기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
SageMaker Profiler UI에서 시각화된 프로파일 출력 데이터 탐색
이 섹션에서는 SageMaker Profiler UI를 살펴보고 Profiler UI에서 인사이트를 사용하고 얻는 방법에 대한 팁을 제공합니다.
프로필 로드
SageMaker Profiler UI를 열면 프로필 로드 페이지가 열립니다. 대시보드와 타임라인을 로드하고 생성하려면 다음 절차를 따르세요.
훈련 작업 프로필을 로드하려면
-
훈련 작업 목록 섹션에서 확인란을 사용하여 프로필을 로드하려는 훈련 작업을 선택합니다.
-
로드(Load)를 선택합니다. 작업 이름이 상단의 로드된 프로필 섹션에 표시되어야 합니다.
-
작업 이름 왼쪽에 있는 라디오 버튼을 선택하여 대시보드와 타임라인을 생성합니다. 참고로 라디오 버튼을 선택하면 UI에서 대시보드가 자동으로 열립니다. 또한 작업 상태 및 로드 상태가 여전히 진행 중인 것으로 보이는 동안 시각화를 생성하는 경우 SageMaker Profiler UI는 진행 중인 훈련 작업 또는 부분적으로 로드된 프로파일 데이터에서 수집된 가장 최근 프로파일 데이터까지 대시보드 플롯과 타임라인을 생성합니다.
작은 정보
프로필을 한 번에 하나씩 로드하고 시각화할 수 있습니다. 다른 프로필을 로드하려면 먼저 이전에 로드한 프로필을 언로드해야 합니다. 프로필을 언로드하려면 로드된 프로필 섹션에서 프로필 오른쪽 끝에 있는 휴지통 아이콘을 사용합니다.
대시보드
훈련 작업 로드 및 선택을 마치면 UI에서 기본적으로 다음 패널이 포함된 대시보드 페이지가 열립니다.
-
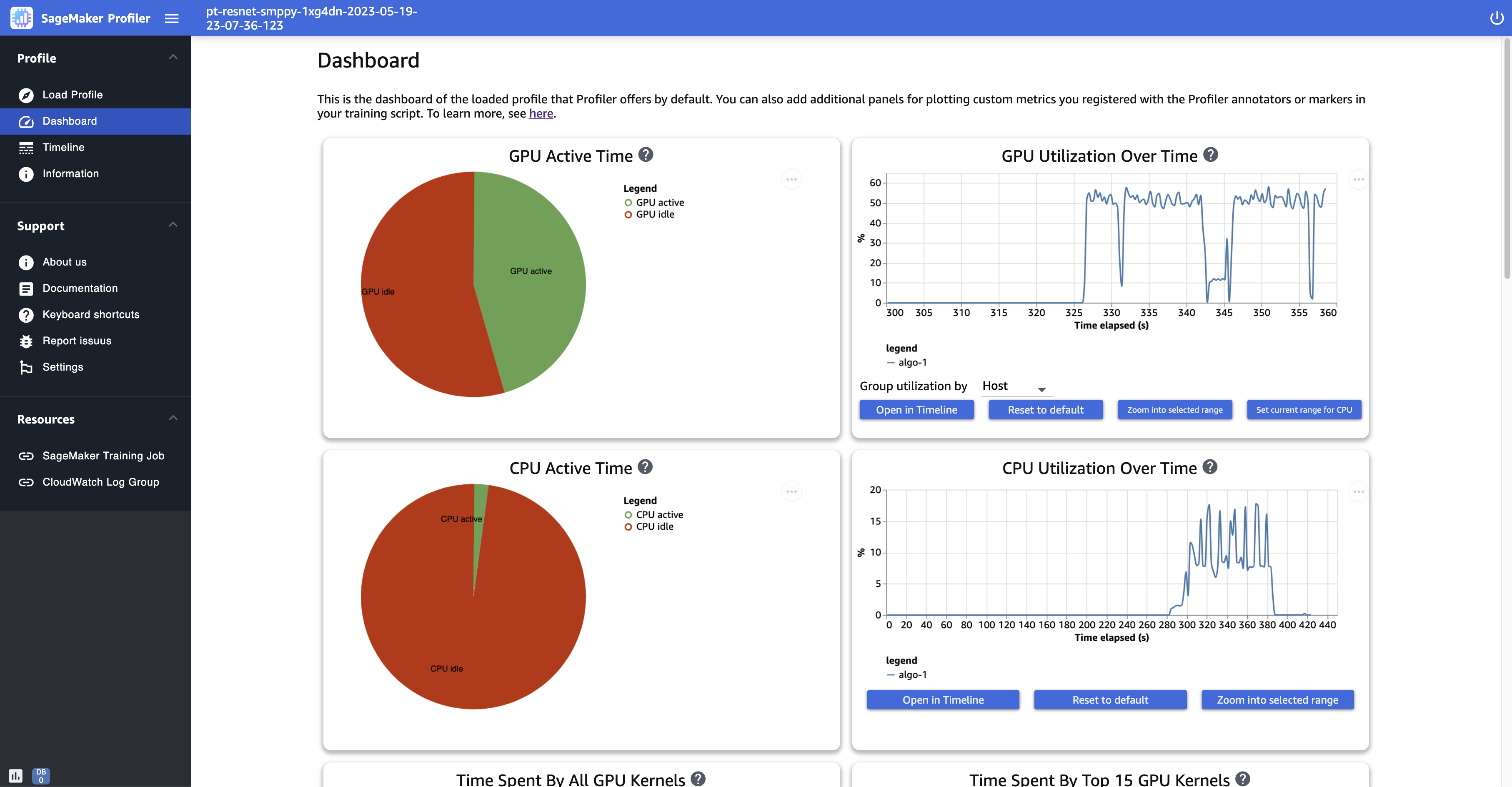
GPU 활성 시간 - 이 원형 차트는 GPU 활성 시간 대 GPU 유휴 시간의 백분율을 보여줍니다. 전체 훈련 작업에서 유휴 상태보다 활성 GPUs 상태인지 확인할 수 있습니다. GPU 활성 시간은 사용률이 0%보다 큰 프로필 데이터 포인트를 기반으로 하는 반면, GPU 유휴 시간은 사용률이 0%인 프로필 데이터 포인트입니다.
-
GPU 시간 경과에 따른 사용률 - 이 타임라인 그래프는 노드당 시간 경과에 따른 평균 GPU 사용률을 보여주며, 모든 노드를 단일 차트로 집계합니다. 특정 시간 간격 동안 GPUs에 불균형한 워크로드, 사용 부족 문제, 병목 현상 또는 유휴 문제가 있는지 확인할 수 있습니다. 개별 GPU 수준 및 관련 커널 실행에서 사용률을 추적하려면 를 사용합니다타임라인 인터페이스. GPU 활동 모음은 훈련 스크립트
SMProf.start_profiling()에 프로파일러 스타터 함수를 추가한 곳에서 시작하여 에서 중지됩니다SMProf.stop_profiling(). -
CPU 활성 시간 - 이 원형 차트는 CPU 활성 시간 대 CPU 유휴 시간의 백분율을 보여줍니다. 전체 훈련 작업에서 유휴 상태보다 활성 CPUs 상태인지 확인할 수 있습니다. CPU 활성 시간은 사용률이 0%보다 큰 프로파일링된 데이터 포인트를 기반으로 하는 반면, CPU 유휴 시간은 사용률이 0%인 프로파일링된 데이터 포인트를 기반으로 합니다.
-
CPU 시간 경과에 따른 사용률 - 이 타임라인 그래프는 노드당 시간 경과에 따른 평균 CPU 사용률을 보여주며 단일 차트에서 모든 노드를 집계합니다. 특정 시간 간격 동안 가 병목 현상CPUs이 발생했는지 또는 제대로 활용되지 않았는지 확인할 수 있습니다. 개별 사용률 및 커널 실행과 CPUs 일치하는 의 GPU 사용률을 추적하려면 를 사용합니다타임라인 인터페이스. 참고로 사용률 지표는 작업 초기화 시점부터 시작됩니다.
-
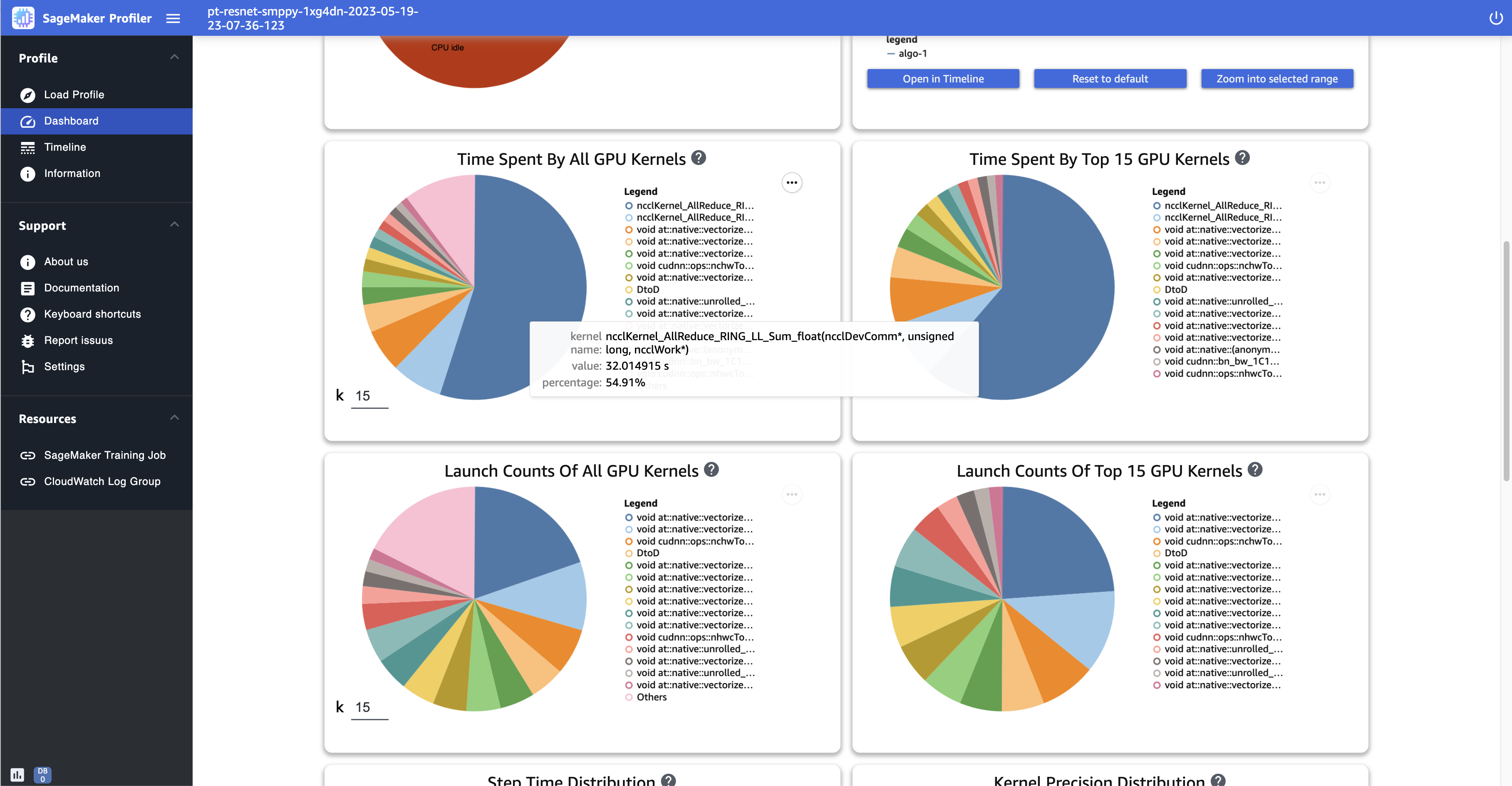
모든 커널에서 소요된 시간 GPU - 이 파이 차트는 훈련 작업 전체에서 작동하는 모든 GPU 커널을 보여줍니다. 기본적으로 상위 GPU 15개 커널을 개별 섹터로 표시하고 한 섹터의 다른 모든 커널을 표시합니다. 섹터 위로 마우스를 가져가면 더 자세한 정보를 볼 수 있습니다. 값은 작동GPU되는 커널의 총 시간을 초 단위로 표시하며 백분율은 프로파일의 전체 시간을 기준으로 합니다.
-
상위 GPU 15개 커널에서 소요된 시간 - 이 파이 차트는 훈련 작업 전반에 걸쳐 운영되는 모든 GPU 커널을 보여줍니다. 상위 GPU 15개 커널을 개별 섹터로 표시합니다. 섹터 위로 마우스를 가져가면 더 자세한 정보를 볼 수 있습니다. 값은 작동GPU되는 커널의 총 시간을 초 단위로 표시하며 백분율은 프로파일의 전체 시간을 기준으로 합니다.
-
모든 커널의 시작 수 GPU - 이 원형 차트는 훈련 작업 동안 시작된 모든 GPU 커널의 수를 보여줍니다. 상위 GPU 15개 커널을 개별 섹터로 표시하고 한 섹터의 다른 모든 커널을 표시합니다. 섹터 위로 마우스를 가져가면 더 자세한 정보를 볼 수 있습니다. 값은 시작된 GPU 커널의 총 개수를 나타내며 백분율은 모든 커널의 전체 개수를 기반으로 합니다.
-
상위 GPU 15개 커널의 시작 수 - 이 원형 차트는 훈련 작업 동안 시작된 모든 GPU 커널의 수를 보여줍니다. 상위 GPU 15개의 커널을 보여줍니다. 섹터 위로 마우스를 가져가면 더 자세한 정보를 볼 수 있습니다. 값은 시작된 GPU 커널의 총 개수를 나타내며 백분율은 모든 커널의 전체 개수를 기반으로 합니다.
-
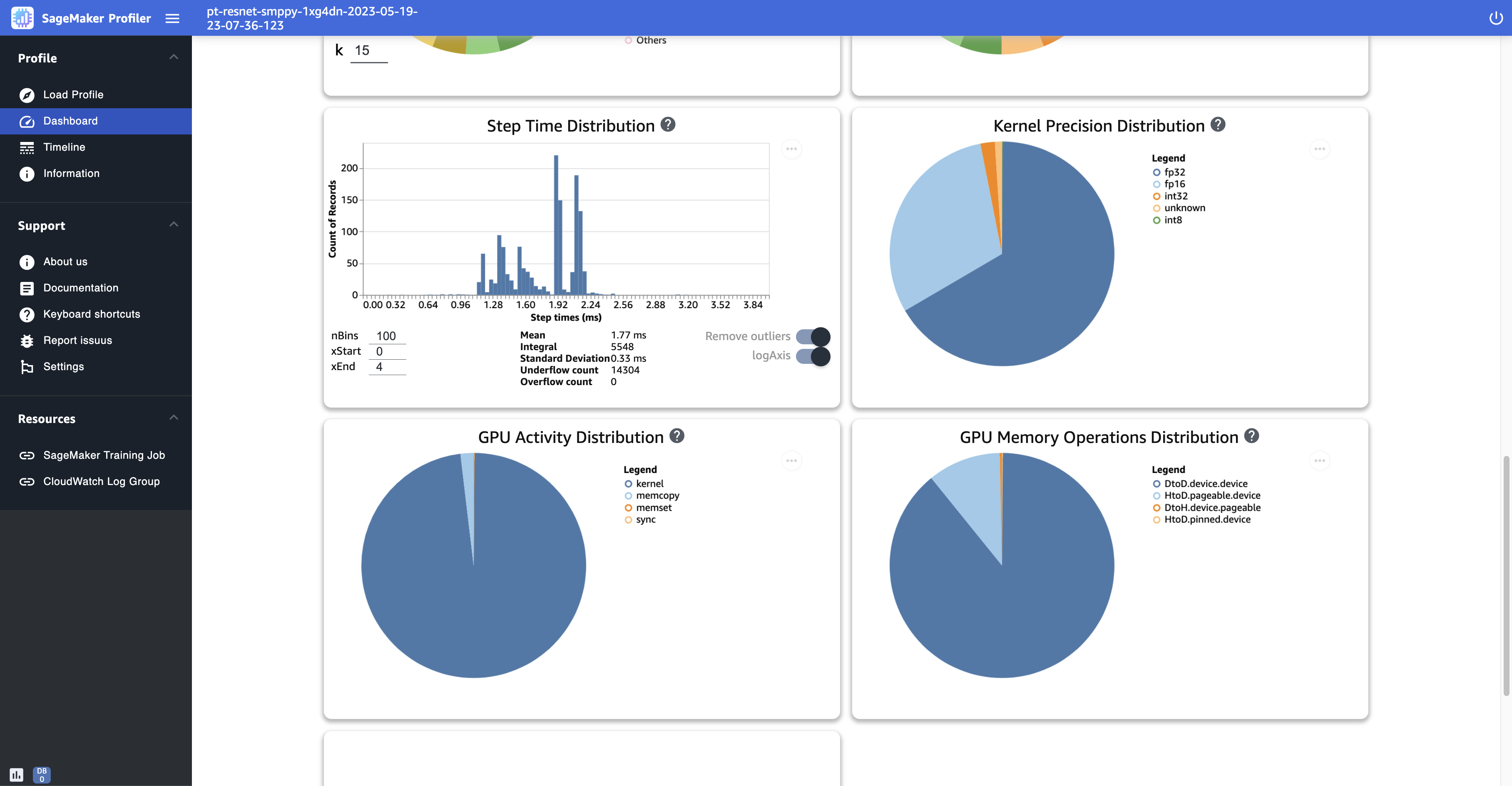
단계 시간 분포 - 이 히스토그램은 의 단계 지속 시간 분포를 보여줍니다GPUs. 이 플롯은 훈련 스크립트에 단계 주석자를 추가한 후에만 생성됩니다.
-
커널 정밀도 분포 - 이 파이 차트는 FP32, , FP16INT32, 와 같은 다양한 데이터 유형에서 커널을 실행하는 데 소요된 시간의 백분율을 보여줍니다INT8.
-
GPU 활동 분포 - 이 원형 차트는 커널 실행, 메모리(
memcpy및memset) 및 동기화()와 같은 GPU 활동에 소요된 시간의 비율을 보여줍니다sync. -
GPU 메모리 작업 배포 - 이 원형 차트는 GPU 메모리 작업에 소요된 시간의 백분율을 보여줍니다. 이를 통해
memcopy활동을 시각화하여 훈련 작업이 특정 메모리 작업에 과도한 시간을 소비하고 있는지 확인할 수 있습니다. -
새 히스토그램 생성 - 1단계: SageMaker Profiler Python 모듈을 사용하여 훈련 스크립트 조정 작업 중에 수동으로 주석을 추가한 사용자 지정 지표의 새 다이어그램을 만드세요. 새 히스토그램에 사용자 지정 주석을 추가할 때는 훈련 스크립트에서 추가한 주석의 이름을 선택하거나 입력합니다. 예를 들어, 1단계의 데모 훈련 스크립트에서는
step,Forward,Backward,Optimize, 및Loss이(가) 사용자 지정 주석입니다. 새 히스토그램을 생성하는 동안 이러한 주석 이름이 지표 선택을 위한 드롭다운 메뉴에 나타나야 합니다.Backward을(를) 선택하는 경우 UI는 프로파일링된 시간 동안 역방향 패스에 소요된 시간의 히스토그램을 대시보드에 추가합니다. 이 유형의 히스토그램은 비정상적으로 시간이 오래 걸리고 병목 현상을 일으키는 특이값이 있는지 확인하는 데 유용합니다.
다음 스크린샷은 GPU 및 CPU 활성 시간 비율과 컴퓨팅 노드당 시간에 대한 평균 GPU 및 CPU 사용률을 보여줍니다.
다음 스크린샷은 커널이 시작된 횟수를 비교하고 커널 실행에 소요된 시간을 측정하는 GPU 파이 차트의 예를 보여줍니다. 모든 커널 및 모든 커널 패널의 시작 수가 소비한 시간에서 k에 대한 입력 필드에 정수를 지정하여 플롯에 표시할 GPU 범례 수를 조정할 수도 있습니다. GPU 예를 들어 10을 지정하면 가장 많이 실행된 커널과 시작된 커널 상위 10개가 각각 플롯에 표시됩니다.
다음 스크린샷은 단계 지속 시간 히스토그램의 예제와 커널 정밀도 분포, GPU 활동 분포 및 GPU 메모리 작업 분포에 대한 파이 차트를 보여줍니다.
타임라인 인터페이스
에 예약된 작업 및 커널 수준에서 컴퓨팅 리소스에 대한 세부 정보를 얻CPUs고 에서 실행하려면 타임라인 인터페이스를 GPUs사용합니다.
마우스, [w, a, s, d] 키 또는 키보드의 화살표 키 4개를 사용하여 타임라인 인터페이스를 확대 및 축소하고 왼쪽이나 오른쪽으로 이동할 수 있습니다.
작은 정보
타임라인 인터페이스와 상호 작용하는 데 필요한 키보드 바로 가기에 대한 추가 팁을 보려면 왼쪽 창에서 키보드 바로 가기를 선택하세요.
이 타임라인 트랙은 트리 구조로 구성되어 있어 호스트 수준에서 디바이스 수준까지의 정보를 제공합니다. 예를 들어 각 N 인스턴스GPUs에 8개가 있는 인스턴스를 실행하는 경우 각 인스턴스의 타임라인 구조는 다음과 같습니다.
-
algo-inode – 프로비저닝된 인스턴스에 작업을 할당할 SageMaker 태그입니다. 숫자 inode은(는) 무작위로 할당됩니다. 예를 들어 인스턴스 4개를 사용하는 경우 이 섹션은 algo-1에서 algo-4로 확장됩니다.
-
CPU - 이 섹션에서는 평균 CPU 사용률 및 성능 카운터를 확인할 수 있습니다.
-
GPUs - 이 섹션에서는 평균 GPU 사용률, 개별 GPU 사용률 및 커널을 확인할 수 있습니다.
-
SUM 사용률 - 인스턴스당 평균 GPU 사용률입니다.
-
HOST-0 PID-123 – 각 프로세스 트랙에 할당된 고유한 이름입니다. 약어PID는 프로세스 ID이고, 약어에 추가된 번호는 프로세스에서 데이터를 캡처하는 동안 기록되는 프로세스 ID 번호입니다. 이 섹션에는 프로세스에서 얻은 다음 정보가 표시됩니다.
-
GPU-inum_gpu 사용률 - 시간 GPU 경과에 따른 i num_gpu-th의 사용률입니다.
-
GPU-inum_gpu 디바이스 – 커널은 inum_gpu번째 GPU 디바이스에서 실행됩니다.
-
stream icuda_stream - GPU 디바이스에서 커널이 실행됨을 보여주는 CUDA 스트림입니다. CUDA 스트림에 대한 자세한 내용은 PDF 에서 제공하는 CUDA C/C++ 스트림 및 동시성의 를
참조하세요NVIDIA.
-
-
GPU-inum_gpu 호스트 – 커널이 i번째num_gpu GPU 호스트에서 시작됩니다.
-
-
-
다음 몇 가지 스크린샷은 ml.p4d.24xlarge 인스턴스에서 실행되는 훈련 작업 프로파일의 타임라인을 보여주며, 각각에 8개의 NVIDIA A100 Tensor 코어가 장착되어 GPUs 있습니다.
다음은 프로필을 축소하여 보여 주는 것으로, 다음 데이터 배치를 가져오기 위해 step_232와(과) step_233 사이의 간헐적인 데이터 로더를 포함하여 12개의 단계를 인쇄합니다.
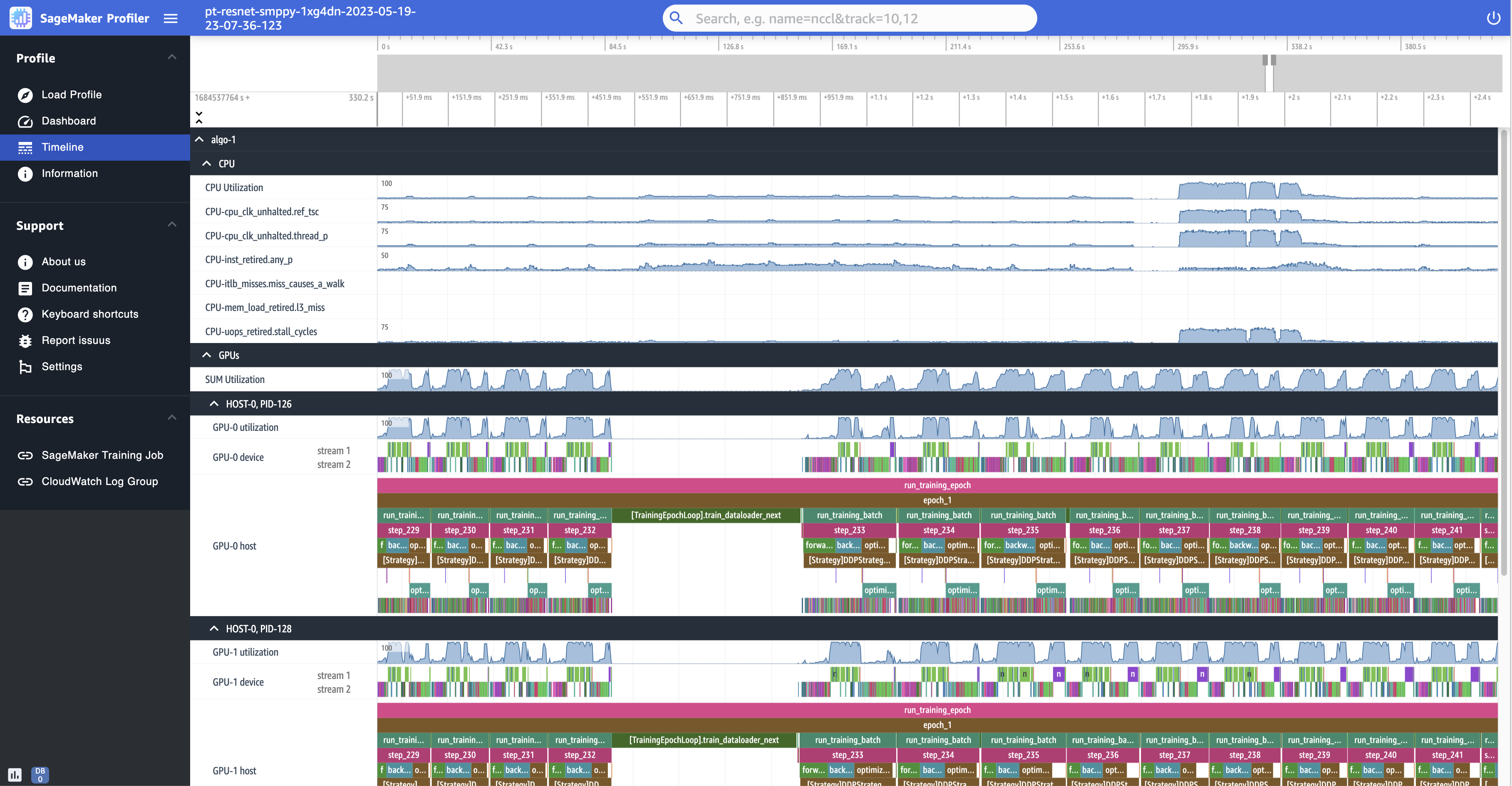
각 에 대해 에서 실행되는 지침을 "itlb_misses.miss_causes_a_walk"나타내는 "clk_unhalted_ref.tsc" 및 와 같은 CPU 사용률 및 성능 카운터를 추적할 CPU수 있습니다CPU.
각 에 대해 호스트 타임라인과 디바이스 타임라인을 볼 GPU수 있습니다. 커널 시작은 호스트 타임라인을 기준으로 하고 커널 실행은 디바이스 타임라인을 기준으로 합니다. GPU 호스트 타임라인의 훈련 스크립트에 를 추가한 경우 주석(예: 앞으로, 뒤로 및 최적화)을 볼 수도 있습니다.
타임라인 보기에서 커널 launch-and-run 페어를 추적할 수도 있습니다. 이렇게 하면 호스트(CPU)에서 예약된 커널 시작이 해당 GPU 디바이스에서 실행되는 방법을 이해하는 데 도움이 됩니다.
작은 정보
f 키를 누르면 선택한 커널이 확대됩니다.
다음 스크린샷은 이전 스크린샷의 step_233 및 step_234을(를) 확대한 모습입니다. 다음 스크린샷에서 선택한 타임라인 간격은 GPU-0 디바이스에서 실행되는 분산 훈련의 필수 통신 및 동기화 단계인 AllReduce 작업입니다. 스크린샷에서 GPU-0 호스트의 커널 시작은 GPU-0 디바이스 스트림 1에서 실행되는 커널에 연결되며, 이는 시아노 색상의 화살표로 표시됩니다.
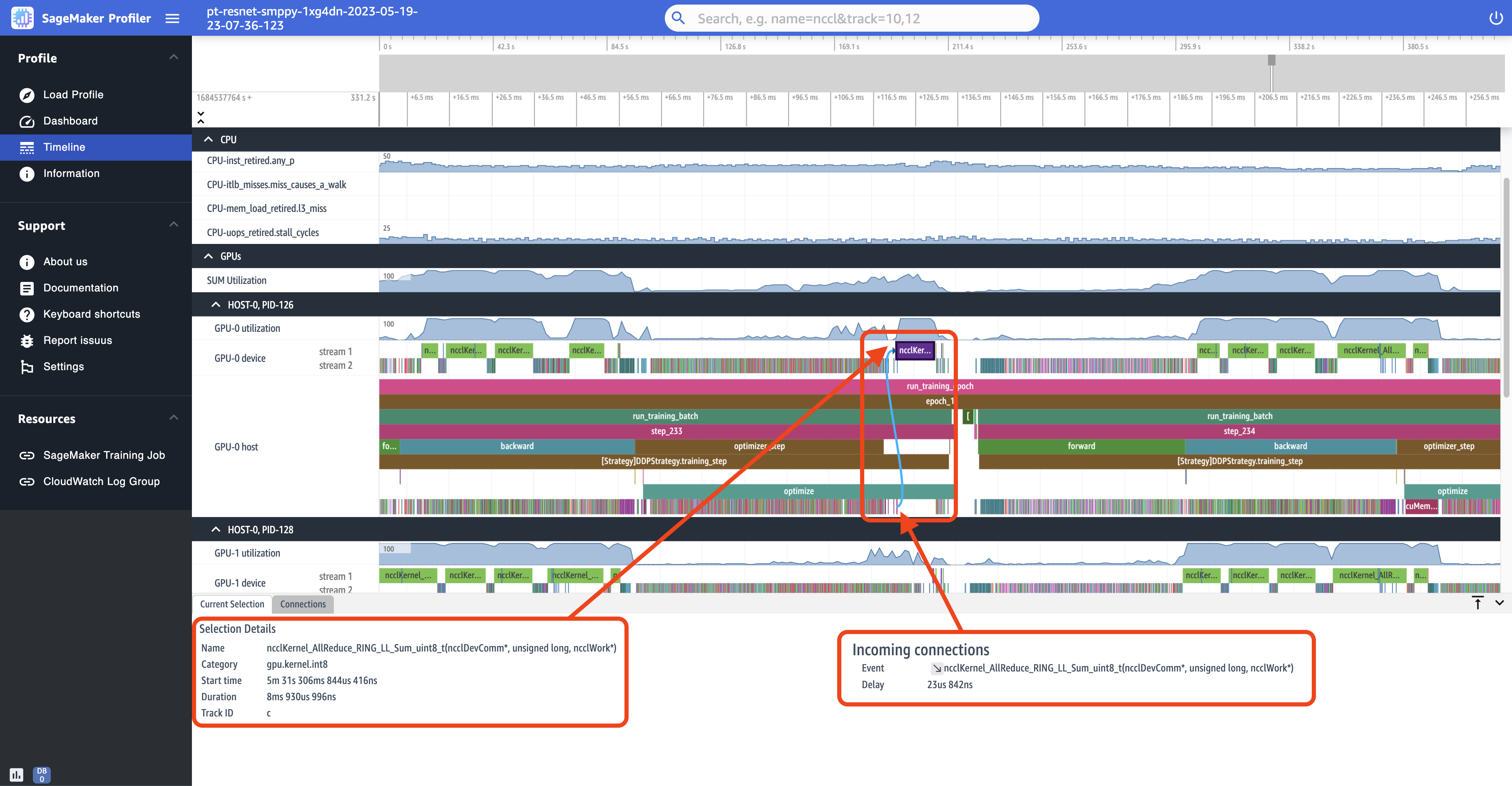
또한 이전 스크린샷과 같이 타임라인 간격을 선택하면 UI의 하단 패널에 두 개의 정보 탭이 나타납니다. 현재 선택 탭에는 선택한 커널과 호스트의 연결된 커널 시작에 대한 세부 정보가 표시됩니다. 각 커널은 항상 GPU 에서 호출되기 때문에 연결 방향은 항상 호스트(CPU)에서 디바이스(GPU)까지입니다CPU. 연결 탭에는 선택한 커널 시작 및 실행 쌍이 표시됩니다. 둘 중 하나를 선택하여 타임라인 보기의 중앙으로 이동할 수 있습니다.
다음 스크린샷은 AllReduce 작업 시작 및 실행 쌍을 더 확대하여 보여줍니다.
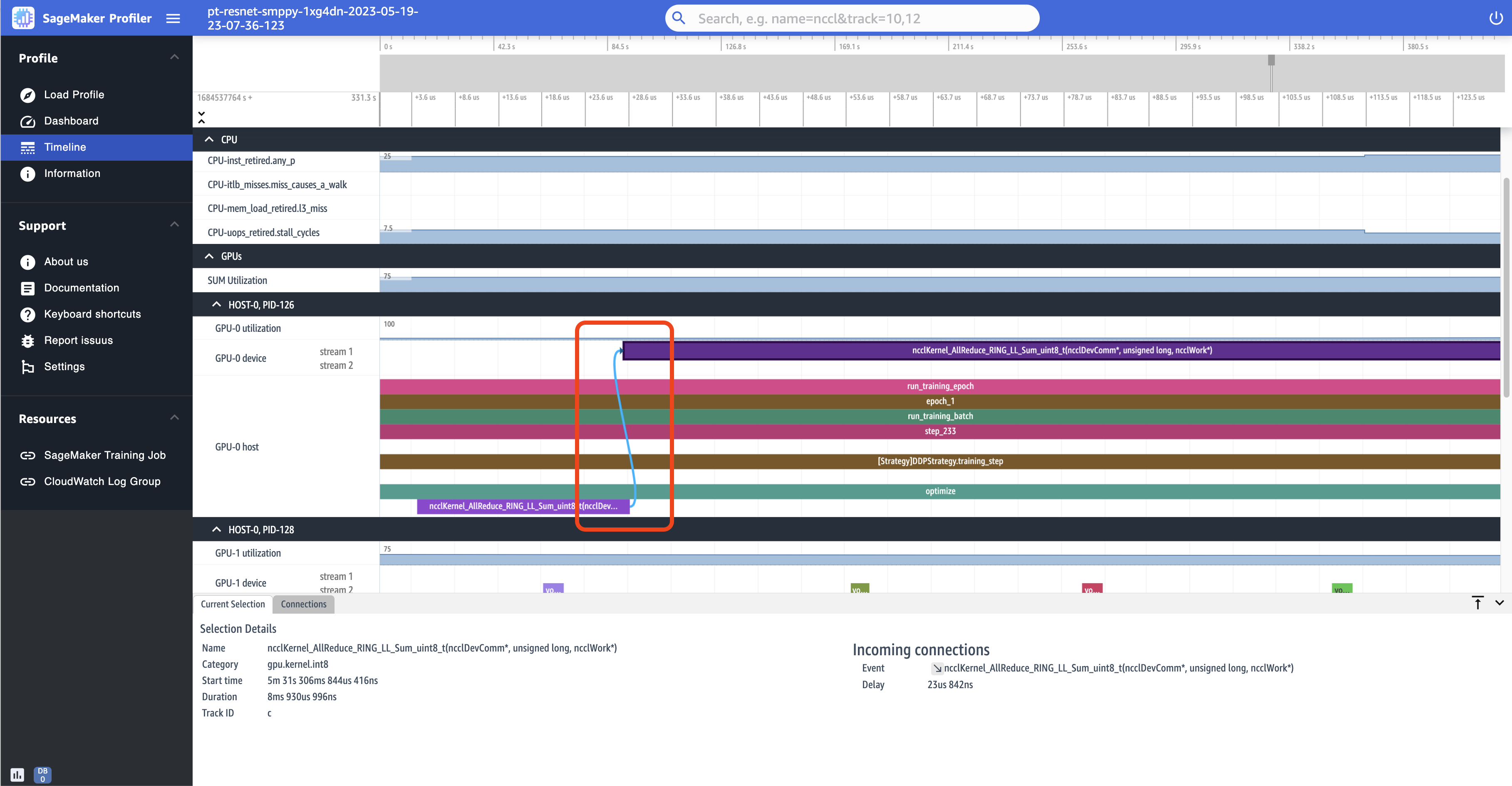
정보
정보 에서 인스턴스 유형, 작업에 프로비저닝된 컴퓨팅 리소스의 Amazon 리소스 이름(ARNs), 노드 이름 및 하이퍼파라미터와 같은 로드된 훈련 작업에 대한 정보에 액세스할 수 있습니다.
설정
SageMaker Profiler UI 애플리케이션 인스턴스는 기본적으로 유휴 시간 2시간 후 종료되도록 구성됩니다. 설정에서 다음 설정을 사용하여 자동 종료 타이머를 조정할 수 있습니다.
-
앱 자동 종료 활성화 - 지정된 유휴 시간이 지나면 애플리케이션이 자동으로 종료되도록 선택하고 활성화로 설정합니다. 자동 종료 기능을 끄려면 비활성화를 선택합니다.
-
자동 종료 임곗값(시간) - 앱 자동 종료 활성화에서 활성화를 선택하면 애플리케이션이 자동으로 종료되는 임곗값을 시간 단위로 설정할 수 있습니다. 기본값은 2시간으로 설정되어 있습니다.
