기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon CloudWatch의 Amazon SageMaker AI 지표
원시 데이터를 수집하여 읽기 가능하며 실시간에 가까운 지표로 처리하는 Amazon CloudWatch를 사용해 Amazon SageMaker AI를 모니터링할 수 있습니다. 이러한 통계는 15개월 동안 유지됩니다. 기록 정보에 액세스하고 웹 애플리케이션 또는 서비스가 어떻게 실행되고 있는지 전체적으로 더 잘 파악할 수 있습니다. 하지만 Amazon CloudWatch 콘솔은 지난 2주 이내에 업데이트된 지표로 검색을 제한합니다. 이 제한은 가장 최신 작업이 네임스페이스에 표시되도록 보장합니다.
검색을 사용하지 않고 지표를 그래프로 표시하려면 소스 보기에서 지표의 정확한 이름을 지정합니다. 특정 임계값을 주시하다가 해당 임계값이 충족될 때 알림을 전송하거나 조치를 취하도록 경보를 설정할 수도 있습니다. 자세한 내용은 Amazon CloudWatch 사용 설명서를 참조하세요.
SageMaker AI 지표 및 차원
SageMaker AI 엔드포인트 지표
/aws/sagemaker/Endpoints 네임스페이스에는 엔드포인트 인스턴스에 대한 다음 지표가 포함됩니다.
지표는 1분 간격으로 제공됩니다. MetricsConfig에서를 설정하여 게시 빈도를 MetricPublishFrequencyInSeconds 10, 30, 60, 120, 180, 240 또는 300초로 구성할 수 있습니다. 이 설정은 활성화EnableEnhancedMetrics할 필요가 없습니다. 를 EnableEnhancedMetrics로 설정하면 True추가 차원 InstanceId 및 AcceleratorId (GPU 지표만 해당)를 사용할 수 있습니다. 자세한 내용은 추론 엔드포인트에 대한 Amazon SageMaker AI 향상된 지표 단원을 참조하십시오.
참고
Amazon CloudWatch는 고해상도 사용자 지정 지표를 지원하며, 최상의 해상도는 1초입니다. 그러나 해상도가 높을수록 CloudWatch 지표의 수명이 짧아집니다. 1초 주파수 해상도의 경우 CloudWatch 지표는 3시간 동안 사용할 수 있습니다. CloudWatch 지표의 해상도와 수명에 대한 자세한 내용은 Amazon CloudWatch API 참조의 GetMetricStatistics를 참조하세요.
| 지표 | 설명 |
|---|---|
CPUReservation |
인스턴스의 컨테이너에서 예약한 CPUs의 합계입니다. 이 지표는 활성 추론 구성 요소를 호스팅하는 엔드포인트에만 제공됩니다. 값 범위는 0%~100%입니다. 추론 구성 요소에 대한 설정에서 |
CPUUtilization |
각 개별 CPU 코어 사용률의 합계. 각 코어 범위의 CPU 사용률은 0–100입니다. 예를 들어 CPU가 4개인 경우 엔드포인트 변환의 경우 이 값은 인스턴스에 있는 기본 및 보조 컨테이너의 CPU 사용률 총합입니다. 단위: 백분율 |
CPUUtilizationNormalized |
각 개별 CPU 코어 사용률의 명목 합계. 이 지표는 활성 추론 구성 요소를 호스팅하는 엔드포인트에만 제공됩니다. 값 범위는 0%~100%입니다. 예를 들어 CPUs가 4개이고 지표가 |
DiskUtilization |
인스턴스의 컨테이너에서 사용하는 디스크 공간의 비율입니다. 이 값 범위는 0%~100%입니다. 엔드포인트 변환의 경우 이 값은 인스턴스에 있는 기본 및 보조 컨테이너의 디스크 공간 사용률 합계입니다.단위: 백분율 |
GPUMemoryUtilization |
인스턴스의 컨테이너에서 사용하는 GPU 메모리의 비율(%)입니다. 값 범위는 0~100이고, GPU의 수를 곱합니다. 예를 들어 GPU가 4개인 경우 엔드포인트 변환의 경우 이 값은 인스턴스에 있는 기본 및 보조 컨테이너의 GPU 메모리 사용률 총합입니다. 단위: 백분율 |
GPUMemoryUtilizationNormalized |
인스턴스의 컨테이너에서 사용하는 GPU 메모리의 비율(%)입니다. 이 지표는 활성 추론 구성 요소를 호스팅하는 엔드포인트에만 제공됩니다. 값 범위는 0%~100%입니다. 예를 들어 GPUs가 4개이고 |
GPUReservation |
인스턴스의 컨테이너에서 예약한 GPU의 합계입니다. 이 지표는 활성 추론 구성 요소를 호스팅하는 엔드포인트에만 제공됩니다. 값 범위는 0%~100%입니다. 추론 구성 요소에 대한 설정에서 GPU 예약을 |
GPUUtilization |
인스턴스의 컨테이너에서 사용하는 GPU 유닛의 비율(%)입니다. 값은 0~100 사이가 될 수 있고, GPU의 수를 곱합니다. 예를 들어 GPU가 4개인 경우 엔드포인트 변환의 경우 이 값은 인스턴스에 있는 기본 및 보조 컨테이너의 GPU 사용률 총합입니다. 단위: 백분율 |
GPUUtilizationNormalized |
인스턴스의 컨테이너에서 사용하는 GPU 유닛의 명목 비율(%)입니다. 이 지표는 활성 추론 구성 요소를 호스팅하는 엔드포인트에만 제공됩니다. 값 범위는 0%~100%입니다. 예를 들어 GPU가 4개 GPUs 이고 |
MemoryReservation |
인스턴스의 컨테이너에서 예약한 메모리의 합계입니다. 이 지표는 활성 추론 구성 요소를 호스팅하는 엔드포인트에만 제공됩니다. 값 범위는 0%~100%입니다. 추론 구성 요소의 설정에서 |
MemoryUtilization |
인스턴스의 컨테이너에서 사용하는 메모리의 비율(%)입니다. 이 값 범위는 0%~100%입니다. 엔드포인트 변환의 경우 이 값은 인스턴스에 있는 기본 및 보조 컨테이너의 메모리 사용률 총합입니다. 단위: 백분율 |
| 차원 | 설명 |
|---|---|
EndpointName, VariantName |
지정된 엔드포인트 및 변형 |
EndpointName, VariantName, InstanceType |
인스턴스 풀을 사용하는 프로덕션 변형의 인스턴스 유형별로 엔드포인트 지표를 필터링합니다. 이 차원을 사용하여 변형 내의 각 인스턴스 유형에 대한 지표를 개별적으로 모니터링합니다. |
InstanceId |
특정 인스턴스에 대한 엔드포인트 지표를 필터링합니다. |
AcceleratorId |
(GPU 지표만 해당) 특정 GPU에 대한 엔드포인트 지표를 필터링합니다. |
SageMaker AI 엔드포인트 간접 호출 지표
AWS/SageMaker 네임스페이스에는 InvokeEndpoint 호출에 대한 다음과 같은 요청 지표가 포함되어 있습니다.
지표는 1분 간격으로 제공됩니다. MetricsConfig에서를 설정하여 게시 빈도를 MetricPublishFrequencyInSeconds 10, 30, 60, 120, 180, 240 또는 300초로 구성할 수 있습니다. 호출 지표EnableEnhancedMetrics의 경우이 설정을 로 설정해야 합니다True. 를 EnableEnhancedMetrics로 설정하면 True추가 차원 InstanceId 및 ContainerId (추론 구성 요소만 해당)도 사용할 수 있습니다. 자세한 내용은 추론 엔드포인트에 대한 Amazon SageMaker AI 향상된 지표 단원을 참조하십시오.
다음 그림은 SageMaker AI 엔드포인트가 Amazon SageMaker 런타임 API와 상호 작용하는 방식을 보여줍니다. 엔드포인트로 요청을 보내고 응답을 받는 데 걸리는 전체 시간은 다음 세 가지 구성 요소에 따라 달라집니다.
-
네트워크 지연 시간(Network latency) - SageMaker 런타임 API에 요청을 보내고 SageMaker 런타임 API로부터 응답을 받는 데 걸리는 시간입니다.
-
오버헤드 지연 시간(Overhead latency) - 모델 컨테이너로 요청을 전송하고 응답을 SageMaker 런타임 런타임 API로 다시 전송하는 데 걸리는 시간입니다.
-
모델 지연 시간(Model latency) - 모델 컨테이너가 요청을 처리하고 응답을 반환하는 데 걸리는 시간입니다.
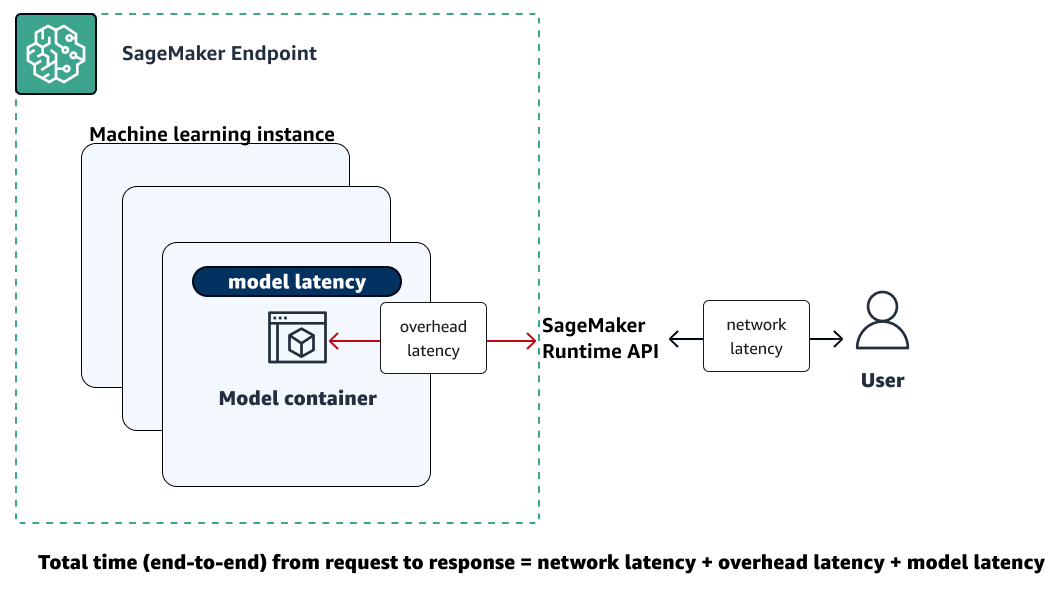
총 지연 시간에 대한 자세한 내용은 Best practices for load testing Amazon SageMaker AI real-time inference endpoints
| 지표 | 설명 |
|---|---|
ConcurrentRequestsPerCopy |
추론 구성 요소의 각 복사본으로 정규화된 추론 구성 요소가 수신한 동시 요청 수입니다. 유효한 통계: Min, Max |
ConcurrentRequestsPerModel |
모델에서 수신 중인 동시 요청 수입니다. 유효한 통계: Min, Max |
Invocation4XXErrors |
모델이 4xx HTTP 응답 코드를 반환하는 단위: 없음 유효한 통계: Average, Sum |
Invocation5XXErrors |
모델이 5xx HTTP 응답 코드를 반환하는 단위: 없음 유효한 통계: Average, Sum |
InvocationModelErrors |
2XX HTTP 응답으로 이어지지 않은 모델 호출 요청 수. 여기에는 4XX/5XX 상태 코드, 저수준 소켓 오류, 잘못된 HTTP 응답 및 요청 제한 시간이 포함됩니다. 각 오류 응답에 대해 1이 전송되고, 그 외의 경우에는 0이 전송됩니다. 단위: 없음 유효한 통계: Average, Sum |
Invocations |
모델 엔드포인트에 전송된 모델 엔드포인트에 전송된 총 요청 수를 가져오려면 Sum 통계를 사용합니다. 단위: 없음 유효 통계: Sum |
InvocationsPerCopy |
추론 구성 요소의 각 복사본별로 정규화된 호출 수입니다. 유효 통계: Sum |
InvocationsPerInstance |
모델에 송신된 호출의 수로서 각 ProductionVariant에서 단위: 없음 유효 통계: Sum |
ModelLatency |
모델이 SageMaker 런타임 API 요청에 응답하는데 걸린 시간 간격. 이 간격에는 요청을 전송하고 모델 컨테이너에서 응답을 가져오는 데 걸리는 로컬 통신 시간이 포함됩니다. 또한 컨테이너에서 추론을 완료하는 데 걸리는 시간도 포함됩니다. 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count, Percentiles |
ModelSetupTime |
서버리스 엔드포인트를 위해 새 컴퓨팅 리소스를 시작하는 데 걸리는 시간입니다. 시간은 모델 크기, 모델 다운로드에 걸리는 시간, 컨테이너의 시작 시간에 따라 달라집니다. 단위: 마이크로초 유효 통계: Average, Min, Max, Sample Count, Percentiles |
OverheadLatency |
SageMaker AI 오버헤드에서 클라이언트 요청에 응답하는 데 걸리는 시간에 추가된 시간의 간격입니다. 이 간격은 SageMaker AI가 요청을 수신할 때부터 클라이언트에 응답을 반환할 때까지 측정된 시간에서 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count |
MidStreamErrors
|
초기 응답이 고객에게 전송된 후 응답 스트리밍 중에 발생하는 오류 수입니다. 단위: 없음 유효한 통계: Average, Sum |
FirstChunkLatency
|
요청이 SageMaker AI 엔드포인트에 도착한 시점부터 응답의 첫 번째 청크가 고객에게 전송될 때까지 경과한 시간입니다. 이 지표는 양방향 스트리밍 추론 요청에 적용됩니다. 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count, Percentiles |
FirstChunkModelLatency
|
모델 컨테이너가 요청을 처리하고 응답의 첫 번째 청크를 반환하는 데 걸리는 시간입니다. 이는 요청이 모델 컨테이너로 전송되는 시점부터 모델에서 첫 번째 바이트가 수신될 때까지 측정됩니다. 이 지표는 양방향 스트리밍 추론 요청에 적용됩니다. 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count, Percentiles |
FirstChunkOverheadLatency
|
모델 처리 시간을 제외한 첫 번째 청크의 오버헤드 지연 시간입니다. 이는 SageMaker AI 플랫폼 내에서 라우팅, 전처리 및 후처리 작업에 소요된 시간을 단위: 마이크로초 유효한 통계: Average, Sum, Min, Max, Sample Count, Percentile |
| 차원 | 설명 |
|---|---|
EndpointName, VariantName |
지정된 엔드포인트 및 변환의 |
EndpointName, VariantName, InstanceType |
인스턴스 풀을 사용하는 프로덕션 변형의 인스턴스 유형별로 엔드포인트 호출 지표를 필터링합니다. 이 차원을 사용하여 변형 내의 각 인스턴스 유형에 대한 호출 패턴을 볼 수 있습니다. |
InferenceComponentName |
추론 구성 요소 호출 지표를 필터링합니다. |
InstanceId |
특정 인스턴스에 대한 호출 지표를 필터링합니다. |
ContainerId |
(추론 구성 요소만 해당) 특정 컨테이너에 대한 호출 지표를 필터링합니다. |
SageMaker AI 추론 구성 요소 지표
/aws/sagemaker/InferenceComponents 네임스페이스에는 추론 구성 요소를 호스팅하는 엔드포인트에 대한 InvokeEndpoint 호출의 다음 지표가 포함됩니다. 컨테이너 수준 세부 수준을 사용하려면 엔드포인트 구성의 MetricsConfigEnableEnhancedMetrics=True에가 필요합니다.
지표는 1분 간격으로 제공됩니다. 에서를 설정하여 게시 빈도를 10, 30, 60, 120, 180, 240 또는 300초로 구성할 수 MetricPublishFrequencyInSeconds 있습니다MetricsConfig. 이 설정은 활성화EnableEnhancedMetrics할 필요가 없습니다. 를 EnableEnhancedMetrics로 설정하면 추가 차원 True, InstanceId ContainerId및 AcceleratorId (GPU 지표만 해당)을 사용할 수 있습니다. 자세한 내용은 추론 엔드포인트에 대한 Amazon SageMaker AI 향상된 지표 단원을 참조하십시오.
| 지표 | 설명 |
|---|---|
CPUUtilizationNormalized |
추론 구성 요소의 각 복사본에서 보고된 |
GPUMemoryUtilizationNormalized |
추론 구성 요소의 각 복사본에서 보고된 |
GPUUtilizationNormalized |
추론 구성 요소의 각 복사본에서 보고된 |
MemoryUtilizationNormalized |
추론 구성 요소의 각 복사본에서 |
| 차원 | 설명 |
|---|---|
InferenceComponentName |
추론 구성 요소 지표를 필터링합니다. |
InferenceComponentName, InstanceType |
인스턴스 유형별로 추론 구성 요소 지표를 필터링합니다. 추론 구성 요소가 인스턴스 풀이 있는 프로덕션 변형에 배포되어 각 인스턴스 유형에 대한 지표를 별도로 볼 때이 차원을 사용합니다. |
InstanceId |
특정 인스턴스에 대한 추론 구성 요소 지표를 필터링합니다. |
ContainerId |
특정 컨테이너에 대한 추론 구성 요소 지표를 필터링합니다. |
AcceleratorId |
(GPU 지표만 해당) 특정 GPU에 대한 추론 구성 요소 지표를 필터링합니다. |
SageMaker AI 다중 모델 엔드포인트 지표
AWS/SageMaker 네임스페이스에는 InvokeEndpoint 호출을 통해 생성된 다음과 같은 모델 로드 지표가 포함됩니다.
지표는 1분 간격으로 제공됩니다.
CloudWatch 지표의 보존 기간에 대한 자세한 내용은 Amazon CloudWatch API 참조의 GetMetricStatistics를 참조하세요.
| 지표 | 설명 |
|---|---|
ModelLoadingWaitTime |
추론을 실행하기 위해 대상 모델이 다운로드, 로드 또는 다운로드 및 로드될 때까지 호출 요청이 대기한 시간 간격입니다. 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count |
ModelUnloadingTime |
컨테이너의 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count |
ModelDownloadingTime |
Amazon Simple Storage Service(S3)에서 모델을 다운로드하는 데 걸린 시간 간격입니다. 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count |
ModelLoadingTime |
컨테이너의 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count |
ModelCacheHit |
모델이 이미 로드된 다중 모델 엔드포인트로 전송된 평균 통계는 모델이 이미 로드된 요청의 비율을 보여줍니다. 단위: 없음 유효한 통계: 평균, 합계, 샘플 개수 |
| 차원 | 설명 |
|---|---|
EndpointName, VariantName |
지정된 엔드포인트 및 변환의 |
/aws/sagemaker/Endpoints 네임스페이스에는 InvokeEndpoint 호출을 통해 생성된 다음과 같은 인스턴스 지표가 포함됩니다.
지표는 1분 간격으로 제공됩니다.
CloudWatch 지표의 보존 기간에 대한 자세한 내용은 Amazon CloudWatch API 참조의 GetMetricStatistics를 참조하세요.
| 지표 | 설명 |
|---|---|
LoadedModelCount |
다중 모델 엔드포인트의 컨테이너에 로드된 모델 수입니다. 이 지표는 인스턴스별로 내보내집니다. 1분의 평균 통계는 인스턴스당 로드된 평균 모델 수를 나타냅니다. 합계 통계는 엔드포인트의 모든 인스턴스에 로드된 총 모델 수를 알려줍니다. 모델이 엔드포인트의 여러 컨테이너에 로드될 수 있기 때문에 이 지표가 추적하는 모델은 고유하지 않을 수 있습니다. 단위: 없음 유효 통계: Average, Sum, Min, Max, Sample Count |
| 차원 | 설명 |
|---|---|
EndpointName, VariantName |
지정된 엔드포인트 및 변환의 |
SageMaker AI 작업 지표
/aws/sagemaker/ProcessingJobs, /aws/sagemaker/TrainingJobs및 /aws/sagemaker/TransformJobs 네임스페이스에는 처리 작업, 훈련 작업 및 배치 변환 작업에 대한 다음 지표가 포함됩니다.
지표는 1분 간격으로 제공됩니다.
참고
Amazon CloudWatch는 고해상도 사용자 지정 지표를 지원하며, 최상의 해상도는 1초입니다. 그러나 해상도가 높을수록 CloudWatch 지표의 수명이 짧아집니다. 1초 주파수 해상도의 경우 CloudWatch 지표는 3시간 동안 사용할 수 있습니다. CloudWatch 지표의 해상도와 수명에 대한 자세한 내용은 Amazon CloudWatch API 참조의 GetMetricStatistics를 참조하세요.
작은 정보
훈련 작업을 100밀리초(0.1초)까지 세밀한 해상도로 프로파일링하고 언제든지 사용자 지정 분석을 위해 Amazon S3에 훈련 지표를 무기한 저장하기 위해 Amazon SageMaker Debugger 사용을 고려해 보세요. SageMaker Debugger는 일반적인 훈련 문제를 자동으로 감지하는 기본 제공 규칙을 제공합니다. 하드웨어 리소스 사용률 문제(예: CPU, GPU 및 I/O 병목 현상)를 감지합니다. 또한 수렴되지 않는 모델 문제(예: 과적합, 그라데이션 사라짐, 텐서 폭발)도 감지합니다. SageMaker Debugger는 Studio 및 프로파일링 보고서를 통해 시각화도 제공합니다. Debugger 시각화를 살펴보려면 SageMaker Debugger 인사이트 대시보드 안내, Debugger 프로파일링 보고서 안내 및 SMDebug 클라이언트 라이브러리를 사용한 데이터 분석을 참조하세요.
| 지표 | 설명 |
|---|---|
CPUUtilization |
각 개별 CPU 코어 사용률의 합계. 각 코어 범위의 CPU 사용률은 0–100입니다. 예를 들어 CPU가 4개인 경우 CPUUtilization 범위는 0%~400%입니다. 처리 작업의 경우 이 값은 인스턴스에 있는 처리 컨테이너의 CPU 사용률입니다.훈련 작업의 경우 이 값은 인스턴스에 있는 알고리즘 컨테이너의 CPU 사용률입니다. 배치 변환 작업의 경우 이 값은 인스턴스에 있는 변환 컨테이너의 CPU 사용률입니다. 참고다중 인스턴스 작업의 경우, 각 인스턴스가 CPU 사용률 지표를 보고합니다. 하지만 CloudWatch 내 기본 보기에는 모든 인스턴스의 평균 CPU 사용률이 표시됩니다. 단위: 백분율 |
DiskUtilization |
인스턴스의 컨테이너에서 사용하는 디스크 공간의 비율입니다. 이 값 범위는 0%~100%입니다. 배치 변환 작업에는 이 지표가 지원되지 않습니다. 처리 작업의 경우 이 값은 인스턴스에 있는 처리 컨테이너의 디스크 공간 사용률입니다.훈련 작업의 경우 이 값은 인스턴스에 있는 알고리즘 컨테이너의 디스크 공간 사용률입니다. 단위: 백분율 참고다중 인스턴스 작업의 경우, 각 인스턴스가 디스크 사용률 지표를 보고합니다. 하지만 CloudWatch 내 기본 보기에는 모든 인스턴스의 평균 디스크 사용률이 표시됩니다. |
GPUMemoryUtilization |
인스턴스의 컨테이너에서 사용하는 GPU 메모리의 비율(%)입니다. 값 범위는 0~100이고, GPU의 수를 곱합니다. 예를 들어 GPU가 4개인 경우 훈련 작업의 경우 이 값은 인스턴스에 있는 알고리즘 컨테이너의 GPU 메모리 사용률입니다. 배치 변환 작업의 경우 이 값은 인스턴스에 있는 변환 컨테이너의 GPU 메모리 사용률입니다. 참고다중 인스턴스 작업의 경우, 각 인스턴스가 GPU 메모리 사용률 지표를 보고합니다. 하지만 CloudWatch 내 기본 보기에는 모든 인스턴스의 평균 GPU 메모리 사용률이 표시됩니다. 단위: 백분율 |
GPUUtilization |
인스턴스의 컨테이너에서 사용하는 GPU 유닛의 비율(%)입니다. 값은 0~100 사이가 될 수 있고, GPU의 수를 곱합니다. 예를 들어 GPU가 4개인 경우 훈련 작업의 경우 이 값은 인스턴스에 있는 알고리즘 컨테이너의 GPU 사용률입니다. 배치 변환 작업의 경우 이 값은 인스턴스에 있는 변환 컨테이너의 GPU 사용률입니다. 참고다중 인스턴스 작업의 경우, 각 인스턴스가 GPU 사용률 지표를 보고합니다. 하지만 CloudWatch 내 기본 보기에는 모든 인스턴스의 평균 GPU 사용률이 표시됩니다. 단위: 백분율 |
MemoryUtilization |
인스턴스의 컨테이너에서 사용하는 메모리의 비율(%)입니다. 이 값 범위는 0%~100%입니다. 처리 작업의 경우 이 값은 인스턴스에 있는 처리 컨테이너의 메모리 사용률입니다.훈련 작업의 경우 이 값은 인스턴스에 있는 알고리즘 컨테이너의 메모리 사용률입니다. 배치 변환 작업의 경우 이 값은 인스턴스에 있는 변환 컨테이너의 메모리 사용률입니다. 단위: 백분율 참고다중 인스턴스 작업의 경우, 각 인스턴스가 메모리 사용률 지표를 보고합니다. 하지만 CloudWatch 내 기본 보기에는 모든 인스턴스의 평균 메모리 사용률이 표시됩니다. |
| 차원 | 설명 |
|---|---|
Host |
처리 작업의 경우 이 차원의 값은 훈련 작업의 경우 이 차원의 값은 배치 변환 작업의 경우 이 차원의 값은 |
SageMaker 추론 추천 작업 지표
/aws/sagemaker/InferenceRecommendationsJobs 네임스페이스에는 추론 추천 작업에 대한 다음 지표가 포함됩니다.
| 지표 | 설명 |
|---|---|
ClientInvocations |
추론 추천에서 관찰한 모델 엔드포인트로 전송된 단위: 없음 유효 통계: Sum |
ClientInvocationErrors |
추론 추천에서 관찰한 실패한 단위: 없음 유효 통계: Sum |
ClientLatency |
추론 추천에서 관찰한 단위: 밀리초 유효 통계: Average, Sum, Min, Max, Sample Count, Percentiles |
NumberOfUsers |
모델 엔드포인트에 단위: 없음 유효 통계: Max, Min, Average |
| 차원 | 설명 |
|---|---|
JobName |
지정된 추론 추천 작업에 대한 추론 추천 작업 지표를 필터링합니다. |
EndpointName |
지정된 엔드포인트에 대한 추론 추천 작업 지표를 필터링합니다. |
Amazon SageMaker Ground Truth 지표
| 지표 | 설명 |
|---|---|
ActiveWorkers |
작업을 제출, 공개 또는 거부한 프라이빗 작업팀의 활성 작업자 한 명. 총 활성 작업자 수를 구하려면 Sum(합계) 통계를 사용하세요. Ground Truth는 각 개별 단위: 없음 유효한 통계: Sum, Sample Count |
DatasetObjectsAutoAnnotated |
레이블 지정 작업에서 자동으로 주석이 추가되는 데이터세트 객체의 수입니다. 이 지표는 자동화 레이블 지정 작업을 활성화한 경우에만 방출됩니다. 레이블 지정 작업 진행 상황을 보려면 Max 지표를 사용합니다. 단위: 없음 유효한 통계: Max |
DatasetObjectsHumanAnnotated |
레이블 지정 작업에서 사람이 주석을 추가한 데이터세트 객체의 수입니다. 레이블 지정 작업 진행 상황을 보려면 Max 지표를 사용합니다. 단위: 없음 유효한 통계: Max |
DatasetObjectsLabelingFailed |
레이블 지정 작업에서 레이블 지정에 실패한 데이터세트 객체의 수입니다. 레이블 지정 작업 진행 상황을 보려면 Max 지표를 사용합니다. 단위: 없음 유효한 통계: Max |
JobsFailed |
단일 레이블 지정 작업이 실패했습니다. 실패한 총 레이블 지정 작업 수를 가져오려면 Sum(합계) 통계를 사용합니다. 단위: 없음 유효한 통계: Sum, Sample Count |
JobsSucceeded |
단일 레이블 지정 작업이 성공했습니다. 성공한 총 레이블 지정 작업의 수를 가져오려면 Sum 통계를 사용합니다. 단위: 없음 유효한 통계: Sum, Sample Count |
JobsStopped |
단일 레이블 지정 작업이 중단되었습니다. 중지된 총 레이블 지정 작업 수를 가져오려면 Sum 통계를 사용합니다. 단위: 없음 유효한 통계: Sum, Sample Count |
TasksAccepted |
한 작업자가 단일 작업을 수락했습니다. 작업자가 수락한 총 작업 수를 구하려면 Sum(합계) 통계를 사용하세요. Ground Truth는 각 개별 단위: 없음 유효한 통계: Sum, Sample Count |
TasksDeclined |
한 작업자가 단일 작업을 거부했습니다. 작업자가 거부한 총 작업 수를 구하려면 Sum(합계) 통계를 사용하세요. Ground Truth는 각 개별 단위: 없음 유효한 통계: Sum, Sample Count |
TasksReturned |
단일 작업이 반환되었습니다. 반환된 총 작업 수를 구하려면 Sum(합계) 통계를 사용하세요. Ground Truth는 각 개별 단위: 없음 유효한 통계: Sum, Sample Count |
TasksSubmitted |
프라이빗 작업자가 단일 작업을 제출/완료했습니다. 작업자가 제출한 총 작업 수를 구하려면 Sum(합계) 통계를 사용하세요. Ground Truth는 각 개별 단위: 없음 유효한 통계: Sum, Sample Count |
TimeSpent |
프라이빗 작업자가 완료한 작업에 소요된 시간입니다. 작업자가 일시 중지하거나 휴식을 취한 시간은 이 지표에 포함되지 않습니다. Ground Truth는 각 단위: 초 유효한 통계: Sum, Sample Count |
TotalDatasetObjectsLabeled |
레이블 지정 작업에서 성공적으로 레이블이 지정된 데이터세트 객체의 수입니다. 레이블 지정 작업 진행 상황을 보려면 Max 지표를 사용합니다. 단위: 없음 유효한 통계: Max |
| 차원 | 설명 |
|---|---|
LabelingJobName |
레이블 지정 작업에 대한 데이터세트 객체 수 지표를 필터링합니다. |
Amazon SageMaker 특성 스토어 지표
| 지표 | 설명 |
|---|---|
ConsumedReadRequestsUnits |
지정한 시간 동안 소비한 읽기 단위의 수. 특성 스토어 런타임 작업 및 해당 특성 그룹에 사용된 읽기 단위를 검색할 수 있습니다. 단위: 없음 유효한 통계: All |
ConsumedWriteRequestsUnits |
지정한 시간 동안 소비한 쓰기 단위의 수. 특성 스토어 런타임 작업 및 해당 특성 그룹에 사용된 쓰기 단위를 검색할 수 있습니다. 단위: 없음 유효한 통계: All |
ConsumedReadCapacityUnits |
지정된 기간 동안 사용된 읽기 용량 단위의 수입니다. 특성 스토어 런타임 작업 및 해당 특성 그룹에 사용된 프로비저닝된 읽기 단위를 검색할 수 있습니다. 단위: 없음 유효한 통계: All |
ConsumedWriteCapacityUnits |
지정된 기간 동안 사용된 프로비저닝된 쓰기 용량 단위의 수입니다. 특성 스토어 런타임 작업 및 해당 특성 그룹에 사용된 쓰기 용량 단위를 검색할 수 있습니다. 단위: 없음 유효한 통계: All |
| 차원 | 설명 |
|---|---|
FeatureGroupName, OperationName |
지정한 특성 그룹 및 작업의 특성 스토어 런타임 소비 지표를 필터링합니다. |
| 지표 | 설명 |
|---|---|
Invocations |
지정된 기간 동안 특성 스토어 런타임 작업에 수행된 요청 수입니다. 단위: 없음 유효 통계: Sum |
Operation4XXErrors |
작업이 4xx HTTP 응답 코드를 반환한 특성 스토어 런타임 작업에 이루어진 요청 수입니다. 각 4xx 응답에서 1이 전송되고, 그 외의 경우에는 0이 전송됩니다. 단위: 없음 유효한 통계: Average, Sum |
Operation5XXErrors |
작업이 5xx HTTP 응답 코드를 반환한 특성 스토어 런타임 작업에 이루어진 요청 수입니다. 각 5xx 응답에서 1이 전송되고, 그 외의 경우에는 0이 전송됩니다. 단위: 없음 유효한 통계: Average, Sum |
ThrottledRequests |
특성 스토어 런타임 작업에 요청되었으나 조절을 받은 요청 수입니다. 조절을 받은 각 요청에는 1이 전송되고, 그렇지 않으면 0이 전송됩니다. 단위: 없음 유효한 통계: Average, Sum |
Latency |
특성 스토어 런타임 작업에의 요청을 처리하는 시간 간격입니다. 이 간격은 SageMaker AI가 요청을 수신할 때부터 클라이언트에 응답을 반환할 때까지 측정된 시간입니다. 단위: 마이크로초 유효 통계: Average, Sum, Min, Max, Sample Count, Percentiles |
| 차원 | 설명 |
|---|---|
|
|
지정한 특성 그룹 및 작업의 특성 스토어 런타임 운영 지표를 필터링합니다. 이러한 차원은 GetRecord, PutRecord, DeleteRecord와 같은 비배치 작업에 사용할 수 있습니다. |
OperationName |
지정한 작업의 특성 스토어 런타임 운영 지표를 필터링합니다. 이 차원은 BatchGetRecord와 같은 배치 작업에 사용할 수 있습니다. |
SageMaker Pipelines 지표
AWS/Sagemaker/ModelBuildingPipeline 네임스페이스에는 파이프라인 실행에 대한 다음 지표가 포함되어 있습니다.
파이프라인 실행 지표의 두 가지 범주를 사용할 수 있습니다.
-
모든 파이프라인의 실행 지표 - 계정 수준 파이프라인 실행 지표 (현재 계정의 모든 파이프라인)
-
파이프라인별 실행 지표 - 파이프라인별 파이프라인 실행 지표
지표는 1분 간격으로 제공됩니다.
| 지표 | 설명 |
|---|---|
ExecutionStarted |
시작된 파이프라인 실행 수입니다. 단위: 개 유효한 통계: Average, Sum |
ExecutionFailed |
실패한 파이프라인 실행 수입니다. 단위: 개 유효한 통계: Average, Sum |
ExecutionSucceeded |
성공한 파이프라인 실행 수입니다. 단위: 개 유효한 통계: Average, Sum |
ExecutionStopped |
중지된 파이프라인 실행 수입니다. 단위: 개 유효한 통계: Average, Sum |
ExecutionDuration |
파이프라인이 실행된 기간 (밀리초). 단위: 밀리초 유효 통계: Average, Sum, Min, Max, Sample Count |
| 차원 | 설명 |
|---|---|
PipelineName |
지정된 파이프라인의 파이프라인 실행 지표를 필터링합니다. |
AWS/Sagemaker/ModelBuildingPipeline 네임스페이스에는 파이프라인 단계에 대한 다음 지표가 포함되어 있습니다.
지표는 1분 간격으로 제공됩니다.
| 지표 | 설명 |
|---|---|
StepStarted |
시작된 단계의 수입니다. 단위: 개 유효한 통계: Average, Sum |
StepFailed |
실패한 단계의 수입니다. 단위: 개 유효한 통계: Average, Sum |
StepSucceeded |
성공한 단계의 수입니다. 단위: 개 유효한 통계: Average, Sum |
StepStopped |
중지된 단계의 수입니다. 단위: 개 유효한 통계: Average, Sum |
StepDuration |
단계가 실행된 기간 (밀리초). 단위: 밀리초 유효 통계: Average, Sum, Min, Max, Sample Count |
| 차원 | 설명 |
|---|---|
PipelineName, StepName |
지정된 파이프라인 및 단계의 단계 지표를 필터링합니다. |
