Solucionar problemas em workloads para bancos de dados do Aurora MySQL
A workload do banco de dados pode ser vista como leituras e gravações. Com uma compreensão da workload de banco de dados “normal”, é possível ajustar as consultas e o servidor do banco de dados para atender à demanda à medida que ela muda. Há vários motivos pelos quais o desempenho pode mudar, então a primeira etapa é entender o que mudou.
-
Houve um upgrade da versão principal ou secundária?
Um upgrade da versão principal inclui alterações no código do mecanismo, principalmente no otimizador, que podem alterar o plano de execução da consulta. Ao fazer upgrade das versões do banco de dados, especialmente das principais, é muito importante que você analise a workload do banco de dados e ajuste adequadamente. O ajuste pode envolver a otimização e a reescrita de consultas ou a adição e atualização de configurações de parâmetros, dependendo dos resultados dos testes. Entender o que está causando o impacto permitirá que você comece a se concentrar nessa área específica.
Consulte mais informações em What is new in MySQL 8.0
e Server and status variables and options added, deprecated, or removed in MySQL 8.0 na documentação do MySQL, e Comparar o Aurora MySQL versão 2 e o Aurora MySQL versão 3. -
Houve um aumento no processamento de dados (contagem de linhas)?
-
Há mais consultas sendo executadas simultaneamente?
-
Há alterações no esquema ou no banco de dados?
-
Houve defeitos ou correções no código?
Sumário
Métricas de host da instância
Monitore as métricas do host da instância, como CPU, memória e atividade de rede, para ajudar a entender se houve uma alteração na workload. Há dois conceitos principais para entender as mudanças na workload:
-
Utilização: o uso de um dispositivo, como CPU ou disco. Pode ser com base no tempo ou na capacidade.
-
Com base no tempo: a quantidade de tempo em que um recurso está ocupado durante determinado período de observação.
-
Com base na capacidade: a quantidade de throughput que um sistema ou componente pode fornecer, como uma porcentagem de sua capacidade.
-
-
Saturação: o grau em que mais trabalho é exigido de um recurso do que ele pode processar. Quando o uso com base na capacidade atinge 100%, o trabalho extra não pode ser processado e deve ser colocado na fila.
Uso da CPU
É possível usar as seguintes ferramentas para identificar o uso e a saturação da CPU:
-
O CloudWatch fornece a métrica
CPUUtilization. Se isso atingir 100%, a instância estará saturada. No entanto, as métricas do CloudWatch são calculadas em média em mais de um minuto e carecem de granularidade.Para obter mais informações sobre métricas do CloudWatch, consulte Métricas no nível da instância do Amazon Aurora.
-
O monitoramento aprimorado fornece métricas retornadas pelo comando
topdo sistema operacional. Ele mostra as médias de carga e os seguintes estados de CPU, com granularidade de um segundo:-
Idle (%)= tempo ocioso -
IRQ (%)= interrupções de software -
Nice (%)= bom momento para processos com uma boaprioridade. -
Steal (%)= tempo gasto atendendo outros locatários (relacionado à virtualização) -
System (%)= hora do sistema -
User (%)= hora do usuário -
Wait (%)= espera de E/S
Para ter mais informações sobre as métricas do Monitoramento Avançado, consulte Métricas do SO para Aurora.
-
Uso de memória
Se o sistema estiver sob pressão de memória e o consumo de recursos estiver atingindo a saturação, você deverá observar um alto grau de erros de digitalização, paginação, troca e falta de memória.
É possível usar as seguintes ferramentas para identificar o uso e a saturação da memória:
O CloudWatch fornece a métrica FreeableMemory que mostra quanta memória pode ser recuperada limpando alguns dos caches do sistema operacional e a memória livre atual.
Para obter mais informações sobre métricas do CloudWatch, consulte Métricas no nível da instância do Amazon Aurora.
O monitoramento avançado fornece as seguintes métricas que podem ajudar a identificar problemas de uso de memória:
-
Buffers (KB): a quantidade de memória usada para o buffer de solicitações de E/S antes de gravar no dispositivo de armazenamento, em kilobytes. -
Cached (KB): a quantidade de memória utilizada para o armazenamento em cache da E/S baseada no sistema de arquivos. -
Free (KB): a quantidade de memória não atribuída, em kilobytes. -
Swap: em cache, livre e total.
Por exemplo, se você perceber que a instância de banco de dados usa memória Swap, a quantidade total de memória para sua workload será maior do que a instância tem disponível atualmente. Recomendamos aumentar o tamanho da instância de banco de dados ou ajustar a workload para usar menos memória.
Para ter mais informações sobre as métricas do Monitoramento Avançado, consulte Métricas do SO para Aurora.
Para ter informações mais detalhadas sobre como usar o Esquema de Performance e o esquema sys para determinar quais conexões e componentes estão usando memória, consulte Solução de problemas de uso de memória para bancos de dados Aurora MySQL.
Throughput na rede
O CloudWatch fornece as seguintes métricas para throughput total da rede, todas com média de um minuto:
-
NetworkReceiveThroughput: a quantidade de throughput de rede recebida dos clientes por cada instância no cluster de bancos de dados do Aurora. -
NetworkTransmitThroughput: a quantidade de throughput de rede enviada aos clientes por cada instância no cluster de bancos de dados do Aurora. -
NetworkThroughput: a quantidade de throughput de rede recebida e transmitida aos clientes por cada instância no cluster de bancos de dados do Aurora. -
StorageNetworkReceiveThroughput: a quantidade de throughput de rede recebida do subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados. -
StorageNetworkTransmitThroughput: a quantidade de throughput de rede enviada ao subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados do Aurora. -
StorageNetworkThroughput: a quantidade de throughput de rede recebida e enviada ao subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados do Aurora.
Para obter mais informações sobre métricas do CloudWatch, consulte Métricas no nível da instância do Amazon Aurora.
O monitoramento avançado fornece os grafos network recebidos (RX) e transmitidos (TX), com granularidade de até um segundo.
Para ter mais informações sobre as métricas do Monitoramento Avançado, consulte Métricas do SO para Aurora.
Métricas de banco de dados
Examine as seguintes métricas do CloudWatch para alterações na workload:
-
BlockedTransactions: o número médio de transações no banco de dados que são bloqueadas por segundo. -
BufferCacheHitRatio: a porcentagem de solicitações atendidas pelo cache de buffer. -
CommitThroughput: o número médio de operações de confirmação por segundo. -
DatabaseConnections: o número de conexões de rede cliente com a instância de banco de dados. -
Deadlocks: o número médio de deadlocks no banco de dados por segundo. -
DMLThroughput: o número médio de inserções, atualizações e exclusões por segundo. -
ResultSetCacheHitRatio: a porcentagem de solicitações atendidas pelo cache de consulta. -
RollbackSegmentHistoryListLength: os logs de ações desfeitas que registram transações confirmadas com registros marcados para exclusão. -
RowLockTime: o tempo total gasto adquirindo bloqueios de linha para tabelas do InnoDB. -
SelectThroughput: o número médio de consultas de seleção por segundo.
Para obter mais informações sobre métricas do CloudWatch, consulte Métricas no nível da instância do Amazon Aurora.
Considere as seguintes perguntas ao examinar a workload:
-
Houve mudanças recentes na classe da instância de banco de dados, por exemplo, redução do tamanho da instância de 8xlarge para 4xlarge ou alteração de db.r5 para db.r6?
-
É possível criar um clone e reproduzir o problema ou isso acontece apenas nessa instância?
-
Há esgotamento dos recursos do servidor, alto esgotamento da CPU ou da memória? Se sim, isso pode significar a necessidade de hardware adicional.
-
Uma ou mais consultas estão demorando mais?
-
As alterações são causadas por um upgrade, especialmente de uma versão principal? Se sim, compare as métricas de antes e depois do upgrade.
-
Há mudanças no número de instâncias de banco de dados do leitor?
-
Você habilitou os logs gerais, de auditoria ou binários? Para ter mais informações, consulte Registro em log de bancos de dados do Aurora MySQL.
-
Você habilitou, desabilitou ou alterou o uso da replicação de logs binários (binlogs)?
-
Há alguma transação de longa duração com um grande número de bloqueios de linha? Examine o tamanho da lista de histórico do InnoDB (HLL) para obter indicações de transações de longa duração.
Consulte mais informações em O tamanho da lista de histórico do InnoDB aumentou significativamente e na publicação do blog Why is my SELECT query running slowly on my Amazon Aurora MySQL DB cluster?
. -
Se um grande HLL for causado por uma transação de gravação, isso significa que os logs
UNDOestão se acumulando (não estão sendo limpos regularmente). Em uma grande transação de gravação, esse acúmulo pode crescer rapidamente. No MySQL,UNDOé armazenado no espaço de tabela SYSTEM. O espaço de tabela SYSTEMnão pode ser reduzido. O logUNDOpode fazer com que o espaço de tabelaSYSTEMcresça para vários GB, ou até mesmo TB. Após a limpeza, libere o espaço alocado fazendo backup lógico (despejo) dos dados e, depois, importe o despejo para uma nova instância de banco de dados. -
Se um HLL grande for causado por uma transação de leitura (consulta de longa duração), isso poderá indicar que a consulta está usando uma grande quantidade de espaço temporário. Libere o espaço temporário ao reinicializar. Examine as métricas de banco de dados do Performance Insights para verificar quaisquer alterações na seção
Temp, comocreated_tmp_tables. Para ter mais informações, consulte Monitorar a carga de banco de dados com o Performance Insights no Amazon Aurora.
-
-
É possível dividir transações de longa duração em transações menores que modificam menos linhas?
-
Há alguma alteração nas transações bloqueadas ou aumento nos deadlocks? Examine as métricas de banco de dados do Performance Insights para verificar quaisquer alterações nas variáveis de status na seção
Locks, comoinnodb_row_lock_time,innodb_row_lock_waitseinnodb_dead_locks. Use intervalos de um minuto ou de cinco minutos. -
Há um aumento nos eventos de espera? Examine os eventos de espera e os tipos de espera do Performance Insights usando intervalos de um minuto ou de cinco minutos. Analise os principais eventos de espera e veja se eles estão correlacionados às mudanças na workload ou à contenção do banco de dados. Por exemplo,
buf_pool mutexindica a contenção do grupo de buffer. Para ter mais informações, consulte Ajustar o Aurora MySQL com eventos de espera.
Solução de problemas de uso de memória para bancos de dados Aurora MySQL
Embora o CloudWatch, o Monitoramento Avançado e o Insights de Performance ofereçam uma boa visão geral do uso da memória em nível de sistema operacional, como a quantidade de memória que o processo do banco de dados está usando, eles não permitem definir quais conexões ou componentes no mecanismo podem estar causando esse uso de memória.
Para solucionar esse problema, é possível usar o Esquema de Performance e o esquema sys. No Aurora MySQL versão 3, a instrumentação de memória está habilitada por padrão quando o Esquema de Performance está habilitado. No Aurora MySQL versão 2, somente a instrumentação de memória para uso de memória do Esquema de Performance está habilitada por padrão. Para ter informações sobre tabelas disponíveis no Esquema de Performance para monitorar o uso da memória e habilitar a instrumentação de memória do Esquema de Performance, consulte Memory summary tables
Embora informações detalhadas estejam disponíveis no Esquema de Performance para monitorar o uso atual da memória, o esquema sys
No esquema sys, as visualizações a seguir estão disponíveis para monitorar o uso da memória por conexão, componente e consulta.
| Visão | Descrição |
|---|---|
|
Fornece informações sobre o uso da memória do mecanismo por host. Pode ser útil para identificar quais servidores de aplicações ou hosts de clientes estão consumindo memória. |
|
|
Fornece informações sobre o uso da memória do mecanismo por ID de thread. O ID de thread no MySQL pode ser uma conexão de cliente ou um thread em segundo plano. É possível associar IDs de thread a IDs de conexão MySQL usando a visualização sys.processlist |
|
|
Fornece informações sobre o uso da memória do mecanismo por usuário. Pode ser útil para identificar quais contas de usuário ou clientes estão consumindo memória. |
|
|
Fornece informações sobre o uso da memória do mecanismo por componente do mecanismo. Pode ser útil para identificar o uso de memória globalmente pelos buffers ou componentes do mecanismo. Por exemplo, é possível que você veja o evento |
|
|
Fornece uma visão geral do uso total de memória monitorado no mecanismo de banco de dados. |
No Aurora MySQL versão 3.05 e posterior, também é possível monitorar o uso máximo de memória por resumo de declarações nas tabelas de resumo de declarações do Esquema de PerformanceMAX_TOTAL_MEMORY pode ajudar a identificar a memória máxima usada pelo resumo da consulta desde a última redefinição das estatísticas ou desde que a instância do banco de dados foi reiniciada. Pode ser útil para identificar consultas específicas que podem estar consumindo muita memória.
nota
O Esquema de Performance e o esquema sys mostram o uso atual da memória no servidor e os limites máximos da memória consumida por conexão e componente do mecanismo. Como o Esquema de Performance é mantido na memória, as informações são redefinidas quando a instância de banco de dados é reiniciada. Para manter um histórico ao longo do tempo, recomendamos configurar a recuperação e o armazenamento desses dados fora do Esquema de Performance.
Exemplo 1: Alto uso contínuo de memória
Examinando globalmente o FreeableMemory no CloudWatch, podemos ver que o uso de memória aumentou muito em 26/3/2024, 2:59, Tempo Universal Coordenado.
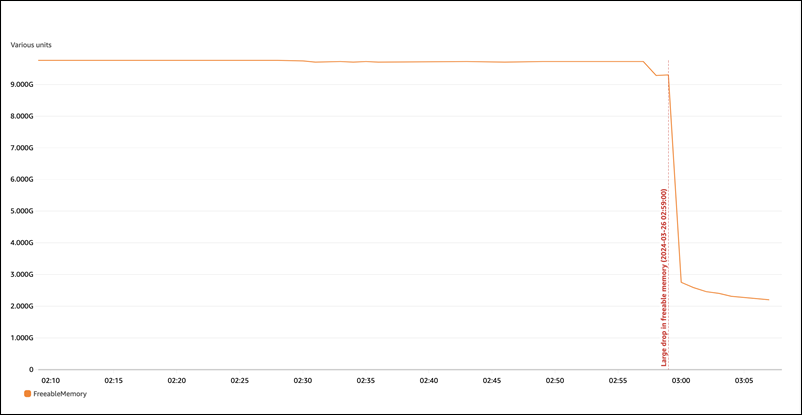
Ele não exibe o panorama geral. Para determinar qual componente está usando mais memória, é possível fazer login no banco de dados e verificar sys.memory_global_by_current_bytes. Essa tabela contém uma lista de eventos de memória monitorados pelo MySQL, além de informações sobre alocação de memória por evento. Cada evento de monitoramento de memória começa com memory/%, seguido de outras informações sobre o componente/recurso do mecanismo ao qual o evento está associado.
Por exemplo, memory/performance_schema/% corresponde a eventos de memória relacionados ao Esquema de Performance, memory/innodb/% corresponde ao InnoDB etc. Para ter informações sobre as convenções de nomenclatura de eventos, consulte Performance Schema instrument naming conventions
Na consulta a seguir, podemos encontrar o provável culpado com base em current_alloc, mas também podemos ver muitos eventos memory/performance_schema/%.
mysql> SELECT * FROM sys.memory_global_by_current_bytes LIMIT 10; +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 512817 | 4.91 GiB | 10.04 KiB | 512823 | 4.91 GiB | 10.04 KiB | | memory/performance_schema/prepared_statements_instances | 252 | 488.25 MiB | 1.94 MiB | 252 | 488.25 MiB | 1.94 MiB | | memory/innodb/hash0hash | 4 | 79.07 MiB | 19.77 MiB | 4 | 79.07 MiB | 19.77 MiB | | memory/performance_schema/events_errors_summary_by_thread_by_error | 1028 | 52.27 MiB | 52.06 KiB | 1028 | 52.27 MiB | 52.06 KiB | | memory/performance_schema/events_statements_summary_by_thread_by_event_name | 4 | 47.25 MiB | 11.81 MiB | 4 | 47.25 MiB | 11.81 MiB | | memory/performance_schema/events_statements_summary_by_digest | 1 | 40.28 MiB | 40.28 MiB | 1 | 40.28 MiB | 40.28 MiB | | memory/performance_schema/memory_summary_by_thread_by_event_name | 4 | 31.64 MiB | 7.91 MiB | 4 | 31.64 MiB | 7.91 MiB | | memory/innodb/memory | 15227 | 27.44 MiB | 1.85 KiB | 20619 | 33.33 MiB | 1.66 KiB | | memory/sql/String::value | 74411 | 21.85 MiB | 307 bytes | 76867 | 25.54 MiB | 348 bytes | | memory/sql/TABLE | 8381 | 21.03 MiB | 2.57 KiB | 8381 | 21.03 MiB | 2.57 KiB | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 10 rows in set (0.02 sec)
Mencionamos anteriormente que o Esquema de Performance é armazenado na memória, o que significa que ele também é monitorado na instrumentação da memória performance_schema.
nota
Se você achar que o Esquema de Performance está usando muita memória e quiser limitar o uso, poderá ajustar os parâmetros do banco de dados com base nos requisitos. Para ter mais informações, consulte The Performance Schema memory-allocation model
Para facilitar a leitura, é possível executar novamente a mesma consulta, mas excluir os eventos do Esquema de Performance. A saída mostra o seguinte:
-
O principal consumidor de memória é
memory/sql/Prepared_statement::main_mem_root. -
A coluna
current_allocinforma que o MySQL tem 4,91 GiB atualmente alocados para esse evento. -
A
high_alloc columninforma que 4,91 GiB é o ponto máximo decurrent_allocdesde a última vez que as estatísticas foram redefinidas ou desde a reinicialização do servidor. Isso significa quememory/sql/Prepared_statement::main_mem_rootestá no valor mais alto.
mysql> SELECT * FROM sys.memory_global_by_current_bytes WHERE event_name NOT LIKE 'memory/performance_schema/%' LIMIT 10; +-----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +-----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 512817 | 4.91 GiB | 10.04 KiB | 512823 | 4.91 GiB | 10.04 KiB | | memory/innodb/hash0hash | 4 | 79.07 MiB | 19.77 MiB | 4 | 79.07 MiB | 19.77 MiB | | memory/innodb/memory | 17096 | 31.68 MiB | 1.90 KiB | 22498 | 37.60 MiB | 1.71 KiB | | memory/sql/String::value | 122277 | 27.94 MiB | 239 bytes | 124699 | 29.47 MiB | 247 bytes | | memory/sql/TABLE | 9927 | 24.67 MiB | 2.55 KiB | 9929 | 24.68 MiB | 2.55 KiB | | memory/innodb/lock0lock | 8888 | 19.71 MiB | 2.27 KiB | 8888 | 19.71 MiB | 2.27 KiB | | memory/sql/Prepared_statement::infrastructure | 257623 | 16.24 MiB | 66 bytes | 257631 | 16.24 MiB | 66 bytes | | memory/mysys/KEY_CACHE | 3 | 16.00 MiB | 5.33 MiB | 3 | 16.00 MiB | 5.33 MiB | | memory/innodb/sync0arr | 3 | 7.03 MiB | 2.34 MiB | 3 | 7.03 MiB | 2.34 MiB | | memory/sql/THD::main_mem_root | 815 | 6.56 MiB | 8.24 KiB | 849 | 7.19 MiB | 8.67 KiB | +-----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 10 rows in set (0.06 sec)
Pelo nome do evento, podemos dizer que essa memória está sendo usada para declarações preparadas. Se você quiser ver quais conexões estão usando essa memória, poderá conferir memory_by_thread_by_current_bytes
No exemplo a seguir, cada conexão tem aproximadamente 7 MiB alocados, com limite máximo de 6,29 MiB (current_max_alloc). Isso faz sentido, porque o exemplo está usando sysbench com 80 tabelas e 800 conexões com declarações preparadas. Se quiser reduzir o uso de memória nessa situação, poderá otimizar o uso de declarações preparadas pela aplicação para diminuir o consumo de memória.
mysql> SELECT * FROM sys.memory_by_thread_by_current_bytes; +-----------+-------------------------------------------+--------------------+-------------------+-------------------+-------------------+-----------------+ | thread_id | user | current_count_used | current_allocated | current_avg_alloc | current_max_alloc | total_allocated | +-----------+-------------------------------------------+--------------------+-------------------+-------------------+-------------------+-----------------+ | 46 | rdsadmin@localhost | 405 | 8.47 MiB | 21.42 KiB | 8.00 MiB | 155.86 MiB | | 61 | reinvent@10.0.4.4 | 1749 | 6.72 MiB | 3.93 KiB | 6.29 MiB | 14.24 MiB | | 101 | reinvent@10.0.4.4 | 1845 | 6.71 MiB | 3.72 KiB | 6.29 MiB | 14.50 MiB | | 55 | reinvent@10.0.4.4 | 1674 | 6.68 MiB | 4.09 KiB | 6.29 MiB | 14.13 MiB | | 57 | reinvent@10.0.4.4 | 1416 | 6.66 MiB | 4.82 KiB | 6.29 MiB | 13.52 MiB | | 112 | reinvent@10.0.4.4 | 1759 | 6.66 MiB | 3.88 KiB | 6.29 MiB | 14.17 MiB | | 66 | reinvent@10.0.4.4 | 1428 | 6.64 MiB | 4.76 KiB | 6.29 MiB | 13.47 MiB | | 75 | reinvent@10.0.4.4 | 1389 | 6.62 MiB | 4.88 KiB | 6.29 MiB | 13.40 MiB | | 116 | reinvent@10.0.4.4 | 1333 | 6.61 MiB | 5.08 KiB | 6.29 MiB | 13.21 MiB | | 90 | reinvent@10.0.4.4 | 1448 | 6.59 MiB | 4.66 KiB | 6.29 MiB | 13.58 MiB | | 98 | reinvent@10.0.4.4 | 1440 | 6.57 MiB | 4.67 KiB | 6.29 MiB | 13.52 MiB | | 94 | reinvent@10.0.4.4 | 1433 | 6.57 MiB | 4.69 KiB | 6.29 MiB | 13.49 MiB | | 62 | reinvent@10.0.4.4 | 1323 | 6.55 MiB | 5.07 KiB | 6.29 MiB | 13.48 MiB | | 87 | reinvent@10.0.4.4 | 1323 | 6.55 MiB | 5.07 KiB | 6.29 MiB | 13.25 MiB | | 99 | reinvent@10.0.4.4 | 1346 | 6.54 MiB | 4.98 KiB | 6.29 MiB | 13.24 MiB | | 105 | reinvent@10.0.4.4 | 1347 | 6.54 MiB | 4.97 KiB | 6.29 MiB | 13.34 MiB | | 73 | reinvent@10.0.4.4 | 1335 | 6.54 MiB | 5.02 KiB | 6.29 MiB | 13.23 MiB | | 54 | reinvent@10.0.4.4 | 1510 | 6.53 MiB | 4.43 KiB | 6.29 MiB | 13.49 MiB | . . . . . . | 812 | reinvent@10.0.4.4 | 1259 | 6.38 MiB | 5.19 KiB | 6.29 MiB | 13.05 MiB | | 214 | reinvent@10.0.4.4 | 1279 | 6.38 MiB | 5.10 KiB | 6.29 MiB | 12.90 MiB | | 325 | reinvent@10.0.4.4 | 1254 | 6.38 MiB | 5.21 KiB | 6.29 MiB | 12.99 MiB | | 705 | reinvent@10.0.4.4 | 1273 | 6.37 MiB | 5.13 KiB | 6.29 MiB | 13.03 MiB | | 530 | reinvent@10.0.4.4 | 1268 | 6.37 MiB | 5.15 KiB | 6.29 MiB | 12.92 MiB | | 307 | reinvent@10.0.4.4 | 1263 | 6.37 MiB | 5.17 KiB | 6.29 MiB | 12.87 MiB | | 738 | reinvent@10.0.4.4 | 1260 | 6.37 MiB | 5.18 KiB | 6.29 MiB | 13.00 MiB | | 819 | reinvent@10.0.4.4 | 1252 | 6.37 MiB | 5.21 KiB | 6.29 MiB | 13.01 MiB | | 31 | innodb/srv_purge_thread | 17810 | 3.14 MiB | 184 bytes | 2.40 MiB | 205.69 MiB | | 38 | rdsadmin@localhost | 599 | 1.76 MiB | 3.01 KiB | 1.00 MiB | 25.58 MiB | | 1 | sql/main | 3756 | 1.32 MiB | 367 bytes | 355.78 KiB | 6.19 MiB | | 854 | rdsadmin@localhost | 46 | 1.08 MiB | 23.98 KiB | 1.00 MiB | 5.10 MiB | | 30 | innodb/clone_gtid_thread | 1596 | 573.14 KiB | 367 bytes | 254.91 KiB | 970.69 KiB | | 40 | rdsadmin@localhost | 235 | 245.19 KiB | 1.04 KiB | 128.88 KiB | 808.64 KiB | | 853 | rdsadmin@localhost | 96 | 94.63 KiB | 1009 bytes | 29.73 KiB | 422.45 KiB | | 36 | rdsadmin@localhost | 33 | 36.29 KiB | 1.10 KiB | 16.08 KiB | 74.15 MiB | | 33 | sql/event_scheduler | 3 | 16.27 KiB | 5.42 KiB | 16.04 KiB | 16.27 KiB | | 35 | sql/compress_gtid_table | 8 | 14.20 KiB | 1.77 KiB | 8.05 KiB | 18.62 KiB | | 25 | innodb/fts_optimize_thread | 12 | 1.86 KiB | 158 bytes | 648 bytes | 1.98 KiB | | 23 | innodb/srv_master_thread | 11 | 1.23 KiB | 114 bytes | 361 bytes | 24.40 KiB | | 24 | innodb/dict_stats_thread | 11 | 1.23 KiB | 114 bytes | 361 bytes | 1.35 KiB | | 5 | innodb/io_read_thread | 1 | 144 bytes | 144 bytes | 144 bytes | 144 bytes | | 6 | innodb/io_read_thread | 1 | 144 bytes | 144 bytes | 144 bytes | 144 bytes | | 2 | sql/aws_oscar_log_level_monitor | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 4 | innodb/io_ibuf_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 7 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 8 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 9 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 10 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 11 | innodb/srv_lra_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 12 | innodb/srv_akp_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 18 | innodb/srv_lock_timeout_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 248 bytes | | 19 | innodb/srv_error_monitor_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 20 | innodb/srv_monitor_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 21 | innodb/buf_resize_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 22 | innodb/btr_search_sys_toggle_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 32 | innodb/dict_persist_metadata_table_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 34 | sql/signal_handler | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | +-----------+-------------------------------------------+--------------------+-------------------+-------------------+-------------------+-----------------+ 831 rows in set (2.48 sec)
Conforme mencionado anteriormente, o valor do ID do thread (thd_id) aqui pode se referir a threads em segundo plano do servidor ou a conexões do banco de dados. Se quiser associar valores de ID de thread a IDs de conexão de banco de dados, você poderá usar a tabela performance_schema.threads ou a visualização sys.processlist, em que conn_id é o ID de conexão.
mysql> SELECT thd_id,conn_id,user,db,command,state,time,last_wait FROM sys.processlist WHERE user='reinvent@10.0.4.4'; +--------+---------+-------------------+----------+---------+----------------+------+-------------------------------------------------+ | thd_id | conn_id | user | db | command | state | time | last_wait | +--------+---------+-------------------+----------+---------+----------------+------+-------------------------------------------------+ | 590 | 562 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 578 | 550 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 579 | 551 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 580 | 552 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 581 | 553 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 582 | 554 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 583 | 555 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 584 | 556 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 585 | 557 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 586 | 558 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 587 | 559 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | . . . . . . | 323 | 295 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 324 | 296 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 325 | 297 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 326 | 298 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 438 | 410 | reinvent@10.0.4.4 | sysbench | Execute | System lock | 0 | wait/lock/table/sql/handler | | 280 | 252 | reinvent@10.0.4.4 | sysbench | Sleep | starting | 0 | wait/io/socket/sql/client_connection | | 98 | 70 | reinvent@10.0.4.4 | sysbench | Query | freeing items | 0 | NULL | +--------+---------+-------------------+----------+---------+----------------+------+-------------------------------------------------+ 804 rows in set (5.51 sec)
Agora interrompemos a workload sysbench, que encerra as conexões e libera a memória. Conferindo novamente os eventos, podemos confirmar que a memória foi liberada, mas high_alloc ainda informa qual é o limite máximo. A coluna high_alloc pode ser muito útil na identificação de pequenos picos no uso da memória, na qual talvez você não consiga identificar imediatamente o uso de current_alloc, o qual mostra apenas a memória atualmente alocada.
mysql> SELECT * FROM sys.memory_global_by_current_bytes WHERE event_name='memory/sql/Prepared_statement::main_mem_root' LIMIT 10; +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 17 | 253.80 KiB | 14.93 KiB | 512823 | 4.91 GiB | 10.04 KiB | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 1 row in set (0.00 sec)
Se quiser redefinir high_alloc, você poderá truncar as tabelas de resumo de memória do performance_schema, mas isso redefinirá toda a instrumentação da memória. Para ter mais informações, consulte Performance Schema general table characteristics
No exemplo a seguir, podemos ver que high_alloc é redefinido após o truncamento.
mysql> TRUNCATE `performance_schema`.`memory_summary_global_by_event_name`; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM sys.memory_global_by_current_bytes WHERE event_name='memory/sql/Prepared_statement::main_mem_root' LIMIT 10; +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 17 | 253.80 KiB | 14.93 KiB | 17 | 253.80 KiB | 14.93 KiB | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 1 row in set (0.00 sec)
Exemplo 2: Picos transitórios de memória
Outra ocorrência comum são pequenos picos no uso da memória em um servidor de banco de dados. Podem ser quedas periódicas na memória liberável que são difíceis de solucionar usando current_alloc em sys.memory_global_by_current_bytes, pois a memória já foi liberada.
nota
Se as estatísticas do Esquema de Performance tiverem sido redefinidas ou a instância do banco de dados tiver sido reiniciada, essas informações não estarão disponíveis no sys nem no performance_schema. Para reter essas informações, recomendamos configurar a coleta de métricas externas.
O grafo a seguir da métrica os.memory.free no Monitoramento Avançado mostra breves picos de sete segundos no uso da memória. O Monitoramento Avançado permite monitorar em intervalos de até um segundo, o que é perfeito para detectar picos transitórios como esses.
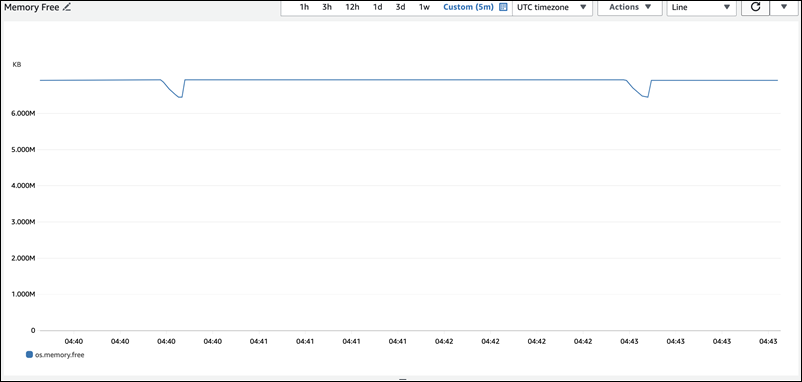
Para ajudar a diagnosticar a causa do uso da memória aqui, podemos usar uma combinação de high_alloc nas visualizações resumidas de memória sys e tabelas de resumo de declarações do Esquema de Performance
Como esperado, visto que o uso de memória atualmente não é alto, não podemos ver nenhum problema grave na visualização do esquema sys abaixo de current_alloc.
mysql> SELECT * FROM sys.memory_global_by_current_bytes LIMIT 10; +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/innodb/hash0hash | 4 | 79.07 MiB | 19.77 MiB | 4 | 79.07 MiB | 19.77 MiB | | memory/innodb/os0event | 439372 | 60.34 MiB | 144 bytes | 439372 | 60.34 MiB | 144 bytes | | memory/performance_schema/events_statements_summary_by_digest | 1 | 40.28 MiB | 40.28 MiB | 1 | 40.28 MiB | 40.28 MiB | | memory/mysys/KEY_CACHE | 3 | 16.00 MiB | 5.33 MiB | 3 | 16.00 MiB | 5.33 MiB | | memory/performance_schema/events_statements_history_long | 1 | 14.34 MiB | 14.34 MiB | 1 | 14.34 MiB | 14.34 MiB | | memory/performance_schema/events_errors_summary_by_thread_by_error | 257 | 13.07 MiB | 52.06 KiB | 257 | 13.07 MiB | 52.06 KiB | | memory/performance_schema/events_statements_summary_by_thread_by_event_name | 1 | 11.81 MiB | 11.81 MiB | 1 | 11.81 MiB | 11.81 MiB | | memory/performance_schema/events_statements_summary_by_digest.digest_text | 1 | 9.77 MiB | 9.77 MiB | 1 | 9.77 MiB | 9.77 MiB | | memory/performance_schema/events_statements_history_long.digest_text | 1 | 9.77 MiB | 9.77 MiB | 1 | 9.77 MiB | 9.77 MiB | | memory/performance_schema/events_statements_history_long.sql_text | 1 | 9.77 MiB | 9.77 MiB | 1 | 9.77 MiB | 9.77 MiB | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 10 rows in set (0.01 sec)
Expandindo a visualização para ordenar por high_alloc, agora podemos ver que o componente memory/temptable/physical_ram é um candidato muito bom aqui. No momento de pico, consumiu 515,00 MiB.
Como o próprio nome sugere, memory/temptable/physical_ram instrumenta o uso de memória para o mecanismo de armazenamento TEMP no MySQL, que foi introduzido no MySQL 8.0. Para ter mais informações sobre como o MySQL usa tabelas temporárias, consulte Internal temporary table use in MySQL
nota
Estamos usando sys.x$memory_global_by_current_bytes neste exemplo.
mysql> SELECT event_name, format_bytes(current_alloc) AS "currently allocated", sys.format_bytes(high_alloc) AS "high-water mark" FROM sys.x$memory_global_by_current_bytes ORDER BY high_alloc DESC LIMIT 10; +-----------------------------------------------------------------------------+---------------------+-----------------+ | event_name | currently allocated | high-water mark | +-----------------------------------------------------------------------------+---------------------+-----------------+ | memory/temptable/physical_ram | 4.00 MiB | 515.00 MiB | | memory/innodb/hash0hash | 79.07 MiB | 79.07 MiB | | memory/innodb/os0event | 63.95 MiB | 63.95 MiB | | memory/performance_schema/events_statements_summary_by_digest | 40.28 MiB | 40.28 MiB | | memory/mysys/KEY_CACHE | 16.00 MiB | 16.00 MiB | | memory/performance_schema/events_statements_history_long | 14.34 MiB | 14.34 MiB | | memory/performance_schema/events_errors_summary_by_thread_by_error | 13.07 MiB | 13.07 MiB | | memory/performance_schema/events_statements_summary_by_thread_by_event_name | 11.81 MiB | 11.81 MiB | | memory/performance_schema/events_statements_summary_by_digest.digest_text | 9.77 MiB | 9.77 MiB | | memory/performance_schema/events_statements_history_long.sql_text | 9.77 MiB | 9.77 MiB | +-----------------------------------------------------------------------------+---------------------+-----------------+ 10 rows in set (0.00 sec)
Em Exemplo 1: Alto uso contínuo de memória, conferimos o uso atual da memória para cada conexão com o objetivo de determinar qual delas é responsável pelo uso da memória em questão. Neste exemplo, a memória já está liberada; portanto, conferir o uso da memória nas conexões atuais não é útil.
Para nos aprofundarmos e encontrarmos as declarações, os usuários e os hosts com problemas, usamos o Esquema de Performance. O Esquema de Performance contém várias tabelas de resumo de declarações que são divididas por dimensões diferentes, como nome do evento, resumo de declarações, host, thread e usuário. Cada visualização possibilitará que você se aprofunde nos locais em que determinadas declarações estão sendo executadas e o que estão fazendo. Esta seção se concentra em MAX_TOTAL_MEMORY, mas é possível encontrar mais informações sobre todas as colunas disponíveis na documentação Performance Schema statement summary tables
mysql> SHOW TABLES IN performance_schema LIKE 'events_statements_summary_%'; +------------------------------------------------------------+ | Tables_in_performance_schema (events_statements_summary_%) | +------------------------------------------------------------+ | events_statements_summary_by_account_by_event_name | | events_statements_summary_by_digest | | events_statements_summary_by_host_by_event_name | | events_statements_summary_by_program | | events_statements_summary_by_thread_by_event_name | | events_statements_summary_by_user_by_event_name | | events_statements_summary_global_by_event_name | +------------------------------------------------------------+ 7 rows in set (0.00 sec)
Primeiro, conferimos events_statements_summary_by_digest para ver MAX_TOTAL_MEMORY.
Com base nesses dados, você pode deduzir o seguinte:
-
A consulta com
20676ce4a690592ff05debcffcbc26faeb76f22005e7628364d7a498769d0c4aresumido parece ser uma boa candidata para esse uso de memória. AMAX_TOTAL_MEMORYé 537450710, que corresponde ao limite máximo que vimos no eventomemory/temptable/physical_ramemsys.x$memory_global_by_current_bytes. -
Houve quatro execuções (
COUNT_STAR); a primeira em 2024-03-26 04:08:34.943256 e a última em 2024-03-26 04:43:06.998310.
mysql> SELECT SCHEMA_NAME,DIGEST,COUNT_STAR,MAX_TOTAL_MEMORY,FIRST_SEEN,LAST_SEEN FROM performance_schema.events_statements_summary_by_digest ORDER BY MAX_TOTAL_MEMORY DESC LIMIT 5; +-------------+------------------------------------------------------------------+------------+------------------+----------------------------+----------------------------+ | SCHEMA_NAME | DIGEST | COUNT_STAR | MAX_TOTAL_MEMORY | FIRST_SEEN | LAST_SEEN | +-------------+------------------------------------------------------------------+------------+------------------+----------------------------+----------------------------+ | sysbench | 20676ce4a690592ff05debcffcbc26faeb76f22005e7628364d7a498769d0c4a | 4 | 537450710 | 2024-03-26 04:08:34.943256 | 2024-03-26 04:43:06.998310 | | NULL | f158282ea0313fefd0a4778f6e9b92fc7d1e839af59ebd8c5eea35e12732c45d | 4 | 3636413 | 2024-03-26 04:29:32.712348 | 2024-03-26 04:36:26.269329 | | NULL | 0046bc5f642c586b8a9afd6ce1ab70612dc5b1fd2408fa8677f370c1b0ca3213 | 2 | 3459965 | 2024-03-26 04:31:37.674008 | 2024-03-26 04:32:09.410718 | | NULL | 8924f01bba3c55324701716c7b50071a60b9ceaf17108c71fd064c20c4ab14db | 1 | 3290981 | 2024-03-26 04:31:49.751506 | 2024-03-26 04:31:49.751506 | | NULL | 90142bbcb50a744fcec03a1aa336b2169761597ea06d85c7f6ab03b5a4e1d841 | 1 | 3131729 | 2024-03-26 04:15:09.719557 | 2024-03-26 04:15:09.719557 | +-------------+------------------------------------------------------------------+------------+------------------+----------------------------+----------------------------+ 5 rows in set (0.00 sec)
Agora que conhecemos o resumo de problemas, podemos ver mais detalhes, como o texto da consulta, o usuário que a executou e onde ela foi executada. Com base no texto resumido exibido, podemos ver que essa é uma expressão de tabela comum (CTE) que cria quatro tabelas temporárias e executa quatro verificações de tabela, o que é muito ineficiente.
mysql> SELECT SCHEMA_NAME,DIGEST_TEXT,QUERY_SAMPLE_TEXT,MAX_TOTAL_MEMORY,SUM_ROWS_SENT,SUM_ROWS_EXAMINED,SUM_CREATED_TMP_TABLES,SUM_NO_INDEX_USED FROM performance_schema.events_statements_summary_by_digest WHERE DIGEST='20676ce4a690592ff05debcffcbc26faeb76f22005e7628364d7a498769d0c4a'\G; *************************** 1. row *************************** SCHEMA_NAME: sysbench DIGEST_TEXT: WITH RECURSIVE `cte` ( `n` ) AS ( SELECT ? FROM `sbtest1` UNION ALL SELECT `id` + ? FROM `sbtest1` ) SELECT * FROM `cte` QUERY_SAMPLE_TEXT: WITH RECURSIVE cte (n) AS ( SELECT 1 from sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte MAX_TOTAL_MEMORY: 537450710 SUM_ROWS_SENT: 80000000 SUM_ROWS_EXAMINED: 80000000 SUM_CREATED_TMP_TABLES: 4 SUM_NO_INDEX_USED: 4 1 row in set (0.01 sec)
Para ter mais informações sobre a tabela events_statements_summary_by_digest e outras tabelas de resumo de declarações do Esquema de Performance, consulte Statement summary tables
Também é possível executar uma declaração EXPLAIN
nota
EXPLAIN ANALYZE pode fornecer mais informações do que EXPLAIN, mas também executa a consulta; portanto, tenha cuidado.
-- EXPLAIN mysql> EXPLAIN WITH RECURSIVE cte (n) AS (SELECT 1 FROM sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte; +----+-------------+------------+------------+-------+---------------+------+---------+------+----------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+---------------+------+---------+------+----------+----------+-------------+ | 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 19221520 | 100.00 | NULL | | 2 | DERIVED | sbtest1 | NULL | index | NULL | k_1 | 4 | NULL | 9610760 | 100.00 | Using index | | 3 | UNION | sbtest1 | NULL | index | NULL | k_1 | 4 | NULL | 9610760 | 100.00 | Using index | +----+-------------+------------+------------+-------+---------------+------+---------+------+----------+----------+-------------+ 3 rows in set, 1 warning (0.00 sec) -- EXPLAIN format=tree mysql> EXPLAIN format=tree WITH RECURSIVE cte (n) AS (SELECT 1 FROM sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte\G; *************************** 1. row *************************** EXPLAIN: -> Table scan on cte (cost=4.11e+6..4.35e+6 rows=19.2e+6) -> Materialize union CTE cte (cost=4.11e+6..4.11e+6 rows=19.2e+6) -> Index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) -> Index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) 1 row in set (0.00 sec) -- EXPLAIN ANALYZE mysql> EXPLAIN ANALYZE WITH RECURSIVE cte (n) AS (SELECT 1 from sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte\G; *************************** 1. row *************************** EXPLAIN: -> Table scan on cte (cost=4.11e+6..4.35e+6 rows=19.2e+6) (actual time=6666..9201 rows=20e+6 loops=1) -> Materialize union CTE cte (cost=4.11e+6..4.11e+6 rows=19.2e+6) (actual time=6666..6666 rows=20e+6 loops=1) -> Covering index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) (actual time=0.0365..2006 rows=10e+6 loops=1) -> Covering index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) (actual time=0.0311..2494 rows=10e+6 loops=1) 1 row in set (10.53 sec)
Mas quem a executou? Podemos ver no Esquema de Performance que o usuário destructive_operator tinha 537450710 de MAX_TOTAL_MEMORY, que novamente corresponde aos resultados anteriores.
nota
O Esquema de Performance é armazenado na memória; portanto, não deve ser considerado a única fonte de auditoria. Se você precisar manter um histórico das declarações executadas e de quais usuários, recomendamos habilitar o registro em log de auditoria. Se você também precisar manter informações sobre o uso da memória, recomendamos configurar o monitoramento para exportar e armazenar esses valores.
mysql> SELECT USER,EVENT_NAME,COUNT_STAR,MAX_TOTAL_MEMORY FROM performance_schema.events_statements_summary_by_user_by_event_name ORDER BY MAX_CONTROLLED_MEMORY DESC LIMIT 5; +----------------------+---------------------------+------------+------------------+ | USER | EVENT_NAME | COUNT_STAR | MAX_TOTAL_MEMORY | +----------------------+---------------------------+------------+------------------+ | destructive_operator | statement/sql/select | 4 | 537450710 | | rdsadmin | statement/sql/select | 4172 | 3290981 | | rdsadmin | statement/sql/show_tables | 2 | 3615821 | | rdsadmin | statement/sql/show_fields | 2 | 3459965 | | rdsadmin | statement/sql/show_status | 75 | 1914976 | +----------------------+---------------------------+------------+------------------+ 5 rows in set (0.00 sec) mysql> SELECT HOST,EVENT_NAME,COUNT_STAR,MAX_TOTAL_MEMORY FROM performance_schema.events_statements_summary_by_host_by_event_name WHERE HOST != 'localhost' AND COUNT_STAR>0 ORDER BY MAX_CONTROLLED_MEMORY DESC LIMIT 5; +------------+----------------------+------------+------------------+ | HOST | EVENT_NAME | COUNT_STAR | MAX_TOTAL_MEMORY | +------------+----------------------+------------+------------------+ | 10.0.8.231 | statement/sql/select | 4 | 537450710 | +------------+----------------------+------------+------------------+ 1 row in set (0.00 sec)
Solucionar problemas de falta de memória em bancos de dados do Aurora MySQL
O parâmetro de nível de instância aurora_oom_response do Aurora MySQL pode habilitar a instância de banco de dados a monitorar a memória de sistema consumida por várias instruções e conexões. Se o sistema estiver com pouca memória, ele poderá executar uma lista de ações para tentar liberar essa memória. Ele faz isso em uma tentativa de evitar uma reinicialização do banco de dados devido a problemas de falta de memória (OOM). O parâmetro no nível da instância usa uma string de ações separadas por vírgula que uma instância de banco de dados realiza quando sua memória está baixa. O parâmetro aurora_oom_response é compatível com o Aurora MySQL versões 2 e 3.
Os valores a seguir e as combinações deles podem ser usados para o parâmetro aurora_oom_response. Uma string vazia significa que não há ações a serem realizadas e desativa efetivamente o recurso, deixando o banco de dados propenso a reinicializações de OOM.
-
decline: recusa novas consultas quando a instância de banco de dados tem pouca memória. kill_connect: fecha as conexões de banco de dados que estão consumindo grande quantidade de memória e encerra as transações atuais e as declarações de linguagem de definição de dados (DDL). Essa resposta não é compatível com o Aurora MySQL versão 2.Consulte mais informações em KILL statement
na documentação do MySQL. -
kill_query: encerra as consultas em ordem decrescente de consumo da memória até a memória da instância superar o limite mínimo. As instruções DDL não são encerradas.Consulte mais informações em KILL statement
na documentação do MySQL. -
print: imprime apenas as consultas que consomem uma grande quantidade de memória. -
tune– ajusta os caches de tabela internos para liberar parte da memória de volta para o sistema. O Aurora MySQL diminui a memória usada para caches, comotable_open_cacheetable_definition_cacheem condições de pouca memória. Por fim, o Aurora MySQL define seu uso de memória de volta ao normal quando o sistema deixa de ter pouca memória.Consulte mais informações em table_open_cache
e table_definition_cache na documentação do MySQL. tune_buffer_pool: diminui o tamanho do pool de buffer para liberar alguma memória e disponibilizá-la para o servidor de banco de dados processar conexões. Essa resposta é compatível com o Aurora MySQL versão 3.06 e posterior.É necessário emparelhar
tune_buffer_poolcomkill_queryoukill_connectno valor do parâmetroaurora_oom_response. Caso contrário, o redimensionamento do pool de buffer não ocorrerá, mesmo quando você incluirtune_buffer_poolno valor do parâmetro.
Nas versões do Aurora MySQL anteriores à 3.06, para classes de instância de banco de dados com memória menor ou igual a 4 GiB, quando a instância está sob pressão de memória, as ações padrão incluem print, tune, decline e kill_query. Para classes de instância de banco de dados com memória maior que 4 GiB, o valor do parâmetro ficará vazio por padrão (desabilitado).
No Aurora MySQL versão 3.06 e posterior, para classes de instância de banco de dados com memória menor ou igual a 4 GiB, o Aurora MySQL também fecha as conexões que mais consomem memória (kill_connect). Em relação a classes de instância de banco de dados com memória maior que 4 GiB, o valor do parâmetro padrão é print.
Se você costuma ter problemas de falta de memória, o uso da memória pode ser monitorado usando tabelas de resumo de memóriaperformance_schema estiver habilitado.
Em relação a métricas do Amazon CloudWatch relacionadas a OOM, consulte Métricas no nível da instância do Amazon Aurora. Em relação a variáveis de status global relacionadas a OOM, consulte Variáveis de status globais do Aurora MySQL.
