기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
파이프라인 병렬 처리와 텐서 병렬 처리를 조합하여 사용할 때의 랭킹 매커니즘
이 섹션에서는 모델 병렬 처리의 랭킹 매커니즘이 텐서 병렬 처리에서 작동하는 방식을 설명합니다. 이 내용은 SageMaker 모델 병렬화 라이브러리의 핵심 기능용 랭킹 기본 사항smp.tp_rank() 텐서 병렬 랭크, smp.pp_rank() 파이프라인 병렬 랭크, smp.rdp_rank() 축소 데이터 병렬 랭크 등 세 가지 유형의 순위 및 프로세스 그룹을 APIs 도입합니다. 해당 통신 프로세스 그룹은 텐서 병렬 그룹(TP_GROUP), 파이프라인 병렬 그룹(PP_GROUP) 및 축소 데이터 병렬 그룹(RDP_GROUP)입니다. 이 그룹은 다음과 같이 정의됩니다.
-
텐서 병렬 그룹(
TP_GROUP)은 모듈의 텐서 병렬 분산이 발생하는 데이터 병렬 그룹의 균등 분할 가능한 서브셋입니다. 파이프라인 병렬도가 1인 경우TP_GROUP은 모델 병렬 그룹(MP_GROUP)과 동일합니다. -
파이프라인 병렬 그룹(
PP_GROUP)은 파이프라인 병렬 처리가 발생하는 프로세스 그룹입니다. 텐서 병렬도가 1인 경우PP_GROUP은MP_GROUP과 동일합니다. -
reduced-data parallel group(
RDP_GROUP)은 동일한 파이프라인 병렬 처리 파티션과 동일한 텐서 병렬 파티션을 모두 보유하고 그 사이의 데이터 병렬 처리를 수행하는 일련의 프로세스입니다. 이 그룹은 전체 데이터 병렬 처리 그룹DP_GROUP의 하위 집합이기 때문에 축소된 데이터 병렬 그룹이라고 합니다.TP_GROUP에 분포된 모델 파라미터의 경우 그라디언트allreduce연산은 감소 데이터 병렬 그룹에 대해서만 수행되고 분포되지 않은 파라미터의 경우 그라디언트allreduce연산이 전체DP_GROUP에 걸쳐 이루어집니다. -
모델 병렬 그룹(
MP_GROUP)은 전체 모델을 집합적으로 저장하는 프로세스 그룹을 나타냅니다. 이는 현재 프로세스의TP_GROUP에 속한 모든 순위의PP_GROUP을 합친 것으로 구성됩니다. 텐서 병렬도가 1인 경우MP_GROUP은PP_GROUP과 같습니다. 이전smdistributed릴리스의 기존 정의인MP_GROUP과도 일치합니다. 현재TP_GROUP은 현재DP_GROUP및 현재MP_GROUP모두의 서브셋입니다.
SageMaker 모델 병렬 처리 라이브러리의 통신 프로세스에 APIs 대한 자세한 내용은 Python SageMaker 설명서의 Common API
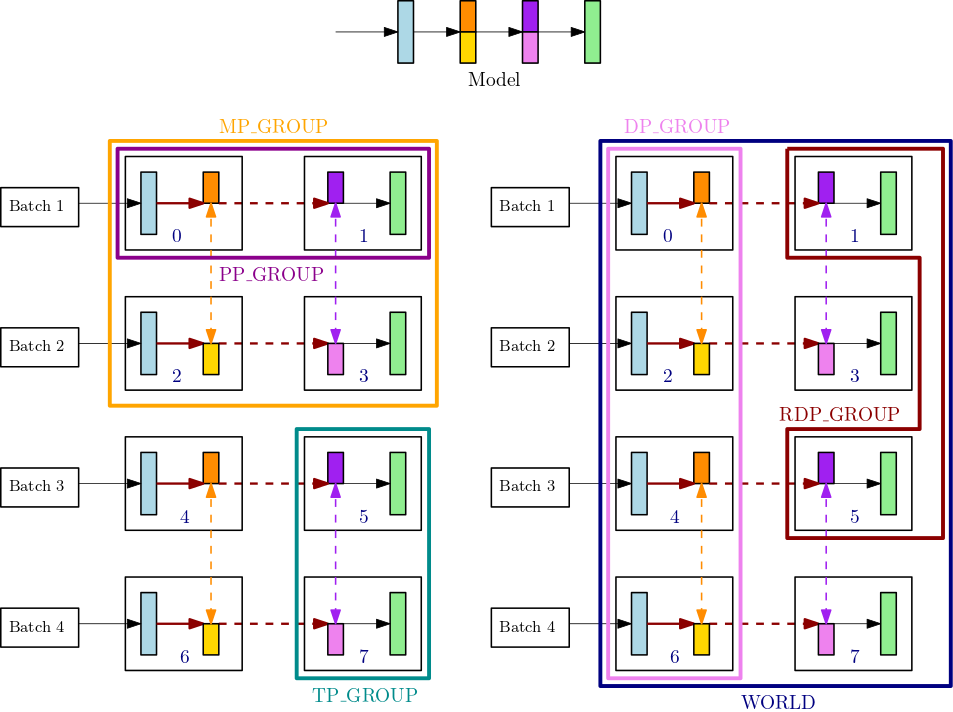
예를 들어 텐서 병렬도는 2이고 파이프라인 병렬도는 2이고 데이터 병렬도는 4인 단일 노드의 프로세스 그룹을 예로 들어 보겠습니다. GPUs 이전 그림의 가운데 위쪽 부분은 계층이 4개인 모델의 예를 보여줍니다. 그림의 왼쪽 하단과 오른쪽 하단은 파이프라인 병렬성과 텐서 병렬성을 모두 GPUs 사용하여 4계층에 분산된 4계층 모델을 보여줍니다. 여기서 텐서 병렬성은 가운데 두 레이어에 사용됩니다. 아래 두 그림은 서로 다른 그룹 경계선을 나타낸 단순 사본입니다. 분할된 모델은 0-3 및 4-7의 데이터 병렬화를 위해 복제됩니다. GPUs 왼쪽 아래 그림에는 MP_GROUP, PP_GROUP 및 TP_GROUP의 정의가 있습니다. 오른쪽 아래 그림은 같은 세트에 대한RDP_GROUP,DP_GROUP, 를 WORLD 보여줍니다. GPUs 색상이 동일한 레이어 및 레이어 슬라이스의 그라디언트는 데이터 병렬 처리를 위해 함께 allreduce됩니다. 예를 들어 첫 번째 레이어(연한 파란색)는 DP_GROUP에서 allreduce 작업을 처리하지만 두 번째 레이어의 짙은 주황색 슬라이스는 프로세스의 RDP_GROUP 내에서만 allreduce 작업을 수행합니다. 굵은 진한 빨간색 화살표는 전체 TP_GROUP 배치가 포함된 텐서를 나타냅니다.
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
이 예제에서 파이프라인 병렬화는 (0,1), (2,3), (4,5), (6,7) GPU 쌍에서 발생합니다. 또한 데이터 병렬화 (allreduce) 는 GPUs 0, 2, 4, 6에서 발생하고 1, 3, 5, 7에서는 독립적으로 발생합니다. GPUs 텐서 병렬 처리는 DP_GROUP s의 하위 집합에서 (0,2), (1,3), (4,6), (5,7) GPU 쌍에서 발생합니다.
