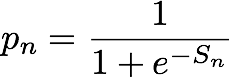기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
IP Insights 작동 방식
Amazon SageMaker IP Insights는 관찰된 데이터를 엔티티와 IP 주소를 연결하는 (엔티티, IPv4 주소) 쌍의 형태로 소비하는 감독되지 않은 알고리즘입니다. IP Insights는 엔터티 및 IP 주소 둘 다에 대한 잠재 벡터 표현을 학습하여 엔터티가 특정 IP 주소를 사용할 가능성을 확인합니다. 두 표현 간의 거리는 이러한 연결 가능성에 대한 프록시의 역할을 할 수 있습니다.
IP Insights 알고리즘은 신경망을 사용하여 엔터티 및 IP 주소에 대한 잠재 벡터 표현을 학습합니다. 엔터티는 먼저 크지만 고정된 해시 공간으로 해시되 후 간단한 임베딩 계층에 의해 인코딩됩니다. 사용자 이름 또는 계정 ID 등과 같은 문자열은 로그 파일에 나타날 때 IP Insights에 직접 제공할 수 있습니다. 엔터티 식별자에 대한 데이터는 사전 처리할 필요가 없습니다. 훈련 및 추론 중 엔터티를 임의 문자열로 제공할 수 있습니다. 해시 크기는 별개의 여러 엔터티가 동일한 잠재 벡터로 매핑되는 경우 발행하는 충돌 횟수가 미미하게 유지될 수 있도록 충분히 큰 값으로 구성되어야 합니다. 적절한 해시 크기를 선택하는 방법에 대한 자세한 정보는 Feature Hashing for Large Scale Multitask Learning
훈련 중 IP Insights는 엔터티와 IP 주소를 무작위로 연결하여 네거티브 샘플을 자동으로 생성합니다. 이러한 네거티브 샘플은 실제 발생할 가능성이 낮은 데이터를 나타냅니다. 이 모델은 훈련 데이터에서 관측되는 포지티브 샘플과 이처럼 생성된 네거티브 샘플을 구분하도록 훈련됩니다. 보다 구체적으로 설명하자면, 모델은 다음과 같이 정의되는 크로스 엔트로피(로그 손실이라고도 함)를 최소화하도록 훈련되었습니다.
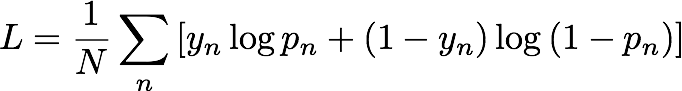
yn은 샘플을 관측 데이터를 관리하는 실제 분포에서 가져왔는지(ynn=1) 아니면 네거티브 샘플을 생성하는 분포에서 가져왔는지(yn=0) 여부를 나타내는 레이블입니다. pn은 모델이 예측한 대로 샘플을 실제 분포에서 가져올 확률입니다.
네거티브 샘플 생성은 관측 데이터의 정확한 모델을 얻기 위해 사용되는 중요한 프로세스입니다. 네거티브 샘플이 발생할 가능성이 매우 낮은 경우 예를 들어, 네거티브 샘플 내 모든 IP 주소가 10.0.0.0인 경우 이 모델은 네거티브 샘플을 구분하도록 제대로 학습하지 못하고, 실제 관측 데이터 세트의 특성을 정확하게 정의하지 못합니다. 네거티브 샘플을 보다 현실적으로 유지하기 위해 IP Insights는 IP 주소를 무작위로 생성하고 훈련 데이터에서 IP 주소를 임의로 선택하는 두 가지 방법을 모두 사용해 네거티브 샘플을 생성합니다. random_negative_sampling_rate 및 shuffled_negative_sampling_rate 하이퍼파라미터를 사용하여 네거티브 샘플링 유형과 네거티브 샘플 생성 속도를 구성할 수 있습니다.
n번째(엔터티, IP 주소 페어)를 고려했을 때, IP Insights 모델은 엔터티가 IP 주소와 호환되는 정도를 나타내는 점수, Sn을 출력합니다. 이 점수는 네거티브 분포에서 가져온 (엔터티, IP 주소) 대비 실제 분포에서 가져온 페어의 주어진 (엔터티, IP 주소)의 로그 승산비에 해당합니다. 다음과 같이 정의됩니다.
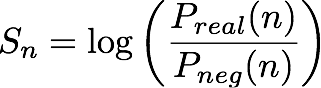
이 점수는 n 번째 엔터티 및 IP 주소의 벡터 표시 간 유사성을 측정한 값입니다. 이 값은 이러한 이벤트가 무작위로 생성된 데이터 세트에서 관측된 것에 비해 실제로 관측될 가능성으로 해석될 수 있습니다. 훈련 중 이 알고리즘은 이 점수를 사용하여 실제 분포 pn에서 가져온 샘플의 확률에 대한 예측치를 계산하여 교차 엔트로피 최소화에 사용합니다. 공식은 다음과 같습니다.