Como funcionam as bases de conhecimento do Amazon Bedrock
O Amazon Bedrock Knowledge Bases ajuda você a aproveitar as vantagens da geração aumentada via recuperação (RAG), uma técnica conhecida que envolve extrair informações de um datastore para aumentar as respostas geradas por grandes modelos de linguagem (LLMs). Quando você configura uma base de conhecimento com a fonte de dados e o armazenamento de vetores, a aplicação pode consultar a base de conhecimento para exibir informações e responder à consulta com citações diretas das fontes ou com respostas naturais geradas com base nos resultados da consulta.
Com as bases de conhecimento, é possível construir aplicações enriquecidas pelo contexto recebido de consulta a uma base de conhecimento. Isso acelera o tempo de lançamento no mercado ao evitar o trabalho pesado da criação de pipelines, fornecendo a você uma solução de RAG pronta para usar a fim de reduzir o tempo de compilação da aplicação. Adicionar uma base de conhecimento também aumenta a relação custo-benefício, eliminando a necessidade de treinar continuamente o modelo para poder aproveitar os dados privados.
Os diagramas a seguir ilustram esquematicamente como a RAG é realizada. A base de conhecimento simplifica a configuração e a implementação da RAG, automatizando várias etapas desse processo.
Pré-processamento de dados
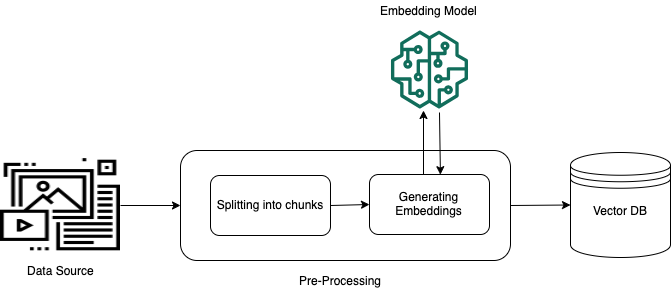
Para permitir a recuperação efetiva de dados privados, uma prática comum é primeiro converter os dados em texto e dividi-los em partes gerenciáveis. As partes ou fragmentos são convertidos em incorporações e gravados em um índice de vetores, mantendo uma correção com o documento original. Essas incorporações são usadas para determinar a semelhança semântica entre as consultas e o texto das fontes de dados. A imagem a seguir ilustra o pré-processamento de dados para o banco de dados de vetores.
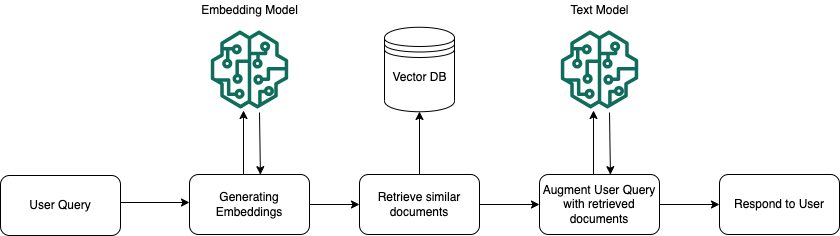
Execução do Runtime
Em tempo de execução, um modelo de incorporação é usado para converter a consulta do usuário em um vetor. O índice de vetores é consultado para encontrar partes que sejam semanticamente semelhantes à consulta do usuário, comparando os vetores do documento com o vetor de consulta do usuário. Na etapa final, o prompt do usuário é aumentado com o contexto adicional dos fragmentos que são recuperados do índice de vetores. O prompt e o contexto adicional são enviados ao modelo para gerar uma resposta para o usuário. A imagem a seguir ilustra como a RAG opera em tempo de execução para aumentar as respostas às consultas dos usuários.