O que é o Amazon S3?
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos que oferece escalabilidade líder do setor, disponibilidade de dados, segurança e performance. Clientes de todos os tamanhos e setores podem usar o Amazon S3 para armazenar e proteger qualquer volume de dados para uma variedade de casos de uso, como data lakes, sites, aplicações móveis, backup e restauração, arquivamento, aplicações corporativas, dispositivos IoT e análises de big data. O Amazon S3 fornece recursos de gerenciamento para que você possa otimizar, organizar e configurar o acesso aos seus dados para atender aos seus requisitos específicos de negócios, organizacionais e de compatibilidade.
nota
Para obter mais informações sobre o uso da classe de armazenamento Amazon S3 Express One Zone com buckets de diretório, consulte S3 Express One Zone e Trabalhar com buckets de diretório.
Tópicos
Recursos do Amazon S3
Classes de armazenamento
O Amazon S3 oferece uma ampla variedade de classes de armazenamento para diferentes casos de uso. Por exemplo, você pode armazenar dados de produção essenciais à missão nas classes S3 Standard ou S3 Express One Zone para acesso frequente, economizar custos armazenando dados acessados com pouca frequência nas classes S3 Standard-IA ou S3 One Zone-IA e arquivar dados com os menores custos nas classes S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval e S3 Glacier Deep Archive.
A classe Amazon S3 Express One Zone é uma classe de armazenamento de zona única e alto desempenho do Amazon S3 desenvolvida com o propósito específico de fornecer acesso consistente aos dados e com latência inferior a dez milissegundos para as aplicações mais sensíveis à latência. A classe S3 Express One Zone é a classe de armazenamento de objetos em nuvem de menor latência disponível atualmente, com velocidades de acesso aos dados até dez vezes mais rápidas e custos de solicitação 50% mais baixos do que a classe S3 Standard. S3 Express One Zone é a primeira classe de armazenamento do S3 em que é possível selecionar uma única zona de disponibilidade com a opção de manter o armazenamento de objetos e os recursos de computação na mesma localização, o que fornece a maior velocidade de acesso possível. Além disso, para aumentar ainda mais a velocidade de acesso e oferecer suporte a centenas de milhares de solicitações por segundo, os dados são armazenados em um novo tipo de bucket: um bucket de diretório do Amazon S3. Para obter mais informações, consulte S3 Express One Zone e Trabalhar com buckets de diretório.
Você pode armazenar dados com padrões de acesso alterados ou desconhecidos no S3 Intelligent-Tiering, o que otimiza os custos de armazenamento movendo automaticamente seus dados entre quatro camadas de acesso quando seus padrões de acesso mudam. Esses quatro níveis de acesso incluem dois níveis de acesso de baixa latência otimizados para acesso frequente e infrequente e dois níveis de acesso de arquivamento de inclusão projetados para acesso assíncrono para dados acessados raramente.
Para obter mais informações, consulte Compreender e gerenciar classes de armazenamento do Amazon S3.
Gerenciamento de armazenamento
O Amazon S3 tem recursos de gerenciamento de armazenamento que você pode usar para gerenciar custos, atender aos requisitos normativos, reduzir a latência e salvar várias cópias distintas de seus dados para requisitos de compatibilidade.
-
Ciclo de vida do S3: configure uma política de ciclo de vida para gerenciar os objetos e armazená-los de maneira econômica durante todo o ciclo de vida. Você pode fazer a transição de objetos para outras classes de armazenamento do S3 ou expirar objetos que atingem o fim de suas vidas.
-
Bloqueio de objetos do S3: evita que os objetos do Amazon S3 sejam excluídos ou substituídos por um período de tempo fixo ou indefinidamente. Você pode usar o bloqueio de objetos para ajudar a atender aos requisitos regulamentares que exigem armazenamento write-once-read-many (WORM) ou simplesmente adicionar outra camada de proteção contra alterações e exclusão de objetos.
-
Replicação do S3: replica objetos e seus respectivos metadados e etiquetas de objeto para um ou mais buckets de destino nas mesmas Regiões da AWS, ou diferentes, para reduzir a latência, compatibilidade, segurança e outros casos de uso.
-
Operações em lote do S3: gerencia bilhões de objetos em escala com uma única solicitação de API do S3 ou com alguns cliques no console do Amazon S3. É possível usar operações em lote para executar operações como copiar, invocar uma função do AWS Lambda e restaurar em milhões ou bilhões de objetos.
Gerenciamento de acesso e segurança
O Amazon S3 fornece recursos para auditoria e gerenciamento de acesso a seus buckets e objetos. Por padrão, os buckets do S3 e os objetos deles são privados. Você tem acesso somente aos recursos do S3 criados. Para conceder permissões de recursos detalhadas que suportam seu caso de uso específico ou para auditar as permissões de seus recursos do Amazon S3, você pode usar os seguintes recursos.
-
Bloqueio de acesso público do S3: bloqueie o acesso público a buckets e objetos do S3. Por padrão, as configurações do Bloqueio de Acesso Público são ativadas no nível do bucket. Recomendamos que você mantenha todas as configurações do Bloqueio de Acesso Público habilitadas, a menos que precise desativar uma ou mais delas para seu caso de uso específico. Para obter mais informações, consulte Configurar o bloqueio de acesso público para seus buckets do S3.
-
AWS Identity and Access Management (IAM): o IAM é um serviço da Web que ajuda você a controlar de maneira segura o acesso aos recursos da AWS, incluindo recursos do Amazon S3. Com o IAM, é possível gerenciar, de maneira centralizada, permissões que controlam quais recursos da AWS os usuários poderão acessar. Você usa o IAM para controlar quem é autenticado (fez login) e autorizado (tem permissões) para usar os recursos.
-
Políticas de buckets: use a linguagem de política baseada em IAM para configurar permissões baseadas em recursos para os buckets do S3 e os objetos neles contidos.
-
Pontos de acesso do Amazon S3: configure endpoints nomeados com políticas de acesso dedicadas para gerenciar o acesso a dados em escala para conjuntos de dados compartilhados no Amazon S3.
-
Listas de controle de acesso (ACLs): conceda permissões de leitura e gravação para buckets e objetos individuais a usuários autorizados. Como regra geral, recomendamos o uso de políticas baseadas em recursos do S3 (políticas de bucket e políticas de ponto de acesso) ou políticas de usuários do IAM para controle de acesso, em vez de ACLs. As políticas são uma opção de controle de acesso simplificada e mais flexível. Com políticas de bucket e políticas de ponto de acesso, é possível definir regras que se aplicam amplamente a todas as solicitações para seus recursos do Amazon S3. Para obter mais informações sobre os casos específicos em que você usaria ACLs, em vez de políticas baseadas em recursos ou políticas de usuário do IAM, consulte Gerenciar o acesso com ACLs.
-
Propriedade de objeto do S3: assuma a propriedade de cada objeto do bucket simplificando o gerenciamento de acesso para dados armazenados no Amazon S3. A Propriedade de objeto do S3 é uma configuração no nível do bucket do Amazon S3 que você pode usar para desabilitar ou habilitar as ACLs. Por padrão, as ACLs estão desabilitadas. Com as ACLs desabilitadas, o proprietário do bucket possui todos os objetos do bucket e gerencia o acesso aos dados exclusivamente usando políticas de gerenciamento de acesso.
-
IAM Access Analyzer para S3: avalie e monitore as políticas de acesso ao bucket do S3, garantindo que elas forneçam apenas o acesso pretendido aos recursos do S3.
Processamento de dados
Para transformar dados e acionar fluxos de trabalho para automatizar uma variedade de outras atividades de processamento em escala, você pode usar os seguintes recursos.
-
S3 Object Lambda: adiciona seu próprio código às solicitações GET, HEAD e LIST do S3 para modificar e processar dados, conforme eles são retornados para uma aplicação. Filtra linhas, redimensiona imagens dinamicamente, edita dados confidenciais e muito mais.
-
Notificações de eventos: aciona fluxos de trabalho que usam o Amazon Simple Notification Service (Amazon SNS), o Amazon Simple Queue Service (Amazon SQS) e o AWS Lambda quando uma alteração for feita em seus recursos do S3.
Registro e monitoramento do armazenamento
O Amazon S3 fornece ferramentas de registro e monitoramento que você pode usar para monitorar e controlar como seus recursos do Amazon S3 estão sendo usados. Para obter mais informações, consulte Ferramentas de monitoramento.
Ferramentas de monitoramento automatizadas
-
Métricas do Amazon CloudWatch para o Amazon S3: acompanha a integridade operacional de seus recursos do S3 e configura alertas de faturamento quando as cobranças estimadas atingirem um limite definido pelo usuário.
-
AWS CloudTrail: registra ações executadas por um usuário, uma função ou um AWS service (Serviço da AWS) no Amazon S3. Os logs do CloudTrail fornecem rastreamento detalhado de API para operações no nível de bucket e objeto do S3.
Ferramentas de monitoramento manual
-
Log de acesso ao servidor: fornece detalhes sobre as solicitações que são feitas a um bucket. Você pode usar logs de acesso ao servidor para muitos casos de uso, como conduzir auditorias de segurança e acesso, saber mais sobre sua base de clientes e entender sua fatura do Amazon S3.
-
AWSTrusted Advisor: avalia sua conta usando verificações de práticas recomendadas da AWS para identificar maneiras de otimizar sua infraestrutura da AWS, melhorar a segurança e a performance, reduzir custos e monitorar cotas de serviço. Em seguida, você pode seguir as recomendações para otimizar seus serviços e recursos.
Análise e insights
O Amazon S3 oferece recursos para ajudá-lo a obter visibilidade do uso do armazenamento, o que permite que você entenda melhor, analise e otimize seu armazenamento em escala.
-
Amazon S3 Storage Lens: entende, analisa e otimiza seu armazenamento. O S3 Storage Lens fornece mais de 60 métricas de uso e atividade e painéis interativos para agregar dados de toda a sua organização, contas específicas, Regiões da AWS, buckets ou prefixos.
-
Análise de classe de armazenamento: analisa padrões de acesso ao armazenamento para decidir quando é hora de mover seus dados para uma classe de armazenamento mais econômica.
-
Inventário do S3: audita e relata sobre objetos e seus metadados correspondentes e configura outros recursos do Amazon S3 para executar ações nos relatórios de inventário. Por exemplo, você pode gerar relatórios sobre o status da replicação e da criptografia de seus objetos. Para obter uma lista de todos os metadados disponíveis para cada objeto nos relatórios de inventário, consulte Lista de inventário do Amazon S3.
Consistência forte
O Amazon S3 oferece uma forte consistência de leitura após gravação para solicitações de PUT e DELETE de objetos no bucket do Amazon S3 em todas as Regiões da AWS. Isso se aplica a ambas as gravações em novos objetos, bem como solicitações PUT que sobrescrevem objetos existentes e solicitações DELETE. Além disso, as operações de leitura no Amazon S3 Select, listas de controle de acesso (ACLs) do Amazon S3, etiquetas de objeto do Amazon S3 e metadados de objeto (por exemplo, objeto HEAD) são fortemente consistentes. Para obter mais informações, consulte Modelo de consistência de dados do Amazon S3.
Como funciona o Amazon S3
O Amazon S3 é um serviço de armazenamento de objetos que armazena dados, dados hierárquicos ou dados tabulares em buckets. Um objeto é um arquivo e quaisquer metadados que descrevam o arquivo. Um bucket é um contêiner de objetos.
Para armazenar seus dados no Amazon S3, crie um bucket e especifique um nome de bucket e a Região da AWS. Em seguida, carregue seus dados para esse bucket como objetos no Amazon S3. Cada objeto tem uma chave (ou nome de chave), que é um identificador exclusivo do objeto no bucket.
O S3 fornece recursos que você pode configurar para oferecer suporte ao seu caso de uso específico. Você pode usar o versionamento do S3 para manter várias versões de um objeto no mesmo bucket que permite que você restaure objetos excluídos ou substituídos acidentalmente.
Os buckets e os objetos neles são privados e poderão ser acessados somente se você conceder explicitamente permissões de acesso. Você pode usar políticas de bucket, políticas do AWS Identity and Access Management (IAM), listas de controle de acesso (ACLs) e pontos de acesso do S3 para gerenciar o acesso.
Tópicos
Buckets
O Amazon S3 comporta quatro tipos de bucket: de uso geral, de diretório, de tabela e de vetores. Cada tipo de bucket oferece um conjunto exclusivo de recursos para diferentes casos de uso.
Buckets de uso geral: eles são recomendados para a maioria dos casos de uso e padrões de acesso e são o tipo original de bucket do S3. Um bucket de uso geral é um contêiner para objetos armazenados no Amazon S3, e você pode armazenar qualquer número de objetos em um bucket e em todas as classes de armazenamento (exceto na classe S3 Express One Zone). Desse modo, é possível armazenar objetos de forma redundante em várias zonas de disponibilidade. Para ter mais informações, consulte Criar, configurar e trabalhar com buckets de uso geral do Amazon S3.
Por padrão, os buckets de uso geral existem em um namespace global, o que significa que cada nome de bucket deve ser exclusivo em todas as Contas da AWS de todas as Regiões da AWS dentro de uma partição. Uma partição é um agrupamento de regiões. No momento, a AWS tem quatro partições: aws (regiões padrão), aws-cn (regiões da China), aws-us-gov (AWS GovCloud (US)) e aws-eusc (European Sovereign Cloud). Ao criar um bucket de uso geral, é possível optar por criar um bucket no namespace global compartilhado ou por criar um bucket no namespace regional da conta. O namespace regional da conta é uma subdivisão do namespace global em que somente a conta pode criar buckets. Os novos buckets de uso geral criados no namespace regional da conta são exclusivos da conta e nunca podem ser recriados por outra conta. Para ter mais informações sobre namespaces de bucket, consulte Namespaces para buckets de uso geral.
nota
Por padrão, todos os buckets de uso geral são privados. Mas você pode conceder acesso público a buckets de uso geral. É possível controlar o acesso a buckets de uso geral em nível de bucket, prefixo (pasta) ou tag de objeto. Para ter mais informações, consulte Controle de acesso no Amazon S3.
Buckets de diretório: recomendados para casos de uso de baixa latência e de residência de dados. Por padrão, é possível criar até cem buckets de diretório em suas Conta da AWS, sem limite no número de objetos que podem ser armazenados em um bucket de diretório. Os buckets de diretório organizam os dados em diretórios hierárquicos (prefixos), e não na estrutura de armazenamento plana dos buckets de uso geral. Esse tipo de bucket não tem limites de prefixo, e diretórios individuais podem escalar horizontalmente. Para ter mais informações, consulte Trabalhar com buckets de diretório.
-
Para casos de uso de baixa latência, você pode criar um bucket de diretório em uma única zona de disponibilidade da AWS para armazenar dados. Buckets de diretório em zonas de disponibilidade permitem a classe de armazenamento S3 Express One Zone. Com a classe S3 Express One Zone, os dados são armazenados de forma redundante em vários dispositivos dentro de uma única zona de disponibilidade. A classe de armazenamento S3 Express One Zone é recomendada se a aplicação é sensível ao desempenho e se beneficia de latências inferiores a dez milissegundos para
PUTeGET. Para saber mais sobre como criar buckets de diretório em zonas de disponibilidade, consulte Workloads de alto desempenho. -
Para casos de uso de residência de dados, você pode criar um bucket de diretório em uma única zona local dedicada (DLZ) da AWS para armazenar dados. Nas zonas locais dedicadas, é possível criar buckets de diretório do S3 para armazenar dados em um perímetro de dados específico, o que ajuda a apoiar casos de uso de isolamento e residência de dados. Os buckets de diretório em zonas locais são compatíveis com a classe de armazenamento S3 One Zone-Infrequent Access (S3 One Zone-IA; Z-IA). Para saber mais sobre como criar buckets de diretório em zonas locais, consulte Workloads de residência de dados.
nota
Nos buckets de diretório, todo acesso público é desabilitado por padrão. Esse comportamento não pode ser alterado. Você não pode conceder acesso a objetos armazenados em buckets de diretório. Você pode conceder acesso somente aos seus buckets de diretório. Para ter mais informações, consulte Autenticar e autorizar solicitações.
Buckets de tabela: recomendados para armazenar dados tabulares, como transações de compras diárias, dados de sensores de streaming ou impressões de anúncios. Os dados tabulares representam dados em colunas e linhas, como em uma tabela de banco de dados. Os buckets de tabela oferecem armazenamento do S3 otimizado para workloads de analytics e machine learning, com recursos projetados para melhorar continuamente a performance das consultas e reduzir os custos de armazenamento de tabelas. As tabelas do S3 são criadas especificamente para armazenar dados tabulares no formato Apache Iceberg. Você pode consultar dados tabulares nas tabelas do S3 com mecanismos de consulta conhecidos, como Amazon Athena, Amazon Redshift e Apache Spark. Por padrão, é possível criar até 10 buckets de tabela por Conta da AWS por Região da AWS e até 10 mil tabelas por bucket de tabela. Para ter mais informações, consulte Trabalhar com a funcionalidade Tabelas do Amazon S3 e com buckets de tabela.
nota
Todas as tabelas e buckets de tabela são privados e não podem ser tornados públicos. Esses recursos só podem ser acessados por usuários que tenham recebido acesso explícito. Para conceder acesso, você pode usar políticas baseadas em recurso do IAM para tabelas e buckets de tabela, e políticas baseadas em identidade do IAM para usuários e perfis. Para ter mais informações, consulte Segurança para a funcionalidade Tabelas do S3.
Buckets de vetores: os buckets de vetores do S3 são um tipo de bucket do Amazon S3 criado especificamente para armazenar e consultar vetores. Os buckets de vetores usam operações de API dedicadas para gravar e consultar dados vetoriais com eficiência. Com os buckets de vetores do S3, você pode armazenar incorporações de vetores para modelos de machine learning, realizar pesquisas por similaridade e integrar-se a determinados serviços, como o Amazon Bedrock e o Amazon OpenSearch.
Os buckets de vetores do S3 organizam os dados usando índices de vetores, que são recursos dentro de um bucket que armazenam e organizam os dados vetoriais para oferecer uma pesquisa por similaridade eficiente. Cada índice de vetores pode ser configurado com dimensões, métricas de distância (como similaridade de cosseno) e configurações de metadados específicas para otimizar seu caso de uso específico. Para obter mais informações, consulte Trabalhar com o S3 Vectors e buckets de vetores.
Informações adicionais sobre todos os tipos de bucket
Ao criar um bucket, você insere um nome de bucket e escolhe a Região da AWS onde o bucket residirá. Assim que você cria um bucket, não pode mais alterar o nome do bucket ou sua região. Os nomes de bucket devem seguir as regras de nomenclatura de bucket.
Os buckets também:
-
Organizam o namespace do Amazon S3 no nível mais elevado. Para buckets de uso geral, esse namespace é
S3. Para buckets de diretório, esse namespace és3express. Para buckets de tabela, esse namespace és3tables. -
Identificam a conta responsável por cobranças de transferência de dados e armazenamento.
-
Serve como a unidade de agregação para relatório de uso.
Objetos
Os objetos são as entidades fundamentais armazenadas no Amazon S3. Os objetos consistem em metadados e dados de objeto. Os metadados são um conjunto de pares de nome e valor que descrevem o objeto. Esses pares incluem alguns metadados padrão, como a data da última modificação, e metadados HTTP padrão, como o Content-Type. Você também pode especificar metadados personalizados no momento em que o objeto é armazenado.
Cada objeto está contido em um bucket. Por exemplo, se o objeto chamado photos/puppy.jpg estiver armazenado no bucket de uso geral amzn-s3-demo-bucket da região Oeste dos EUA (Oregon), ele poderá ser endereçado usando o URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg. Para obter mais informações, consulte Accessing a Bucket (Como acessar um bucket).
Um objeto é identificado exclusivamente em um bucket por uma chave (nome) e um ID da versão (se o Versionamento do S3 estiver habilitado no bucket). Para obter mais informações sobre objetos, consulte Visão geral de objetos Amazon S3.
Chaves
Uma chave de objeto (ou nome da chave) é um identificador exclusivo de um objeto em um bucket. Cada objeto em um bucket tem exatamente uma chave. A combinação de um bucket, chave de objeto e, opcionalmente, o ID de versão (se o Versionamento do S3 estiver habilitado para o bucket) identifica exclusivamente cada objeto. Portanto, é possível pensar no Amazon S3 como um mapa de dados básico entre "bucket + chave + versão" e o objeto em si.
Cada objeto no Amazon S3 pode ser endereçado exclusivamente por meio da combinação do endpoint de serviço da web, do nome de bucket, da chave e, opcionalmente, de uma versão. Por exemplo, no URL https://, amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg é a chave.
Para obter mais informações sobre chaves de objeto, consulte Nomear objetos do Amazon S3.
Versionamento do S3
Use o versionamento do S3 para manter diversas variantes de um objeto no mesmo bucket. Com o versionamento do S3, você pode preservar, recuperar e restaurar todas as versões de cada objeto armazenado em seus buckets. Você pode se recuperar facilmente de ações não intencionais do usuário e de falhas da aplicação.
Para obter mais informações, consulte Reter várias versões de objetos com o Versionamento do S3.
ID da versão
Se você habilitar o versionamento do S3 em um bucket, o Amazon S3 gerará um ID de versão exclusivo para cada objeto adicionado ao bucket. Os objetos que já existiam no bucket no momento em que você habilita o controle de versão têm um ID de versão null. Se você modificar esses (ou quaisquer outros) objetos com outras operações, como CopyObject e PutObject, os novos objetos obtêm um ID de versão exclusivo.
Para obter mais informações, consulte Reter várias versões de objetos com o Versionamento do S3.
Política de bucket
Uma política de bucket é baseada em recursos do AWS Identity and Access Management (IAM) que você pode usar para conceder permissões de acesso ao bucket e aos objetos nele contidos. Só o proprietário do bucket pode associar uma política a um bucket. As permissões anexadas ao bucket se aplicam a todos os objetos do bucket que pertencem ao proprietário do bucket. As políticas de bucket são limitadas a 20 KB.
As políticas de bucket usam uma linguagem de políticas de acesso baseada em JSON que é padrão na AWS. Você pode usar políticas de bucket para adicionar ou negar permissões para os objetos em um bucket. As políticas de bucket permitem ou negam solicitações com base nos elementos da política, incluindo o solicitante, ações do S3, recursos e aspectos ou condições da solicitação (por exemplo, o endereço IP usado para fazer a solicitação). Por exemplo, você pode criar uma política de bucket que conceda permissões entre contas para carregar objetos em um bucket do S3 enquanto garante que o proprietário do bucket tenha controle total dos objetos carregados. Para obter mais informações, consulte Exemplos de políticas de bucket do Amazon S3.
Na política de bucket, você pode usar caracteres curinga nos nomes de recursos da Amazon (ARNs) e outros valores para conceder permissões a um subconjunto de objetos. Por exemplo, você pode controlar o acesso a grupos de objetos que começam com um prefixo ou termine com uma determinada extensão, como .html.
Pontos de Acesso S3
Os Pontos de Acesso Amazon S3 são endpoints de rede nomeados com políticas de acesso dedicadas que descrevem como os dados podem ser acessados usando esse endpoint. Os pontos de acesso são anexados a uma fonte de dados subjacente, como um bucket de uso geral, bucket de diretório ou um volume do FSx para OpenZFS, que você pode usar para executar operações de objeto do S3, como GetObject e PutObject. Os pontos de acesso simplificam o gerenciamento do acesso a dados em escala para conjuntos de dados compartilhados no Amazon S3.
Cada ponto de acesso tem sua própria política. Você também pode configurar as definições do Bloqueio de Acesso Público para cada ponto de acesso anexado a um bucket. Você pode configurar qualquer ponto de acesso para aceitar solicitações somente de uma nuvem virtual privada (VPC) para restringir o acesso a dados do Amazon S3 a uma rede privada.
Para ter mais informações sobre pontos de acesso para buckets de uso geral, consulte Gerenciar o acesso a conjuntos de dados compartilhados com pontos de acesso. Para ter mais informações sobre pontos de acesso para buckets de diretório, consulte Gerenciar o acesso a conjuntos de dados compartilhados em buckets de diretório por meio de pontos de acesso.
Listas de controle de acesso (ACLs)
Você pode usar ACLs para conceder permissões de leitura e gravação a usuários autorizados referentes a buckets de uso geral e objetos individuais. Cada bucket de uso geral e objeto tem uma ACL anexada como um sub-recurso. Uma ACL define a quais grupos ou Contas da AWS é concedido acesso, bem como o tipo de acesso. As ACLs são mecanismos de controle de acesso que antecedem o IAM. Para ter mais informações sobre ACLs, consulte Visão geral da lista de controle de acesso (ACL).
A Propriedade de objetos do S3 é uma configuração no nível do bucket do Amazon S3 que você pode usar para controlar a propriedade de objetos carregados no bucket e para desabilitar ou habilitar as ACLs. Por padrão, a Propriedade de Objetos está definida com a configuração Imposto pelo proprietário do bucket e todas as ACLs estão desabilitadas. Quando as ACLs são desabilitadas, o proprietário do bucket possui todos os objetos do bucket e gerencia o acesso a eles exclusivamente usando políticas de gerenciamento de acesso.
A maioria dos casos de uso modernos no Amazon S3 não exige mais o uso de ACLs. Recomendamos manter as ACLs desabilitadas, exceto em circunstâncias em que seja necessário controlar o acesso para cada objeto individualmente. Com as ACLs desabilitadas, é possível usar políticas para controlar o acesso a todos os objetos no bucket, independentemente de quem carregou os objetos para o bucket. Para obter mais informações, consulte Controlar a propriedade de objetos e desabilitar ACLs para seu bucket.
Regiões
Você pode escolher a região da Região da AWS geográfica onde o Amazon S3 armazena os buckets criados. É possível escolher uma r[Região para otimizar a latência, minimizar os custos ou atender a requisitos regulatórios. Os objetos armazenados em uma Região da AWS nunca saem dela, a não ser que você os transfira ou os replique explicitamente para outra região. Por exemplo, os objetos armazenados na região da UE (Irlanda) nunca saem dela.
nota
Só é possível acessar o Amazon S3 e seus recursos em Regiões da AWS que estão habilitadas para sua conta. Para obter mais informações sobre como habilitar uma região para criar e gerenciar recursos da AWS, consulte Como gerenciar Regiões da AWS na Referência geral da AWS.
Para obter uma lista de regiões e endpoints do Amazon S3, consulte Regiões e endpoints na Referência geral da AWS.
Modelo de consistência de dados do Amazon S3
O Amazon S3 oferece uma forte consistência de leitura após gravação para solicitações de PUT e DELETE de objetos no bucket do Amazon S3 em todas as Regiões da AWS. Isso se aplica a ambas as gravações em novos objetos, bem como solicitações PUT que sobrescrevem objetos existentes e solicitações DELETE. Além disso, as operações de leitura no Amazon S3 Select, listas de controle de acesso (ACLs) do Amazon S3, etiquetas de objeto do Amazon S3 e metadados de objeto (por exemplo, objeto HEAD) são muito consistentes.
As atualizações em uma única chave são atômicas. Por exemplo, se você executar uma solicitação PUT em uma chave existente de um thread e executar uma solicitação GET na mesma chave de um segundo thread simultaneamente, você obterá os dados antigos ou os novos dados, mas nunca dados parciais ou corrompidos.
O Amazon S3 atinge alta disponibilidade replicando dados entre vários servidores nos datacenters da AWS. Se uma solicitação PUT for bem-sucedida, os dados serão armazenados com segurança. Qualquer leitura (solicitação de GET ou LIST) iniciada após o recebimento de uma resposta PUT bem-sucedida retornará os dados escritos pelo PUT. Veja alguns exemplos desse comportamento:
-
Um processo grava um novo objeto no Amazon S3 e imediatamente lista as chaves em seu bucket. O novo objeto aparecerá na lista.
-
Um processo substitui um objeto existente e imediatamente tenta lê-lo. O Amazon S3 retorna os novos dados.
-
Um processo exclui um objeto existente e imediatamente tenta lê-lo. O Amazon S3 não retorna dados porque o objeto foi excluído.
-
Um processo exclui um objeto existente e imediatamente lista as chaves em seu bucket. O objeto não aparecerá na listagem.
nota
-
O Amazon S3 não oferece suporte ao bloqueio de objetos para escritores simultâneos. Se duas solicitações PUT forem realizadas simultaneamente na mesma chave, a solicitação com o time stamp mais recente será a escolhida. Se isso for um problema, você precisará criar um mecanismo de bloqueio de objetos em sua aplicação.
-
As atualizações são baseadas em chave. Não há possibilidade de realizar atualizações atômicas entre chaves. Por exemplo, você não pode tornar a atualização de uma chave dependente da atualização de outra chave a menos que você desenvolva essa funcionalidade em seu aplicativo.
As configurações de bucket têm um modelo de consistência eventual. Especificamente, isso significa que:
-
Por exemplo, se você excluir um bucket e listar imediatamente todos os buckets, o bucket excluído ainda poderá ser exibido na lista.
-
Se você ativar o versionamento em um bucket pela primeira vez, pode levar um curto período de tempo para que a alteração seja totalmente propagada. Recomendamos que você aguarde 15 minutos após ativar o versionamento antes de emitir operações de gravação (solicitações PUT ou DELETE) em objetos no bucket.
Aplicações simultâneas
Esta seção fornece exemplos de comportamento a serem esperados do Amazon S3 quando vários clientes estão gravando nos mesmos itens.
Neste exemplo, W1 (gravação 1) e W2 (gravação 2) são concluídas antes do início de R1 (leitura 1) e R2 (leitura 2). Como o S3 é fortemente consistente, R1 e R2 retornam color = ruby.
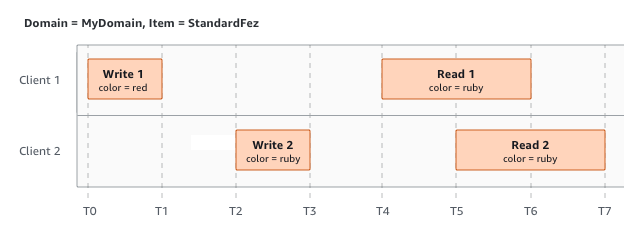
No próximo exemplo, a W2 não é encerrada antes do início da R1. Portanto, R1 pode retornar color = ruby ou color = garnet. No entanto, como W1 e W2 terminam antes do início do R2, o R2 retorna color =
garnet.
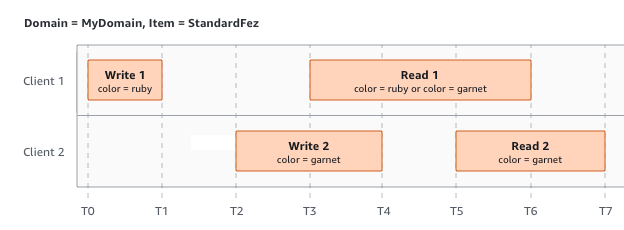
No último exemplo, o W2 começa antes que o W1 tenha recebido uma confirmação. Portanto, essas gravações são consideradas simultâneas. O Amazon S3 usa internamente a semântica do último escritor para determinar qual gravação tem precedência. No entanto, a ordem em que o Amazon S3 recebe as solicitações e a ordem em que as aplicações recebem confirmações não podem ser previstas devido a fatores como a latência de rede. Por exemplo, o W2 pode ser iniciado por uma instância do Amazon EC2 na mesma região, enquanto o W1 pode ser iniciado por um host que está mais longe. A melhor maneira de determinar o valor final é realizar uma leitura após ambas as gravações terem sido confirmadas.

Serviços relacionados
Depois de carregar os dados no Amazon S3, você poderá usá-los com outros serviços da AWS. Os serviços a seguir podem ser usados com mais frequência:
-
O Amazon Elastic Compute Cloud (Amazon EC2)
oferece uma capacidade de computação escalável na Nuvem AWS. O uso do Amazon EC2 elimina a necessidade de investir em hardware inicialmente, portanto, você pode desenvolver e implantar aplicações com mais rapidez. É possível usar o Amazon EC2 para executar quantos servidores virtuais forem necessários, configurar a segurança e as redes e gerenciar o armazenamento. -
Amazon EMR
: ajuda empresas, pesquisadores, analistas de dados e desenvolvedores a processar de maneira fácil e econômica grandes quantidades de dados. O Amazon EMR usa um framework do Hadoop hospedado que é executado na infraestrutura de escala da Web do Amazon EC2 e do Amazon S3. -
AWS Transfer Family
– fornece suporte totalmente gerenciado para transferências de arquivos diretamente para dentro e fora do Amazon S3 ou Amazon Elastic File System (Amazon EFS) usando Secure Shell (SSH), File Transfer Protocol (SFTP), File Transfer Protocol over SSL (FTPS) e File Transfer Protocol (FTP).
Acesso ao Amazon S3
Você pode trabalhar com o Amazon S3 de qualquer uma das seguintes formas:
AWS Management Console
O console é uma interface de usuário baseada na Web para gerenciar o Amazon S3 e o recursos da AWS. Se você se inscreveu em uma Conta da AWS, pode acessar o console do Amazon S3 fazendo login no AWS Management Console e escolhendo S3 na página inicial do AWS Management Console.
AWS Command Line Interface
Você pode usar as ferramentas de linha de comando da AWS para emitir comandos ou criar scripts na linha de comando de seu sistema e executar tarefas da AWS (incluindo o S3).
A AWS Command Line Interface (AWS CLI)
AWS SDKs
AWSA fornece SDKs (kits de desenvolvimento de software) que consistem em bibliotecas e códigos de exemplo para várias linguagens de programação e plataformas (Java, Python, Ruby, .NET, iOS, Android etc.). Os AWS SDKs constituem uma forma conveniente de criar acesso programático para o S3 e a AWS. O Amazon S3 é um serviço REST. É possível enviar solicitações para o Amazon S3 usando a API REST ou as bibliotecas SDK da AWS, que envolvem a API REST do Amazon S3 e simplificam as tarefas de programação. Por exemplo, os SDKs processam tarefas como calcular assinaturas, assinar solicitações de forma criptográfica, gerenciar erros e novas tentativas automáticas de solicitações. Para obter informações sobre os AWS SDKs, incluindo como baixar e instalá-los, consulte Ferramentas da AWS
Cada interação com o Amazon S3 é autenticada ou anônima. Se você estiver usando os AWS SDKs, as bibliotecas calcularão a assinatura das chaves fornecidas. Consulte mais informações sobre como fazer solicitações ao Amazon S3 em Making requests.
API REST do Amazon S3
A arquitetura do Amazon S3 foi desenvolvida para ser neutra em termos de linguagem de programação, usando nossas interfaces compatíveis com a AWS para armazenar e recuperar objetos. Você pode acessar o S3 e a AWS de forma programada usando a API REST do Amazon S3. A API REST é uma interface HTTP para o Amazon S3. Usando a API REST, você usa solicitações HTTP padrão para criar, buscar e excluir buckets e objetos.
Você pode usar qualquer toolkit compatível com HTTP para usar a API REST. Você pode até usar um navegador para buscar objetos, desde que eles possam ser lidos anonimamente.
A API REST usa os cabeçalhos padrão e os códigos de status HTTP para que os navegadores e os toolkits padrão funcionem como esperado. Em algumas áreas, adicionamos funcionalidade ao HTTP (por exemplo, adicionamos cabeçalhos para oferecer suporte ao controle de acesso). Nesses casos, fizemos o melhor para adicionar nova funcionalidade de uma forma que correspondesse ao estilo de uso padrão do HTTP.
Se fizer chamadas diretas da API REST na aplicação, você deverá escrever o código para calcular a assinatura e adicioná-la à solicitação. Consulte mais informações sobre como fazer solicitações ao Amazon S3 em Making requests na Referência de API do Amazon S3.
nota
O suporte da API de SOAP via HTTP está defasado, mas continua disponível via HTTPS. Os novos recursos do Amazon S3 não são compatíveis com o SOAP. Recomendamos usar a API REST ou os AWS SDKs.
Pagar pelo Amazon S3
A definição de preço para o Amazon S3 foi desenvolvida para que você não precise planejar para os requisitos de armazenamento da aplicação. A maioria dos provedores de armazenamento exige que você adquira uma quantidade predeterminada de armazenamento e capacidade de transferência de rede. Nesse cenário, se você exceder essa capacidade, o serviço é desativado ou você é cobrado por altas taxas excedentes. Se você não exceder essa capacidade, você paga como se tivesse usado tudo.
O Amazon S3 cobra apenas pelo que você realmente usa, sem taxas ocultas e nenhuma taxa excedente. Este modelo fornece a você um serviço com custo variável que pode aumentar com seus negócios enquanto proporciona a você as vantagens de custos de infraestrutura da AWS. Para obter mais informações, consulte Preços do Amazon S3
Ao cadastrar-se na AWS, sua Conta da AWS é automaticamente cadastrada em todos os serviços da AWS incluindo o Amazon S3. Entretanto, você será cobrado apenas pelos serviços que usar. Se você for um novo cliente do Amazon S3, você pode começar a usar o Amazon S3 gratuitamente. Para obter mais informações, consulte nível gratuito da AWS
Para ver sua fatura, acesse o Painel de Billing and Cost Management no console da Gerenciamento de Faturamento e Custos da AWS
Conformidade do PCI DSS
O Amazon S3 é compatível com o processamento, o armazenamento e a transmissão de dados de cartão de crédito por um comerciante ou um provedor de serviços e foi validada como em conformidade com o Data Security Standard (DSS, Padrão de segurança de dados) da Payment Card Industry (PCI, Padrão de cartão de crédito). Para obter mais informações sobre o PCI DSS, incluindo como solicitar uma cópia do pacote de conformidade com o PCI da AWS, consulte Nível 1 do PCI DSS
