As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migração de dados do armazém de dados local para o Amazon Redshift com AWS Schema Conversion Tool
Você pode usar um AWS SCT agente para extrair dados do seu armazém de dados local e migrá-los para o Amazon Redshift. O agente extrai seus dados e os carrega para o Amazon S3 ou, para migrações em grande escala, para um dispositivo Edge. AWS Snowball Edge Em seguida, você pode usar um AWS SCT agente para copiar os dados para o Amazon Redshift.
Como alternativa, você pode usar AWS Database Migration Service (AWS DMS) para migrar dados para o Amazon Redshift. A vantagem do AWS DMS é o suporte à replicação contínua (captura de dados de alteração). No entanto, para aumentar a velocidade da migração de dados, use vários AWS SCT agentes em paralelo. De acordo com nossos testes, os AWS SCT agentes migram dados mais rápido do que 15 a AWS DMS 35 por cento. A diferença na velocidade se deve à compactação de dados, ao suporte à migração de partições de tabela em paralelo e às diferentes configurações. Para obter mais informações, consulte Usar um banco de dados do Amazon Redshift como destino do AWS Database Migration Service.
O Amazon S3 é um serviço de armazenamento e recuperação. Para armazenar um objeto no Amazon S3, você carrega o arquivo que deseja armazenar em um bucket do Amazon S3. Quando você carrega um arquivo, pode definir permissões sobre o objeto e também em todos os metadados.
Migrações em larga escala
As migrações de dados em grande escala podem incluir muitos terabytes de informações e podem ser retardadas pelo desempenho da rede e pela grande quantidade de dados que precisam ser movidos. AWS Snowball Edge O Edge é um AWS serviço que você pode usar para transferir dados para a nuvem em faster-than-network alta velocidade usando um dispositivo AWS próprio. Um dispositivo AWS Snowball Edge Edge pode armazenar até 100 TB de dados. Ele usa criptografia de 256 bits e um Trusted Platform Module (TPM) padrão do setor para garantir a segurança e a integridade de seus dados. chain-of-custody AWS SCT funciona com dispositivos AWS Snowball Edge Edge.
Ao usar AWS SCT um dispositivo AWS Snowball Edge Edge, você migra seus dados em dois estágios. Primeiro, você usa AWS SCT para processar os dados localmente e depois mover esses dados para o dispositivo AWS Snowball Edge Edge. Em seguida, você envia o dispositivo para AWS usar o processo AWS Snowball Edge Edge e, em seguida, carrega AWS automaticamente os dados em um bucket do Amazon S3. Em seguida, quando os dados estiverem disponíveis no Amazon S3, você os usará AWS SCT para migrar os dados para o Amazon Redshift. Os agentes de extração de dados podem trabalhar em segundo plano enquanto AWS SCT estão fechados.
O diagrama a seguir mostra o cenário com suporte.
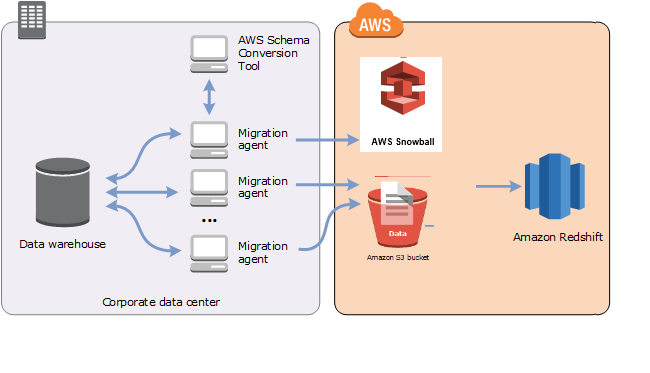
No momento, os agentes de extração de dados recebem suporte dos seguintes data warehouses de origem:
Azure Synapse Analytics
BigQuery
Banco de dados Greenplum (versão 4.3)
Microsoft SQL Server (versão 2008 e superior)
Netezza (versão 7.0.3 e superior)
Oracle (versão 10 e superior)
Snowflake (versão 3)
Teradata (versão 13 e superior)
Vertica (versão 7.2.2 e superior)
Você pode conectar os endpoints do FIPS para o Amazon Redshift se precisar estar em conformidade com os requisitos de segurança do Padrão Federal de Processamento de Informações (FIPS). Os endpoints FIPS estão disponíveis nas seguintes regiões: AWS
Região Leste dos EUA (Norte da Virgínia) (redshift-fips.us-east-1.amazonaws.com)
Região Leste dos EUA (Ohio) (redshift-fips.us-east-2.amazonaws.com)
Região Oeste dos EUA (Norte da Califórnia) (redshift-fips.us-west-1.amazonaws.com)
Região Oeste dos EUA (Oregon) (redshift-fips.us-west-2.amazonaws.com)
Use as informações nos tópicos a seguir para saber como trabalhar com os agentes de extração de dados.
Tópicos
Registrando agentes de extração com o AWS Schema Conversion Tool
Como alterar as configurações do extrator e da cópia das configurações do projeto
Criação, execução e monitoramento de uma tarefa AWS SCT de extração de dados
Exportação e importação de uma tarefa de extração de AWS SCT dados
Extração de dados usando um dispositivo AWS Snowball Edge Edge
Usando particionamento virtual com AWS Schema Conversion Tool
Melhores práticas e solução de problemas para atendentes de extração de dados
Pré-requisitos para usar os atendentes de extração de dados
Antes de trabalhar com atendentes de extração de dados, adicione as permissões necessárias para o Amazon Redshift como destino para seu usuário do Amazon Redshift. Para obter mais informações, consulte Permissões para o Amazon Redshift como destino.
Em seguida, armazene as informações do bucket do Amazon S3 e configure a confiança e o armazenamento de chaves do Secure Sockets Layer (SSL).
Configurações do Amazon S3
Os atendentes extraem os dados e, depois, os carregam para o bucket do Amazon S3. Antes de continuar, você deve fornecer as credenciais para se conectar à sua AWS conta e ao seu bucket do Amazon S3. Você armazena suas credenciais e informações do bucket em um perfil nas configurações globais do aplicativo e, em seguida, associa o perfil ao seu AWS SCT projeto. Se necessário, escolha Configurações globais para criar um novo perfil. Para obter mais informações, consulte Gerenciando perfis no AWS Schema Conversion Tool.
Para migrar dados para seu banco de dados de destino do Amazon Redshift, AWS SCT o agente de extração de dados precisa de permissão para acessar o bucket do Amazon S3 em seu nome. Para fornecer essa permissão, crie um usuário AWS Identity and Access Management (IAM) com a política a seguir.
No exemplo anterior, substitua bucket_name111122223333:user/DataExtractionAgentName
Como assumir perfis do IAM
Para segurança adicional, você pode usar funções AWS Identity and Access Management (IAM) para acessar seu bucket do Amazon S3. Para fazer isso, crie um usuário do IAM para seus atendentes de extração de dados sem nenhuma permissão. Em seguida, crie um perfil do IAM que permita o acesso ao Amazon S3 e especifique a lista de serviços e usuários que podem assumir esse perfil. Para obter mais informações, consulte Funções do IAM no Guia do usuário do IAM.
Para configurar um perfil do IAM para acessar o bucket do Amazon S3
-
Crie um novo usuário do IAM. Para credenciais do usuário, selecione o tipo de Acesso programático.
-
Configure o ambiente do host para que seu agente de extração de dados possa assumir a função que AWS SCT fornece. Certifique-se de que o usuário que você configurou na etapa anterior permita que os atendentes de extração de dados usem a cadeia de fornecedores de credenciais. Para obter mais informações, consulte Como usar credenciais no Guia do desenvolvedor do AWS SDK para Java .
-
Crie um novo perfil do IAM que tenha acesso ao seu bucket do Amazon S3.
-
Modifique a seção confiável desse perfil para confiar no usuário que você criou antes para assumir o perfil. Nos exemplos a seguir, substitua
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
Modifique a seção confiável desse perfil para confiar em
redshift.amazonaws.com.rproxy.goskope.compara assumir o perfil.{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
Anexe este perfil ao seu cluster do Amazon Redshift.
Agora, você pode executar seu atendente de extração de dados na AWS SCT.
Quando você usa a suposição do perfil do IAM, a migração de dados funciona da seguinte maneira. O atendente de extração de dados inicia e obtém as credenciais do usuário usando a cadeia de fornecedores de credenciais. Em seguida, você cria uma tarefa de migração de dados em AWS SCT, especifica a função do IAM a ser assumida pelos agentes de extração de dados e inicia a tarefa. AWS Security Token Service (AWS STS) gera credenciais temporárias para acessar o Amazon S3. O atendente de extração de dados usa essas credenciais para carregar dados para o Amazon S3.
Em seguida, AWS SCT fornece ao Amazon Redshift a função IAM. Por sua vez, o Amazon Redshift obtém novas credenciais temporárias AWS STS para acessar o Amazon S3. O Amazon Redshift usa essas credenciais para copiar dados do Amazon S3 para a tabela do Amazon Redshift.
Configurações de segurança
Os agentes de extração AWS Schema Conversion Tool e os agentes de extração podem se comunicar por meio do Secure Sockets Layer (SSL). Para habilitar a SSL, configure um armazenamento de confiança e um armazenamento de chaves.
Para configurar a comunicação segura com o agente de extração
-
Inicie AWS Schema Conversion Tool o.
-
Abra o menu Configurações e selecione Configurações globais. A caixa de diálogo Configurações globais é exibida.
-
Selecione Segurança.
-
Selecione Gerar armazenamento confiável e de chaves ou Selecionar armazenamento confiável e de chaves existente.
Caso escolha Gerar armazenamento de confiança e de chaves, você poderá especificar o nome e a senha para os armazenamentos de confiança e de chaves, e o caminho para o local dos arquivos gerados. Você usa esses arquivos em etapas posteriores.
Caso você escolha Selecionar armazenamento confiável e de chaves existente, você poderá especificar a senha e o nome de arquivo para os armazenamentos confiável e de chaves. Você usa esses arquivos em etapas posteriores.
-
Depois de especificar o armazenamento de confiança e o armazenamento de chaves, escolha OK para fechar a caixa de diálogo Configurações globais.
Como configurar o ambiente para atendentes de extração de dados
Você pode instalar vários atendentes de extração de dados em um único host. No entanto, recomendamos executar um atendente de extração de dados em um host.
Para executar seu agente de extração de dados, certifique-se de usar um host com pelo menos quatro V CPUs e 32 GB de memória. Além disso, defina a memória mínima disponível AWS SCT para pelo menos quatro GB. Para obter mais informações, consulte Como configurar memória adicional.
A configuração ideal e o número de hosts de atendentes dependem da situação específica de cada cliente. Certifique-se de considerar fatores como quantidade de dados a serem migrados, largura de banda da rede, tempo para extrair dados e assim por diante. Você pode realizar uma prova de conceito (PoC) primeiro e depois configurar seus atendentes e hosts de extração de dados de acordo com os resultados dessa PoC.
Como instalar atendentes de extração
Recomendamos que você instale vários agentes de extração em computadores individuais, separados do computador que está executando a AWS Schema Conversion Tool.
No momento, os agentes de extração têm suporte nos seguintes sistemas operacionais:
Microsoft Windows
Red Hat Enterprise Linux (RHEL) 6.0
Ubuntu Linux (versão 14.04 e posterior)
Use o seguinte procedimento para instalar agentes de extração. Repita esse procedimento para cada computador em que você deseja instalar um agente de extração.
Para instalar um agente de extração
-
Se você ainda não baixou o arquivo AWS SCT do instalador, siga as instruções em Instalando e configurando AWS Schema Conversion Tool para baixá-lo. O arquivo.zip que contém o arquivo do AWS SCT instalador também contém o arquivo instalador do agente de extração.
-
Faça download e instale a versão mais recente do Amazon Corretto 11. Para obter mais informações, consulte Downloads do Amazon Corretto 11 no Guia do usuário do Amazon Corretto 11.
-
Localize o arquivo do instalador de seu agente de extração em uma subpasta chamada agentes. Para cada sistema operacional do computador, o arquivo correto para instalar o agente de extração é mostrado a seguir.
Sistema operacional Nome do arquivo Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
Instale o atendente de extração em um computador separado, copiando o arquivo do instalador para o novo computador.
-
Execute o arquivo do instalador. Use as instruções para o seu sistema operacional, mostradas a seguir.
Sistema operacional Instruções de instalação Microsoft Windows
Clique duas vezes no arquivo para executar o instalador.
RHEL
Execute os seguintes comandos na pasta para a qual você baixou ou moveu o arquivo.
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
Execute os seguintes comandos na pasta para a qual você baixou ou moveu o arquivo.
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
Selecione Avançar, aceite o contrato de licença e depois Avançar.
-
Insira o caminho para instalar o agente AWS SCT de extração de dados e escolha Avançar.
-
Selecione Instalar para instalar seu atendente de extração de dados.
AWS SCT instala seu agente de extração de dados. Para concluir a instalação, configure seu agente de extração de dados. AWS SCT inicia automaticamente o programa de configuração. Para obter mais informações, consulte Como configurar atendentes de extração.
-
Selecione Concluir para fechar o assistente de instalação depois de configurar seu atendente de extração de dados.
Como configurar atendentes de extração
Use o seguinte procedimento para configurar agentes de extração. Repita esse procedimento em cada computador em que você tenha um agente de extração instalado.
Para configurar seu agente de extração
-
Inicie o programa de configuração:
-
No Windows, AWS SCT inicia o programa de configuração automaticamente durante a instalação de um agente de extração de dados.
Se necessário, você pode iniciar o programa de configuração manualmente. Para fazer isso, execute o arquivo
ConfigAgent.batno Windows. Você pode encontrar esse arquivo na pasta onde você instalou o atendente. -
No RHEL e no Ubuntu, execute o arquivo
sct-extractor-setup.shdo local onde você instalou o atendente.
O programa de configuração solicitará informações. Para cada solicitação, um valor padrão será exibido.
-
-
Aceite o valor padrão em cada solicitação ou insira um novo valor.
Especifique as seguintes informações:
Em Porta de escuta, digite o número da porta em que o atendente está escutando.
Em Adicionar um fornecedor de origem, digite sim e, em seguida, insira sua plataforma de data warehouse de origem.
Em driver JDBC, digite o local onde você instalou os drivers JDBC.
Em Pasta de trabalho, insira o caminho em que o agente de extração de AWS SCT dados armazenará os dados extraídos. A pasta de trabalho pode estar em um computador diferente do agente, e uma única pasta de trabalho pode ser compartilhada por vários agentes em diferentes computadores.
Em Ativar comunicação SSL, digite sim.
Em Armazenamento de chaves, insira a localização do arquivo de armazenamento de chaves.
Em Senha do armazenamento de chaves, digite a senha do armazenamento de chaves.
Em Habilitar a autenticação SSL do cliente, digite sim.
Em Armazenamento confiável, insira a localização do arquivo de armazenamento confiável.
Em Senha do armazenamento confiável, digite a senha do armazenamento confiável.
O programa de configuração atualiza o arquivo de configurações do agente de extração. O arquivo de configurações é chamado de settings.properties, e está localizado onde você instalou o agente de extração.
Veja a seguir um exemplo de arquivo de configurações.
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFFPara alterar as configurações, você pode editar o arquivo settings.properties usando um editor de texto ou executar a configuração do atendente novamente.
Como instalar e configurar atendentes de extração com atendentes de cópia dedicados
Você pode instalar atendentes de extração em uma configuração que tenha armazenamento compartilhado e um atendente de cópia dedicado. O diagrama a seguir ilustra esse cenário.
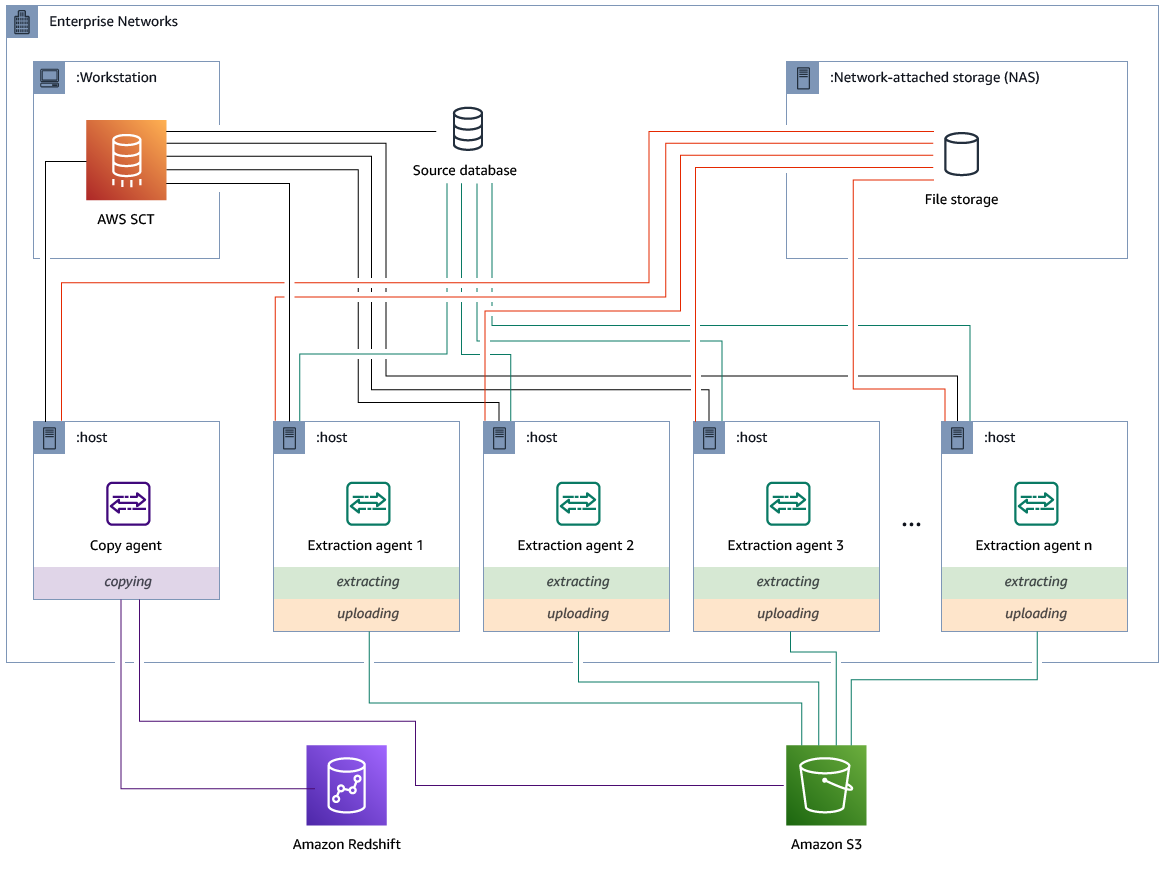
Essa configuração pode ser útil quando um servidor de banco de dados de origem suporta até 120 conexões e sua rede tem amplo armazenamento conectado. Use o procedimento a seguir para configurar atendentes de extração que possuem um atendente de cópia dedicado.
Para instalar e configurar atendentes de extração e um atendente de cópia dedicado
-
Certifique-se de que o diretório de trabalho de todos os atendentes de extração use a mesma pasta no armazenamento compartilhado.
-
Instale atendentes extratores seguindo as etapas em Como instalar atendentes de extração.
-
Configure os atendentes de extração seguindo as etapas em Como configurar atendentes de extração, mas especifique somente o driver JDBC de origem.
-
Configure um atendente de cópia dedicado seguindo as etapas emComo configurar atendentes de extração, mas especifique somente um driver JDBC do Amazon Redshift.
Como iniciar atendentes de extração
Use o seguinte procedimento para iniciar agentes de extração Repita esse procedimento em cada computador em que você tenha um agente de extração instalado.
Os agentes de extração atuam como ouvintes. Quando você inicia um agente com esse procedimento, o agente começa ouvindo para obter instruções. Você envia aos agentes instruções para extrair dados do seu data warehouse em uma seção posterior.
Para iniciar seu agente de extração
-
No computador que tem o agente de extração instalado, execute o comando a seguir para seu sistema operacional.
Sistema operacional Comando para iniciar Microsoft Windows
Clique duas vezes no arquivo de lote
StartAgent.bat.RHEL
Execute o seguinte comando no caminho para a pasta em que você instalou o agente:
sudo initctlstartsct-extractorUbuntu Linux
Execute o seguinte comando no caminho para a pasta em que você instalou o agente. Use o comando apropriado para a sua versão do Ubuntu.
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 e superior:
sudo systemctlstartsct-extractor
Para verificar o status do agente, execute o mesmo comando, mas substitua start por status.
Para interromper um agente, execute o mesmo comando, mas substitua start por stop.
Registrando agentes de extração com o AWS Schema Conversion Tool
Você gerencia seus agentes de extração usando AWS SCT. Os agentes de extração atuam como ouvintes. Quando recebem instruções AWS SCT, eles extraem dados do seu data warehouse.
Use o procedimento a seguir para registrar agentes de extração em seu AWS SCT projeto.
Para registrar um agente de extração
-
Inicie AWS Schema Conversion Tool o e abra um projeto.
-
Abra o menu Exibir e selecione Visualização de migração de dados (outros). A guia Agentes é exibida. Se você já registrou atendentes, a AWS SCT os exibirá em uma grade na parte superior da guia.
-
Escolha Registrar.
Depois de registrar um agente em um AWS SCT projeto, você não pode registrar o mesmo agente em um projeto diferente. Se você não estiver mais usando um agente em um AWS SCT projeto, você pode cancelar o registro. Em seguida, você pode registrá-lo com um projeto diferente.
-
Selecione Atendente de dados do Redshift e depois OK.
-
Insira suas informações na guia Conexão da caixa de diálogo:
-
Em Descrição, insira uma descrição do atendente.
-
Em Nome do host, digite o nome do host ou o endereço IP do computador do atendente.
-
Em Porta, digite o número da porta em que o atendente está escutando.
-
Escolha Registrar para registrar o agente em seu AWS SCT projeto.
-
-
Repita as etapas anteriores para registrar vários agentes com seu projeto da AWS SCT .
Ocultar e recuperar informações para um agente AWS SCT
Um AWS SCT agente criptografa uma quantidade significativa de informações, por exemplo, senhas para repositórios confiáveis de chaves do usuário, contas de banco de dados, AWS informações de contas e itens similares. Ele faz isso usando um arquivo especial chamado seed.dat. Por padrão, o agente cria esse arquivo na pasta de trabalho do usuário que configura o agente primeiro.
Como usuários diferentes podem configurar e executar o agente, o caminho para seed.dat é armazenado no parâmetro {extractor.private.folder} do arquivo settings.properties. Quando o agente é iniciado, ele pode usar esse caminho para localizar o arquivo seed.dat para acessar as informações do armazenamento de confiança de chaves para o banco de dados em que ele funciona.
Você pode precisar recuperar as senhas que um agente armazenou nos seguintes casos:
Se o usuário perder o
seed.datarquivo e a localização e a porta do AWS SCT agente não mudarem.Se o usuário perder o
seed.datarquivo e a localização e a porta do AWS SCT agente mudarem. Nesse caso, a alteração geralmente ocorre porque o agente foi migrado para outro host ou outra porta, e as informações no arquivoseed.datnão são mais válidas.
Nesses casos, se um agente for iniciado sem SSL, ele inicia e, em seguida, acessa o armazenamento do agente criado anteriormente. Em seguida, ele entra no estado Waiting for recovery (Aguardando recuperação).
No entanto, nesses casos, se um agente for iniciado com SSL, não será possível reiniciá-lo. Isso ocorre porque o agente não pode descriptografar as senhas para os certificados armazenados no arquivo settings.properties. Nesse tipo de inicialização, ocorre uma falha ao iniciar ao agente. Um erro semelhante ao seguinte é gravado no log: "O agente não pôde ser iniciado com o modo SSL ativado. Reconfigure o agente. Motivo: a senha para o armazenamento de chaves está incorreta."
Para corrigir isso, crie um novo agente e configure-o para usar as senhas existentes para acessar os certificados SSL. Para fazer isso, use o procedimento a seguir.
Depois de executar esse procedimento, o agente deve ser executado e ir para o estado Aguardando recuperação. AWS SCT envia automaticamente as senhas necessárias para um agente no estado Aguardando recuperação. Quando o agente tem as senhas, ele reinicia as tarefas. Nenhuma outra ação do usuário é necessária por parte da AWS SCT .
Para reconfigurar o agente e restaurar senhas para acessar certificados SSL
Instale um novo AWS SCT agente e execute a configuração.
Altere a propriedade
agent.nameno arquivoinstance.propertiespara o nome do agente para o qual o armazenamento foi criado, para que o novo agente funcione com o armazenamento de agente existente.O arquivo
instance.propertiesé armazenado na pasta privada do agente, que é nomeada usando a seguinte convenção:{.output.folder}\dmt\{hostName}_{portNumber}\Altere o nome de
{para o da pasta de saída do agente anterior.output.folder}Neste momento, ainda AWS SCT está tentando acessar o extrator antigo no host e na porta antigos. Como resultado, o extrator inacessível obtém o status FAILED. Em seguida, você pode alterar o host e a porta.
Modifique o host, a porta ou ambos para o antigo agente usando o comando Modify para redirecionar o fluxo de solicitações para o novo agente.
Quando AWS SCT consegue fazer ping no novo agente, AWS SCT recebe o status Aguardando recuperação do agente. AWS SCT em seguida, recupera automaticamente as senhas do agente.
Cada agente que funciona com o armazenamento de agente atualiza um arquivo especial chamado storage.lck localizado em {. Esse arquivo contém o ID de rede do agente e o tempo até que o armazenamento seja bloqueado. Quando o agente funciona com o armazenamento de agente, ele atualiza o arquivo output.folder}\{agentName}\storage\storage.lck e amplia a locação do armazenamento em 10 minutos a cada 5 minutos. Nenhuma outra instância pode utilizar esse armazenamento de agente até que a locação expire.
Criação de regras de migração de dados no AWS SCT
Antes de extrair seus dados com o AWS Schema Conversion Tool, você pode configurar filtros que reduzam a quantidade de dados que você extrai. Você pode criar filtros de migração de dados, usando cláusulas WHERE para reduzir os dados a serem extraídos. Por exemplo, você pode gravar uma cláusula WHERE que seleciona dados de uma única tabela.
Você pode criar filtros de migração de dados e salvá-los como parte do seu projeto. Com seu projeto aberto, use o procedimento a seguir para criar regras de migração de dados.
Para criar regras de migração de dados
-
Abra o menu Exibir e selecione Visualização de migração de dados (outros).
-
Selecione Regras de migração de dados e, em seguida, selecione Adicionar nova regra.
-
Configure sua regra de migração de dados:
-
Em Nome, insira um nome para sua regra de migração.
-
Em Onde o nome do esquema é como, digite um filtro para aplicar a esquemas. Neste filtro, uma cláusula
WHEREé avaliada usando uma cláusulaLIKE. Para escolher um esquema, insira o nome exato do esquema. Para escolher vários esquemas, use o caractere “%” como curinga para corresponder a qualquer número de caracteres no nome do esquema. -
Em nome da tabela como, digite um filtro para aplicar às tabelas. Neste filtro, uma cláusula
WHEREé avaliada usando uma cláusulaLIKE. Para escolher uma tabela, insira um nome exato. Para escolher várias tabelas, use o caractere “%” como curinga para corresponder a qualquer número de caracteres no nome da tabela. -
Em Onde cláusula, digite uma cláusula
WHEREpara filtrar os dados.
-
-
Depois de configurar seu filtro, selecione Salvar para salvar seu filtro ou Cancelar para cancelar as alterações.
-
Ao finalizar a adição, edição e exclusão dos filtros, selecione Salvar tudo para salvar todas as alterações.
Para desativar um filtro sem excluí-lo, use o ícone de alternância. Para duplicar um filtro existente, use o ícone de cópia. Para excluir um filtro existente, use o ícone de exclusão. Para salvar as alterações feitas em seus filtros, selecione Salvar tudo.
Como alterar as configurações do extrator e da cópia das configurações do projeto
Na janela Configurações do projeto AWS SCT, você pode escolher as configurações dos agentes de extração de dados e do comando Amazon RedshiftCOPY.
Para escolher essas configurações, selecione Configurações, Configurações do projeto e, em seguida, Migração de dados. Aqui, você pode editar as Configurações de extração, as Configurações do Amazon S3 e as Configurações de cópia.
Use as instruções na tabela a seguir para fornecer as informações sobre as Configurações de extração.
| Para este parâmetro | Faça o seguinte |
|---|---|
Compression format (Formato de compactação) |
Especifique o formato de compactação dos arquivos de entrada. Escolha uma das seguintes opções: GZIP BZIP2, ZSTD ou Sem compressão. |
Caractere delimitador |
Especifique o caractere ASCII que separa os campos nos arquivos de entrada. Não há suporte para caracteres não imprimíveis. |
Valor NULO como uma string |
Ative essa opção se seus dados incluírem um terminador nulo. Se essa opção estiver desativada, o comando |
Estratégia de classificação |
Use a classificação para reiniciar a extração a partir do ponto de falha. Escolha uma das seguintes estratégias de classificação: Use a classificação após a primeira falha (recomendado), Use a classificação, se possível, ou Nunca use a classificação. Para obter mais informações, consulte Classificando dados antes de migrar usando AWS SCT. |
Esquema temporário de origem |
Insira o nome do esquema no banco de dados de origem, onde o atendente de extração pode criar os objetos temporários. |
Tamanho do arquivo de saída (em MB) |
Insira o tamanho, em MB, dos arquivos carregados no Amazon S3. |
Tamanho do arquivo Snowball out (em MB) |
Insira o tamanho, em MB, dos arquivos enviados para AWS Snowball Edge. Os arquivos podem ter de 1 a 1.000 MB de tamanho. |
Usar o particionamento automático. Para Greenplum e Netezza, insira o tamanho mínimo das tabelas suportadas (em megabytes) |
Ative essa opção para usar o particionamento de tabelas e, em seguida, insira o tamanho das tabelas a serem particionadas para os bancos de dados de origem Greenplum e Netezza. Para migrações do Oracle para o Amazon Redshift, você pode manter esse campo vazio porque AWS SCT cria subtarefas para todas as tabelas particionadas. |
Extrair LOBs |
Ative essa opção para extrair objetos grandes (LOBs) do seu banco de dados de origem. LOBs incluem BLOBs, CLOBs, NCLOBs, arquivos XML e assim por diante. Para cada LOB, os atendentes de extração da AWS SCT criam um arquivo de dados. |
Pasta de bucket do Amazon S3 LOBs |
Insira o local para armazenar os agentes de AWS SCT extração LOBs. |
Aplicar RTRIM às colunas de string |
Ative essa opção para cortar um conjunto específico de caracteres do final das sequências extraídas. |
Manter os arquivos localmente após carregá-los para o Amazon S3 |
Ative essa opção para manter os arquivos em sua máquina local depois que os atendentes de extração de dados os enviarem para o Amazon S3. |
Use as instruções na tabela a seguir para fornecer as informações sobre as Configurações do Amazon S3.
| Para este parâmetro | Faça o seguinte |
|---|---|
Usar proxy |
Ative essa opção para usar um servidor proxy para fazer upload de dados para o Amazon S3. Em seguida, escolha o protocolo de transferência de dados, insira o nome do host, a porta, o nome do usuário e a senha. |
Endpoint type |
Selecione FIPS para usar o endpoint do Padrão Federal de Processamento de Informações (FIPS). Selecione VPCE para usar o endpoint da nuvem privada virtual (VPC). Em seguida, em endpoint da VPC, insira o Sistema de Nomes de Domínio (DNS) de seu endpoint da VPC. |
Manter os arquivos no Amazon S3 depois de copiar para o Amazon Redshift |
Ative essa opção para manter os arquivos extraídos no Amazon S3 depois de copiar esses arquivos para o Amazon Redshift. |
Use as instruções na tabela a seguir para fornecer as informações para Copiar configurações.
| Para este parâmetro | Faça o seguinte |
|---|---|
Contagem máxima de erros |
Insira o número de erros de carregamento. Depois que a operação atinge esse limite, os agentes de extração de AWS SCT dados encerram o processo de carregamento de dados. O valor padrão é 0, o que significa que os agentes de extração de AWS SCT dados continuam o carregamento de dados, independentemente das falhas. |
Substituir caracteres UTF-8 não válidos |
Ative essa opção para substituir caracteres UTF-8 não válidos pelo caractere especificado e continuar a operação de carregamento de dados. |
Usar espaço em branco como valor nulo |
Ative essa opção para carregar campos em branco que consistem em caracteres de espaço em branco como nulos. |
Usar vazio como valor nulo |
Ative essa opção para carregar campos vazios |
Truncar colunas |
Ative essa opção para truncar dados em colunas de acordo com a especificação do tipo de dados. |
Compactação automática |
Ative essa opção para aplicar a codificação de compactação durante uma operação de cópia. |
Atualização automática de estatísticas |
Ative essa opção para atualizar as estatísticas ao final de uma operação de cópia. |
Verificar o arquivo antes de carregar |
Ative essa opção para validar arquivos de dados antes de carregá-los no Amazon Redshift. |
Classificando dados antes de migrar usando AWS SCT
Classificar seus dados antes da migração AWS SCT oferece alguns benefícios. Se você classificar os dados primeiro, AWS SCT poderá reiniciar o agente de extração no último ponto salvo após uma falha. Além disso, se você estiver migrando dados para o Amazon Redshift e classificar os dados primeiro AWS SCT , poderá inseri-los no Amazon Redshift com mais rapidez.
Esses benefícios têm a ver com a forma como AWS SCT cria consultas de extração de dados. Em alguns casos, AWS SCT usa a função analítica DENSE_RANK nessas consultas. No entanto, o DENSE_RANK pode usar muito tempo e recursos do servidor para classificar o conjunto de dados resultante da extração. Portanto, se AWS SCT puder funcionar sem ele, funcionará.
Para classificar dados antes de migrar usando AWS SCT
Abra um AWS SCT projeto.
Abra o menu de contexto (clique com o botão direito do mouse) do objeto e, em seguida, escolha Criar tarefa local.
Selecione a guia Avançado e em Estratégia de classificação, escolha uma opção:
Nunca usar classificação: O atendente de extração não usará a função analítica DENSE_RANK e reiniciará do começo se ocorrer uma falha.
Usar a classificação, se possível: O atendente de extração usará a função DENSE_RANK se a tabela tiver uma chave primária ou uma restrição exclusiva.
Usar a classificação após a primeira falha (recomendado): Primeiro o atendente de extração tenta obter os dados sem usar a função DENSE_RANK. Se a primeira tentativa falhar, o agente de extração recriará a consulta usando a função DENSE_RANK e preservará sua localização em caso de falha.
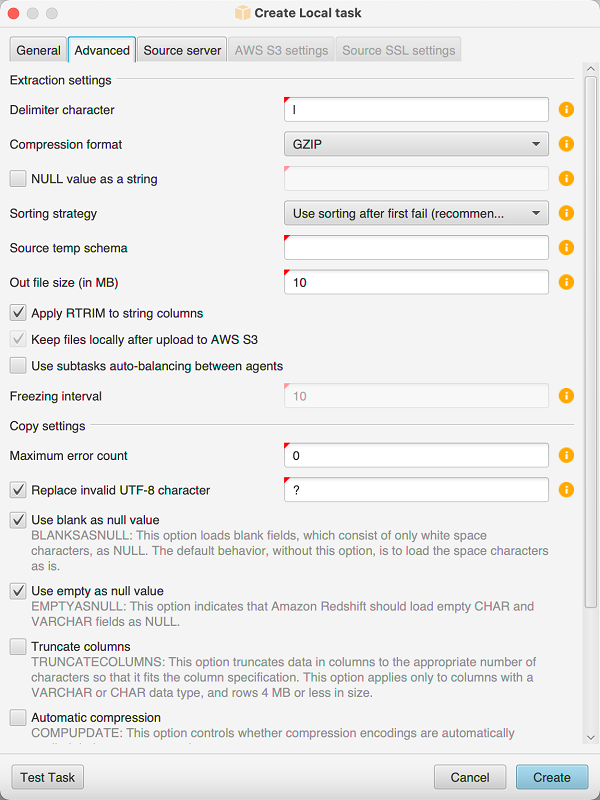
Defina parâmetros adicionais como descrito abaixo e, em seguida, escolha Criar para criar a tarefa de extração de dados.
Criação, execução e monitoramento de uma tarefa AWS SCT de extração de dados
Use os procedimentos a seguir para criar, executar e monitorar tarefas de extração de dados.
Para atribuir tarefas a agentes e migrar dados
-
No AWS Schema Conversion Tool, depois de converter seu esquema, escolha uma ou mais tabelas no painel esquerdo do seu projeto.
Você pode escolher todas as tabelas, mas não recomendamos isso por motivos de desempenho. Recomendamos que você crie várias tarefas para várias tabelas com base no tamanho das tabelas do seu data warehouse.
-
Abra o menu de contexto (clique com o botão direito do mouse) de cada tabela e selecione Criar tarefa. A caixa de diálogo Criar tarefa local é aberta.
-
Em Nome da tarefa, digite um nome para a tarefa.
-
Em Modo de migração, escolha uma das seguintes opções:
-
Extrair somente: Extraia os dados e salve-os em suas pastas de trabalho locais.
-
Extrair e carregar: Extraia seus dados e carregue-os para o Amazon S3.
-
Extrair, carregar e copiar: Extraia seus dados, carregue-os para o Amazon S3 e copie-os para seu data warehouse do Amazon Redshift.
-
-
Em Tipo de criptografia, selecione uma das seguintes opções:
-
NENHUMA: Desative a criptografia de dados em todo o processo de migração de dados.
-
CSE_SK — Use criptografia do lado do cliente com uma chave simétrica para migrar dados. AWS SCT gera chaves de criptografia automaticamente e as transmite para agentes de extração de dados usando Secure Sockets Layer (SSL). AWS SCT não criptografa objetos grandes (LOBs) durante a migração de dados.
-
-
Escolha LOBsExtrair para extrair objetos grandes. Se você não precisar extrair objetos grandes, poderá desmarcar a caixa de seleção. Isso reduz a quantidade de dados extraídos.
-
Para ver informações detalhadas sobre uma tarefa, selecione Habilitar log de tarefas. Você pode usar o log de tarefas para depurar problemas.
Se você habilitar o log de tarefas, escolha o nível de detalhes que você deseja ver. Os níveis são os seguintes, com cada nível incluindo todas as mensagens do nível anterior:
ERROR: A menor quantidade de detalhes.WARNINGINFODEBUGTRACE: A maior quantidade de detalhes.
-
Para exportar dados de BigQuery, AWS SCT use a pasta bucket do Google Cloud Storage. Nessa pasta, os atendentes de extração de dados armazenam seus dados de origem.
Para inserir o caminho para sua pasta de bucket do Google Cloud Storage, selecione Avançado. Para a pasta de bucket do Google CS, insira o nome do bucket e o nome da pasta.
-
Para assumir uma função para o usuário do seu atendente de extração de dados, escolha as configurações do Amazon S3. Quanto ao perfil do IAM, insira o nome do perfil a ser usado. Em Região, escolha o Região da AWS para essa função.
-
Selecione Testar tarefa para verificar se você pode se conectar à sua pasta de trabalho, bucket do Amazon S3 e data warehouse do Amazon Redshift. A verificação depende do modo de migração que você escolheu.
-
Escolha Criar para criar a tarefa.
-
Repita as etapas anteriores para criar tarefas para todos os dados que você deseja migrar.
Para executar e monitorar tarefas
-
Em Visualização, selecione Visualização de migração de dados. A guia Agentes é exibida.
-
Escolha a guia Tasks (Tarefas). Suas tarefas são exibidas na grade na parte superior, como mostrado a seguir. Você pode ver o status de uma tarefa na grade superior, e o status de suas subtarefas na grade inferior.
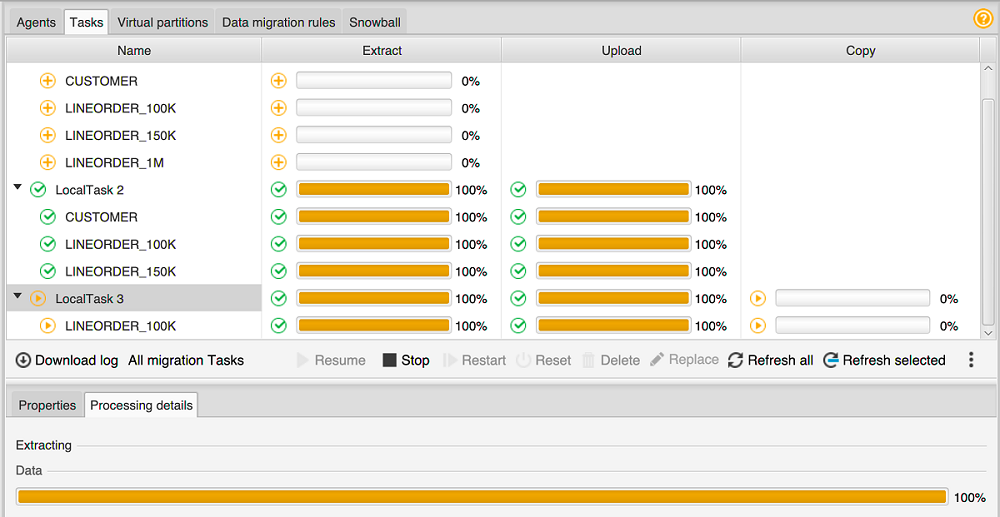
-
Escolha uma tarefa na grade superior e expanda-a. Dependendo do modo de migração que foi escolhido, você vê a tarefa dividida em Extrair, Fazer upload e Copiar.
-
Escolha Iniciar para iniciar uma tarefa. Você pode monitorar o status de suas tarefas ao mesmo tempo em que elas estão ativas. As subtarefas são executadas em paralelo. Extrair, fazer upload e copiar também funcionam em paralelo.
-
Se você habilitou o registro em log quando configurou a tarefa, será possível visualizar o log:
-
Selecione Fazer download do log. É exibida uma mensagem com o nome da pasta que contém o arquivo de log. Ignore a mensagem.
-
É exibido um link na guia Detalhes da tarefa. Escolha o link para abrir a pasta que contém o arquivo de log.
-
Você pode fechar AWS SCT e seus agentes e tarefas continuarão funcionando. Você pode reabrir AWS SCT mais tarde para verificar o status de suas tarefas e visualizar os registros de tarefas.
Você pode salvar tarefas de extração de dados em seu disco local e restaurá-las no mesmo projeto ou em outro projeto usando exportação e importação. Para exportar uma tarefa, verifique se você tem pelo menos uma tarefa de extração criada em um projeto. Você pode importar uma única tarefa de extração ou todas as tarefas criadas no projeto.
Ao exportar uma tarefa de extração, AWS SCT cria um .xml arquivo separado para essa tarefa. O arquivo .xml armazena as informações de metadados dessa tarefa, como propriedades, descrição e subtarefas da tarefa. O arquivo .xml não contém informações sobre o processamento de uma tarefa de extração. Informações como as seguintes são recriadas quando a tarefa é importada:
-
Progresso da tarefa
-
Estados da subtarefa e do estágio
-
Distribuição dos atendentes extratores por subtarefas e estágios
-
Tarefa e subtarefa IDs
-
Task name
Exportação e importação de uma tarefa de extração de AWS SCT dados
Você pode salvar rapidamente uma tarefa existente de um projeto e restaurá-la em outro projeto (ou no mesmo projeto) usando AWS SCT exportação e importação. Use o procedimento a seguir para exportar e importar tarefas de extração de dados.
Para exportar e importar uma tarefa de extração de dados
-
Em Visualização, selecione Visualização de migração de dados. A guia Agentes é exibida.
-
Escolha a guia Tasks (Tarefas). Suas tarefas estão listadas na grade que é exibida.
-
Selecione os três pontos alinhados verticalmente (ícone de reticências) localizados no canto inferior direito abaixo da lista de tarefas.
-
Selecione Exportar tarefa no menu pop-up.
-
Escolha a pasta onde você deseja AWS SCT colocar o
.xmlarquivo de exportação da tarefa.AWS SCT cria o arquivo de exportação da tarefa com um formato de nome de arquivo de
TASK-DESCRIPTION_TASK-ID.xml -
Selecione os três pontos alinhados verticalmente (ícone de reticências) no canto inferior direito abaixo da lista de tarefas.
-
Selecione Importar tarefa no menu pop-up.
Você pode importar uma tarefa de extração para um projeto conectado ao banco de dados de origem, e o projeto tem pelo menos um atendente de extração registrado ativo.
-
Selecione o arquivo
.xmlpara a tarefa de extração que você exportou.AWS SCT obtém os parâmetros da tarefa de extração do arquivo, cria a tarefa e adiciona a tarefa aos agentes de extração.
-
Repita essas etapas para exportar e importar tarefas adicionais de extração de dados.
Ao final desse processo, sua exportação e importação estão concluídas e suas tarefas de extração de dados estão prontas para uso.
Extração de dados usando um dispositivo AWS Snowball Edge Edge
O processo de uso AWS SCT do AWS Snowball Edge Edge tem várias etapas. A migração envolve uma tarefa local, na qual AWS SCT usa um agente de extração de dados para mover os dados para o dispositivo AWS Snowball Edge Edge e, em seguida, uma ação intermediária em que AWS copia os dados do dispositivo AWS Snowball Edge Edge para um bucket do Amazon S3. O processo termina de AWS SCT carregar os dados do bucket do Amazon S3 para o Amazon Redshift.
As seções a seguir a essa visão geral fornecem um step-by-step guia para cada uma dessas tarefas. O procedimento pressupõe que você tenha AWS SCT instalado, configurado e registrado um agente de extração de dados em uma máquina dedicada.
Execute as etapas a seguir para migrar dados de um armazenamento de dados local para um armazenamento de AWS dados usando o AWS Snowball Edge Edge.
Crie uma tarefa AWS Snowball Edge do Edge usando o AWS Snowball Edge console.
Desbloqueie o dispositivo AWS Snowball Edge Edge usando a máquina Linux dedicada local.
Crie um novo projeto em AWS SCT.
Instale, configure e execute seus atendentes de extração de dados.
Crie e defina permissões para o bucket do Amazon S3 usar.
Importe um AWS Snowball Edge trabalho para o seu AWS SCT projeto.
Registre seu atendente de extração de dados na AWS SCT.
Crie uma tarefa local em AWS SCT.
Execute e monitore a tarefa de migração de dados na AWS SCT.
Step-by-step procedimentos para migrar dados usando um AWS SCT Edge AWS Snowball Edge
As seções a seguir apresentam informações detalhadas sobre as etapas de migração.
Etapa 1: criar uma tarefa AWS Snowball Edge Edge
Crie um AWS Snowball Edge trabalho seguindo as etapas descritas na seção Criando um trabalho de AWS Snowball Edge borda no Guia do desenvolvedor do AWS Snowball Edge Edge.
Etapa 2: desbloquear o dispositivo AWS Snowball Edge Edge
Execute os comandos que desbloqueiam e fornecem credenciais para o dispositivo Snowball Edge Edge a partir da máquina em que você instalou AWS DMS o agente. Ao executar esses comandos, você pode ter certeza de que a chamada do AWS DMS agente se conecta ao dispositivo AWS Snowball Edge Edge. Para obter mais informações sobre como desbloquear o dispositivo AWS Snowball Edge Edge, consulte Desbloquear o Snowball Edge Edge.
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
Etapa 3: criar um novo AWS SCT projeto
Em seguida, crie um novo AWS SCT projeto.
Para criar um novo projeto no AWS SCT
-
Inicie AWS Schema Conversion Tool o. No menu Arquivo, selecione Novo projeto. A caixa de diálogo Novo projeto é exibida.
-
Digite um nome para o projeto, que é armazenado localmente no computador.
-
Digite o local do arquivo do projeto local.
-
Escolha OK para criar seu AWS SCT projeto.
-
Escolha Adicionar fonte para adicionar um novo banco de dados de origem ao seu AWS SCT projeto.
-
Escolha Adicionar destino para adicionar uma nova plataforma de destino ao seu AWS SCT projeto.
-
Escolha o esquema do banco de dados de origem no painel esquerdo.
-
No painel direito, especifique a plataforma de banco de dados de destino para o esquema de origem selecionado.
-
Selecione Criar mapeamento. Esse botão fica ativo depois que você escolhe o esquema do banco de dados de origem e a plataforma do banco de dados de destino.
Etapa 4: instalar, configurar e executar seu atendente de extração de dados
AWS SCT usa um agente de extração de dados para migrar dados para o Amazon Redshift. O arquivo.zip que você baixou para instalar AWS SCT inclui o arquivo instalador do agente de extração. Você pode instalar o atendente de extração de dados no Windows, Red Hat Enterprise Linux ou Ubuntu. Para obter mais informações, consulte Como instalar atendentes de extração.
Para configurar seu atendente de extração de dados, insira seus mecanismos de banco de dados de origem e destino. Além disso, certifique-se de ter baixado os drivers JDBC para seus bancos de dados de origem e destino no computador em que você executa o atendente de extração de dados. Os atendentes de extração de dados usam esses drivers para se conectar aos bancos de dados de origem e de destino. Para obter mais informações, consulte Instalando drivers JDBC para AWS Schema Conversion Tool.
No Windows, o instalador do atendente de extração de dados inicia o assistente de configuração na janela do prompt de comando. No Linux, execute o arquivo sct-extractor-setup.sh do local onde você instalou o atendente.
Etapa 5: Configurar AWS SCT para acessar o bucket do Amazon S3
Para obter informações sobre como configurar um bucket do Amazon S3, consulte Visão geral dos buckets no Guia do usuário do Amazon Simple Storage Service.
Etapa 6: importar um AWS Snowball Edge trabalho para seu AWS SCT projeto
Para conectar seu AWS SCT projeto ao seu dispositivo AWS Snowball Edge Edge, importe seu AWS Snowball Edge trabalho.
Para importar seu AWS Snowball Edge trabalho
-
Abra o menu Configurações e selecione Configurações globais. A caixa de diálogo Configurações globais é exibida.
-
Selecione perfis de serviço da AWS e, em seguida, selecione Importar trabalho.
Escolha seu AWS Snowball Edge emprego.
-
Insira seu IP do AWS Snowball Edge . Para obter mais informações, consulte Como alterar seu Endereço IP no Guia do usuário do AWS Snowball Edge .
-
Entre no seu AWS Snowball Edge porto. Para obter mais informações, consulte Portas necessárias para usar AWS serviços em um dispositivo AWS Snowball Edge Edge no Guia do desenvolvedor do AWS Snowball Edge Edge.
-
Insira sua chave de acesso do AWS Snowball Edge e a chave secreta do AWS Snowball Edge . Para obter mais informações, consulte Autorização e controle de acesso no AWS Snowball Edge no Guia do usuário do AWS Snowball Edge .
Escolha Apply e, em seguida, escolha OK.
Etapa 7: registrar um agente de extração de dados no AWS SCT
Nesta seção, você registra o atendente de extração de dados na AWS SCT.
Para registrar um atendente de extração de dados
-
Abra o menu Exibir, selecione Visualização de migração de dados (outros) e depois selecione Registrar.
-
Em Descrição, insira um nome para seu atendente de extração de dados.
-
Em Nome do host, insira o endereço IP do computador em que você executa o atendente de extração de dados.
-
Em Porta, insira a porta de escuta que você configurou.
-
Escolha Registrar.
Etapa 8: como criar uma tarefa local
Em seguida, você cria a tarefa de migração. A tarefa inclui duas subtarefas. Uma subtarefa migra os dados do banco de dados de origem para o equipamento AWS Snowball Edge Edge. A outra subtarefa leva os dados que o dispositivo carrega em um bucket do Amazon S3 e os migra para o banco de dados de destino.
Para criar uma tarefa de migração
-
No menu Exibir e selecione Visualização de migração de dados (outros).
No painel esquerdo que exibe o schema do banco de dados de origem, escolha um objeto de schema para migrar. Abra o menu de contexto (clique com o botão direito do mouse) do objeto e, em seguida, escolha Criar tarefa local.
-
Em Nome da tarefa, insira um nome descritivo para a tarefa de migração de dados.
-
Para o Modo de migração, escolha Extrair, carregar e copiar.
-
Escolha Configurações do Amazon S3.
-
Selecione Usar Snowball Edge.
-
Insira pastas e subpastas em seu bucket do Amazon S3 onde o atendente de extração de dados pode armazenar dados.
-
Escolha Criar para criar a tarefa.
Etapa 9: Executar e monitorar a tarefa de migração de dados no AWS SCT
Para iniciar sua tarefa de migração de dados, selecione Iniciar. Certifique-se de estabelecer conexões com o banco de dados de origem, o bucket do Amazon S3, o AWS Snowball Edge dispositivo, bem como a conexão com o banco de dados de destino em. AWS
Você pode monitorar e gerenciar as tarefas de migração de dados e suas subtarefas na guia Tarefas. Você pode ver o progresso da migração de dados, bem como pausar ou reiniciar suas tarefas de migração de dados.
Saída da tarefa de extração de dados
Após a conclusão de suas tarefas de migração, seus dados estão prontos. Use as informações seguintes para determinar como proceder com base no modo de migração escolhido e a localização de seus dados.
| Modo de migração | Local dos dados |
|---|---|
|
Extrair, fazer upload e copiar |
Os dados já estão em seu data warehouse do Amazon Redshift. Você pode verificar se os dados estão lá e começar a usá-los. Para obter mais informações, consulte Conexão com clusters a partir de ferramentas do cliente e de código. |
|
Extrair e fazer upload |
Os atendentes de extração salvaram os dados como arquivos em seu bucket do Amazon S3. Você pode usar o comando COPIAR do Amazon Redshift para carregar dados no Amazon Redshift. Para obter mais informações, consulte Como carregar dados do Amazon S3 na documentação do Amazon Redshift. Há várias pastas em seu bucket do Amazon S3 correspondentes às tarefas de extração que você configurou. Quando você carregar os dados para o Amazon Redshift, especifique o nome do arquivo de manifesto criado por cada tarefa. O arquivo de manifesto é exibido na pasta da tarefa no seu bucket do Amazon S3, conforme mostrado a seguir. 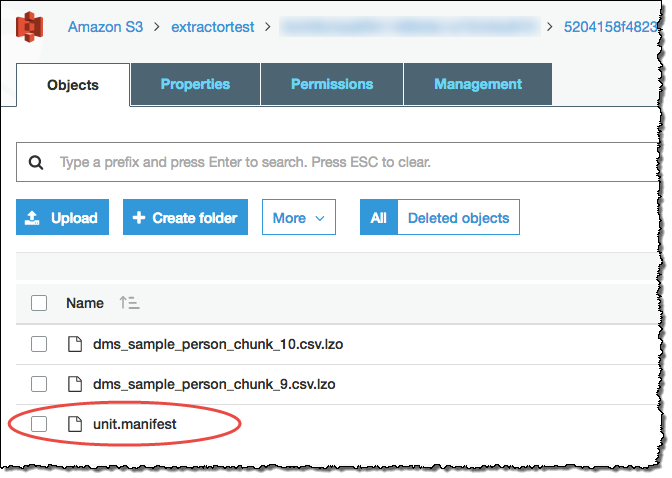
|
|
Extrair somente |
Os agentes de extração salvaram os dados como arquivos em sua pasta de trabalho. Copie manualmente os dados para o seu bucket do Amazon S3 e, em seguida, prossiga com as instruções para Extrair e carregar. |
Usando particionamento virtual com AWS Schema Conversion Tool
Muitas vezes, você pode gerenciar melhor tabelas grandes não particionadas criando subtarefas que criam partições virtuais dos dados de tabela usando regras de filtragem. Em AWS SCT, você pode criar partições virtuais para seus dados migrados. Há três tipos de partição que funcionam com tipos de dados específicos:
O tipo de partição RANGE funciona com tipos de dados numéricos e de data e hora.
O tipo de partição LIST funciona com tipos de dados numéricos, de caracteres e de data e hora.
O tipo de partição DATE AUTO SPLIT funciona com tipos de dados numéricos, de data e hora.
AWS SCT valida os valores fornecidos para criar uma partição. Por exemplo, se você tentar particionar uma coluna com o tipo de dados NUMERIC, mas fornecer valores de um tipo de dados diferente, AWS SCT gerará um erro.
Além disso, se você estiver usando AWS SCT para migrar dados para o Amazon Redshift, você pode usar o particionamento nativo para gerenciar a migração de tabelas grandes. Para obter mais informações, consulte Como usar o particionamento nativo.
Limites ao criar um particionamento virtual
Estas são as limitações para a criar uma partição virtual:
Você pode usar o particionamento virtual apenas para tabelas não particionadas.
Você pode usar o particionamento virtual apenas na visualização de migração de dados.
Você não pode usar a opção UNION ALL VIEW com particionamento virtual.
Tipo de Partição RANGE
O tipo de partição RANGE particiona dados com base em um intervalo de valores de coluna para tipos de dados numéricos e de data e hora. Esse tipo de partição cria uma cláusula WHERE, e você fornece o intervalo de valores para cada partição. Para especificas uma lista de valores para a coluna particionada, use a caixa Valores. Você pode carregar informações de valor usando um arquivo .csv.
O tipo de partição RANGE cria partições padrão nas duas extremidades dos valores da partição. Essas partições padrão capturam quaisquer dados menores ou maiores que os valores de partição especificados.
Por exemplo, você pode criar várias partições com base em um intervalo de valores fornecido. No exemplo a seguir, os valores de particionamento para LO_TAX são especificados para criar várias partições.
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
Para criar uma partição virtual RANGE
Aberto AWS SCT.
Selecione o modo Visualização de migração de dados (outros).
Escolha a tabela na qual você deseja configurar o particionamento virtual. Abra o menu de contexto (clique com o botão direito do mouse) da tabela e selecione Adicionar particionamento virtual.
Na caixa de diálogo Adicionar particionamento virtual, insira as informações conforme a seguir.
Opção Ação Tipo de partição
Escolha RANGE. A caixa de diálogo da interface do usuário muda de acordo com tipo de partição escolhida.
Nome da coluna
Escolha a coluna que você deseja particionar.
Tipo de coluna
Escolha o tipo de dados para os valores na coluna.
Valores
Adicione novos valores digitando cada valor na caixa Novo valor e, em seguida, escolhendo o sinal de adição para acrescentar o valor.
Carregar do arquivo
(Opcional) Digite o nome de um arquivo .csv que contém os valores de partição.
-
Escolha OK.
Tipo de partição LIST
O tipo de partição LIST particiona dados com base nos valores de coluna para tipos de dados numéricos, de caractere e de data e hora. Esse tipo de partição cria uma cláusula WHERE, e você fornece os valores para cada partição. Para especificas uma lista de valores para a coluna particionada, use a caixa Valores. Você pode carregar informações de valor usando um arquivo .csv.
Por exemplo, você pode criar várias partições com base em um valor fornecido. No exemplo a seguir, os valores de particionamento para LO_ORDERKEY são especificados para criar várias partições.
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
Você também pode criar uma partição padrão para valores não incluídos nas partições especificadas.
Você pode usar o tipo de partição LIST para filtrar os dados de origem se quiser excluir valores específicos da migração. Por exemplo, suponha que você queira omitir as linhas com LO_ORDERKEY = 4. Nesse caso, não inclua o valor 4 na lista de valores de partição e certifique-se de que a opção Incluir outros valores não esteja selecionada.
Para criar uma partição virtual LIST
Aberto AWS SCT.
Selecione o modo Visualização de migração de dados (outros).
Escolha a tabela na qual você deseja configurar o particionamento virtual. Abra o menu de contexto (clique com o botão direito do mouse) da tabela e selecione Adicionar particionamento virtual.
Na caixa de diálogo Adicionar particionamento virtual, insira as informações conforme a seguir.
Opção Ação Tipo de partição
Selecione LIST. A caixa de diálogo da interface do usuário muda de acordo com tipo de partição escolhida.
Nome da coluna
Escolha a coluna que você deseja particionar.
Novo valor
Digite aqui um valor para adicioná-lo ao conjunto de valores de particionamento.
Incluir outros valores
Escolha essa opção para criar uma partição padrão em que todos os valores que não estiverem de acordo com critérios de particionamento são armazenados.
Carregar do arquivo
(Opcional) Digite o nome de um arquivo .csv que contém os valores de partição.
Escolha OK.
Tipo de partição DATE AUTO SPLIT
O tipo de partição DATE AUTO SPLIT é uma forma automatizada de gerar partições RANGE. Com DATA AUTO SPLIT, você informa AWS SCT o atributo de particionamento, onde começar e terminar e o tamanho do intervalo entre os valores. Em seguida, a AWS SCT calcula os valores da partição automaticamente.
O DATA AUTO SPLIT automatiza grande parte do trabalho envolvido na criação de partições de intervalo. A compensação entre o uso dessa técnica e o particionamento de intervalos é quanto controle você precisa sobre os limites da partição. O processo de divisão automática sempre cria intervalos de tamanhos iguais (uniformes). O particionamento de intervalo permite que você varie o tamanho de cada intervalo conforme necessário para sua distribuição de dados específica. Por exemplo, você pode usar diariamente, semanalmente, quinzenalmente, mensalmente e assim por diante.
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
Para criar uma partição virtual DATE AUTO SPLIT
Aberto AWS SCT.
Selecione o modo Visualização de migração de dados (outros).
Escolha a tabela na qual você deseja configurar o particionamento virtual. Abra o menu de contexto (clique com o botão direito do mouse) da tabela e selecione Adicionar particionamento virtual.
Na caixa de diálogo Adicionar particionamento virtual, insira as informações conforme a seguir.
Opção Ação Tipo de partição
Escolha DATE AUTO SPLIT. A caixa de diálogo da interface do usuário muda de acordo com tipo de partição escolhida.
Nome da coluna
Escolha a coluna que você deseja particionar.
Data de início
Digite uma data de início.
Data de término
Digite uma data de término.
Interval
Digite a unidade de intervalo e escolha o valor para essa unidade.
Escolha OK.
Como usar o particionamento nativo
Para acelerar a migração de dados, seus agentes de extração de dados podem usar partições nativas de tabelas no servidor de data warehouse de origem. AWS SCT oferece suporte ao particionamento nativo para migrações do Greenplum, Netezza e Oracle para o Amazon Redshift.
Por exemplo, depois de criar um projeto, você pode coletar estatísticas sobre um esquema e analisar o tamanho das tabelas selecionadas para migração. Para tabelas que excedem o tamanho especificado, AWS SCT aciona o mecanismo de particionamento nativo.
Para usar o particionamento nativo
-
Abra AWS SCT e escolha Novo projeto para Arquivo. A caixa de diálogo Novo projeto é exibida.
-
Crie um novo projeto, adicione seus servidores de origem e de destino e crie regras de mapeamento. Para obter mais informações, consulte Iniciando e gerenciando projetos em AWS SCT.
-
Escolha Exibir e, em seguida, Visualização principal.
-
Em Configurações do projeto, selecione a guia Migração de dados. Selecione Usar o particionamento automático. Para bancos de dados de origem Greenplum e Netezza, insira o tamanho mínimo das tabelas suportadas em megabytes (por exemplo, 100). A AWS SCT cria automaticamente subtarefas de migração separadas para cada partição nativa que não está vazia. Para migrações do Oracle para o Amazon Redshift, AWS SCT cria subtarefas para todas as tabelas particionadas.
-
No painel esquerdo que exibe o esquema do banco de dados de origem, escolha um esquema. Abra o menu de contexto (clique com o botão direito do mouse) do objeto e escolha Coletar estatísticas. Quanto à migração de dados da Oracle para o Amazon Redshift, você pode ignorar esta etapa.
-
Selecione todas as tabelas para migrar.
-
Registre o número necessário de atendentes. Para obter mais informações, consulte Registrando agentes de extração com o AWS Schema Conversion Tool.
-
Crie uma tarefa de extração de dados para as tabelas selecionadas. Para obter mais informações, consulte Criação, execução e monitoramento de uma tarefa AWS SCT de extração de dados.
Verifique se tabelas grandes estão divididas em subtarefas e se cada subtarefa corresponde ao conjunto de dados que apresenta uma parte da tabela localizada em uma fatia em seu data warehouse de origem.
-
Inicie e monitore o processo de migração até que AWS SCT os agentes de extração de dados concluam a migração dos dados de suas tabelas de origem.
Migração LOBs para o Amazon Redshift
O Amazon Redshift não oferece suporte ao armazenamento de objetos binários grandes ()LOBs. No entanto, se você precisar migrar um ou mais LOBs para o Amazon Redshift AWS SCT , poderá realizar a migração. Para fazer isso, AWS SCT usa um bucket do Amazon S3 para armazenar LOBs e grava a URL do bucket do Amazon S3 nos dados migrados armazenados no Amazon Redshift.
Para migrar LOBs para o Amazon Redshift
Abra um AWS SCT projeto.
Conecte-se aos bancos de dados de origem e de destino. Atualize os metadados do banco de dados de destino e certifique-se de que as tabelas convertidas existam lá.
Em Ações, selecione Criar tarefa local.
-
Em Modo de migração, escolha uma das seguintes opções:
-
Extrair e carregar para extrair seus dados e carregá-los para o Amazon S3.
-
Extrair, carregar e copiar para extrair seus dados, carregá-los para o Amazon S3 e copiá-los para seu data warehouse do Amazon Redshift.
-
Escolha Configurações do Amazon S3.
Para a LOBs pasta de bucket do Amazon S3, insira o nome da pasta em um bucket do Amazon S3 onde você deseja armazená-la. LOBs
Se você usa perfil AWS de serviço, esse campo é opcional. AWS SCT pode usar as configurações padrão do seu perfil. Para usar outro bucket do Amazon S3, insira o caminho aqui.
-
Ative essa opção Usar proxy para usar um servidor proxy para carregar os dados para o Amazon S3. Em seguida, escolha o protocolo de transferência de dados, insira o nome do host, a porta, o nome do usuário e a senha.
-
Para o Tipo de endpoint, selecione FIPS para usar o endpoint do Padrão Federal de Processamento de Informações (FIPS). Selecione VPCE para usar o endpoint da nuvem privada virtual (VPC). Em seguida, em endpoint da VPC, insira o Sistema de Nomes de Domínio (DNS) de seu endpoint da VPC.
-
Ative a opção Manter arquivos no Amazon S3 após copiar para o Amazon Redshift para manter os arquivos extraídos no Amazon S3 depois de copiar esses arquivos para o Amazon Redshift.
Escolha Criar para criar a tarefa.
Melhores práticas e solução de problemas para atendentes de extração de dados
Veja a seguir algumas sugestões de práticas recomendadas e de solução de problemas para o uso de agentes de extração.
| Problema | Sugestões de solução de problemas |
|---|---|
|
O desempenho está lento |
Para melhorar o desempenho, recomendamos o seguinte:
|
|
Atrasos de contenção |
Evite ter muitos agentes acessando seu data warehouse ao mesmo tempo. |
|
Um agente é desativado temporariamente |
Se um agente estiver desativado, o status de cada uma de suas tarefas aparece como falha na AWS SCT. Se você esperar, em alguns casos, o agente pode se recuperar. Neste caso, o status de suas tarefas é atualizado na AWS SCT. |
|
Um agente é desativado permanentemente |
Se o computador que executa um agente for desativado permanentemente, e se o agente estiver executando uma tarefa, você poderá substituir um novo agente para continuar a tarefa. Você pode substituir um novo agente somente se a pasta de trabalho do agente original não estava no mesmo computador que o agente original. Para substituir um novo agente, faça o seguinte:
|
