Adicionar uma Região da AWS a um Amazon Aurora Global Database
É possível usar o procedimento a seguir para adicionar um cluster secundário adicional a um banco de dados global existente. Também é possível criar um banco de dados global por meio de um cluster de banco de dados independente do Aurora usando esse procedimento para adicionar a primeira região da AWS secundária.
Um Aurora Global Database precisa de pelo menos um cluster de banco de dados Aurora secundário em uma Região da AWS diferente do cluster de banco de dados Aurora principal. Você pode anexar até dez clusters de banco de dados secundários ao Aurora Global Database. Repita o procedimento a seguir para cada novo cluster de banco de dados secundário. Para cada cluster de banco de dados secundário que você adiciona ao banco de dados Aurora global, reduza o número de réplicas Aurora permitidas ao cluster de banco de dados primário para um.
Por exemplo, se seu Aurora Global Database tiver dez regiões secundárias, seu cluster de banco de dados primário poderá ter apenas dez (em vez de quinze) réplicas. Para obter mais informações, consulte Requisitos de configuração do banco de dados do Amazon Aurora global.
O número de réplicas do Aurora (instâncias de leitor) no cluster de banco de dados primário determina o número de clusters de banco de dados secundários que você pode adicionar. Em alguns casos, o número de instâncias de leitor no cluster de banco de dados primário mais o número de clusters secundários pode totalizar 15. Por exemplo, se você tiver 14 instâncias de leitor no cluster de banco de dados primário e 1 cluster secundário, não será possível adicionar um cluster secundário a um banco de dados global.
nota
No Aurora MySQL versão 3, ao criar um cluster secundário, certifique-se de que o valor de lower_case_table_names corresponda ao valor no cluster principal. Essa configuração é um parâmetro de banco de dados que afeta a forma como o servidor lida com diferenciação entre minúsculas e maiúsculas. Para obter mais informações sobre parâmetros de banco de dados, consulte Grupos de parâmetros para Amazon Aurora.
Recomendamos que, ao criar um cluster secundário, use a mesma versão do mecanismo de banco de dados para o primário e o secundário. Se necessário, atualize o cluster primário para que fique com a mesma versão do secundário. Para obter mais informações, consulte Compatibilidade em nível de patch para transições e failovers gerenciados entre regiões.
Para adicionar uma Região da AWS a um Aurora Global Database
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação do AWS Management Console, escolha Databases (Bancos de dados).
-
Escolha o banco de dados Aurora global que precisa de um cluster de bancos de dados Aurora secundário. Certifique-se de que o cluster de bancos de dados Aurora primário seja
Available. -
Em Ações, selecione Adicionar região da AWS.
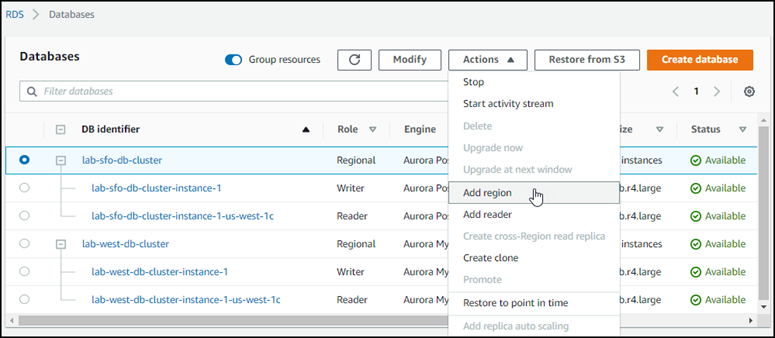
-
Na página Add a region (Adicionar uma região), escolha a Região da AWS secundária.
Não é possível escolher uma Região da AWS que já tenha um cluster de banco de dados Aurora secundário para o mesmo Aurora Global Database. Além disso, não pode ser a mesma região que o cluster de banco de dados primário do Aurora.
nota
Os bancos de dados globais do Babelfish para Aurora PostgreSQL funcionarão em regiões secundárias somente se os parâmetros que controlam as preferências do Babelfish estiverem ativados nessas regiões. Para obter mais informações, consulte . Configurações de grupo de parâmetros de cluster de banco de dados para o Babelfish

-
Preencha os campos restantes do cluster secundário do Aurora na nova região da AWS. Estas são as mesmas opções de configuração que para qualquer instância de cluster de banco de dados Aurora, exceto para a seguinte opção apenas para bancos de dados globais Aurora baseados no Aurora MySQL:
Ativar encaminhamento de gravação de réplica de leitura – Essa configuração opcional permite que os clusters de banco de dados secundários do banco de dados global Aurora encaminhe as operações de gravação para o cluster primário. Para obter mais informações, consulte Como usar o encaminhamento de gravação em um banco de dados global Amazon Aurora.

Escolha Adicionar região da AWS.
Ao terminar de adicionar a região ao seu banco de dados global do Aurora, você poderá visualizá-la na lista Databases (Bancos de dados) no AWS Management Console, como mostrado na captura de tela.
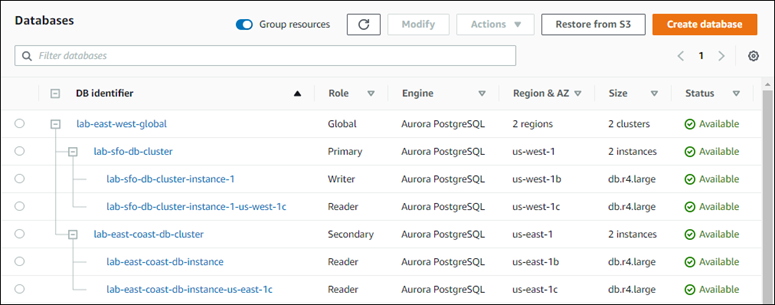
Para adicionar uma Região da AWS secundária a um Aurora Global Database
Para adicionar um cluster secundário ao banco de dados global usando a CLI, você já deve ter o objeto de contêiner do cluster global. Se você ainda não executou o comando create-global-cluster, consulte o procedimento da CLI em Criar um banco de dados global do Amazon Aurora.
-
Use o comando de CLI de
create-db-clustercom o nome (--global-cluster-identifier) do seu banco de dados do Aurora global. Para outros parâmetros: Para
--region, escolha uma Região da AWS diferente de sua região principal do Aurora.-
Escolha valores específicos para os parâmetros
--enginee--engine-version. Esses valores são os mesmos que os do cluster de banco de dados primário Aurora em seu banco de dados globalAurora. Para um cluster criptografado, especifique sua Região da AWS principal como a
--source-regionda criptografia.
O exemplo a seguir cria um novo cluster de banco de dados de Aurora e o anexa a um banco de dados do Aurora global como um cluster de banco de dados Aurora secundário somente leitura. Na última etapa, uma instância de bancos de dados Aurora é adicionada ao novo cluster de bancos de dados Aurora.
Para Linux, macOS ou Unix:
aws rds --regionsecondary_region\ create-db-cluster \ --db-cluster-identifiersecondary_cluster_id\ --global-cluster-identifierglobal_database_id\ --engineaurora-mysql | aurora-postgresql\ --engine-versionversionaws rds --regionsecondary_region\ create-db-instance \ --db-instance-classinstance_class\ --db-cluster-identifiersecondary_cluster_id\ --db-instance-identifierdb_instance_id\ --engineaurora-mysql | aurora-postgresql
Para Windows:
aws rds --regionsecondary_region^ create-db-cluster ^ --db-cluster-identifiersecondary_cluster_id^ --global-cluster-identifierglobal_database_id_id^ --engineaurora-mysql | aurora-postgresql^ --engine-versionversionaws rds --regionsecondary_region^ create-db-instance ^ --db-instance-classinstance_class^ --db-cluster-identifiersecondary_cluster_id^ --db-instance-identifierdb_instance_id^ --engineaurora-mysql | aurora-postgresql
Para adicionar uma nova Região da AWS a um Aurora Global Database com a API do RDS, execute a operação CreateDBCluster. Especifique o identificador do banco de dados global existente usando o parâmetro GlobalClusterIdentifier.
