Migração física do MySQL usando o Percona XtraBackup e o Amazon S3
Você pode copiar os arquivos de backup completos e incrementais do banco de dados MySQL de origem, versão 5.7 ou 8.0, para um bucket do Amazon S3. Em seguida, você pode restaurar para um cluster de banco de dados do Amazon Aurora MySQL com a mesma versão principal do mecanismo de banco de dados desses arquivos.
Essa opção pode ser considerada mais rápida do que migrar dados usando mysqldump, pois o uso de mysqldump repete todos os comandos para recriar o esquema e os dados do seu banco de dados de origem no novo cluster de banco de dados Aurora MySQL. Ao copiar os arquivos de dados de origem MySQL, o Aurora MySQL pode usá-los imediatamente como dados para um cluster de banco de dados do Aurora MySQL.
Você pode também minimizar o tempo de inatividade usando a replicação de log binário durante o processo de migração. Se você usar a replicação de log binário, ao banco de dados externo de MySQL permanece aberta para transações enquanto os dados estão sendo migrados para o cluster de banco de dados Aurora MySQL. Depois do cluster de banco de dados do Aurora MySQL ter sido criado, você usa a replicação de log binário para sincronizar o cluster de banco de dados do Aurora MySQL com as transações que aconteceram depois do backup. Quando o cluster de banco de dados do Aurora MySQL é acessado com o banco de dados do MySQL, você conclui a migração trocando completamente para o cluster de banco de dados do Aurora MySQL para novas transações. Para obter mais informações, consulte Sincronizar o cluster do banco de dados do Amazon Aurora MySQL com banco de dados MySQL usando a replicação.
Sumário
Limitações e considerações
As limitações e considerações a seguir se aplicam à restauração para um cluster de banco de dados do Amazon Aurora MySQL usando um bucket do Amazon S3:
-
Você pode migrar os dados somente para um novo cluster de banco de dados e não para um cluster existente.
-
Use o Percona XtraBackup para fazer backup de dados no S3. Para obter mais informações, consulte Instalação do Percona XtraBackup.
-
O bucket do Amazon S3 e o cluster de banco de dados do Aurora MySQL devem estar localizados na mesma região da AWS.
-
Não é possível restaurar nos seguintes casos:
-
De uma exportação de snapshot de cluster de banco de dados para o Amazon S3. Também não é possível migrar dados de uma exportação de snapshot de cluster de banco de dados para o bucket do S3.
-
De um banco de dados de origem criptografado. Mas é possível criptografar os dados que estão sendo migrados. Também é possível deixar os dados não criptografados durante o processo de migração.
-
De um banco de dados MySQL 5.5 ou 5.6.
-
-
O Percona Server para MySQL não é aceito como banco de dados de origem porque ele pode conter tabelas
compression_dictionary*no esquemamysql. -
Não é possível realizar uma restauração para um cluster de banco de dados do Aurora Serverless.
-
A reversão de migrações não é uma operação compatível com versões principais nem com secundárias. Por exemplo, não é possível migrar do MySQL versão 8.0 para o Aurora MySQL versão 2 (compatível com o MySQL 5.7) nem do MySQL versão 8.0.32 para o Aurora MySQL versão 3.03, que é compatível com a versão 8.0.26 da comunidade do MySQL.
-
Não é possível migrar de algumas versões anteriores a 8.0 do MySQL para o Aurora MySQL 3.05, incluindo 8.0.11, 8.0.13 e 8.0.15. Recomendamos que você atualize para a versão 8.0.28 do MySQL antes da migração.
-
Não é possível fazer importações do Amazon S3 na classe de instância de banco de dados db.t2.micro. Contudo, é possível restaurar para outra classe de instância de banco de dados e alterar a instância de banco de dados posteriormente. Para ter mais informações sobre classes de instância de banco de dados, consulte Classes de instâncias de banco de dados do Amazon Aurora.
-
O Amazon S3 limita o tamanho de um arquivo carregado para um bucket do S3 a 5 TB. Se um arquivo de backup exceder 5 TB, você deverá dividi o arquivo de backup em arquivos menores.
-
O Amazon RDS limita a 1 milhão o número de arquivos carregados para um bucket do S3. Se os dados de backup do banco de dados, incluindo todos os backups completos e incrementais, exceder 1 milhão de arquivos, use um arquivo Gzip (.gz), tar (.tar.gz) ou Percona xbstream (.xbstream) para armazenar arquivos de backup completos e incrementais no bucket do S3. O Percona XtraBackup 8.0 oferece suporte apenas ao Percona xbstream para compactação.
-
Para fornecer serviços de gerenciamento para cada cluster de banco de dados, o usuário
rdsadminé criado quando o cluster de banco de dados é criado. Como esse é um usuário reservado no RDS, as seguintes limitações se aplicam:-
Funções, procedimentos, visualizações, eventos e acionadores com o
'rdsadmin'@'localhost'como definidor não são importados. Para obter mais informações, consulte Objetos armazenados com ‘rdsadmin'@'localhost’ como definidor e Privilégios de usuário mestre com Amazon Aurora MySQL.. -
Quando o cluster de banco de dados do Aurora MySQL é criado, um usuário principal é criado com os privilégios máximos aceitos. Na restauração por meio de backup, quaisquer privilégios incompatíveis atribuídos aos usuários que estão sendo importados são removidos automaticamente durante a importação.
Para identificar usuários que possam ser afetados por isso, consulteContas de usuário com privilégios não compatíveis. Para obter mais informações sobre privilégios compatíveis no Aurora MySQL, consulte Modelo de privilégios baseados em funções.
-
-
No Aurora MySQL versão 3, os privilégios dinâmicos não são importados. Os privilégios dinâmicos aceitos pelo Aurora podem ser importados após a migração. Para obter mais informações, consulte Privilégios dinâmicos no Aurora MySQL versão 3.
-
Tabelas criadas pelo usuário no esquema do
mysqlnão são migradas. -
O parâmetro
innodb_data_file_pathdeve ser configurado com apenas um arquivo de dados que usa o nome de arquivo de dados padrãoibdata1:12M:autoextend. Bancos de dados com dois arquivos de dados ou com um arquivo de dados com um nome diferente não podem ser migrados usando esse método.Veja a seguir, exemplos de nomes de arquivos que não são permitidos:
innodb_data_file_path=ibdata1:50M,ibdata2:50M:autoextendeinnodb_data_file_path=ibdata01:50M:autoextend. -
Não é possível migrar de um banco de dados de origem que tenha tabelas definidas fora do diretório de dados MySQL padrão.
-
No momento, o tamanho máximo aceito para backups não compactados usando esse método é 64 TiB. Para backups compactados, esse limite é menor para levar em conta os requisitos de espaço sem compactação. Nesses casos, o tamanho máximo de backup aceito seria
64 TiB – compressed backup size. -
O Aurora MySQL não é compatível com a importação do MySQL e de outros componentes e plug-ins externos.
-
O Aurora MySQL não restaura tudo do seu banco de dados. Recomendamos salvar o esquema do banco de dados e os valores dos itens do banco de dados MySQL de origem relacionados abaixo e adicioná-los ao cluster de banco de dados do Aurora MySQL restaurado depois que ele for criado:
-
Contas de usuário
-
Funções
-
Procedimentos armazenados
-
Informações de fuso horário. As informações de fuso horário são carregadas do sistema operacional local do cluster de banco de dados do Aurora MySQL. Para obter mais informações, consulte Fuso horário local para os clusters de bancos de dados Amazon Aurora.
-
Antes de começar
Antes de copiar os dados para um bucket do Amazon S3 e restaurar um cluster de banco de dados desses arquivos, faça o seguinte:
-
Instale o Percona XtraBackup no seu servidor local.
-
Permita que o Aurora MySQL acesse o seu bucket do Amazon S3 em seu nome.
Instalação do Percona XtraBackup
O Amazon Aurora pode restaurar um cluster de banco de dados a partir de arquivos criados com o Percona XtraBackup. Você pode instalar o Percona XtraBackup em Software Downloads - Percona
Para migração do MySQL 5.7, use o Percona XtraBackup 2.4.
Para migração do MySQL 8.0, use o Percona XtraBackup 8.0. Verifique se a versão do Percona XtraBackup é compatível com a versão do mecanismo do banco de dados de origem.
Permissões obrigatórias
Para migrar os dados do MySQL para um cluster de banco de dados do Amazon Aurora MySQL, são necessárias várias permissões:
-
O usuário que está solicitando que o Aurora crie um novo cluster de um bucket do Amazon S3 deve ter permissão para listar os buckets da sua conta da AWS. Você concede essa permissão ao usuário usando uma política do AWS Identity and Access Management (IAM).
-
O Aurora exige permissão para atuar em seu nome e acessar o bucket do Amazon S3 em que você armazena os arquivos usados para criar o cluster de banco de dados do Amazon Aurora MySQL. Conceda ao Aurora as permissões necessárias usando uma função de serviço do IAM.
-
O usuário que faz a solicitação também deve ter permissão para indicar as funções do IAM de sua conta da AWS.
-
Se o usuário que faz a solicitação for criar a função de serviço do IAM ou solicitar que o Aurora crie a função de serviço do IAM (usando o console), ele deverá ter permissão para criar uma função do IAM para sua conta da AWS.
-
Se você pretende criptografar os dados durante o processo de migração, atualize a política do IAM do usuário responsável pela migração para conceder acesso do RDS às AWS KMS keys usadas para criptografar os backups. Para instruções, consulte Criar uma política do IAM para acessar recursos do AWS KMS.
Por exemplo, a política do IAM a seguir concede a um usuário as permissões mínimas exigidas para usar o console para listar funções do IAM, criar uma função do IAM, listar os buckets do Amazon S3 para a sua conta e listar as chaves do KMS.
Além disso, para um usuário associar uma função do IAM a um bucket do Amazon S3, o usuário do IAM deve ter a permissão iam:PassRole para aquela função do IAM. Essa permissão autoriza que um administrador restrinja as funções do IAM que um usuário pode associar a buckets do Amazon S3.
Por exemplo, a seguinte política do IAM permite que um usuário associe a função chamada S3Access a um bucket do Amazon S3.
Para obter mais informações sobre as permissões de usuário do IAM, consulte Gerenciamento do acesso usando políticas.
Criar a função de serviço do IAM
Para solicitar que o Console de gerenciamento da AWS crie uma função para você, selecione a opção Create a New Role (Criar uma nova função) (mostrada posteriormente neste tópico). Se você selecionar essa opção e especificar um nome para a nova função, o Aurora criará a função de serviço do IAM necessária para o Aurora acessar o bucket do Amazon S3 com o nome fornecido.
Você também pode criar a função manualmente usando o procedimento seguinte.
Como criar uma função do IAM para o Aurora acessar o Amazon S3
-
Siga as etapas em Criar uma política do IAM para acessar recursos do Amazon S3.
-
Siga as etapas em Criar uma função do IAM para permitir que o Amazon Aurora acesse produtos da AWS.
-
Siga as etapas em Associar uma função do IAM a um cluster de banco de dados do Amazon Aurora MySQL.
Fazer backup de arquivos a serem restaurados como um cluster de banco de dados do Amazon Aurora MySQL
Você pode criar um backup completo de seus arquivos de banco de dados MySQL usando o Percona XtraBackup e fazer upload dos arquivos de backup em um bucket do Amazon S3. Ou, se você já usa o Percona XtraBackup para fazer o backup dos arquivos do banco de dados MySQL, pode fazer upload dos arquivos e diretórios de backup completos e incrementais em um bucket do Amazon S3.
Tópicos
Criar um backup completo com o Percona XtraBackup
Para criar um backup completo dos arquivos do banco de dados MySQL que podem ser restaurados do Amazon S3 para criar um cluster de banco de dados do Aurora MySQL, use o utilitário Percona XtraBackup (xtrabackup) para fazer backup do banco de dados.
Por exemplo, o seguinte comando cria um backup de um banco de dados MySQL e armazena os arquivos na pasta /on-premises/s3-restore/backup.
xtrabackup --backup --user=<myuser>--password=<password>--target-dir=</on-premises/s3-restore/backup>
Se você deseja compactar o backup em um único arquivo (que pode ser dividido, se necessário), use a opção --stream para salvar o backup em um dos seguintes formatos:
-
Gzip (.gz)
-
tar (.tar)
-
Percona xbstream (.xbstream)
O comando a seguir cria um backup do seu banco de dados MySQL dividido em vários arquivos Gzip.
xtrabackup --backup --user=<myuser>--password=<password>--stream=tar \ --target-dir=</on-premises/s3-restore/backup>| gzip - | split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.tar.gz
O comando a seguir cria um backup do seu banco de dados MySQL dividido em vários arquivos tar.
xtrabackup --backup --user=<myuser>--password=<password>--stream=tar \ --target-dir=</on-premises/s3-restore/backup>| split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.tar
O comando a seguir cria um backup do seu banco de dados MySQL dividido em vários arquivos xbstream.
xtrabackup --backup --user=<myuser>--password=<password>--stream=xbstream \ --target-dir=</on-premises/s3-restore/backup>| split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.xbstream
nota
Se você vir o erro a seguir, saiba que ele pode ser causado pela mistura de formatos de arquivo em seu comando:
ERROR:/bin/tar: This does not look like a tar archive
Após fazer o backup do seu banco de dados MySQL usando o utilitário Percona XtraBackup, você poderá copiar os arquivos e diretórios de backup para um bucket do Amazon S3.
Para obter informações sobre a criação e o upload de um arquivo para um bucket do Amazon S3, consulte Conceitos básicos do Amazon Simple Storage Service, no Guia de conceitos básicos do Amazon S3.
Usar backups incrementais com o Percona XtraBackup
O Amazon Aurora MySQL oferece suporte a backups completos e incrementais criados com o Percona XtraBackup. Se você já usa o Percona XtraBackup para fazer backups completos e incrementais de seus arquivos de banco de dados MySQL, não precisa criar um backup completo e fazer upload dos arquivos de backup no Amazon S3. Em vez disso, você pode economizar muito tempo copiando os diretórios e arquivos de backup existentes para seus backups completos e incrementais para um bucket do Amazon S3. Para obter mais informações, consulte Create an incremental backup
Quando copiar os arquivos existentes de backup completo e incremental para um bucket do Amazon S3, copie recursivamente o conteúdo do diretório de base. Esse conteúdo inclui o backup completo e também todo o backup incremental dos diretórios e arquivos. Essa cópia deve preservar a estrutura de diretórios no bucket do Amazon S3. O Aurora percorre todos os arquivos e diretórios. O Aurora usa o arquivo xtrabackup-checkpoints incluído em cada backup incremental para identificar o diretório de base e ordenar os backups incrementais por intervalo de número de sequência de log (LSN).
Para obter informações sobre a criação e o upload de um arquivo para um bucket do Amazon S3, consulte Conceitos básicos do Amazon Simple Storage Service, no Guia de conceitos básicos do Amazon S3.
Considerações sobre backup
O Aurora não oferece suporte a backups parciais criados com o Percona XtraBackup. Você não pode usar as seguintes opções para criar um backup parcial quando faz backup dos arquivos de origem de seu banco de dados: --tables, --tables-exclude, --tables-file, --databases, --databases-exclude ou --databases-file.
Para ter mais informações sobre como fazer backup do banco de dados com o Percona XtraBackup, consulte Percona XtraBackup - Documentation
O Aurora oferece suporte a backups incrementais criados com o Percona XtraBackup. Para obter mais informações, consulte Create an incremental backup
O Aurora consome seus arquivos de backup com base no nome do arquivo. Renomeie seus arquivos de backup com a extensão de arquivo apropriada com base no formato do arquivo — por exemplo, .xbstream para arquivos armazenados usando o formato Percona xbstream.
O Aurora consome os arquivos de backup em ordem alfabética assim como na ordem numérica natural. Sempre use a opção split ao emitir o comando xtrabackup para garantir que os arquivos de backup sejam gravados e nomeados na ordem apropriada.
O Amazon S3 limita o tamanho de um arquivo carregado para um bucket do Amazon S3 a 5 TB. Se os dados de backup do seu banco de dados ultrapassarem 5 TB, use o comando split para dividir os arquivos de backup em vários arquivos com menos de 5 TB cada.
O Aurora limita a 1 milhão o número de arquivos de origem enviados por upload para um bucket do Amazon S3. Em alguns casos, os dados de backup de seu banco de dados, incluindo todos os backups completos e incrementais, podem aumentar para um grande número de arquivos. Nesses casos, use um arquivo de tarball (.tar.gz) para armazenar arquivos completos e incrementais de backup no bucket Amazon S3.
Quando você carrega um arquivo no bucket Amazon S3, você pode usar criptografia por parte do servidor para criptografar os dados. Então você pode restaurar o cluster de banco de dados do Amazon Aurora MySQL a partir desses arquivos criptografados. O Amazon Aurora MySQL pode restaurar um cluster de banco de dados com arquivos criptografados usando os seguintes tipos de criptografia do lado do servidor:
-
Criptografia de servidor com chaves gerenciadas pelo Amazon S3 (SSE-S3) – cada objeto é criptografado com uma chave única empregando uma criptografia multifator forte.
-
Criptografia do lado do servidor com chaves gerenciadas pelo AWS KMS (SSE-KMS): semelhante à SSE-S3, mas com a opção de você mesmo criar e gerenciar chaves de criptografia, além de outras diferenças.
Para obter informações sobre como usar a criptografia do lado do servidor ao carregar arquivos para um bucket do Amazon S3, consulte Proteger dados usando a criptografia do lado do servidor no Guia de desenvolvedor do Amazon S3.
Restaurar um cluster de banco de dados do Amazon Aurora MySQL de um bucket do Amazon S3
É possível restaurar os arquivos de backup do bucket do Amazon S3 para criar um novo cluster de banco de dados do Amazon Aurora MySQL usando o console do Amazon RDS.
Para restaurar um cluster de banco de dados do Amazon Aurora MySQL a partir de arquivos em um bucket do Amazon S3
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No canto superior direito do console do console do Amazon RDS, escolha a região da AWS na qual deseja criar o cluster de banco de dados. Escolha o mesmo nome da região da AWS que o bucket Amazon S3 que contém o backup do banco de dados.
-
No painel de navegação, escolha Databases (Bancos de dados) e depois escolha Restore from S3 (Restaurar de S3).
-
Escolha Restore from S3 (Restaurar do S3).
A página Create database by restoring from S3 (Criar banco de dados restaurando a partir do S3) é exibida.

-
Em S3 destination (destino do S3):
-
Escolha o bucket do S3 que contém seus arquivos backup.
-
(Opcional) Em S3 folder path prefix (Prefixo do caminho da pasta do S3), digite um prefixo de caminho de arquivo para os arquivos armazenados no bucket do Amazon S3.
Se você não especificar um prefixo, o RDS criará a instância de banco de dados usando todos os arquivos e as pastas na pasta raiz do bucket do S3. Se você especificar um prefixo, o RDS criará a instância de banco de dados usando os arquivos e as pastas no bucket do S3 no qual o caminho para o arquivo começa com o prefixo especificado.
Por exemplo, suponha que você armazene seus arquivos de backup no S3 em uma subpasta denominada backups e que você tenha vários conjuntos de arquivos de backup, cada um em seu próprio diretório (gzip_backup1, gzip_backup2 e assim por diante). Nesse caso, especifique um prefixo de backups/gzip_backup1 para restaurar dos arquivos na pasta gzip_backup1.
-
-
Em Engine options (Opções de mecanismo):
-
Para Engine type (Tipo de mecanismo), escolha Amazon Aurora.
-
Em Version (Versão), escolha a versão do Aurora MySQL mecanismo para sua instância de banco de dados restaurada.
-
-
Para IAM role (Função do IAM), é possível escolher uma função existente do IAM.
-
(Opcional) Você também pode ter uma nova função do IAM escolhendo Create a New Role (Criar uma nova função). Em caso afirmativo:
-
Insira o IAM role name (Nome da função do IAM).
-
Escolha se deseja Allow access to KMS key (Permitir acesso à chave do KMS):
-
Se você não criptografou os arquivos de backup, escolha No (Não).
-
Se você criptografou os arquivos de backup com AES-256 (SSE-S3) ao fazer upload para o Amazon S3, escolha No (Não). Nesse caso, os dados são descriptografados automaticamente.
-
Se você criptografou os arquivos de backup com criptografia do lado do servidor do AWS KMS (SSE-KMS) ao fazer upload para o Amazon S3, escolha Yes (Sim). A seguir, escolha a chave do KMS correta para AWS KMS key.
O Console de gerenciamento da AWS cria uma política do IAM que habilita o Aurora para descriptografar os dados.
Para obter mais informações, consulte Proteger dados usando criptografia do lado do servidor no Guia do desenvolvedor do Amazon S3.
-
-
-
Escolha configurações para o cluster de banco de dados, como a configuração do armazenamento do cluster de banco de dados, a classe de instância de banco de dados, o identificador do cluster de banco de dados e as credenciais de login. Para obter informações sobre cada configuração, consulte Configurações de clusters de bancos de dados do Aurora.
-
Personalize configurações adicionais para o cluster de banco de dados do Aurora MySQL conforme necessário.
-
Escolha Create database (Criar banco de dados) para executar sua instância de banco de dados de Aurora.
No console do Amazon RDS, a nova instância de banco de dados é exibida na lista de instâncias de banco de dados. A instância de banco de dados fica com o status creating (criando) até que esteja criada e pronta para uso. Quando o status for alterado para available, você poderá se conectar à instância primária do seu cluster de banco de dados. Dependendo da classe da instância de banco de dados e do armazenamento alocado, pode levar alguns minutos até que a nova instância fique disponível.
Para visualizar o cluster recém-criado, escolha a visualização Databases (Bancos de dados) no console do Amazon RDS e escolha o cluster de banco de dados. Para obter mais informações, consulte Visualizar um cluster de bancos de dados Amazon Aurora.
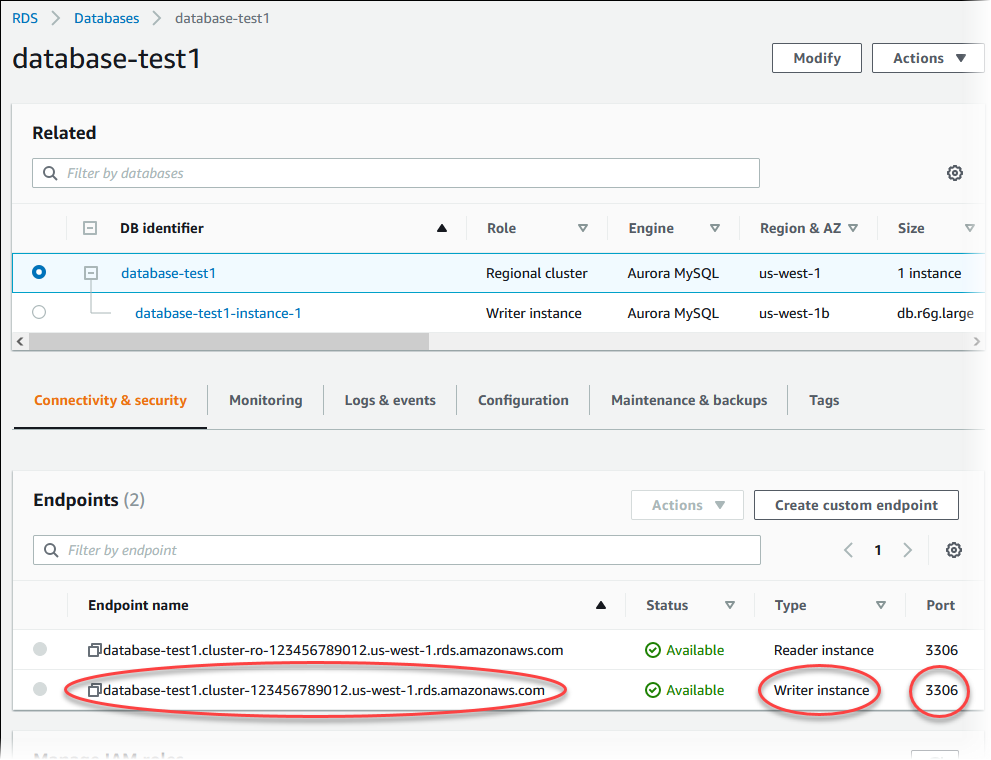
Anote a porta e o endpoint do gravador do cluster do banco de dados. Use o endpoint do gravador e a porta do cluster do banco de dados em suas strings de conexão JDBC e ODBC para qualquer aplicativo que realize operações de gravação ou leitura.
Sincronizar o cluster do banco de dados do Amazon Aurora MySQL com banco de dados MySQL usando a replicação
Para alcançar pouco ou quase nenhum tempo de inatividade durante a migração, você pode replicar transações que foram confirmadas em seu banco de dados do MySQL para seu cluster de banco de dados do Aurora MySQL. A replicação permite que o cluster do banco de dados recupere as transações no banco de dados do MySQL que aconteceram durante a migração. Quando o cluster do banco de dados é completamente recuperado, você pode interromper a replicação e terminar a migração para Aurora MySQL.
Tópicos
Configurar seu banco de dados MySQL externo e seu cluster de banco de dados do Aurora MySQL para replicação criptografada
Para replicar dados de forma segura, você pode usar a replicação criptografada.
nota
Se você não precisar usar a replicação criptografada, você pode passar essas etapas e seguir para as instruções em Sincronizar o cluster de banco de dados do Amazon Aurora MySQL com o banco de dados MySQL externo.
Veja a seguir os pré-requisitos para usar a replicação criptografada:
-
O Secure Sockets Layer (SSL) deve ser habilitado no banco de dados primário do MySQL.
-
Uma chave e certificado de cliente devem estar preparados para o cluster do banco de dados do Aurora MySQL.
Durante a replicação criptografada, o cluster do banco de dados de Aurora MySQL age como um cliente para o servidor de banco de dados do MySQL. Os certificados e chaves do cliente Aurora MySQL estão nos arquivos em formato .pem.
Para configurar seu banco de dados MySQL externo e seu cluster de banco de dados do Aurora MySQL para replicação criptografada
-
Certifique-se de que você estará preparado para a replicação criptografada:
-
Se você não tem o SSL habilitado no banco de dados primário externo do MySQL e não tem uma chave de cliente e um certificado de cliente preparados, habilite o SSL no servidor de banco de dados MySQL e gere a chave de cliente e o certificado de cliente necessários.
-
Se o SSL estiver habilitado no primário externo, forneça uma chave e um certificado de cliente para o cluster de banco de dados do Aurora MySQL. Se você não os tiver, gere uma nova chave e certificado para o cluster de banco de dados do Aurora MySQL. Para assinar o certificado de cliente, é necessário ter a chave de autoridade de certificado usada para configurar o SSL no banco de dados primário externo do MySQL.
Para obter mais informações, consulte Creating SSL certificates and keys using openssl
na documentação do MySQL. Você precisa do certificado de autoridade de certificação, a chave do cliente e o certificado do cliente.
-
-
Conecte-se ao cluster de banco de dados do Aurora MySQL como o usuário primário usando SSL.
Para obter informações sobre como se conectar ao cluster de banco de dados do Aurora MySQL com SSL, consulte Conexões do TLS com clusters de banco de dados do Aurora MySQL.
-
Execute o procedimento armazenado mysql.rds_import_binlog_ssl_material para importar as informações de SSL para o cluster de banco de dados do Aurora MySQL.
Para o parâmetro
ssl_material_value, insira as informações dos arquivos em formato .pem no cluster de banco de dados do Aurora MySQL, na carga JSON correta.O exemplo a seguir importa informações SSL em um cluster de banco de dados Aurora MySQL. Em arquivos de formato .pem, o código do corpo geralmente é maior que o código de corpo exibido no exemplo.
call mysql.rds_import_binlog_ssl_material( '{"ssl_ca":"-----BEGIN CERTIFICATE----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END CERTIFICATE-----\n","ssl_cert":"-----BEGIN CERTIFICATE----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END CERTIFICATE-----\n","ssl_key":"-----BEGIN RSA PRIVATE KEY----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END RSA PRIVATE KEY-----\n"}');Para obter mais informações, consulte mysql.rds_import_binlog_ssl_material e Conexões do TLS com clusters de banco de dados do Aurora MySQL.
nota
Após executar o procedimento, os segredos são armazenados em arquivos. Para apagar os arquivos posteriormente, você pode executar o procedimento armazenado mysql.rds_remove_binlog_ssl_material.
Sincronizar o cluster de banco de dados do Amazon Aurora MySQL com o banco de dados MySQL externo
Você pode sincronizar seu cluster de banco de dados do Amazon Aurora MySQL com o banco de dados de MySQL usando replicação.
Para sincronizar seu cluster de banco de dados do Aurora MySQL com o banco de dados de MySQL usando replicação
-
Certifique-se de que o arquivo /etc/my.cnf do banco de dados MySQL externo tem as entradas relevantes.
Se a replicação criptografada não for necessária, assegure-se de que o banco de dados MySQL externo é iniciado com logs binários (binlogs) habilitados e SSL desabilitado. A seguir veja as entradas relevantes no arquivo /etc/my.cnf para obter dados não criptografados.
log-bin=mysql-bin server-id=2133421 innodb_flush_log_at_trx_commit=1 sync_binlog=1Se a replicação criptografada for necessária, assegure-se de que o banco de dados MySQL externo é iniciado SSL e logs binários estão habilitados. As entradas no arquivo /etc/my.cnf incluem os locais de arquivos .pem para servidor de banco de dados MySQL.
log-bin=mysql-bin server-id=2133421 innodb_flush_log_at_trx_commit=1 sync_binlog=1 # Setup SSL. ssl-ca=/home/sslcerts/ca.pem ssl-cert=/home/sslcerts/server-cert.pem ssl-key=/home/sslcerts/server-key.pemVocê pode verificar que o SSL está habilitado com o comando a seguir.
mysql>show variables like 'have_ssl';Sua saída deve ser similar à seguinte.
+~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ | Variable_name | Value | +~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ | have_ssl | YES | +~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ 1 row in set (0.00 sec) -
Determine a posição começando do log binário até a replicação. Especifique a posição para iniciar a replicação em uma etapa posterior.
Usar o Console de gerenciamento da AWS
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
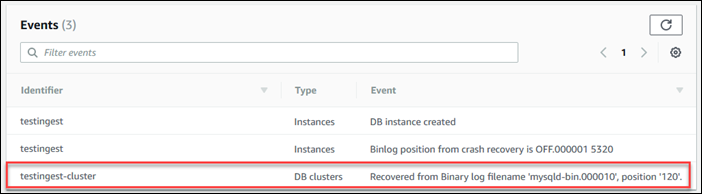
No painel de navegação, selecione Events.
-
Na lista Events (Eventos), anote a posição no evento Recovered from Binary log filename (Recuperado do nome de arquivo de log binário).
Como usar o AWS CLI
Você também pode obter o nome e a posição do arquivo de log binário usando o comando describe-events da AWS CLI. O seguinte mostra um exemplo de comando
describe-events.PROMPT> aws rds describe-eventsNa saída, identifique o evento que mostra a posição do log binário.
-
Quando conectado ao banco de dados MySQL externo, crie um usuário para ser usado na replicação. Esta conta é usada unicamente para replicação e deve estar restrita ao seu domínio para melhorar a segurança. Veja um exemplo a seguir.
mysql>CREATE USER '<user_name>'@'<domain_name>' IDENTIFIED BY '<password>';O usuário requer os privilégios
REPLICATION CLIENTeREPLICATION SLAVE. Concede esses privilégios ao usuário.GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO '<user_name>'@'<domain_name>';Se você precisar usar replicação criptografada, exija conexões SSL para o usuário de replicação. Você pode usar o seguinte comando, por exemplo, para solicitar conexões SSL na conta de usuário
<user_name>GRANT USAGE ON *.* TO '<user_name>'@'<domain_name>' REQUIRE SSL;nota
Se
REQUIRE SSLnão estiver incluído, a conexão de replicação pode silenciosamente cair de volta para uma conexão não criptografada. -
No console do Amazon RDS, adicione o endereço IP do servidor que hospeda o banco de dados MySQL externo ao grupo de segurança da VPC para o cluster de banco de dados do Aurora MySQL. Para obter mais informações sobre como modificar um grupo de segurança da VPC, consulte Grupos de segurança para a VPC no Manual do usuário da Amazon Virtual Private Cloud.
Você também pode precisar configurar sua rede local para permitir conexões com o endereço IP de seu cluster de banco de dados Aurora MySQL, para que ele possa se comunicar com seu banco de dados MySQL externo. Para encontrar o endereço IP do cluster de banco de dados do Aurora MySQL, use o comando
host.host<db_cluster_endpoint>O nome do host é o nome de DNS do endpoint do cluster de banco de dados Aurora MySQL.
-
Habilite a replicação de log binário executando o procedimento mysql.rds_reset_external_master (Aurora MySQL versão 2) ou mysql.rds_reset_external_source (Aurora MySQL versão 3) armazenado. Esse procedimento armazenado tem a seguinte sintaxe.
CALL mysql.rds_set_external_master ( host_name , host_port , replication_user_name , replication_user_password , mysql_binary_log_file_name , mysql_binary_log_file_location , ssl_encryption ); CALL mysql.rds_set_external_source ( host_name , host_port , replication_user_name , replication_user_password , mysql_binary_log_file_name , mysql_binary_log_file_location , ssl_encryption );Para obter informações sobre os parâmetros, consulte mysql.rds_reset_external_master (Aurora MySQL versão 2) e mysql.rds_reset_external_source (Aurora MySQL versão 3).
Para
mysql_binary_log_file_nameemysql_binary_log_file_location, use a posição no evento Recovered from Binary log filename (Recuperado do nome de arquivo de log binário) que você anotou anteriormente.Se os dados no cluster de banco de dados do Aurora MySQL não estiverem criptografados, o parâmetro
ssl_encryptiondeverá ser definido como0. Se os dados são criptografados, o parâmetrossl_encryptiondeve ser definido como1.O exemplo a seguir executa o procedimento para um cluster de banco de dados de Aurora MySQL que tem dados criptografados.
CALL mysql.rds_set_external_master( 'Externaldb.some.com', 3306, 'repl_user'@'mydomain.com', 'password', 'mysql-bin.000010', 120, 1); CALL mysql.rds_set_external_source( 'Externaldb.some.com', 3306, 'repl_user'@'mydomain.com', 'password', 'mysql-bin.000010', 120, 1);Esse procedimento armazenado define os parâmetros que o cluster de banco de dados de Aurora MySQL usa para conectar ao banco de dados MySQL externo e ler seu log binário. Se os dados são criptografados, ele também baixa o certificado de autoridade de certificação SSL, certificado e chave de cliente ao disco local.
-
Inicie a replicação de log binário executando o procedimento armazenadomysql.rds_start_replication.
CALL mysql.rds_start_replication; -
Monitore a distância do cluster do banco de dados de Aurora MySQL que está atrás do banco de dados MySQL primário de replicação. Para fazer isso, conecte ao cluster de banco de dados do Aurora MySQL e execute o comando a seguir.
Aurora MySQL version 2: SHOW SLAVE STATUS; Aurora MySQL version 3: SHOW REPLICA STATUS;Na saída do comando, o campo
Seconds Behind Mastermostra a distância o cluster de banco de dados do Aurora MySQL está em relação ao MySQL primário. Quando esse valor for0(zero), o cluster de banco de dados do Aurora MySQL terá alcançado o primário e você poderá movê-lo para a próxima etapa, a fim de parar a replicação. -
Conecte-se ao banco de dados primário de replicação do MySQL e pare a replicação. Para isso, execute o procedimento mysql.rds_stop_replication armazenado.
CALL mysql.rds_stop_replication;
