As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Resolvedores
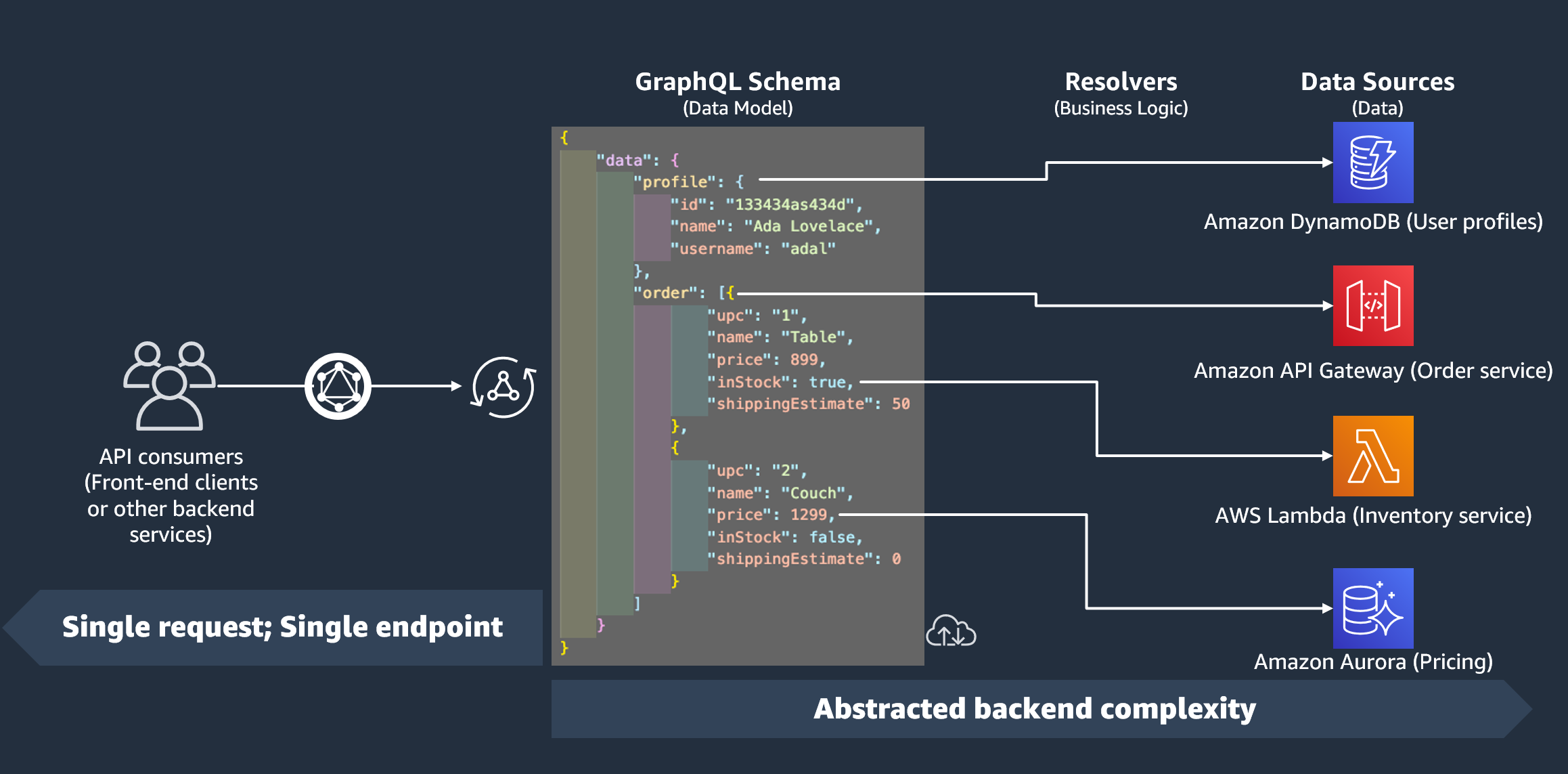
Nas seções anteriores, você aprendeu sobre os componentes do esquema e da fonte de dados. Agora, precisamos abordar como o esquema e as fontes de dados interagem. Tudo começa com o resolvedor.
Um resolvedor é uma unidade de código que controla como os dados desse campo serão resolvidos quando uma solicitação for feita ao serviço. Os resolvedores são anexados a campos específicos dentro dos seus tipos em seu esquema. Eles costumam ser usados para implementar as operações de mudança de estado para suas operações de campo de consulta, mutação e assinatura. O resolvedor processará a solicitação de um cliente e retornará o resultado, que pode ser um grupo de tipos de saída, como objetos ou escalares:
Runtime do resolvedor
Em AWS AppSync, você deve primeiro especificar um tempo de execução para seu resolvedor. Um runtime do resolvedor indica o ambiente no qual um resolvedor é executado. Ele também determina o idioma em que seus resolvedores serão escritos. AWS AppSync atualmente suporta APPSYNC_JS JavaScript e Velocity Template Language (VTL). Consulte os recursos JavaScript de tempo de execução para resolvedores e funções JavaScript ou a referência do utilitário de modelo de mapeamento Resolver para VTL.
Estrutura do resolvedor
Em termos de código, os resolvedores podem ser estruturados de duas maneiras. Existem resolvedores de unidades e de pipeline.
Resolvedores de unidade
Um resolvedor de unidade é composto de código que define um único manipulador de solicitação e resposta que é executado em uma fonte de dados. O manipulador da solicitação usa um objeto de contexto como argumento e retorna a payload da solicitação usada para chamar sua fonte de dados. O manipulador de respostas recebe uma payload da fonte de dados com o resultado da solicitação executada. O manipulador de respostas transforma a payload em uma resposta do GraphQL para resolver o campo do GraphQL.

Resolvedores de pipeline
Ao implementar resolvedores, eles seguem uma estrutura geral:
-
Etapa Anterior: quando uma solicitação é feita pelo cliente, os resolvedores dos campos do esquema que estão sendo usados (normalmente consultas, mutações e assinaturas) recebem os dados da solicitação. O resolvedor começará a processar os dados da solicitação com um manipulador de etapas anteriores, o que permite que algumas operações de pré-processamento sejam executadas antes que os dados passem pelo resolvedor.
-
Função(ões): Após a execução da etapa anterior, a solicitação é passada para a lista de funções. A primeira função na lista será executada na fonte de dados. Uma função é um subconjunto do código do resolvedor contendo seu próprio manipulador de solicitações e respostas. Um manipulador de solicitações pegará os dados da solicitação e executará operações na fonte de dados. O manipulador de respostas processará a resposta da fonte de dados antes de passá-la de volta para a lista. Se houver mais de uma função, os dados da solicitação serão enviados para a próxima função a ser executada na lista. As funções na lista serão executadas na ordem definida pelo desenvolvedor. Depois que todas as funções forem executadas, o resultado final será passado para a etapa posterior.
-
Etapa Posterior: a etapa Posterior é uma função do manipulador que permite realizar algumas operações finais na resposta da função final antes de passá-la para a resposta do GraphQL.

Estrutura do manipulador do resolvedor
Os manipuladores são normalmente funções chamadas Request e Response:
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
Em um resolvedor de unidades, haverá apenas um conjunto dessas funções. Em um resolvedor de pipeline, haverá um conjunto dessas etapas para a etapa Anterior e etapa Posterior e um conjunto adicional por função. Para visualizar esse caso, vamos analisar um tipo Query simples:
type Query { helloWorld: String! }
Essa é uma consulta simples com um campo chamado helloWorld do tipo String. Vamos supor que sempre queremos que esse campo retorne a string “Hello World”. Para implementar esse comportamento, precisamos adicionar o resolvedor a esse campo. Em um resolvedor de unidades, poderíamos adicionar algo assim:
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
A request pode ser deixada em branco porque não estamos solicitando ou processando dados. Também podemos supor que nossa fonte de dados seja None, indicando que esse código não precisa realizar nenhuma invocação. A resposta simplesmente retorna “Hello World”. Para testar esse resolvedor, precisamos fazer uma solicitação usando o tipo de consulta:
query helloWorldTest { helloWorld }
Essa é uma consulta chamada helloWorldTest que retorna o campo helloWorld. Quando executado, o resolvedor do campo helloWorld também executa e retorna a resposta:
{ "data": { "helloWorld": "Hello World" } }
Retornar constantes como essa é a coisa mais simples que você pode fazer. Na realidade, você retornará entradas, listas e muito mais. O exemplo a seguir é mais complicado:
type Book { id: ID! title: String } type Query { getBooks: [Book] }
Aqui estamos retornando uma lista de Books. Vamos supor que estejamos usando uma tabela do DynamoDB para armazenar dados do livro. Os manipuladores podem ser semelhantes a estes:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
Nossa solicitação usou uma operação de verificação integrada para pesquisar todas as entradas na tabela, armazenar as descobertas no contexto e depois passá-las para a resposta. A resposta pegou os itens do resultado e os retornou na resposta:
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
Contexto do resolvedor
Em um resolvedor, cada etapa na cadeia de manipuladores deve estar ciente do estado dos dados das etapas anteriores. O resultado de um manipulador pode ser armazenado e passado para outro como argumento. O GraphQL define quatro argumentos básicos do resolvedor:
| Argumentos básicos do resolvedor | Description |
|---|---|
obj, root, parent etc. |
O resultado do pai. |
args |
Os argumentos fornecidos ao campo na consulta do GraphQL. |
context |
Um valor que é fornecido a cada resolvedor e contém informações contextuais importantes, como o usuário atualmente conectado ou o acesso a um banco de dados. |
info |
Um valor que contém informações específicas do campo relevantes para a consulta atual, bem como os detalhes do esquema. |
Em AWS AppSync, o argumento context (ctx) pode conter todos os dados mencionados acima. Trata-se um objeto criado por solicitação e contém dados como credenciais de autorização, dados de resultados, erros, metadados de solicitações etc. O contexto é uma maneira fácil para os programadores manipularem dados provenientes de outras partes da solicitação. Considere este trecho novamente:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
A solicitação recebe o contexto (ctx) como argumento; esse é o estado da solicitação. Ele executa uma varredura de todos os itens em uma tabela e, em seguida, armazena o resultado no contexto em result. O contexto é então passado para o argumento de resposta, que acessa o result e retorna seu conteúdo.
Solicitações e análises
Quando você faz uma consulta ao seu serviço do GraphQL, ela deve passar por um processo de análise e validação antes de ser executada. Sua solicitação será analisada e traduzida em uma árvore de sintaxe abstrata. O conteúdo da árvore é validado por meio da execução de vários algoritmos de validação em relação ao seu esquema. Após a etapa de validação, os nós da árvore são percorridos e processados. Os resolvedores são invocados, os resultados são armazenados no contexto e a resposta é retornada. Por exemplo, considere esta consulta:
query { Person { //object type name //scalar age //scalar } }
Estamos retornando Person com campos name e age. Ao executar essa consulta, a árvore será semelhante a esta:

Na árvore, parece que essa solicitação pesquisará a raiz de Query no esquema. Dentro da consulta, o campo Person será resolvido. Com base em exemplos anteriores, sabemos que isso pode ser uma entrada do usuário, uma lista de valores, etc. A Person provavelmente está vinculada a um tipo de objeto que contém os campos de que precisamos (name e age). Depois que esses dois campos secundários são encontrados, eles são resolvidos na ordem indicada (name seguido por age). Depois que a árvore for completamente resolvida, a solicitação será concluída e enviada de volta ao cliente.
