Criar um banco de dados global do Amazon Aurora
Para criar um banco de dados global do Aurora e os recursos associados usando o Console de gerenciamento da AWS, a AWS CLI ou a API do RDS, siga as etapas abaixo.
nota
Se você tiver um cluster de banco de dados do Aurora que esteja executando um mecanismo de banco de dados do Aurora compatível globalmente, poderá usar uma forma abreviada desse procedimento. Se for o caso, você poderá adicionar outra Região da AWS ao cluster de banco de dados existente para criar o banco de dados global do Aurora. Para fazer isto, consulte Adicionar uma Região da AWS a um Amazon Aurora Global Database.
As etapas para criar um Aurora Global Database começam fazendo login em uma Região da AWS compatível com o recurso Aurora Global Database. Para obter uma lista completa, consulte Regiões e mecanismos de banco de dados compatíveis com bancos de dados globais do Aurora.
Uma das etapas a seguir é escolher uma nuvem privada virtual (VPC) com base na Amazon VPC para o cluster de bancos de dados Aurora. Para usar sua própria VPC, recomendamos que você a crie com antecedência para que esteja disponível para escolher. Ao mesmo tempo, crie sub-redes relacionadas e, conforme necessário, um grupo de sub-rede e um grupo de segurança. Para saber como, consulte Tutorial: Criar uma VPC para usar com um cluster de banco de dados (somente IPv4).
Para obter informações gerais sobre como criar um cluster de bancos de dados Aurora, consulte Criar um cluster de bancos de dados do Amazon Aurora.
Para criar um banco de dados do Aurora global
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. Escolha Create database (Criar banco de dados). Na página Criar banco de dados (Criar banco de dados) , faça o seguinte:
Como método de criação do banco de dados, escolha Standard Create (Criação padrão). (Não escolha Easy Create (Criação fácil).
Em
Engine typena seção Opções de mecanismo, escolha o tipo de mecanismo aplicável, Aurora (compatível com MySQL) ou Aurora (compatível com PostgreSQL).
Continue criando seu banco de dados Aurora global usando as etapas dos procedimentos a seguir.
Criar um banco de dados global do Aurora MySQL
As etapas a seguir se aplicam a todas as versões do Aurora MySQL.
Como criar um banco de dados Aurora global usando o Aurora MySQL
Preencha a página Create database (Criar banco de dados).
Para Engine options (Opções de mecanismo), escolha o seguinte:
Em Engine version (Versão do mecanismo), escolha a versão de Aurora MySQL que deseja usar para seu banco de dados do Aurora global.
Para Templates (Modelos), escolha Production (Produção). Ou, você pode escolher Dev/Teste se apropriado para o seu caso de uso. Não use Dev/Teste em ambientes de produção.
Em Settings (Configurações), faça o seguinte:
Insira um nome significativo para o identificador do cluster de banco de dados. Quando você terminar de criar o banco de dados Aurora global, esse nome identifica o cluster de banco de dados primário.
Insira sua própria senha para a conta de usuário de
adminpara a instância de banco de dados ou deixe Aurora gerar uma para você. Se você escolher Auto generate a password (Gerar uma senha automática), você terá uma opção para copiar a senha.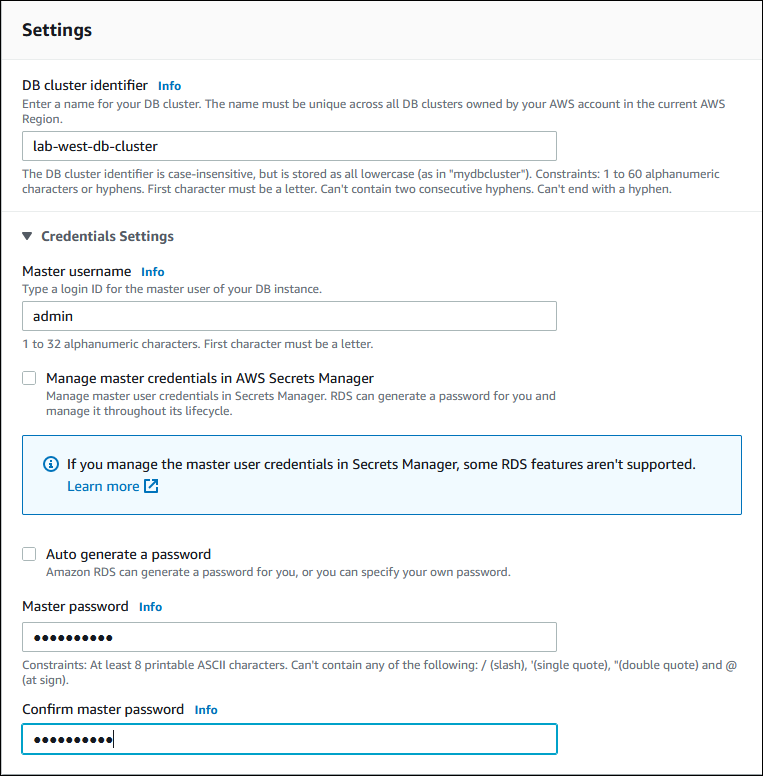
Em DB instance class (Classe da instância do banco de dados), escolha
db.r5.largeou qualquer outra classe de instância de banco de dados otimizada para a memória. Recomendamos utilizar uma classe de instância db.r5 ou superior.Para Availability & durability (Disponibilidade e durabilidade), recomendamos que você escolha Aurora criar uma Aurora réplica de um zona de disponibilidade (AZ) diferente para você. Se você não criar uma réplica Aurora agora, precisará mais tarde.
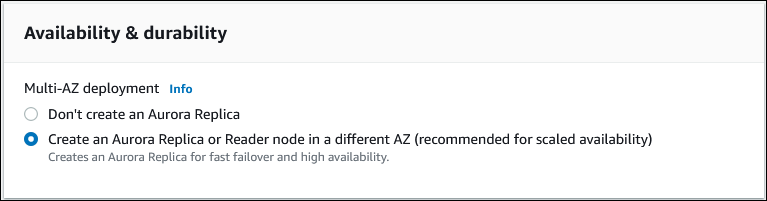
Para Connectivity (Conectividade), escolha a virtual private cloud (VPC) com base na Amazon VPC qual define o ambiente de rede virtual para essa instância de banco de dados. Você pode escolher os padrões para simplificar essa tarefa.
Conclua as configurações Database authentication (Autenticação de banco de dados). Para simplificar o processo, você pode escolher a Password authentication (Autenticação de senha) agora e configurar AWS Identity and Access Management (IAM) mais tarde.
Em Additional configuration (Configuração adicional), faça o seguinte:
Insira um nome para Initial database name (Banco de dados inicial) para criar a instância de banco de dados primário do Aurora para esse cluster. Este é o nó do gravador para o cluster de banco de dados primário do Aurora.
Deixe os padrões selecionados para o grupo de parâmetros do cluster de banco de dados e o grupo de parâmetros de banco de dados, a menos que você tenha seus próprios grupos de parâmetros personalizados que deseja usar.
-
Limpe a caixa de seleção Enable backtrack (Habilitar retrocesso), se estiver selecionada. Os bancos de dados globais do Aurora não são compatíveis com retrocesso. Caso contrário, você pode aceitar todas as outras configurações padrão para Additional configuration (Configuração adicional).
-
Escolha Create database (Criar banco de dados).
Pode levar alguns minutos para Aurora concluir o processo de criação da instância de bancos de dados Aurora, sua réplica do Aurora e o cluster de bancos de dados Aurora. Você pode dizer quando o cluster de banco de dados Aurora está pronto para usar como o cluster de banco de dados primário em um banco de dados global Aurora por seu status. Quando isso acontece, o status e o do nó do gravador e da réplica estão Disponíveis, conforme mostrado a seguir.
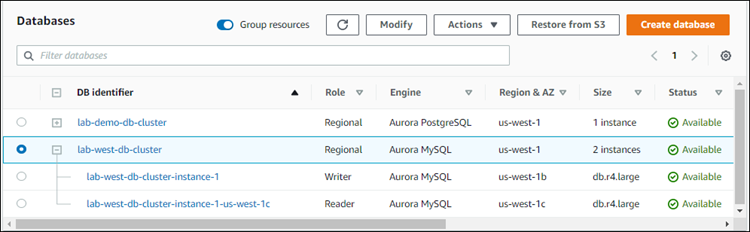
Quando seu cluster de banco de dados primário estiver disponível, crie o banco de dados do global Aurora adicionando um cluster secundário. Para isso, siga as etapas em Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Criar um banco de dados global usando Aurora PostgreSQL
Como criar um banco de dados Aurora global usando o Aurora PostgreSQL
Preencha a página Create database (Criar banco de dados).
Para Engine options (Opções de mecanismo), escolha o seguinte:
Em Engine version (Versão do mecanismo), escolha a versão do Aurora PostgreSQL que você deseja usar para seu banco de dados Aurora global.
Para Templates (Modelos), escolha Production (Produção). Ou você pode escolher Dev/Test, se apropriado. Não use Dev/Teste em ambientes de produção.
Em Settings (Configurações), faça o seguinte:
Insira um nome significativo para o identificador do cluster de banco de dados. Quando você terminar de criar o banco de dados Aurora global, esse nome identifica o cluster de banco de dados primário.
Insira sua própria senha para a conta de administrador padrão para o cluster de banco de dados ou deixe Aurora gerar uma para você. Se você escolher Auto generate a password (Gerar uma senha automática), você terá uma opção para copiar a senha.
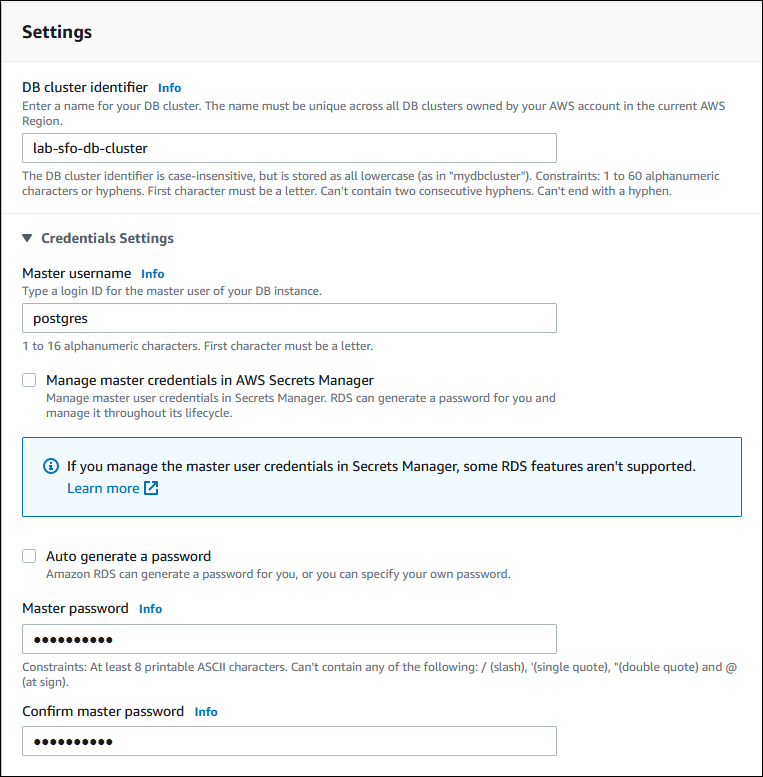
Em DB instance class (Classe da instância do banco de dados), escolha
db.r5.largeou qualquer outra classe de instância de banco de dados otimizada para a memória. Recomendamos utilizar uma classe de instância db.r5 ou superior.Para disponibilidade e durabilidade, recomendamos que você escolha Aurora criar uma réplica Aurora de um AZ diferente para você. Se você não criar uma réplica Aurora agora, precisará mais tarde.
Para Connectivity (Conectividade), escolha a virtual private cloud (VPC) com base na Amazon VPC qual define o ambiente de rede virtual para essa instância de banco de dados. Você pode escolher os padrões para simplificar essa tarefa.
(Opcional) Conclua as configurações Database authentication (Autenticação de banco de dados). A autenticação por senha está sempre habilitada. Para simplificar o processo, você pode pular esta seção e configurar IAM ou senha e autenticação Kerberos posteriormente.
Em Additional configuration (Configuração adicional), faça o seguinte:
Insira um nome para Initial database name (Banco de dados inicial) para criar a instância de banco de dados primário do Aurora para esse cluster. Este é o nó do gravador para o cluster de banco de dados primário do Aurora.
Deixe os padrões selecionados para o grupo de parâmetros do cluster de banco de dados e o grupo de parâmetros de banco de dados, a menos que você tenha seus próprios grupos de parâmetros personalizados que deseja usar.
Aceite todas as outras configurações padrão para Additional configuration (Configuração adicional), como Criptografia, Exportações de log e outros.
-
Escolha Create database (Criar banco de dados).
Pode levar alguns minutos para Aurora concluir o processo de criação da instância de bancos de dados Aurora, sua réplica do Aurora e o cluster de bancos de dados Aurora. Quando o cluster estiver pronto para uso, o cluster de bancos de dados Aurora e seus nós de gravador e réplica exibirão o status Available (Disponível). Isso se torna o cluster de banco de dados primário do seu banco de dados Aurora global, depois de adicionar um secundário.
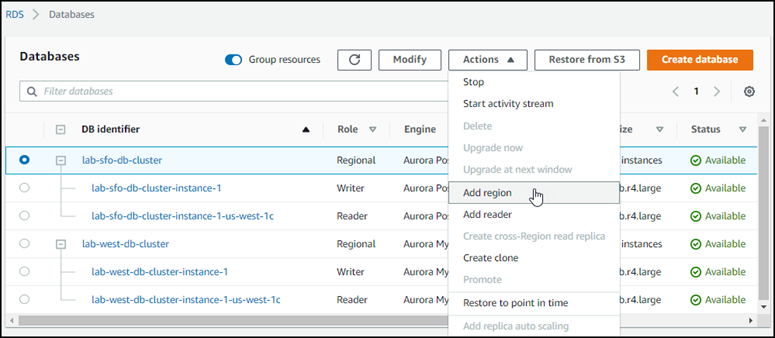
Quando seu cluster de banco de dados primário estiver disponível, crie um ou mais clusters secundários seguindo as etapas em Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Os comandos AWS CLI nos procedimentos a seguir realizam as seguintes tarefas:
Crie um banco de dados global Aurora, dando nome a ele e especificando o tipo de mecanismo de banco de dados de Aurora que você planeja usar.
Crie um cluster de bancos de dados Aurora para o banco de dados do Aurora global.
Crie a instância de bancos de dados Aurora para o cluster. Este é o cluster de banco de dados primário do Aurora para o banco de dados global.
Crie uma segunda instância de banco de dados para cluster de bancos de dados Aurora. Este é um leitor para concluir o cluster de bancos de dados Aurora.
Crie um segundo cluster de bancos de dados Aurora em outra região e adicione-o ao banco de dados Aurora global, seguindo as etapas em Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Siga o procedimento para o mecanismo de banco de dados do Aurora.
Criar um banco de dados global do Aurora MySQL
Para criar um banco de dados do Aurora global usando o Aurora MySQL
-
Use o comando
create-global-clusterda CLI, transferindo o nome da Região da AWS, o mecanismo de banco de dados Aurora e a versão.Para Linux, macOS ou Unix:
aws rds create-global-cluster --regionprimary_region\ --global-cluster-identifierglobal_database_id\ --engine aurora-mysql \ --engine-versionversion# optionalPara Windows:
aws rds create-global-cluster ^ --global-cluster-identifierglobal_database_id^ --engine aurora-mysql ^ --engine-versionversion# optionalIsso cria um banco de dados Aurora global “vazio”, com apenas um nome (identificador) e mecanismo de banco de dados do Aurora. Pode levar alguns minutos para que o banco de dados Aurora global esteja disponível. Antes de ir à próxima etapa, use o comando de CLI
describe-global-clusterspara ver se está disponível.aws rds describe-global-clusters --regionprimary_region--global-cluster-identifierglobal_database_idQuando o banco de dados do Aurora global estiver disponível, você pode criar seu cluster de banco de dados primário do Aurora.
Para criar um cluster de banco de dados primário do Aurora, use o comando de CLI do
create-db-cluster. Inclua o nome do Aurora Global Database usando o parâmetro--global-cluster-identifier.Para Linux, macOS ou Unix:
aws rds create-db-cluster \ --regionprimary_region\ --db-cluster-identifierprimary_db_cluster_id\ --master-usernameuserid\ --master-user-passwordpassword\ --engine aurora-mysql \ --engine-versionversion\ --global-cluster-identifierglobal_database_idPara Windows:
aws rds create-db-cluster ^ --regionprimary_region^ --db-cluster-identifierprimary_db_cluster_id^ --master-usernameuserid^ --master-user-passwordpassword^ --engine aurora-mysql ^ --engine-versionversion^ --global-cluster-identifierglobal_database_idUse o comando
describe-db-clustersda AWS CLI para confirmar se o cluster de bancos de dados Aurora está pronto. Para destacar um cluster de bancos de dados Aurora específico, use o parâmetro--db-cluster-identifier. Ou você pode deixar de fora o nome do cluster de bancos de dados Aurora no comando para obter detalhes sobre todos os seus clusters de bancos de dados Aurora na região determinada.aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierprimary_db_cluster_idQuando a resposta é exibida
"Status": "available"para o cluster, estará pronta para uso.Crie a instância de banco de dados para o cluster de banco de dados primário do Aurora. Para isso, use o comando de CLI de
create-db-instance. Dê o comando o nome do cluster de bancos de dados Aurora e especifique os detalhes de configuração para a instância. Você não precisa transferir os parâmetros--master-usernamee--master-user-passwordno comando, porque obtém aqueles do cluster de bancos de dados Aurora.Para o
--db-instance-class, você pode usar apenas aqueles de classes otimizadas para a memória, comodb.r5.large. Recomendamos utilizar uma classe de instância db.r5 ou superior. Para ter mais informações sobre essas classes, consulte Tipos de classe de instância de banco de dados.Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierdb_instance_id\ --engine aurora-mysql \ --engine-versionversion\ --regionprimary_regionPara Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierdb_instance_id^ --engine aurora-mysql ^ --engine-versionversion^ --regionprimary_regionA operação
create-db-instancepode demorar um pouco para ser concluída. Verifique o status para ver se a instância de bancos de dados Aurora está disponível antes de continuar.aws rds describe-db-clusters --db-cluster-identifierprimary_db_cluster_idQuando o comando exibe o status
available, é possível criar outra instância de bancos de dados do Aurora para o cluster de banco de dados primário. Esta é a instância do leitor (a réplica Aurora) para o cluster de bancos de dados Aurora.-
Para criar outra instância de bancos de dados Aurora para o cluster, use o comando de CLI do
create-db-instance.Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierreplica_db_instance_id\ --engine aurora-mysqlPara Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierreplica_db_instance_id^ --engine aurora-mysql
Quando a instância de banco de dados está disponível, a replicação começa do nó do gravador para a Réplica. Antes de continuar, verifique se a instância de banco de dados está disponível com o comando de CLI do describe-db-instances.
Neste ponto, você tem um banco de dados do Aurora global com seu cluster de banco de dados primário do Aurora contendo uma instância de banco de dados de gravador e uma réplica de Aurora. Agora você pode adicionar um cluster de bancos de dados Aurora somente leitura em uma região diferente para concluir seu banco de dados do Aurora global. Para isso, siga as etapas em Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Criar um banco de dados global usando Aurora PostgreSQL
Quando você cria objetos Aurora para um banco de dados global Aurora usando os comandos a seguir, pode levar alguns minutos para que cada um fique disponível. Recomendamos que, após concluir qualquer comando, verifique o status do objeto Aurora específico para garantir que o status esteja disponível.
Para isso, use o comando de CLI de describe-global-clusters.
aws rds describe-global-clusters --regionprimary_region--global-cluster-identifierglobal_database_id
Para criar um banco de dados do Aurora global usando o Aurora PostgreSQL
Use o comando de CLI de
create-global-cluster.Para Linux, macOS ou Unix:
aws rds create-global-cluster --regionprimary_region\ --global-cluster-identifierglobal_database_id\ --engine aurora-postgresql \ --engine-versionversion# optionalPara Windows:
aws rds create-global-cluster ^ --global-cluster-identifierglobal_database_id^ --engine aurora-postgresql ^ --engine-versionversion# optionalQuando o Aurora Global Database estiver disponível, você pode criar seu cluster de banco de dados primário do Aurora.
-
Para criar um cluster de banco de dados primário do Aurora, use o comando de CLI do
create-db-cluster. Inclua o nome do Aurora Global Database usando o parâmetro--global-cluster-identifier.Para Linux, macOS ou Unix:
aws rds create-db-cluster \ --regionprimary_region\ --db-cluster-identifierprimary_db_cluster_id\ --master-usernameuserid\ --master-user-passwordpassword\ --engine aurora-postgresql \ --engine-versionversion\ --global-cluster-identifierglobal_database_idPara Windows:
aws rds create-db-cluster ^ --regionprimary_region^ --db-cluster-identifierprimary_db_cluster_id^ --master-usernameuserid^ --master-user-passwordpassword^ --engine aurora-postgresql ^ --engine-versionversion^ --global-cluster-identifierglobal_database_idVerifique se o cluster de bancos de dados Aurora está pronto. Quando a resposta do comando a seguir mostra
"Status": "available"para o cluster de bancos de dados Aurora, você pode continuar.aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierprimary_db_cluster_id Crie a instância de banco de dados para o cluster de banco de dados primário do Aurora. Para isso, use o comando de CLI de
create-db-instance.Transfira o nome do seu cluster de bancos de dados Aurora para o parâmetro
--db-cluster-identifier.Você não precisa transferir os parâmetros
--master-usernamee--master-user-passwordno comando, porque obtém aqueles do cluster de bancos de dados Aurora.Para o
--db-instance-class, você pode usar apenas aqueles de classes otimizadas para a memória, comodb.r5.large. Recomendamos utilizar uma classe de instância db.r5 ou superior. Para ter mais informações sobre essas classes, consulte Tipos de classe de instância de banco de dados.Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierdb_instance_id\ --engine aurora-postgresql \ --engine-versionversion\ --regionprimary_regionPara Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierdb_instance_id^ --engine aurora-postgresql ^ --engine-versionversion^ --regionprimary_region-
Verifique o status da instância de bancos de dados Aurora antes de continuar.
aws rds describe-db-clusters --db-cluster-identifierprimary_db_cluster_idSe a resposta mostrar que o status da instância de bancos de dados do Aurora é
available, será possível criar outra instância de bancos de dados do Aurora para o cluster de banco de dados primário. -
Para criar uma réplica de Aurora para cluster de bancos de dados Aurora, use o comando de CLI do
create-db-instance.Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-cluster-identifierprimary_db_cluster_id\ --db-instance-classinstance_class\ --db-instance-identifierreplica_db_instance_id\ --engine aurora-postgresqlPara Windows:
aws rds create-db-instance ^ --db-cluster-identifierprimary_db_cluster_id^ --db-instance-classinstance_class^ --db-instance-identifierreplica_db_instance_id^ --engine aurora-postgresql
Quando a instância de banco de dados está disponível, a replicação começa do nó do gravador para a Réplica. Antes de continuar, verifique se a instância de banco de dados está disponível com o comando de CLI do describe-db-instances.
Seu banco de dados Aurora global existe, mas tem apenas sua região primária com um cluster de bancos de dados Aurora composto por uma instância de banco de dados de gravador e uma réplica do Aurora. Agora você pode adicionar um cluster de bancos de dados Aurora somente leitura em uma região diferente para concluir seu banco de dados do Aurora global. Para isso, siga as etapas em Adicionar uma Região da AWS a um Amazon Aurora Global Database.
Para criar um banco de dados global Aurora com a API do RDS, execute a operação CreateGlobalCluster.
