Trabalhar com o Amazon S3 Files
Tópicos
O que é o S3 Files?
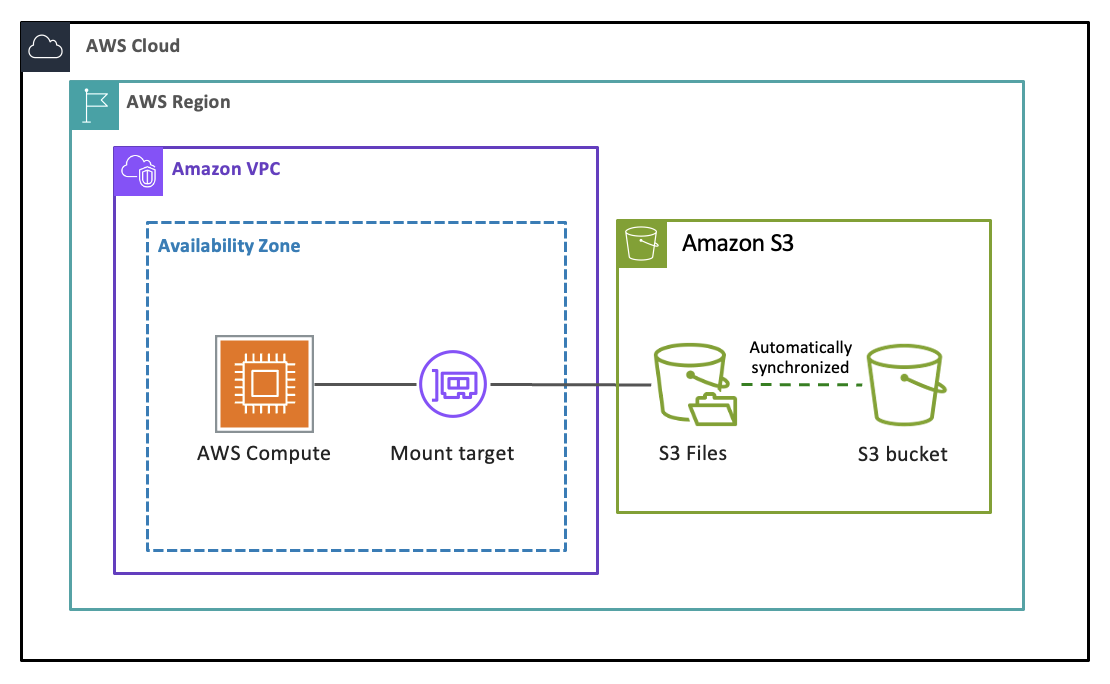
O S3 Files é um sistema de arquivos compartilhado que conecta qualquer recurso de computação da AWS diretamente aos dados no Amazon S3. Ele oferece acesso rápido e direto a todos os dados do S3 como arquivos com semântica completa do sistema de arquivos e desempenho de baixa latência, sem que os dados saiam do S3. Todos os agentes, aplicações baseadas em arquivo e equipes podem acessar e trabalhar com seus dados do S3 como um sistema de arquivos usando as ferramentas que eles já utilizam. Criado com o Amazon EFS, o S3 oferece o desempenho e a simplicidade de um sistema de arquivos com a escalabilidade, durabilidade e economia do S3. Você pode ler, gravar e organizar dados usando operações de arquivo e diretório, enquanto o S3 Files gerencia a sincronização das alterações entre o bucket e o sistema de arquivos.
Como o S3 Files funciona?
Quando você cria um sistema de arquivos do S3 vinculado ao seu bucket do S3 ou a um prefixo dentro dele e o monta em um recurso de computação, como uma instância do EC2 ou uma função do Lambda, o S3 Files primeiro apresenta uma visualização navegável dos objetos do bucket como arquivos. Conforme você navega pelos diretórios e abre arquivos, o conteúdo e os metadados correspondentes são colocados no armazenamento de alta performance do sistema de arquivos. Quando você lê arquivos, o S3 Files carrega o respectivo conteúdo no armazenamento de alta performance sob demanda, sem duplicar todo o conjunto de dados. Quando você grava dados, as gravações são inseridas no armazenamento de alta performance e sincronizadas de volta para o bucket do S3. O S3 Files converte de forma inteligente as operações do sistema de arquivos em solicitações eficientes do S3 em seu nome. Muitas operações de leitura ignoram totalmente o sistema de arquivos, caso em que os dados são fornecidos diretamente do S3.
É possível configurar o limite de tamanho de arquivo que é carregado no armazenamento de alta performance (o padrão é < 128 KiB), pois as latências são mais importantes para arquivos pequenos. O S3 Files transmite leituras de arquivo diretamente do bucket do S3 em dois casos: quando os dados do arquivo não estão armazenados no armazenamento de alta performance do sistema de arquivos e para leituras grandes (>= 1 MiB), mesmo quando os dados também residem no armazenamento de alta performance do sistema de arquivos. O bucket do S3 é otimizado para oferecer alto throughput, enquanto a camada de armazenamento de alta performance do sistema de arquivos é otimizada para oferecer acesso de baixa latência. O S3 Files importa de forma assíncrona dados de arquivos pequenos (< 128 KiB, por padrão) para o armazenamento de alta performance do sistema de arquivos para oferecer acesso de baixa latência em leituras subsequentes. Os dados modificados recentemente que ainda não foram sincronizados com o S3 são sempre fornecidos pelo sistema de arquivos. Para obter mais informações, consulte Personalizar a sincronização para o S3 Files.
Os dados que não foram lidos em uma janela configurável (de 1 a 365 dias, padrão de 30) expiram automaticamente no armazenamento de alta performance. Os dados autorizados sempre permanecem no S3, e a sincronização em segundo plano mantém o sistema de arquivos e o bucket consistentes em ambas as direções. Para obter mais informações, consulte Como funciona a sincronização.
Os serviços de computação compatíveis para montar sistemas de arquivos do S3 são o Amazon EC2, o AWS Lambda, o Amazon EKS e o Amazon ECS. Para obter mais informações, consulte Montar seus buckets do S3 em recursos de computação.
Você está usando o S3 Files pela primeira vez?
Se estiver usando o S3 Files pela primeira vez, use o console do S3 ou a AWS CLI seguindo o Tutorial: conceitos básicos do S3 Files para criar seu primeiro sistema de arquivos do S3.
Principais conceitos
Os seguintes termos são usados ao longo da documentação do S3 Files:
- Sistema de arquivos
Um sistema de arquivos compartilhado vinculado a um bucket do S3.
- Armazenamento de alta performance
Camada de armazenamento de baixa latência no sistema de arquivos na qual residem os dados e metadados de arquivos usados ativamente. O S3 Files gerencia automaticamente esse armazenamento, copiando os dados para ele quando os arquivos são acessados e removendo os dados que não foram lidos de acordo com uma janela de expiração configurável. Você paga uma taxa de armazenamento pelos dados que residem no armazenamento de alta performance.
- Sincronização
Processo por meio do qual o S3 Files mantém o conjunto de dados de trabalho ativo e as alterações consistentes entre o sistema de arquivos e o bucket do S3. A importação copia dados do bucket do S3 para o sistema de arquivos. A exportação copia as alterações feitas por meio do sistema de arquivos de volta para o bucket do S3. O S3 Files executa a sincronização automaticamente em ambas as direções.
- Destino de montagem
Um destino de montagem oferece acesso de rede ao sistema de arquivos em uma única zona de disponibilidade em sua VPC. É necessário ter pelo menos um destino de montagem para acessar o sistema de arquivos por meio dos recursos de computação e é possível criar no máximo um destino de montagem por zona de disponibilidade.
- Ponto de acesso
Pontos de acesso são pontos de entrada específicos da aplicação em um sistema de arquivos que simplificam o gerenciamento de acesso a dados em grande escala para conjuntos de dados compartilhados. É possível usar um ponto de acesso para impor identidades e permissões de usuário para todas as solicitações do sistema de arquivos feitas por meio do ponto de acesso. Quando um sistema de arquivos é criado por meio do Console de Gerenciamento da AWS, o S3 Files cria automaticamente um ponto de acesso para o sistema de arquivos.
Recursos
- Alto desempenho sem replicação total de dados
O S3 Files oferece acesso de baixa latência aos arquivos copiando somente o conjunto de trabalho ativo para o armazenamento de alta performance do sistema de arquivos, e não todo o conjunto de dados. Os arquivos pequenos e acessados com frequência são fornecidos pelo armazenamento de alta performance com latências de menos de 1 milissegundo a latências abaixo de 10 milissegundos. As leituras grandes são transmitidas diretamente do S3 com até terabytes por segundo de throughput agregado. Isso significa que você obtém desempenho do sistema de arquivos para workloads interativas e throughput do S3 para workloads de streaming, sem pagar para armazenar ou importar dados que não estão sendo usados ou que não se beneficiam da baixa latência. Para obter mais informações, consulte Especificações de desempenho.
- Roteamento inteligente de leitura
O S3 Files encaminha automaticamente as solicitações de leitura à camada de armazenamento (sistema de arquivos do S3 ou bucket do S3) mais adequada para elas, mantendo a semântica completa do sistema de arquivos, inclusive consistência, bloqueio e permissões POSIX. Leituras pequenas e aleatórias de arquivos usados ativamente são fornecidas pelo armazenamento de alta performance para oferecer baixa latência. Grandes leituras sequenciais e leituras de dados que não estão no sistema de arquivos são fornecidas diretamente do bucket do S3 para oferecer alto throughput, sem cobrança de dados do sistema de arquivos.
- Sincronização automática
O S3 Files mantém automaticamente o sistema de arquivos e o bucket do S3 consistentes em ambas as direções. As alterações feitas por meio do sistema de arquivos são copiadas de volta para o bucket do S3 e as alterações feitas diretamente no bucket do S3 são reproduzidas na visualização do sistema de arquivos. É possível personalizar o comportamento da sincronização, como quais dados devem ser importados e por quanto tempo devem permanecer no sistema de arquivos. Para obter mais informações, consulte Como funciona a sincronização.
- Desempenho escalável
O S3 Files escala automaticamente throughput e IOPS para que correspondam à atividade da workload. Você não precisa provisionar nem gerencia a capacidade de desempenho e paga apenas pelo que usa.
- Durabilidade regional
Os dados gravados na camada de armazenamento de alta performance têm a mesma durabilidade que no Amazon S3. Os dados são armazenados de maneira redundante em várias zonas de disponibilidade separadas geograficamente na mesma região da AWS, oferecendo alta durabilidade e disponibilidade para eles.
- Criptografia
O S3 Files criptografa todos os dados em trânsito usando TLS e todos os dados em repouso usando chaves do AWS KMS. Você pode usar chaves de propriedade da AWS (padrão) ou suas próprias chaves gerenciadas pelo cliente. Para obter mais informações, consulte Criptografia.
- Semântica do sistema de arquivos
O S3 Files é compatível com as versões 4.2 e 4.1 do protocolo NFS. Ele oferece semântica de acesso ao sistema de arquivos, como consistência de dados de leitura após gravação, bloqueio de arquivos e permissões POSIX.
Como o S3 Files é faturado?
Você paga uma taxa de armazenamento pela fração de dados ativos residentes no armazenamento de alta performance e paga taxas de acesso ao sistema de arquivos pela leitura e gravação no armazenamento de alta performance do sistema de arquivos. O S3 Files transmite leituras de arquivo diretamente do bucket do S3 em dois casos: quando os dados do arquivo não estão armazenados no armazenamento de alta performance do sistema de arquivos e para leituras grandes (>= 1 MiB), mesmo quando os dados também residem no armazenamento de alta performance do sistema de arquivos. O bucket do S3 é otimizado para oferecer alto throughput, enquanto a camada de armazenamento de alta performance do sistema de arquivos é otimizada para oferecer acesso de baixa latência. O S3 Files importa de forma assíncrona dados de arquivos pequenos (< 128 KiB, por padrão) para o armazenamento de alta performance do sistema de arquivos para oferecer acesso de baixa latência em leituras subsequentes. Essas leituras estão sujeitas apenas ao custo padrão das solicitações GET do S3, não havendo cobranças de acesso ao sistema de arquivos. As taxas de acesso ao sistema de arquivos se aplicam às operações de sincronização: a importação de dados para o sistema de arquivos gera custos de gravação e a exportação de alterações de volta para o S3 gera custos de leitura. Para obter mais informações, consulte Como o S3 Files é medido. Para ver os preços atuais, consulte a página Preços do S3 Files
