자체 컨테이너를 빌드하거나 SageMaker AI 프레임워크 컨테이너를 사용하는 경우 선택한 형식으로 응답을 반환하는 로직을 포함할 수 있습니다.
Invoke Endpoint API 직접 호출을 사용하여 엔드포인트에 대해 추론할 수 있습니다.
입력을 InvokeEndpoint API에 페이로드로 전달할 때는 모델이 맞는 올바른 유형의 입력 데이터를 제공해야 합니다. InvokeEndpoint API 직접 호출에서 페이로드를 전달하면 요청 바이트가 모델 컨테이너로 직접 전달됩니다. 예를 들어 이미지의 경우 ContentType에 맞는 application/jpeg을 사용하고, 모델이 이러한 유형에 대해 추론할 수 있는지 확인할 수 있습니다. 이는 JSON, CSV, 동영상 또는 처리할 수 있는 기타 모든 유형의 입력에 적용됩니다.
고려해야 할 또 다른 요소는 페이로드 크기 제한입니다. 실시간 및 서버리스 엔드포인트의 경우 페이로드 제한은 6MB입니다. 동영상을 여러 프레임으로 분할하고 각 프레임마다 개별적으로 엔드포인트를 호출할 수 있습니다. 또는 사용 사례가 허용되는 경우, 최대 1GB의 페이로드를 지원하는 비동기 엔드포인트를 사용하여 페이로드에 전체 동영상을 전송할 수 있습니다.
비동기 추론을 사용하여 대형 동영상에서 컴퓨터 비전 추론을 실행하는 방법을 보여주는 예제는 이 블로그 게시물
실시간 추론
다음 FAQ 항목은 SageMaker AI 실시간 추론에 대한 일반적인 질문에 답변합니다.
A: AWS SDKs, SageMaker Python SDK AWS Management Console AWS CloudFormation, 및와 같은 AWS지원되는 도구를 통해 SageMaker AI 엔드포인트를 생성할 수 있습니다 AWS Cloud Development Kit (AWS CDK).
엔드포인트 생성에는 SageMaker AI 모델, SageMaker AI 엔드포인트 구성, SageMaker AI 엔드포인트의 세 가지 주요 개체가 있습니다. SageMaker AI 모델은 사용 중인 모델 데이터와 이미지를 가리킵니다. 엔드포인트 구성은 인스턴스 유형 및 인스턴스 수를 포함할 수 있는 프로덕션 변형을 정의합니다. 그런 다음 Create_endpoint
A: 다중 모델 엔드포인트는 SageMaker AI가 제공하는 실시간 추론 옵션입니다. 다중 모델 엔드포인트를 사용하면 하나의 엔드포인트에서 수천 개의 모델을 호스팅할 수 있습니다. 다중 모델 서버
A: SageMaker AI 실시간 추론은 다중 모델 엔드포인트, 다중 컨테이너 엔드포인트 및 직렬 추론 파이프라인과 같은 다양한 모델 배포 아키텍처를 지원합니다.
다중 모델 엔드포인트(MME) - MME를 통해 고객은 수천 개의 초개인화된 모델을 비용 효율적인 방식으로 배포할 수 있습니다. 모든 모델은 공유 리소스 플릿에서 배포됩니다. MME는 모델의 크기와 지연 시간이 비슷하고 동일한 ML 프레임워크에 속할 때 가장 잘 작동합니다. 이러한 엔드포인트는 항상 같은 모델을 호출할 필요가 없는 경우에 적합합니다. 각 모델을 SageMaker AI 엔드포인트에 동적으로 로드하여 요청을 처리할 수 있습니다.
다중 컨테이너 엔드포인트(MCE) - MCE를 통해 고객은 SageMaker 엔드포인트 1개만 사용하면서 콜드 스타트 없이 다양한 ML 프레임워크 및 기능을 갖춘 15개의 서로 다른 컨테이너를 배포할 수 있습니다. 이러한 컨테이너를 직접 호출할 수 있습니다. MCE는 모든 모델을 메모리에 보관하려는 경우에 가장 적합합니다.
직렬 추론 파이프라인(SIP) - SIP를 사용하여 단일 엔드포인트에서 2-15개의 컨테이너를 연결할 수 있습니다. SIP는 한 엔드포인트에서 전처리와 모델 추론을 결합하고 지연 시간이 짧은 작업에 가장 적합합니다.
서버리스 추론
다음 FAQ 항목은 Amazon SageMaker 서버리스 추론에 대한 일반적인 질문에 대한 답변을 제공합니다.
A: Amazon SageMaker 서버리스 추론을 사용하여 모델 배포은/는 용도에 맞게 구축된 서버리스 모델 서비스 옵션으로, ML 모델을 쉽게 배포하고 확장할 수 있습니다. 서버리스 추론 엔드포인트는 자동으로 컴퓨팅 리소스를 시작하고 트래픽에 따라 리소스를 확장 및 축소하므로 인스턴스 유형을 선택하거나 프로비저닝 용량을 실행하거나 조정을 관리할 필요가 없습니다. 선택적으로 서버리스 엔드포인트에 대한 메모리 요구 사항을 지정할 수 있습니다. 유휴 기간이 아닌 추론 코드를 실행하는 기간과 처리된 데이터 양에 대해서만 비용을 지불하면 됩니다.
A: 서버리스 추론을 사용하면 용량을 미리 프로비저닝하고 조정 정책을 관리할 필요가 없으므로 개발자 경험이 간소화됩니다. 서버리스 추론은 사용 패턴에 따라 몇 초 내에 수십 개에서 수천 개의 추론으로 즉시 확장할 수 있으므로 트래픽이 간헐적이거나 예측할 수 없는 ML 애플리케이션에 적합합니다. 예를 들어, 급여 처리 회사에서 사용하는 챗봇 서비스의 경우 월말에 문의가 증가하는 반면 나머지 기간에는 트래픽이 간헐적인 경우가 있습니다. 이러한 시나리오에서 한 달 내내 인스턴스를 프로비저닝하는 것은 유휴 기간에 대한 비용을 지불하게 되므로 비용 효율적이지 않습니다.
서버리스 추론을 사용하면 미리 트래픽을 예측하거나 조정 정책을 관리할 필요 없이 자동으로 빠르게 확장할 수 있어 이러한 유형의 사용 사례를 해결할 수 있습니다. 또한 추론 코드를 실행하는 데 드는 컴퓨팅 시간과 데이터 처리에 대한 비용만 지불하므로 트래픽이 간헐적으로 발생하는 워크로드에 적합합니다.
A. 서버리스 엔드포인트의 최소 RAM 크기는 1,024MB(1GB)이고, 선택할 수 있는 최대 RAM 크기는 6,144MB(6GB)입니다. 선택할 수 있는 메모리 크기는 1,024MB, 2,048MB, 3,072MB, 4,096MB, 5,120MB 또는 6,144MB입니다. 서버리스 추론은 선택한 메모리에 비례하여 컴퓨팅 리소스를 자동 할당합니다. 더 큰 메모리 크기를 선택하면 컨테이너가 더 많은 vCPU에 액세스할 수 있습니다.
모델 크기에 따라 엔드포인트의 메모리 크기를 선택합니다. 일반적으로 메모리 크기는 최소한 모델 크기만큼 커야 합니다. 지연 시간 SLA에 따라 모델에 적합한 메모리를 선택하려면 벤치마킹이 필요할 수 있습니다. 메모리 크기 증분은 요금이 다릅니다. 자세한 내용은 Amazon SageMaker AI 요금 페이지를
배치 변환
다음 FAQ 항목은 SageMaker AI 배치 변환에 대한 일반적인 질문에 답변합니다.
A: CSV, RecordIO 및 TFRecord와 같은 특정 파일 형식의 경우 SageMaker AI는 데이터를 단일 레코드 또는 다중 레코드 미니 배치로 분할하여 모델 컨테이너에 페이로드로 전송할 수 있습니다. 값이 이면 MultiRecord SageMaker AIBatchStrategy는 각 요청의 최대 레코드 수를 MaxPayloadInMB 한도까지 전송합니다. 값이 이면 SingleRecord SageMaker AIBatchStrategy는 각 요청에서 개별 레코드를 전송합니다.
A: 배치 변환의 최대 제한 시간은 3600초입니다. 레코드의 최대 페이로드 크기(미니 배치당)는 100MB입니다.
CreateTransformJob API를 사용하는 경우 MaxPayloadInMB, MaxConcurrentTransforms 또는 BatchStrategy와 같은 최적의 파라미터 값을 사용하여 배치 변환 작업을 완료하는 데 걸리는 시간을 단축할 수 있습니다. MaxConcurrentTransforms의 이상적인 값은 배치 변환 작업의 컴퓨팅 작업자 수와 같습니다. SageMaker AI 콘솔을 사용하는 경우 배치 변환 작업 구성 페이지의 추가 구성 섹션에서 이러한 최적의 파라미터 값을 지정할 수 있습니다. SageMaker AI는 내장 알고리즘에 대한 최적의 파라미터 설정을 자동으로 찾습니다. 사용자 지정 알고리즘의 경우 execution-parameters 엔드포인트를 통해 이러한 값을 제공합니다.
A:배치 변환은 CSV 및 JSON을 지원합니다.
비동기식 추론
다음 FAQ 항목은 SageMaker AI 비동기 추론에 대한 일반적인 질문에 답변합니다.
A: 비동기 추론은 비동기기적으로 수신 요청을 대기열에 넣고 처리합니다. 이 옵션은 페이로드 크기가 크거나 처리 시간이 길어 도착하자마자 처리해야 하는 요청에 적합합니다. 선택적으로, 요청을 적극적으로 처리하지 않는 경우 인스턴스 수를 0으로 축소하도록 오토 스케일링 설정을 구성할 수 있습니다.
A: Amazon SageMaker AI는 비동기 엔드포인트의 자동 조정(자동 조정)을 지원합니다. 오토 스케일링은 워크로드의 변화에 따라 모델에 대해 프로비저닝된 인스턴스의 수를 동적으로 조정합니다. SageMaker AI가 지원하는 다른 호스팅 모델과 달리 비동기 추론을 사용하면 비동기 엔드포인트 인스턴스를 0으로 축소할 수도 있습니다. 인스턴스가 0개일 때 수신된 요청은 엔드포인트가 확장되면 처리를 위해 대기열에 추가됩니다. 자세한 내용은 비동기 엔드포인트 오토 스케일링을 참조하세요.
Amazon SageMaker 서버리스 추론도 자동으로 0으로 축소됩니다. SageMaker AI가 서버리스 엔드포인트의 크기 조정을 관리하지만 트래픽이 발생하지 않는 경우 동일한 인프라가 적용되므로이 문제가 표시되지 않습니다.
