기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터세트에 액세스하기 위한 훈련 작업 설정
훈련 작업을 생성할 때 선택한 데이터 스토리지의 훈련 데이터세트 위치와 작업에 대한 데이터 입력 모드를 지정합니다. Amazon SageMaker AI는 Amazon Simple Storage Service(Amazon S3), Amazon Elastic File System(Amazon EFS), Amazon FSx for Lustre를 지원합니다. 입력 모드는 훈련 작업 시작 시 데이터세트의 데이터 파일을 실시간으로 스트리밍할지 아니면 전체 데이터세트를 다운로드할지를 결정합니다.
참고
데이터 세트는 훈련 작업 AWS 리전 과 동일한에 있어야 합니다.
SageMaker AI 입력 모드 및 AWS 클라우드 스토리지 옵션
이 섹션에서는 Amazon EFS 및 Amazon FSx for Lustre에 저장된 데이터에 대해 SageMaker에서 지원하는 파일 입력 모드의 개요를 제공합니다.
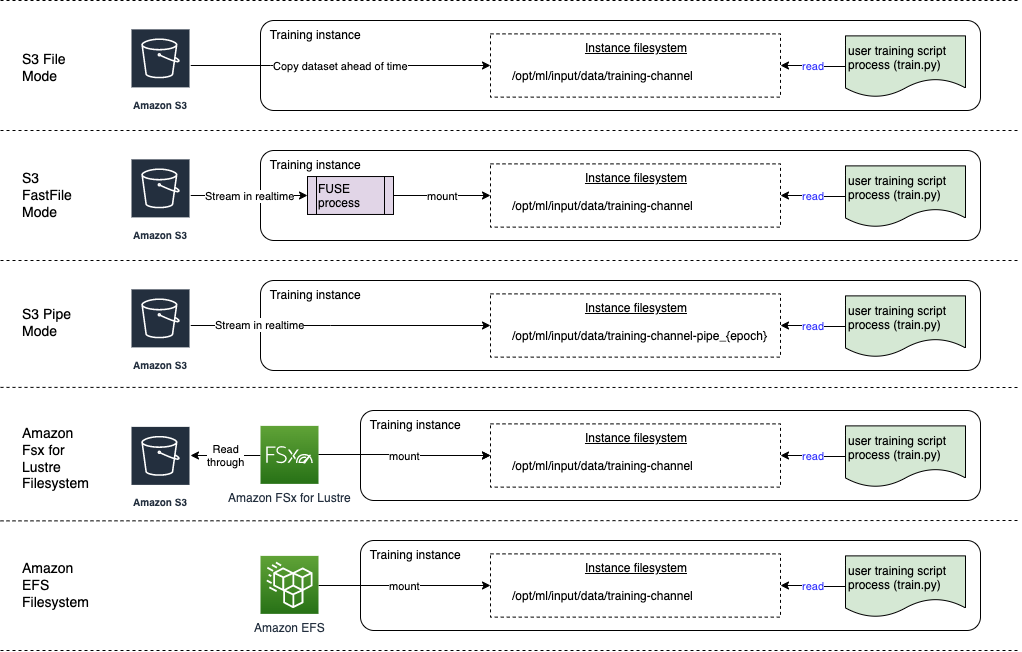
-
파일 모드는 데이터세트의 파일 시스템 보기를 훈련 컨테이너에 제공합니다. 다른 두 옵션 중 하나를 명시적으로 지정하지 않는 경우 이 모드가 기본 입력 모드입니다. 파일 모드를 사용하는 경우 SageMaker AI는 저장 위치의 훈련 데이터를 Docker 컨테이너의 로컬 디렉터리로 다운로드합니다. 전체 데이터세트를 다운로드한 후 훈련이 시작됩니다. 파일 모드에서는 훈련 인스턴스에 전체 데이터세트를 담을 수 있는 충분한 저장 공간이 있어야 합니다. 파일 모드 다운로드 속도는 데이터세트 크기, 평균 파일 크기, 파일 수에 따라 달라집니다. Amazon S3 접두사, 매니페스트 파일 또는 증강 매니페스트 파일을 제공하여 파일 모드에 맞게 데이터세트를 구성할 수 있습니다. 모든 데이터세트 파일이 공통 S3 접두사 안에 있는 경우 S3 접두사를 사용해야 합니다. 파일 모드는 SageMaker AI 로컬 모드
(SageMaker 훈련 컨테이너를 몇 초 만에 대화식으로 시작)와 호환됩니다. 분산 훈련의 경우 ShardedByS3Key옵션을 사용하여 여러 인스턴스에서 데이터세트를 샤드할 수 있습니다. -
고속 파일 모드는 파이프 모드의 성능 이점을 활용하면서 Amazon S3 데이터 소스에 대한 파일 시스템 액세스를 제공합니다. 훈련 시작 시 고속 파일 모드는 데이터 파일을 식별하지만 다운로드하지는 않습니다. 전체 데이터세트가 다운로드될 때까지 기다릴 필요 없이 훈련을 시작할 수 있습니다. 즉, 제공된 Amazon S3 접두사에 파일 수가 적으면 훈련 시작 스타트업이 줄어듭니다.
파이프 모드와 달리 고속 파일 모드는 데이터에 대해 임의로 액세스할 수 있습니다. 하지만 데이터를 순차적으로 읽을 때 가장 효과적입니다. 고속 파일 모드에서는 증강 매니페스트 파일을 지원하지 않습니다.
고속 파일 모드에서는 마치 훈련 인스턴스의 로컬 디스크에서 파일을 사용할 수 있는 것처럼 POSIX 호환 파일 시스템 인터페이스를 사용하여 S3 객체를 노출합니다. 훈련 스크립트가 데이터를 소비할 때 온디맨드 방식으로 S3 콘텐츠를 스트리밍합니다. 즉, 더 이상 데이터세트 전체를 훈련 인스턴스 스토리지 공간에 담을 필요가 없으며, 훈련 시작 전에 데이터세트가 훈련 인스턴스로 다운로드될 때까지 기다릴 필요가 없습니다. 고속 파일은 현재 S3 접두사만 지원합니다 (매니페스트 및 증강 매니페스트는 지원하지 않음). 고속 파일 모드는 SageMaker AI 로컬 모드와 호환됩니다.
참고
고속 파일 모드를 사용하면 다음과 같이 추가 로깅으로 인해 CloudTrail 비용이 증가할 수 있습니다.
-
Amazon S3 데이터 이벤트(CloudTrail을 사용하는 경우)
-
AWS KMS 키로 AWS KMS 암호화된 Amazon S3 객체에 액세스할 때의 복호화 이벤트입니다.
-
AWS KMS 작업과 관련된 관리 이벤트입니다.
이러한 이벤트 유형에서 CloudTrail 로깅을 사용하는 경우 CloudTrail 구성 및 모니터링 비용을 검토합니다.
-
-
파이프 모드는 Amazon S3 데이터 소스에서 직접 데이터를 스트리밍합니다. 스트리밍은 파일 모드보다 시작 시간이 더 빠르고 처리량이 더 높습니다.
데이터를 직접 스트리밍하면 훈련 인스턴스에서 사용하는 Amazon EBS 볼륨의 크기를 줄일 수 있습니다. 파이프 모드에서는 최종 모델 아티팩트를 저장하는 데 충분한 디스크 공간만 필요합니다.
이 모드는 새롭고 사용이 더 간편한 고속 파일 모드로 대부분 대체된 또 다른 스트리밍 모드입니다. 파이프 모드에서는 Amazon S3에서 높은 동시성과 처리량으로 데이터를 미리 가져와서 명명된 파이프로 스트리밍합니다. 이는 해당 동작 때문에 First-In-First-Out (FIFO) 파이프라고도 합니다. 각 파이프는 단일 프로세스에서만 읽을 수 있습니다. SageMaker AI의 TensorFlow 전용 확장 프로그램은 텍스트, TFRecords 또는 RecordIO 파일 형식을 스트리밍하기 위해 파이프 모드를 네이티브 TensorFlow 데이터 로더
에 편리하게 통합합니다. 파이프 모드는 관리형 데이터 샤딩 및 셔플링도 지원합니다. -
Amazon S3 Express One Zone은 SageMaker 모델 학습 등 지연 시간에 민감한 애플리케이션에 한 자릿수 밀리초 단위의 일관된 데이터 액세스를 제공할 수 있는 고성능의 단일 가용성 영역 스토리지 클래스입니다. Amazon S3 Express One Zone을 사용하면 단일 AWS 가용 영역에서 객체 스토리지 및 컴퓨팅 리소스를 공동 배치하여 데이터 처리 속도를 높여 컴퓨팅 성능과 비용을 모두 최적화할 수 있습니다. 액세스 속도를 더욱 높이고 초당 수십만 건의 요청을 지원하기 위해 데이터는 새로운 버킷 유형인 Amazon S3 디렉터리 버킷에 저장됩니다.
SageMaker AI 모델 훈련은 고성능 Amazon S3 Express One Zone 디렉터리 버킷을 파일 모드, 고속 파일 모드 및 파이프 모드의 데이터 입력 위치로 지원합니다. Amazon S3 Express One Zone을 사용하려면 Amazon S3 버킷 대신 Amazon S3 Express One Zone 디렉터리 버킷의 위치를 입력합니다. 필요한 액세스 제어 및 권한 정책을 IAM 역할에 대한 ARN에 제공합니다. 자세한 내용은 AmazonSageMakerFullAccesspolicy를 참조하세요. Amazon S3 관리형 키(SSE-S3)를 사용한 서버 측 암호화를 통해서만 디렉터리 버킷에서 SageMaker AI 출력 데이터를 암호화할 수 있습니다. AWS KMS 키를 사용한 서버 측 암호화(SSE-KMS)는 현재 SageMaker AI 출력 데이터를 디렉터리 버킷에 저장하는 데 지원되지 않습니다. 자세한 내용은 Amazon S3 Express One Zone을 참조하세요.
-
Amazon FSx for Lustre - FSx for Lustre는 지연 시간이 짧고 수백 기가바이트의 처리량과 수백만 IOPS까지 확장할 수 있습니다. 훈련 작업을 시작할 때 SageMaker AI는 FSx for Lustre 파일 시스템을 훈련 인스턴스 파일 시스템에 마운트한 다음 훈련 스크립트를 시작합니다. 마운트 자체는 FSx for Lustre에 저장된 데이터세트의 크기에 영향을 받지 않는 비교적 빠른 작업입니다.
FSx for Lustre에 액세스하려면 훈련 작업을 Amazon Virtual Private Cloud(VPC)에 연결해야 하며, 이를 위해서는 DevOps 설정 및 참여가 필요합니다. 데이터 전송 비용을 피하기 위해 파일 시스템은 단일 Availability Zone(가용 영역)을 사용하며, 훈련 작업을 실행할 때 이 Availability Zone ID에 매핑되는 VPC 서브넷을 지정해야 합니다.
-
Amazon EFS- Amazon EFS를 데이터 소스로 사용하려면 훈련 전에 데이터가 이미 Amazon EFS에 있어야 합니다. SageMaker AI는 지정된 Amazon EFS 파일 시스템을 훈련 인스턴스에 마운트한 다음 훈련 스크립트를 시작합니다. Amazon EFS에 액세스하려면 훈련 작업을 VPC에 연결해야 합니다.
작은 정보
VPC 구성을 SageMaker AI 예측기에 지정하는 방법에 대해 자세히 알아보려면 SageMaker AI Python SDK 설명서에 나와 있는 Use File Systems as Training Inputs
를 참조하세요.
