기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
모델 파이프라이닝
SageMaker의 모델 병렬 처리 라이브러리의 핵심 기능 중 하나는 파이프라인 병렬 처리로 이는 모델 훈련 중에 디바이스 전반에서 계산을 수행하고 데이터를 처리하는 순서를 결정합니다. 파이프라이닝은 GPU가 서로 다른 데이터 샘플에서 동시에 계산을 수행하도록 함으로써 모델 병렬 처리의 진정한 병렬화를 달성하고 순차 계산으로 인한 성능 손실을 극복하는 기법입니다. 파이프라인 병렬 처리를 사용하여 마이크로배치를 통해 파이프라인 방식으로 훈련 작업을 실행하고 GPU 사용을 극대화할 수 있습니다.
참고
모델 분할이라고도 하는 파이프라인 병렬 처리는 PyTorch와 TensorFlow 모두에서 사용할 수 있습니다. 지원되는 프레임워크 버전은 지원되는 프레임워크 및 AWS 리전을 참조하세요.
파이프라인 실행 일정
파이프라이닝은 미니 배치를 마이크로배치로 분할하는 것을 기반으로 하며 이는 훈련 파이프라인에 하나씩 공급되며 라이브러리 런타임에서 정의한 실행 일정을 따릅니다. 마이크로배치는 주어진 훈련용 미니 배치의 더 작은 서브셋입니다. 파이프라인 일정에 따라 각 타임슬롯에 대해 어떤 디바이스가 어떤 마이크로배치를 실행할지 결정됩니다.
예를 들어 파이프라인 일정과 모델 파티션에 따라 GPU i는 마이크로배치 b에서 계산을 수행(순방향 또는 역방향)하는 반면 GPU i+1은 마이크로배치 b+1에서 계산을 수행하여 두 GPU를 동시에 활성 상태로 유지할 수 있습니다. 단일 순방향 또는 역방향 패스 중에 분할 결정에 따라 단일 마이크로배치의 실행 흐름이 동일 디바이스를 여러 번 방문할 수 있습니다. 예를 들어 모델의 시작 부분에 있는 작업은 모델 종료 시 작업과 동일한 디바이스에 배치되는 반면, 그 사이의 작업은 서로 다른 디바이스에서 수행되므로 이 디바이스를 두 번 방문하게 됩니다.
라이브러리는 SageMaker Python SDK의 pipeline 파라미터를 사용하여 구성할 수 있는 두 가지 파이프라인 일정, 즉 단순 및 인터리브를 제공합니다. 대부분의 경우 인터리브 파이프라인은 GPU를 더 효율적으로 활용하여 성능이 더 높습니다.
인터리브 파이프라인
인터리브 파이프라인에서는 가능하면 마이크로배치의 역방향 실행이 우선시됩니다. 이를 통해 활성화에 사용된 메모리를 더 빨리 릴리스하고 메모리를 더 효율적으로 사용할 수 있습니다. 또한 마이크로배치 수를 늘려 GPU의 유휴 시간을 줄일 수 있습니다. 안정 상태에서는 각 디바이스가 순방향 패스 및 역방향 패스를 번갈아 가며 실행합니다. 즉, 한 마이크로배치의 역방향 패스가 다른 마이크로배치의 순방향 패스가 완료되기 전에 실행될 수 있습니다.

위 그림은 2개의 GPU에서 인터리브 파이프라인의 실행 일정 예제를 보여줍니다. 그림에서 F0은 마이크로배치 0의 순방향 패스를 나타내고 B1은 마이크로배치 1의 역방향 패스를 나타냅니다. 업데이트는 파라미터의 옵티마이저 업데이트를 나타냅니다. GPU0은 가능할 때마다 항상 역방향 패스의 우선 순위를 지정합니다(예: F2보다 B0을 먼저 실행). 이렇게 하면 이전에 활성화에 사용된 메모리를 지울 수 있습니다.
단순 파이프라인
이와 대조적으로 단순 파이프라인은 역방향 패스를 시작하기 전에 각 마이크로배치에 대한 순방향 패스 실행을 완료합니다. 즉, 순방향 패스와 역방향 패스 스테이지를 스테이지 안에서만 파이프라이닝합니다. 다음 그림은 GPU를 2개 이상 사용했을 때 작동 방식을 보여주는 예시입니다.

특정 프레임워크에서의 파이프라이닝 실행
다음 섹션을 사용하여 SageMaker의 모델 병렬 처리 라이브러리가 TensorFlow 및 PyTorch를 위해 실시하는 프레임워크별 파이프라인 일정 예약 결정에 대해 알아보세요.
TensorFlow를 사용한 파이프라인 실행
다음 이미지는 자동 모델 분할을 사용하여 모델 병렬 처리 라이브러리로 분할된 TensorFlow 그래프의 예입니다. 그래프를 분할하면 결과로 생성되는 각 하위 그래프가 B회 복제됩니다(변수 제외). 여기서 B는 마이크로배치의 수입니다. 이 그림에서는 각 하위 그래프가 2번 복제됩니다(B=2). 하위 그래프의 각 입력에 SMPInput 연산이 삽입되고 각 출력에 SMPOutput 연산이 삽입됩니다. 이러한 연산은 라이브러리 백엔드와 통신하여 텐서를 서로 주고받습니다.

다음 이미지는 그라디언트 연산이 추가되고 B=2로 분할된 하위 그래프 2개의 예입니다. SMPInput 연산의 기울기는 SMPOutput 연산이고 그 반대의 경우도 마찬가지입니다. 이렇게 하면 역전파 중에 그라디언트가 역방향으로 흐를 수 있습니다.
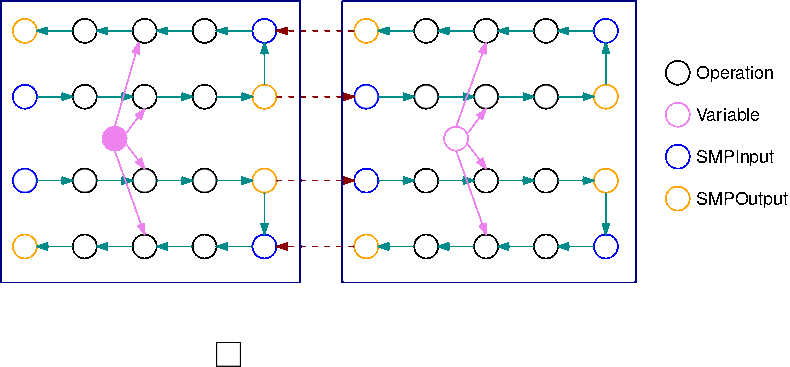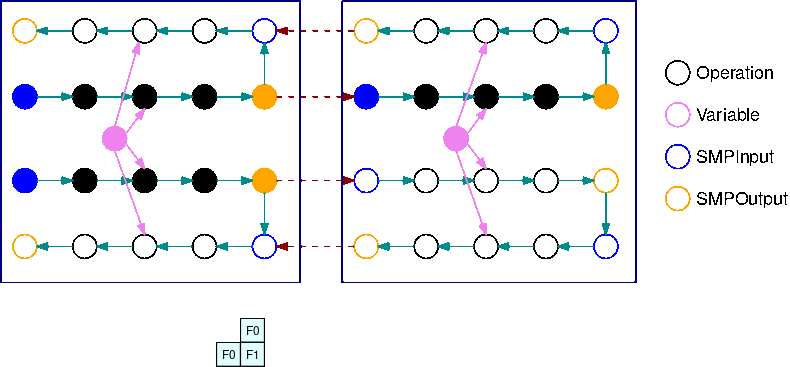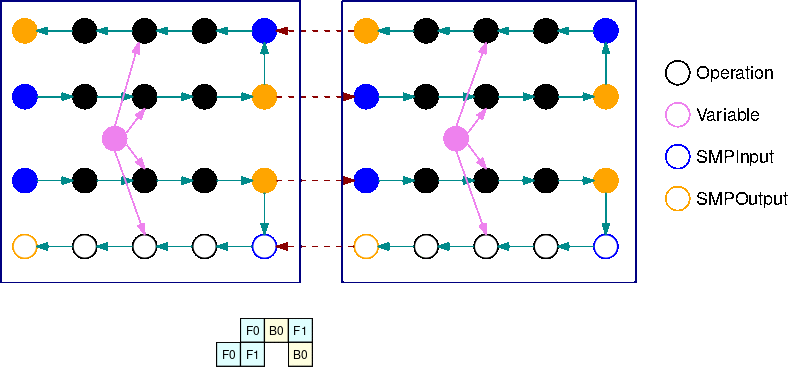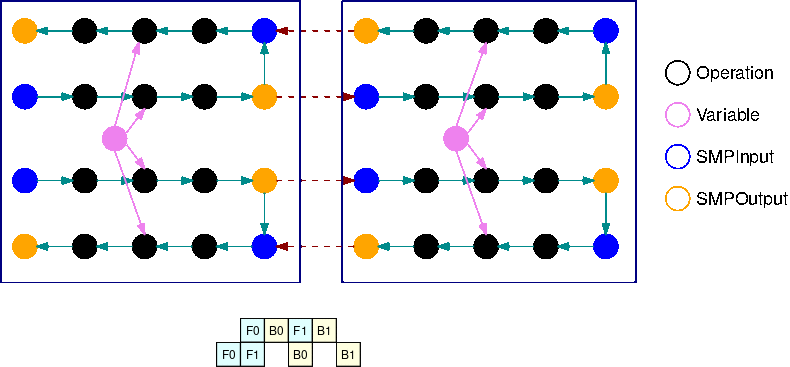
이 GIF는 B=2 마이크로배치와 2개의 하위 그래프를 포함하는 인터리브 파이프라인 실행 일정의 예를 보여줍니다. 각 디바이스는 하위 그래프 복제본 중 하나를 순차적으로 실행하여 GPU 활용도를 높입니다. B가 커질수록 유휴 시간 슬롯의 비율은 0에 가까워집니다. 특정 하위 그래프 복제본에서 순방향 또는 역방향 계산을 수행할 때가 되면 파이프라인 계층이 해당하는 파란색 SMPInput 작업에 신호를 보내 실행을 시작합니다.
단일 미니 배치에 있는 모든 마이크로배치의 그라디언트가 계산되면 라이브러리는 마이크로배치의 그라디언트를 결합하여 파라미터에 적용합니다.
PyTorch를 사용한 파이프라인 실행
개념적으로 파이프라이닝은 PyTorch와 유사한 아이디어를 따릅니다. 그러나 PyTorch는 정적 그래프를 포함하지 않으므로 모델 병렬 처리 라이브러리의 PyTorch 기능은 더 동적인 파이프라이닝 패러다임을 사용합니다.
TensorFlow에서와 같이 각 배치는 여러 개의 마이크로배치로 분할되며 각 마이크로배치는 각 디바이스에서 한 번에 하나씩 실행됩니다. 하지만 실행 일정은 각 디바이스에서 실행되는 실행 서버를 통해 처리됩니다. 다른 디바이스에 배치된 하위 모듈의 출력이 현재 디바이스에 필요할 때마다 실행 요청이 하위 모듈에 대한 입력 텐서와 함께 원격 디바이스의 실행 서버로 전송됩니다. 그러면 서버는 주어진 입력으로 이 모듈을 실행하고 현재 디바이스에 응답을 반환합니다.
원격 하위 모듈 실행 중에는 현재 디바이스가 유휴 상태이므로 현재 마이크로배치의 로컬 실행이 일시 중지되고 라이브러리 런타임은 현재 디바이스가 적극적으로 작업할 수 있는 다른 마이크로배치로 실행을 전환합니다. 마이크로배치의 우선순위는 선택한 파이프라인 일정에 따라 결정됩니다. 인터리브 파이프라인 일정의 경우 가능하면 계산의 역방향 스테이지에 있는 마이크로배치를 우선 순위로 지정합니다.
