Migrar usando espaços de tabela transportáveis da Oracle
Você pode usar o atributo de espaços de tabela transportáveis da Oracle para copiar um conjunto de espaços de tabela de um banco de dados Oracle on-premises para uma instância de banco de dados do RDS para Oracle. No nível físico, é necessário transferir os arquivos de dados de origem e os arquivos de metadados para a instância de banco de dados de destino usando o Amazon EFS ou o Amazon S3. O recurso de espaços de tabela transportáveis usa o pacote rdsadmin.rdsadmin_transport_util. Consulte a sintaxe e a semântica desse pacote em Transportar espaços para tabela.
Para publicações de blog que explicam como transportar espaços de tabela, consulte Migrate Oracle Databases to AWS using transportable tablespace
Tópicos
Visão geral dos espaços de tabela transportáveis da Oracle
Um conjunto de espaços de tabela transportáveis consiste em arquivos de dados para o conjunto de espaços de tabela que está sendo transportado e um arquivo de despejo de exportação que contém metadados do espaço de tabela. Em uma solução de migração física, como os espaços de tabela transportáveis, você transfere arquivos físicos: arquivos de dados, arquivos de configuração e arquivos de despejo do Data Pump.
Tópicos
Vantagens e desvantagens dos espaços de tabela transportáveis
Recomendamos que você use espaços de tabela transportáveis quando precisar migrar um ou mais espaços de tabela grandes para o RDS com o mínimo de tempo de inatividade. Os espaços de tabela transportáveis oferecem as seguintes vantagens em relação à migração lógica:
-
O tempo de inatividade é menor do que a maioria das outras soluções de migração da Oracle.
-
Como o atributo de espaço de tabela transportável copia somente arquivos físicos, ele evita os erros de integridade de dados e a corrupção lógica que podem ocorrer na migração lógica.
-
Nenhuma licença adicional é necessária.
-
Você pode migrar um conjunto de espaços de tabela entre diferentes plataformas e tipos de extremidade, por exemplo, de uma plataforma do Oracle Solaris para Linux. No entanto, não há suporte ao transporte de espaços de tabela de e para servidores Windows.
nota
O Linux foi totalmente testado e é totalmente compatível. Nem todas as variações do UNIX foram testadas.
Se você usar espaços de tabela transportáveis, poderá transportar dados usando o Amazon S3 ou o Amazon EFS:
-
Ao usar o EFS, seus backups permanecem no sistema de arquivos do EFS durante a importação. Você poderá remover os arquivos posteriormente. Nessa técnica, não é necessário provisionar o armazenamento do EBS para sua instância de banco de dados. Por esse motivo, recomendamos usar o Amazon EFS em vez do S3. Para obter mais informações, consulte Integração do Amazon EFS.
-
Ao usar o S3, baixe backups do RMAN para o armazenamento do EBS conectado à sua instância de banco de dados. Os arquivos permanecem no armazenamento do EBS durante a importação. Após a importação, você poderá liberar esse espaço, que permanecerá alocado para sua instância de banco de dados.
A principal desvantagem dos espaços de tabela transportáveis é a necessidade de um conhecimento relativamente avançado sobre o Oracle Database. Para obter mais informações, consulte Transporting Tablespaces Between Databases
Limitações dos espaços de tabela transportáveis
As limitações do Oracle Database para espaços de tabela transportáveis se aplicam quando você usa esse atributo no RDS para Oracle. Para obter mais informações, consulte Limitations on Transportable Tablespaces
-
Nem o banco de dados de origem, nem o de destino podem usar a Standard Edition 2 (SE2). Somente a Enterprise Edition é compatível.
-
Não é possível usar um banco de dados do Oracle Database 11g como fonte. O recurso de espaços de tabela transportáveis multiplataforma do RMAN depende do mecanismo de transporte RMAN, que o Oracle Database 11g não comporta.
-
Não é possível migrar dados de uma instância de banco de dados do RDS para Oracle usando espaços de tabela transportáveis. Só é possível usar os espaços de tabela transportáveis para migrar dados para uma instância de banco de dados do RDS para Oracle.
-
Não há suporte ao sistema operacional Windows.
-
Não é possível transportar espaços de tabela para um banco de dados em um nível de versão inferior. O banco de dados de destino deve estar no mesmo nível de versão, ou posterior, do banco de dados de origem. Por exemplo, não é possível transportar espaços de tabela do Oracle Database 21c para o Oracle Database 19c.
-
Não é possível transportar espaços de tabela administrativos, como
SYSTEMeSYSAUX. -
Não é possível transportar objetos que não sejam de dados, como pacotes PL/SQL, classes Java, visualizações, gatilhos, sequências, usuários, perfis e tabelas temporárias. Para transportar objetos que não sejam de dados, crie-os manualmente ou use a exportação e importação de metadados do Data Pump. Para ter mais informações, consulte My Oracle Support Note 1454872.1
. -
Não é possível transportar espaços de tabela que estão criptografados ou que usam colunas criptografadas.
-
Ao transferir arquivos usando o Amazon S3, o tamanho máximo de arquivo compatível é de 5 TiB.
-
Se o banco de dados de origem usar opções do Oracle como o Spatial, você não poderá transportar espaços de tabela, a menos que as mesmas opções estejam configuradas no banco de dados de destino.
-
Não é possível transportar espaços de tabela para uma instância de banco de dados do RDS para Oracle em uma configuração de réplica do Oracle. Como solução alternativa, você pode excluir todas as réplicas, transportar os espaços de tabela e recriar as réplicas.
Pré-requisitos para espaços de tabela transportáveis
Antes de começar, conclua as seguintes tarefas:
-
Analise os requisitos para espaços de tabela transportáveis descritos nos seguintes documentos em My Oracle Support:
-
Planeje a conversão de extremidade. Se você especificar o ID da plataforma de origem, o RDS para Oracle converterá a extremidade automaticamente. Para saber como encontrar IDs de plataforma, consulte Data Guard Support for Heterogeneous Primary and Physical Standbys in Same Data Guard Configuration (Doc ID 413484.1)
. -
Verifique se o atributo de espaços de tabela transportáveis está habilitado em sua instância de banco de dados de destino. O atributo só estará habilitado se você não receber um erro
ORA-20304ao executar a seguinte consulta:SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files);Se o atributo de espaços de tabela transportáveis não estiver habilitado, reinicialize a instância de banco de dados. Para obter mais informações, consulte Reinicializar uma instância de banco de dados.
-
Verifique se o arquivo de fuso horário é o mesmo nos bancos de dados de origem e de destino.
-
Certifique-se de que os conjuntos de caracteres do banco de dados nos bancos de dados de origem e de destino satisfaçam um dos seguintes requisitos:
-
Os conjuntos de caracteres são os mesmos.
-
Os conjuntos de caracteres são compatíveis. Para obter uma lista dos requisitos de compatibilidade, consulte Limitações gerais no transporte de dados
na documentação do Oracle Database.
-
-
Se você planeja transferir arquivos usando o Amazon S3, faça o seguinte:
-
Verifique se há um bucket do Amazon S3 disponível para transferências de arquivos e se o bucket do Amazon S3 está na mesma região da AWS que a sua instância de banco de dados. Para obter mais informações, consulte Criar um bucket no Guia de conceitos básicos do Amazon Simple Storage Service.
-
Prepare o bucket do Amazon S3 para a integração com o Amazon RDS seguindo as instruções em Configurar permissões do IAM para a integração do RDS para Oracle com o Amazon S3.
-
-
Se você planeja transferir arquivos usando o Amazon EFS, verifique se configurou o EFS de acordo com as instruções em Integração do Amazon EFS.
-
É altamente recomendável que você ative os backups automáticos na instância de banco de dados de destino. Como a etapa de importação de metadados pode falhar, é importante ser capaz de restaurar a instância de banco de dados para o estado anterior à importação, evitando assim a necessidade de fazer backup, transferir e importar os espaços de tabela novamente.
Fase 1: Configurar o host de origem
Nesta etapa, você copiará os scripts de transporte de espaços de tabela fornecidos em My Oracle Support e definirá os arquivos de configuração necessários. Nas etapas a seguir, o host de origem executará o banco de dados que contém os espaços de tabela que serão transportados para a instância de destino.
Como configurar o host de origem
-
Faça login no host de origem como proprietário do início do Oracle.
-
Certifique-se de que as variáveis de ambiente
ORACLE_HOMEeORACLE_SIDapontem para o banco de dados de origem. -
Faça login em seu banco de dados como administrador e verifique se a versão do fuso horário, o conjunto de caracteres do banco de dados e o conjunto de caracteres nacionais são iguais aos do banco de dados de destino.
SELECT * FROM V$TIMEZONE_FILE; SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER IN ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET'); -
Configure o utilitário de espaços de tabela transportáveis conforme descrito em Oracle Support note 2471245.1
. A configuração inclui a edição do arquivo
xtt.propertiesem seu host de origem. O exemplo de arquivoxtt.propertiesa seguir especifica backups de três espaços de tabela no diretório/dsk1/backups. Esses são os espaços de tabela que você pretende transportar para a instância de banco de dados de destino. Também especifica o ID da plataforma de origem para converter a extremidade automaticamente.nota
Para saber como encontrar IDs de plataforma, consulte Data Guard Support for Heterogeneous Primary and Physical Standbys in Same Data Guard Configuration (Doc ID 413484.1)
. #linux system platformid=13#list of tablespaces to transport tablespaces=TBS1,TBS2,TBS3#location where backup will be generated src_scratch_location=/dsk1/backups#RMAN command for performing backup usermantransport=1
Fase 2: Preparar o backup completo dos espaços de tabela
Nesta fase, você fará backup dos espaços de tabela pela primeira vez, transferirá os backups para o host de destino e restaurará usando o procedimento rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces. Quando essa fase estiver concluída, os backups iniciais dos espaços de tabela vão residir na instância de banco de dados de destino e poderão ser atualizados com backups incrementais.
Tópicos
Etapa 1: Fazer backup dos espaços de tabela no host de origem
Nesta etapa, use o script xttdriver.pl para fazer um backup completo dos espaços de tabela. A saída de xttdriver.pl é armazenada na variável de ambiente TMPDIR.
Como fazer backup dos espaços de tabela
-
Se os espaços de tabela estiverem no modo somente leitura, faça login no banco de dados de origem como um usuário que tem o privilégio
ALTER TABLESPACEe coloque os espaços de tabela no modo de leitura/gravação. Caso contrário, vá para a próxima etapa.O exemplo a seguir coloca
tbs1,tbs2etbs3no modo de leitura/gravação.ALTER TABLESPACE tbs1 READ WRITE; ALTER TABLESPACE tbs2 READ WRITE; ALTER TABLESPACE tbs3 READ WRITE; -
Faça backup dos espaços de tabela usando o script
xttdriver.pl. Opcionalmente, você pode especificar--debugpara executar o script no modo de depuração.export TMPDIR=location_of_log_filescdlocation_of_xttdriver.pl$ORACLE_HOME/perl/bin/perl xttdriver.pl --backup
Etapa 2: Transferir os arquivos de backup para a instância de banco de dados de destino
Nesta etapa, copie os arquivos de backup e configuração do local temporário para a instância de banco de dados de destino. Escolha uma das seguintes opções:
-
Se os hosts de origem e de destino compartilharem um sistema de arquivos do Amazon EFS, use um utilitário de sistema operacional, como
cp, para copiar os arquivos de backup e o arquivores.txtdo local temporário para um diretório compartilhado. Em seguida, vá para Etapa 3: Importar os espaços de tabela na instância de banco de dados de destino. -
Se você precisar preparar os backups em um bucket do Amazon S3, realize as etapas a seguir.
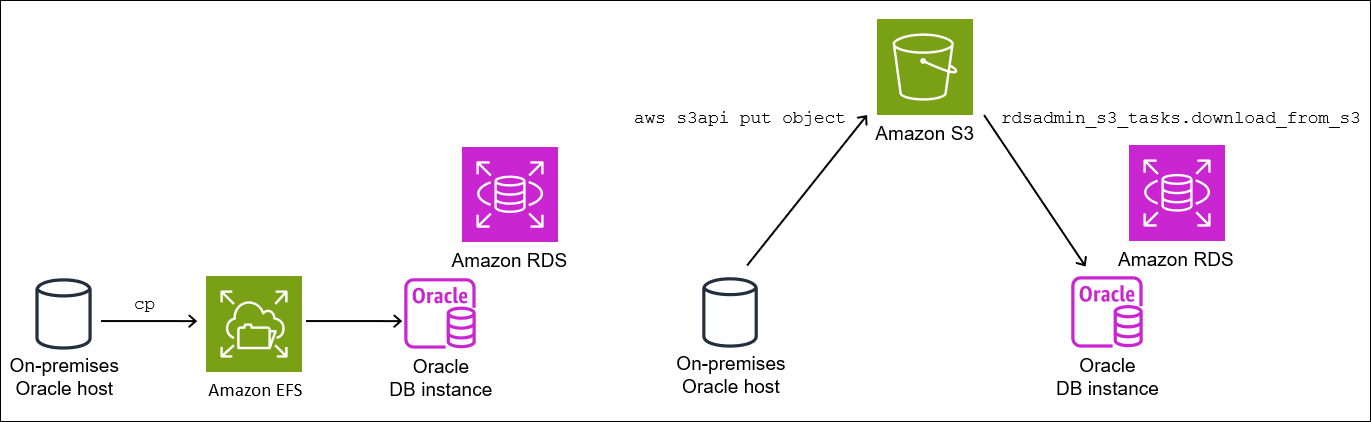
Etapa 2.2: Fazer upload dos backups no bucket do Amazon S3
Faça upload dos backups e do arquivo res.txt do diretório temporário para o bucket do Amazon S3. Para obter mais informações, consulte Fazer upload de objetos no Guia do usuário do Amazon Simple Storage Service.
Etapa 2.3: Fazer download dos backups do bucket do Amazon S3 para a instância de banco de dados de destino
Nesta etapa, use o procedimento rdsadmin.rdsadmin_s3_tasks.download_from_s3 para fazer download dos backups para a instância de banco de dados do RDS para Oracle.
Como fazer download dos backups do bucket do Amazon S3
-
Inicie o SQL*Plus ou o Oracle SQL Developer e faça login em sua instância de banco de dados do RDS para Oracle.
-
Faça download dos backups do bucket do Amazon S3 na instância de banco de dados de destino usando o procedimento
rdsadmin.rdsadmin_s3_tasks.download_from_s3do Amazon RDS para baixar os arquivos do bucket do Amazon S3 na instância de banco de dados. O exemplo a seguir baixa todos os arquivos de um bucket do Amazon S3 chamadoamzn-s3-demo-bucketDATA_PUMP_DIREXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'res.txt'); SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'amzn-s3-demo-bucket', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;A instrução
SELECTretorna o ID da tarefa em um tipo de dadosVARCHAR2. Para obter mais informações, consulte Baixar arquivos de um bucket do Amazon S3 para uma instância de banco de dados Oracle.
Etapa 3: Importar os espaços de tabela na instância de banco de dados de destino
Use o procedimento rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces para restaurar os espaços de tabela na instância de banco de dados de destino. Esse procedimento converte automaticamente os arquivos de dados para o formato endian correto.
Se você importar de uma plataforma diferente do Linux, especifique a plataforma de origem usando o parâmetro p_platform_id ao chamar import_xtts_tablespaces. O ID da plataforma que você especificou deve corresponder ao que foi especificado no arquivo xtt.properties em Etapa 2: Exportar os metadados dos espaços de tabela no host de origem.
Importar os espaços de tabela na instância de banco de dados de destino
-
Inicie um cliente Oracle SQL e faça login como usuário principal na instância de banco de dados de destino do RDS para Oracle.
-
Execute o procedimento
rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces, especificando os espaços de tabela que serão importados e o diretório que contém os backups.O exemplo a seguir importa os espaços de tabela
TBS1,TBS2eTBS3do diretórioDATA_PUMP_DIR. A plataforma de origem é de sistemas baseados em AIX (64 bits), que tem o ID da plataforma de6. É possível encontrar os IDs da plataforma consultandoV$TRANSPORTABLE_PLATFORM.VAR task_id CLOB BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces( 'TBS1,TBS2,TBS3', 'DATA_PUMP_DIR', p_platform_id => 6); END; / PRINT task_id -
(Opcional) Monitore o progresso consultando a tabela
rdsadmin.rds_xtts_operation_info. A colunaxtts_operation_statemostra o valorEXECUTING,COMPLETEDouFAILED.SELECT * FROM rdsadmin.rds_xtts_operation_info;nota
Para operações de longa duração, você também pode consultar
V$SESSION_LONGOPS,V$RMAN_STATUSeV$RMAN_OUTPUT. -
Veja o log da importação concluída usando o ID de tarefa da etapa anterior.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));Verifique se importação foi bem-sucedida antes de prosseguir para a próxima etapa.
Fase 3: Criar e transferir backups incrementais
Nesta fase, você fará e transferirá backups incrementais periodicamente enquanto o banco de dados de origem estiver ativo. Essa técnica reduz o tamanho do backup final de espaços de tabela. Se você criar vários backups incrementais, deverá copiar o arquivo res.txt depois do último backup incremental antes de poder aplicá-lo na instância de destino.
As etapas são as mesmas de Fase 2: Preparar o backup completo dos espaços de tabela, exceto que a etapa de importação é opcional.
Fase 4: Transportar os espaços de tabela
Nesta fase, você fará backup dos espaços de tabela somente leitura e exportará os metadados do Data Pump, transferirá esses arquivos para o host de destino e importará os espaços de tabela e os metadados.
Tópicos
Etapa 1: Fazer backup dos espaços de tabela somente leitura
Esta etapa é idêntica a Etapa 1: Fazer backup dos espaços de tabela no host de origem, com uma única diferença importante: você coloca os espaços de tabela no modo somente leitura antes de fazer backup dos espaços de tabela pela última vez.
O exemplo a seguir coloca tbs1, tbs2 e tbs3 no modo somente leitura.
Importante
Ao definir o modo dos espaços de tabela como somente leitura, sua janela de tempo de inatividade de migração é iniciada. A partir desse momento, as aplicações não poderão gravar nesses espaços de tabela no banco de dados de origem. Planeje essa etapa durante uma janela de manutenção.
ALTER TABLESPACE tbs1 READ ONLY; ALTER TABLESPACE tbs2 READ ONLY; ALTER TABLESPACE tbs3 READ ONLY;
Etapa 2: Exportar os metadados dos espaços de tabela no host de origem
Exporte os metadados dos espaços de tabela executando o utilitário expdp no host de origem. O exemplo a seguir exporta os espaços de tabela TBS1, TBS2 e TBS3 para o arquivo de despejo xttdump.dmp no diretório DATA_PUMP_DIR.
expdpusername/pwd\ dumpfile=xttdump.dmp\ directory=DATA_PUMP_DIR\ statistics=NONE \ transport_tablespaces=TBS1,TBS2,TBS3\ transport_full_check=y \ logfile=tts_export.log
Se DATA_PUMP_DIR for um diretório compartilhado no Amazon EFS, vá para Etapa 4: Importar os espaços de tabela na instância de banco de dados de destino.
Etapa 3: (somente Amazon S3) Transferir os arquivos de backup e exportação para a instância de banco de dados de destino
Se você estiver usando o Amazon S3 para preparar os backups de espaços de tabela e o arquivo de exportação do Data Pump, conclua as etapas a seguir.
Etapa 3.1: Fazer upload dos backups e do arquivo de despejo do host de origem no bucket do Amazon S3
Faça upload dos arquivos de backup e despejo do host de origem no bucket do Amazon S3. Para obter mais informações, consulte Fazer upload de objetos no Guia do usuário do Amazon Simple Storage Service.
Etapa 3.2: Fazer download dos backups e do arquivo de despejo do bucket do Amazon S3 para a instância de banco de dados de destino
Nesta etapa, use o procedimento rdsadmin.rdsadmin_s3_tasks.download_from_s3 para fazer download dos backups e do arquivo de despejo para a instância de banco de dados do RDS para Oracle. Siga as etapas em Etapa 2.3: Fazer download dos backups do bucket do Amazon S3 para a instância de banco de dados de destino.
Etapa 4: Importar os espaços de tabela na instância de banco de dados de destino
Use o procedimento rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces para restaurar os espaços de tabela. Para conhecer a sintaxe e a semântica desse procedimento, consulte Importar espaços para tabela transportados para a instância de banco de dados.
Importante
Depois de concluir a importação final de espaços de tabela, a próxima etapa será importar os metadados do Oracle Data Pump. Em caso de falha na importação, é importante restaurar o estado da instância de banco de dados anterior à falha. Portanto, recomendamos que você crie um snapshot de banco de dados da instância de banco de dados seguindo as instruções em Criar um snapshot de banco de dados para uma instância de banco de dados single-AZ para o Amazon RDS. O snapshot conterá todos os espaços de tabela importados, portanto, se a importação falhar, você não precisará repetir o processo de backup e importação.
Se a instância de banco de dados de destino estiver com a opção de backups automáticos ativada e o Amazon RDS não detectar que um snapshot válido foi iniciado antes da importação dos metadados, o RDS tentará criar um snapshot. Dependendo da atividade da instância, esse snapshot pode ou não ser bem-sucedido. Se um snapshot válido não for detectado ou se não for possível iniciar o snapshot, a importação de metadados será encerrada com erros.
Importar os espaços de tabela na instância de banco de dados de destino
-
Inicie um cliente Oracle SQL e faça login como usuário principal na instância de banco de dados de destino do RDS para Oracle.
-
Execute o procedimento
rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces, especificando os espaços de tabela que serão importados e o diretório que contém os backups.O exemplo a seguir importa os espaços de tabela
TBS1,TBS2eTBS3do diretórioDATA_PUMP_DIR.BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces('TBS1,TBS2,TBS3','DATA_PUMP_DIR'); END; / PRINT task_id -
(Opcional) Monitore o progresso consultando a tabela
rdsadmin.rds_xtts_operation_info. A colunaxtts_operation_statemostra o valorEXECUTING,COMPLETEDouFAILED.SELECT * FROM rdsadmin.rds_xtts_operation_info;nota
Para operações de longa duração, você também pode consultar
V$SESSION_LONGOPS,V$RMAN_STATUSeV$RMAN_OUTPUT. -
Veja o log da importação concluída usando o ID de tarefa da etapa anterior.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));Verifique se importação foi bem-sucedida antes de prosseguir para a próxima etapa.
-
Gere um snapshot manual do banco de dados seguindo as instruções em Criar um snapshot de banco de dados para uma instância de banco de dados single-AZ para o Amazon RDS.
Etapa 5: Importar os metadados de espaços de tabela na instância de banco de dados de destino
Nesta etapa, importe os metadados de espaços de tabela transportáveis para a instância de banco de dados do RDS para Oracle usando o procedimento rdsadmin.rdsadmin_transport_util.import_xtts_metadata. Para conhecer a sintaxe e a semântica desse procedimento, consulte Importar metadados de espaços para tabela transportáveis para a instância de banco de dados. Durante a operação, o status da importação é mostrado na tabela rdsadmin.rds_xtts_operation_info.
Importante
Antes de importar metadados, é altamente recomendável que você confirme se um snapshot do banco de dados foi criado com êxito depois da importação dos espaços de tabela. Se a etapa de importação falhar, restaure a instância de banco de dados, resolva os erros de importação e tente importar novamente.
Importar os metadados do Data Pump para uma instância de banco de dados do RDS para Oracle
-
Inicie seu cliente Oracle SQL e faça login como usuário principal na instância de banco de dados de destino.
-
Crie os usuários proprietários de esquemas nos espaços de tabela transportados, caso esses usuários ainda não existam.
CREATE USERtbs_ownerIDENTIFIED BYpassword; -
Importe os metadados, especificando o nome do arquivo de despejo e sua localização no diretório.
BEGIN rdsadmin.rdsadmin_transport_util.import_xtts_metadata('xttdump.dmp','DATA_PUMP_DIR'); END; / -
(Opcional) Consulte a tabela de histórico de espaços de tabela transportáveis para ver o status da importação de metadados.
SELECT * FROM rdsadmin.rds_xtts_operation_info;Quando a operação for concluída, os espaços de tabela ficarão no modo somente leitura.
-
(Opcional) Veja o arquivo de log.
O exemplo a seguir lista o conteúdo do diretório BDUMP, depois consulta o log de importação.
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'BDUMP')); SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-import_xtts_metadata-2023-05-22.01-52-35.560858000.log'));
Fase 5: Validar os espaços de tabela transportados
Nesta etapa opcional, você validará os espaços de tabela transportados usando o procedimento rdsadmin.rdsadmin_rman_util.validate_tablespace, depois colocará os espaços de tabela no modo de leitura/gravação.
Como validar os dados transportados
-
Inicie o SQL*Plus ou o SQL Developer e faça login como usuário principal em sua instância de banco de dados de destino.
-
Valide os espaços de tabela usando o procedimento
rdsadmin.rdsadmin_rman_util.validate_tablespace.SET SERVEROUTPUT ON BEGIN rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS1', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS2', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS3', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); END; / -
Coloque os espaços de tabela no modo de leitura/gravação.
ALTER TABLESPACETBS1READ WRITE; ALTER TABLESPACETBS2READ WRITE; ALTER TABLESPACETBS3READ WRITE;
Fase 6: Limpar os arquivos restantes
Nesta etapa opcional, você removerá todos os arquivos desnecessários. Use o procedimento rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files para listar arquivos de dados que ficaram órfãos após a importação de um espaço de tabela e, depois, use o procedimento rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import para excluí-los. Para conhecer a sintaxe e a semântica desses procedimentos, consulte Listar arquivos órfãos após a importação de um espaço para tabela e Excluir arquivos de dados órfãos após a importação de espaços para tabela.
Como limpar os arquivos restantes
-
Remova os backups antigos em
DATA_PUMP_DIRda seguinte forma:-
Liste os arquivos de backup executando
rdsadmin.rdsadmin_file_util.listdir.SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')); -
Remova os backups um por um chamando
UTL_FILE.FREMOVE.EXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'backup_filename');
-
-
Se você importou espaços de tabela, mas não importou metadados para esses espaços de tabela, poderá excluir os arquivos de dados órfãos da seguinte forma:
-
Liste os arquivos de dados órfãos que você precisa excluir. O exemplo a seguir executa o procedimento
rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files.SQL> SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files); FILENAME FILESIZE -------------- --------- datafile_7.dbf 104865792 datafile_8.dbf 104865792 -
Exclua os arquivos órfãos executando o procedimento
rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import.BEGIN rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import('DATA_PUMP_DIR'); END; /A operação de limpeza gera um arquivo de log que usa o formato de nome
rds-xtts-delete_xtts_orphaned_files-no diretórioYYYY-MM-DD.HH24-MI-SS.FF.logBDUMP. -
Leia o arquivo de log gerado na etapa anterior. O exemplo a seguir lê o log
rds-xtts-delete_xtts_orphaned_files-.2023-06-01.09-33-11.868894000.logSELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-delete_xtts_orphaned_files-2023-06-01.09-33-11.868894000.log')); TEXT -------------------------------------------------------------------------------- orphan transported datafile datafile_7.dbf deleted. orphan transported datafile datafile_8.dbf deleted.
-
-
Se você importou espaços de tabela e importou metadados para esses espaços de tabela, mas encontrou erros de compatibilidade ou outros problemas do Oracle Data Pump, limpe os arquivos de dados parcialmente transportados da seguinte forma:
-
Liste os espaços de tabela que contêm arquivos de dados parcialmente transportados consultando
DBA_TABLESPACES.SQL> SELECT TABLESPACE_NAME FROM DBA_TABLESPACES WHERE PLUGGED_IN='YES'; TABLESPACE_NAME -------------------------------------------------------------------------------- TBS_3 -
Elimine os espaços de tabela e os arquivos de dados parcialmente transportados.
DROP TABLESPACETBS_3INCLUDING CONTENTS AND DATAFILES;
-
