기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
SageMaker 훈련 컴파일러 문제 해결
중요
Amazon Web Services(AWS)는 SageMaker 훈련 컴파일러의 새 릴리스 또는 버전이 없을 것이라고 발표했습니다. SageMaker 훈련을 위한 기존 AWS 딥 러닝 컨테이너(DLC)를 통해 SageMaker 훈련 컴파일러를 계속 활용할 수 있습니다. 기존 DLCs는 계속 액세스할 수 있지만 딥 러닝 컨테이너 프레임워크 지원 정책에 AWS따라 더 이상에서 패치 또는 업데이트를 받지 않는다는 점에 유의해야 합니다. AWS
오류가 발생하는 경우 다음 목록을 사용하여 훈련 작업 문제를 해결할 수 있습니다. 추가 지원이 필요한 경우 Amazon SageMaker AI용 AWS 지원
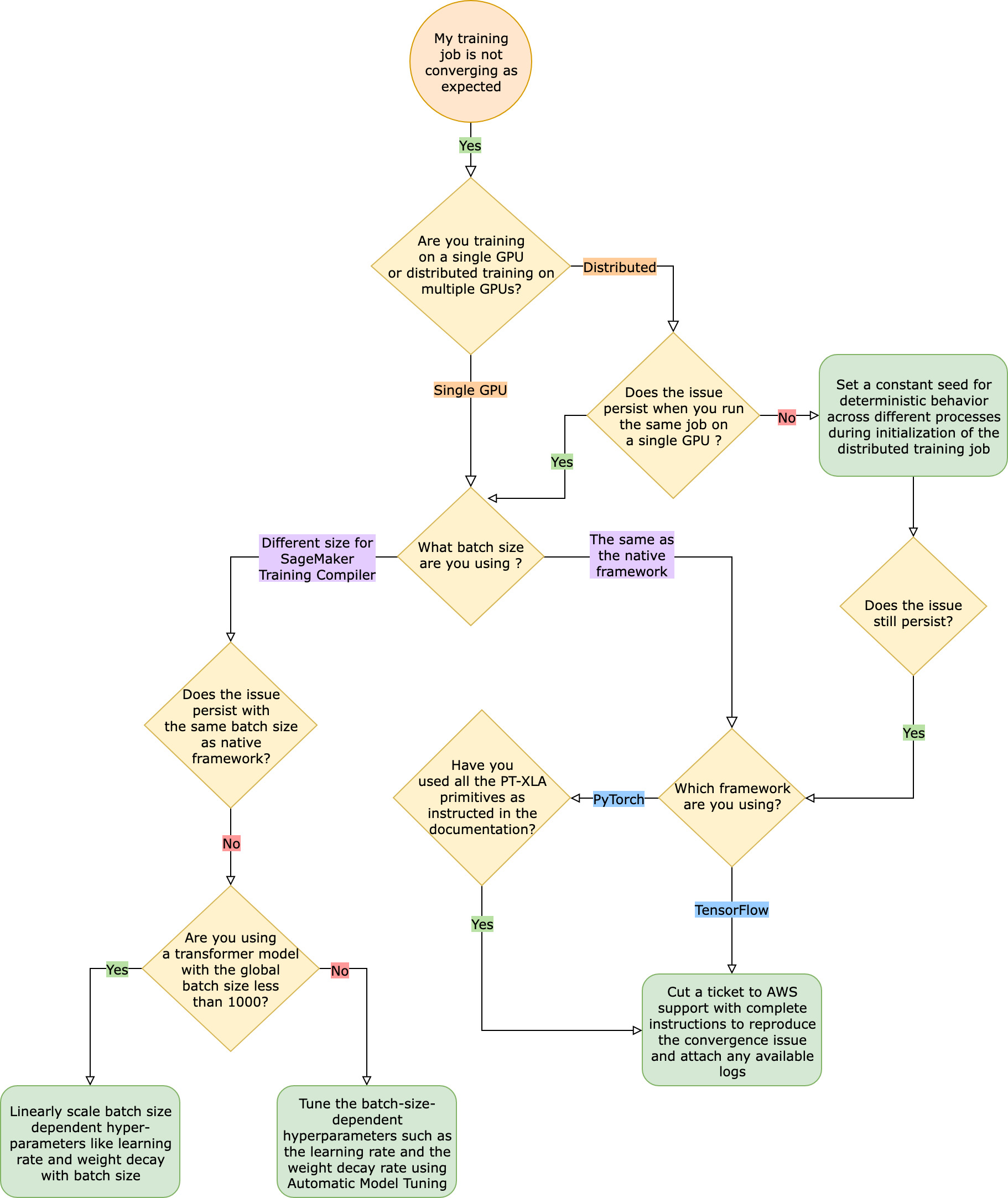
네이티브 프레임워크 훈련 작업과 비교했을 때 훈련 작업이 예상대로 수렴되지 않습니다.
수렴 문제는 “SageMaker 훈련 컴파일러가 켜져 있을 때 모델이 학습하지 않음”에서 “모델이 학습하고 있지만 네이티브 프레임워크보다 느림”까지 다양합니다. 이 문제 해결 가이드는 SageMaker 훈련 컴파일러(네이티브 프레임워크에서)를 사용하지 않아도 수렴이 정상이라고 가정하고 이를 기준으로 간주합니다.
이러한 수렴 문제에 직면했을 때 첫 번째 단계는 문제가 분산 훈련에만 국한된 것인지 아니면 단일 GPU 훈련에서 비롯된 것인지 파악하는 것입니다. SageMaker 훈련 컴파일러를 사용한 분산 훈련은 추가 단계가 포함된 단일 GPU 훈련의 확장입니다.
-
다중 인스턴스 또는 GPU로 클러스터를 설정합니다.
-
입력 데이터를 모든 작업자에게 배포합니다.
-
모든 작업자의 모델 업데이트를 동기화합니다.
따라서 단일 GPU 훈련의 모든 수렴 문제는 여러 작업자가 있는 분산 훈련으로 전파됩니다.
단일 GPU 훈련에서 발생하는 수렴 문제
수렴 문제가 단일 GPU 훈련에서 비롯된 경우 하이퍼파라미터 또는 torch_xla API의 부적절한 설정 때문일 수 있습니다.
하이퍼파라미터 확인
SageMaker 훈련 컴파일러를 사용한 훈련은 모델의 메모리 사용량을 변화시킵니다. 컴파일러는 재사용과 재계산을 지능적으로 조정하여 그에 따라 메모리 사용량을 늘리거나 줄입니다. 이를 활용하려면 훈련 작업을 SageMaker 훈련 컴파일러로 마이그레이션할 때 배치 크기 및 관련 하이퍼파라미터를 다시 조정해야 합니다. 하이퍼파라미터 설정이 올바르지 않으면 훈련 손실이 진동하고 그 결과 수렴 속도가 느려질 수 있습니다. 드문 경우이긴 하지만, 과도한 하이퍼파라미터로 인해 모델이 학습되지 않을 수 있습니다(훈련 손실 지표는 NaN을(를) 감소하거나 반환하지 않음) 수렴 문제가 하이퍼파라미터 때문인지 확인하려면 모든 하이퍼파라미터를 동일하게 유지하면서 SageMaker 훈련 컴파일러를 사용하는 작업과 사용하지 않는 훈련 작업 두 개를 나란히 테스트하세요.
torch_xla API가 단일 GPU 훈련에 맞게 제대로 설정되었는지 확인하세요.
기본 하이퍼파라미터에 수렴 문제가 지속되면 torch_xla API, 특히 모델 업데이트를 위한 해당 API의 부적절한 사용이 있는지 확인해야 합니다. 기본적으로 torch_xla은(는) 누적된 그래프를 실행하라는 명시적인 지시가 있을 때까지 그래프 형태로 명령을 계속 누적(실행 지연)합니다. torch_xla.core.xla_model.mark_step() 함수를 사용하면 누적된 그래프를 쉽게 실행할 수 있습니다. 각 모델 업데이트 후, 변수를 인쇄 및 기록하기 전에 이 함수를 사용하여 그래프 실행을 동기화해야 합니다. 동기화 단계가 없는 경우 모델은 모든 반복 및 모델 업데이트 후 동기화해야 하는 최신 값을 사용하는 대신 인쇄, 로그 및 후속 전달 과정에 메모리의 오래된 값을 사용할 수 있습니다.
SageMaker 훈련 컴파일러를 그라데이션 스케일링(AMP 사용으로 인한) 또는 그라데이션 클리핑 기법과 함께 사용하면 더 복잡해질 수 있습니다. AMP를 사용한 적절한 그라데이션 계산 순서는 다음과 같습니다.
-
스케일링을 통한 그라데이션 계산
-
그라데이션 스케일링 해제, 그라데이션 클리핑 후 스케일링
-
모델 업데이트
-
그래프 실행을
mark_step()와(과) 동기화합니다.
목록에 언급된 작업에 적합한 API를 찾으려면 훈련 스크립트를 SageMaker 훈련 컴파일러로 마이그레이션하기 가이드를 참조하세요.
자동 모델 튜닝을 사용해 보세요.
SageMaker 훈련 컴파일러를 사용하는 동안 배치 크기 및 관련 하이퍼파라미터(예: 학습률)를 재조정할 때 수렴 문제가 발생하는 경우 자동 모델 튜닝을 사용하여 하이퍼파라미터를 조정하는 것을 고려해 보세요. SageMaker 훈련 컴파일러의 하이퍼파라미터 튜닝에 대한 예제 노트북
분산 훈련에서 발생하는 수렴 문제
분산 훈련에서도 수렴 문제가 지속된다면 이는 가중치 초기화 또는 torch_xla API에 대한 부적절한 설정 때문일 수 있습니다.
작업자 전체의 가중치 초기화를 확인하세요.
여러 작업자를 사용하여 분산 훈련 작업을 실행할 때 수렴 문제가 발생하는 경우, 해당하는 경우 상수 시드를 설정하여 모든 작업자에게 일관된 결정적 동작이 적용되도록 하세요. 무작위화를 포함하는 가중치 초기화와 같은 기법에 주의하세요. 상수 시드가 없으면 각 작업자가 다른 모델을 훈련하게 될 수도 있습니다.
torch_xla API가 분산 훈련에 맞게 제대로 설정되었는지 확인하세요.
문제가 지속된다면 분산 훈련에 torch_xla API를 잘못 사용했기 때문일 수 있습니다. SageMaker 훈련 컴파일러를 사용하여 분산 훈련을 위한 클러스터를 설정하려면 예측기에 다음을 추가해야 합니다.
distribution={'torchxla': {'enabled': True}}
여기에는 작업자당 한 번씩 간접 호출되는 훈련 스크립트의 _mp_fn(index) 함수가 함께 포함되어야 합니다. mp_fn(index) 함수가 없으면 각 작업자가 모델 업데이트를 공유하지 않고 독립적으로 모델을 훈련하게 될 수 있습니다.
다음으로, 다음 예제와 같이 훈련 스크립트를 SageMaker 훈련 컴파일러로 마이그레이션하는 방법 설명서의 지침에 따라 torch_xla.distributed.parallel_loader.MpDeviceLoader API를 분산 데이터 샘플러와 함께 사용해야 합니다.
torch.utils.data.distributed.DistributedSampler()
이렇게 하면 입력 데이터가 모든 작업자에게 적절하게 배포될 수 있습니다.
마지막으로, 모든 작업자의 모델 업데이트를 동기화하려면 torch_xla.core.xla_model._fetch_gradients을(를) 사용하여 모든 작업자로부터 그라데이션을 수집하고 torch_xla.core.xla_model.all_reduce을(를) 사용해 수집된 모든 그라데이션을 단일 업데이트로 결합합니다.
SageMaker 훈련 컴파일러를 그라데이션 스케일링(AMP 사용으로 인한) 또는 그라데이션 클리핑 기법과 함께 사용하면 더 복잡해질 수 있습니다. AMP를 사용한 적절한 그라데이션 계산 순서는 다음과 같습니다.
-
스케일링을 통한 그라데이션 계산
-
모든 작업자 간의 그라데이션 동기화
-
그라데이션 스케일링 해제, 그라데이션 클리핑 후 그라데이션 스케일링
-
모델 업데이트
-
그래프 실행을
mark_step()와(과) 동기화합니다.
참고로 이 체크리스트에는 단일 GPU 훈련 체크리스트와 비교하여 모든 작업자를 동기화하기 위한 추가 항목이 있습니다.
PyTorch/XLA 구성 누락으로 인한 훈련 작업 실패
훈련 작업이 실패하고 Missing XLA configuration 오류 메시지가 표시되는 경우, 사용하는 인스턴스당 GPU 수가 잘못 구성되었기 때문일 수 있습니다.
XLA를 사용하려면 훈련 작업을 컴파일하기 위한 추가 환경 변수가 필요합니다. 가장 일반적으로 누락되는 환경 변수는 GPU_NUM_DEVICES입니다. 컴파일러가 제대로 작동하려면 이 환경 변수를 인스턴스당 GPU 수와 동일하게 설정해야 합니다.
GPU_NUM_DEVICES 환경 변수를 설정하는 세 가지 방법이 있습니다.
-
접근 방식 1 - SageMaker AI 예측기 클래스의
environment인수를 사용합니다. 예를 들어 GPU가 4개인ml.p3.8xlarge인스턴스를 사용하는 경우 다음을 수행하세요.# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
접근 방식 2 - SageMaker AI 예측기 클래스의
hyperparameters인수를 사용하여 훈련 스크립트에서 구문 분석합니다.-
GPU 수를 지정하려면
hyperparameters인수에 키-값 쌍을 추가하세요.예를 들어 GPU가 4개인
ml.p3.8xlarge인스턴스를 사용하는 경우 다음을 수행하세요.# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
훈련 스크립트에서
n_gpus하이퍼파라미터를 파싱하고 이를GPU_NUM_DEVICES환경 변수의 입력으로 지정합니다.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
접근법 3 - 훈련 스크립트에서
GPU_NUM_DEVICES환경 변수를 하드 코딩합니다. 예를 들어, GPU가 4개인 인스턴스를 사용하는 경우 스크립트에 다음을 추가하세요.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
작은 정보
사용하려는 기계 학습 인스턴스의 GPU 디바이스 수를 확인하려면 Amazon EC2 인스턴스 유형 페이지의 액셀러레이티드 컴퓨팅
SageMaker 훈련 컴파일러를 사용해도 총 훈련 시간이 줄지 않습니다.
SageMaker 훈련 컴파일러를 사용해도 총 훈련 시간이 줄어들지 않는 경우 SageMaker 훈련 컴파일러 모범 사례 및 고려 사항 페이지를 검토하여 훈련 구성, 입력 텐서 셰이프에 대한 패딩 전략 및 하이퍼파라미터를 확인하는 것이 좋습니다.
