기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
모델 성능 보고서
Amazon SageMaker AI 모델 품질 보고서(성능 보고서라고도 함)는 AutoML 작업에서 생성된 최상의 모델 후보에 대한 인사이트와 품질 정보를 제공합니다. 여기에는 작업 세부 정보, 모델 문제 유형, 목표 함수 및 다양한 지표에 대한 정보가 포함됩니다. 이 섹션에서는 텍스트 분류 문제에 대한 성능 보고서의 내용을 자세히 설명하고 지표에 JSON 파일의 원시 데이터로 액세스하는 방법을 설명합니다.
BestCandidate.CandidateProperties.CandidateArtifactLocations.ModelInsights에서 DescribeAutoMLJobV2에 대한 응답에 최적의 후보에 대해 생성된 모델 품질 보고서 아티팩트의 Amazon S3 접두사를 찾을 수 있습니다.
성능 보고서에는 다음 두 섹션이 있습니다.
-
첫 번째 섹션에는 모델을 생성한 Autopilot 작업에 대한 세부 정보가 포함되어 있습니다.
-
두 번째 섹션에는 다양한 성능 지표가 포함된 모델 품질 보고서가 포함되어 있습니다.
Autopilot 작업 세부 정보
보고서의 첫 번째 섹션에서는 모델을 생성한 Autopilot 작업에 대한 몇 가지 일반적인 정보를 제공합니다. 이러한 세부 정보에는 다음 정보가 포함되어 있습니다.
-
Autopilot 후보 이름: 최적의 모델 후보 이름.
-
Autopilot 작업 이름: 작업의 이름입니다.
-
문제 유형: 문제 유형입니다. 여기서는 텍스트 분류입니다.
-
목표 지표: 모델의 성능을 최적화하는 데 사용되는 목표 지표입니다. 여기서는 정확도입니다.
-
최적화 방향: 목표 지표를 최소화할지 최대화할지를 나타냅니다.
모델 품질 보고서
모델 품질 정보는 Autopilot 모델 인사이트를 통해 생성됩니다. 생성되는 보고서 내용은 보고서에서 다루는 문제 유형에 따라 달라집니다. 보고서는 평가 데이터세트에 포함된 행 수와 평가가 발생한 시간을 지정합니다.
지표 테이블
모델 품질 보고서의 첫 번째 부분에는 지표 테이블이 포함되어 있습니다. 이는 모델이 해결한 문제 유형에 적합합니다.
다음 이미지는 이미지 또는 텍스트 분류 문제에 대해 Autopilot으로 생성된 지표 테이블의 예제입니다. 지표 이름, 값 및 표준 편차를 보여줍니다.
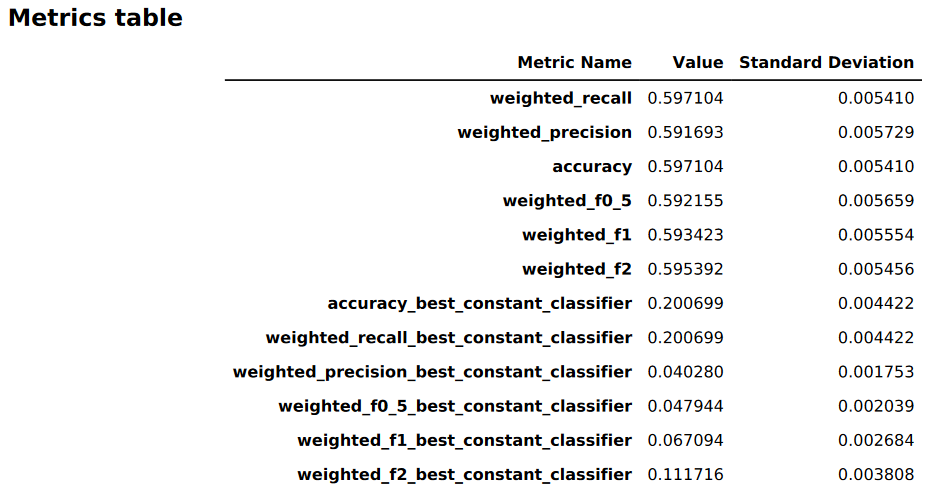
그래픽 모델 성능 정보
모델 품질 보고서의 두 번째 부분에는 모델 성능을 평가하는 데 도움이 되는 그래픽 정보가 포함되어 있습니다. 이 섹션의 내용은 선택한 문제 유형에 따라 달라집니다.
혼동 행렬
혼동 행렬은 다양한 문제에 대한 바이너리 및 멀티클래스 분류에 대한 모델의 예측 정확도를 시각화하는 방법을 제공합니다.
그래프의 구성 요소 중 위양성률(FPR)과 진양성률(TPR)의 요약은 다음과 같이 정의됩니다.
-
올바른 예측
-
진양성(TP): 예측값이 1이고 실제 값도 1입니다.
-
진음성(TN): 예측 값이 0이고 실제 값도 0입니다.
-
-
잘못된 예측
-
위양성(FP): 예측 값은 1이지만 실제 값은 0입니다.
-
위음성(FN): 예측값은 0이고, 실제값은 1입니다.
-
모델 품질 보고서의 혼동 행렬에는 다음이 포함됩니다.
-
실제 레이블에 대한 정확한 예측과 잘못된 예측의 수와 백분율
-
왼쪽 상단에서 오른쪽 아래 모서리까지의 대각선 상의 정확한 예측 수 및 백분율
-
상단 오른쪽에서 왼쪽 아래 모서리까지의 대각선 상의 부정확한 예측의 수와 백분율
혼동 행렬의 부정확한 예측은 혼동 값입니다.
다음 다이어그램은 멀티클래스 분류 문제에 대한 혼동 행렬의 예를 보여줍니다. 모델 품질 보고서의 혼동 행렬에는 다음이 포함됩니다.
-
세로축은 서로 다른 세 개의 실제 레이블을 포함하는 세 개의 행으로 나뉩니다.
-
가로 축은 모델에서 예측한 레이블을 포함하는 세 개의 열로 나뉩니다.
-
색상 막대는 많은 수의 샘플에 어두운 색조를 할당하여 각 범주에서 분류된 값의 수를 시각적으로 나타냅니다.
아래 예제에서 모델은 레이블 f의 실제값 354, 레이블 i의 실제값 1094, 레이블 m의 실제값 852를 정확하게 예측했습니다. 색조의 차이는 f 또는 m 값에 대한 것보다 i 값에 대한 레이블이 많기 때문에 데이터세트의 균형이 맞지 않는다는 것을 나타냅니다.
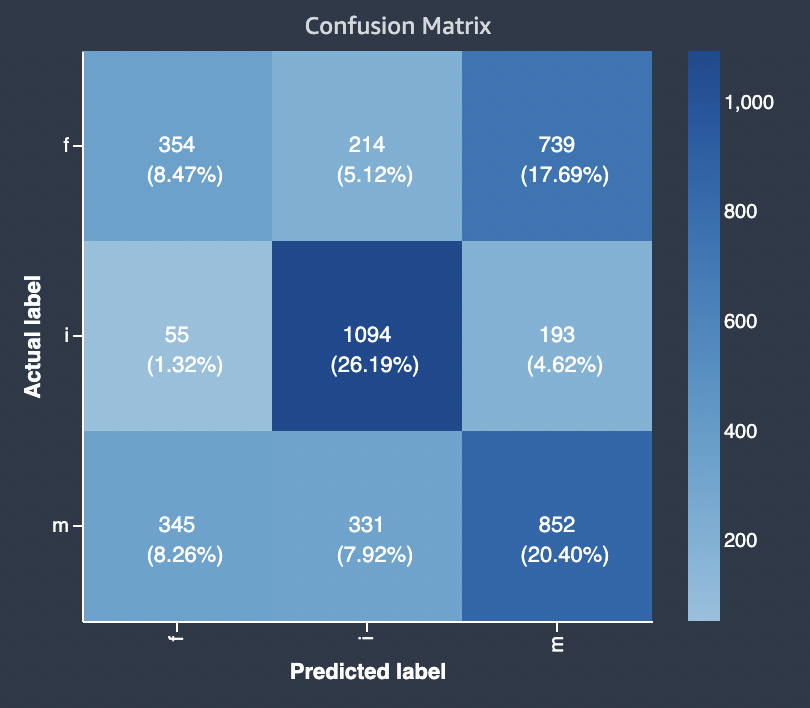
제공된 모델 품질 보고서의 혼동 행렬은 멀티클래스 분류 문제 유형에 대해 최대 15개의 레이블을 수용할 수 있습니다. 레이블에 해당하는 행에 Nan 값이 표시되면, 모델 예측을 확인하는 데 사용되는 검증 데이터세트에 해당 레이블의 데이터가 포함되어 있지 않다는 의미입니다.
