As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Salas limpas da AWS ML
O AWS Clean Rooms ML permite que duas ou mais partes executem modelos de aprendizado de máquina em seus dados sem a necessidade de compartilhá-los entre si. O serviço fornece controles de aprimoramento de privacidade que permitem que os proprietários de dados protejam seus dados e o IP do modelo. Você pode usar modelos de AWS autoria ou trazer seu próprio modelo personalizado.
Consulte uma explicação mais detalhada de como isso funciona em Cross-account empregos.
Para obter mais informações sobre os recursos dos modelos ML de salas limpas, consulte os tópicos a seguir.
Tópicos
Terminologia de ML do AWS Clean Rooms
É importante entender a seguinte terminologia ao usar o Clean Rooms ML:
-
Provedor de dados de treinamento: a parte que contribui com os dados de treinamento, cria e configura um modelo de semelhanças e o associa a uma colaboração.
-
Provedor de dados de seed: a parte que contribui com os dados de seed, gera um segmento de semelhanças e o exporta.
-
Dados de treinamento: os dados do provedor de dados de treinamento, que são usados para gerar um modelo de semelhanças. Os dados de treinamento são usados para medir a semelhança nos comportamentos do usuário.
Os dados de treinamento devem conter uma coluna de ID de usuário, ID do item e carimbo de data/hora. Opcionalmente, os dados de treinamento podem conter outras interações como atributos numéricos ou categóricos. Exemplos de interações são uma lista de vídeos assistidos, itens comprados ou artigos lidos.
-
Dados de seed: os dados do provedor de dados de seed, que são usados para criar um segmento de semelhanças. Os dados iniciais podem ser fornecidos diretamente ou podem vir dos resultados de uma AWS Clean Rooms consulta. A saída do segmento de semelhanças é um conjunto de usuários dos dados de treinamento que mais se assemelha aos usuários de seed.
-
Modelo de semelhanças: um modelo de machine learning dos dados de treinamento usado para encontrar usuários semelhantes em outros conjuntos de dados.
Ao usar a API, o termo modelo de público é usado de forma equivalente ao modelo de semelhanças. Por exemplo, você usa a CreateAudienceModelAPI para criar um modelo semelhante.
-
Segmento de semelhanças: um subconjunto dos dados de treinamento que mais se assemelha aos dados iniciais.
Ao usar a API, você cria um segmento semelhante com a StartAudienceGenerationJobAPI.
Os dados do provedor de dados de treinamento nunca são compartilhados com o provedor de dados de seed e os dados do provedor de dados de seed nunca são compartilhados com o provedor de dados de treinamento. A saída do segmento de semelhanças é compartilhada com o provedor de dados de treinamento, mas nunca com o provedor de dados de seed.
Como o AWS Clean Rooms ML funciona com AWS modelos
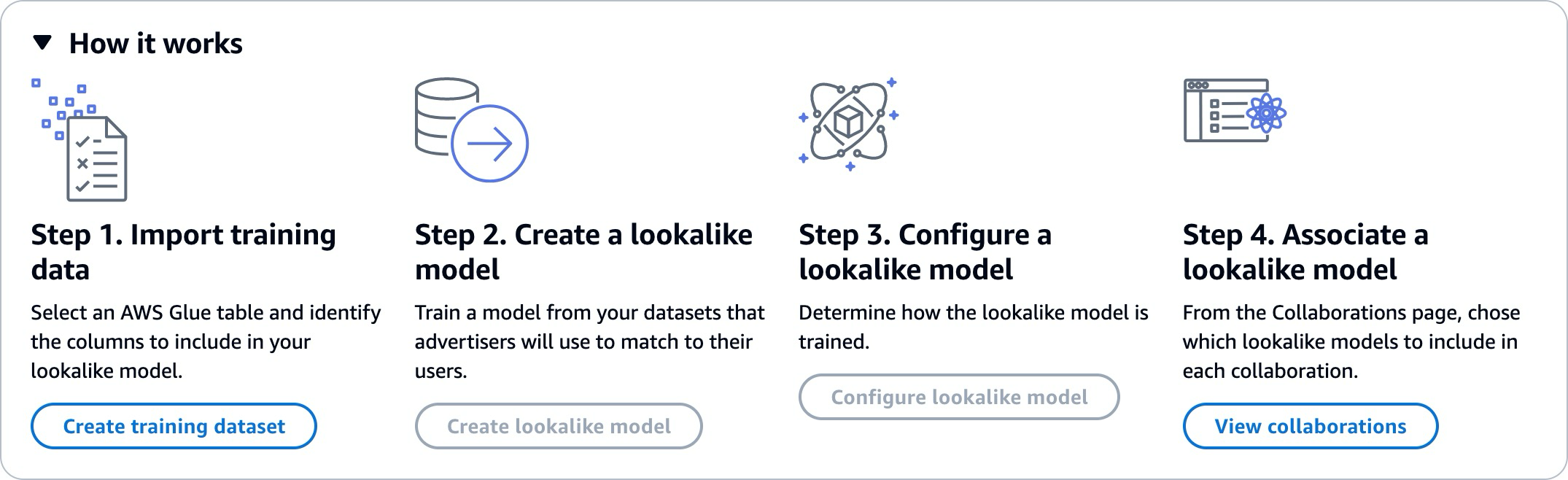
Trabalhar com modelos semelhantes exige que duas partes, um provedor de dados de treinamento e um provedor de dados iniciais, trabalhem sequencialmente AWS Clean Rooms para reunir seus dados em uma colaboração. Esse é o fluxo de trabalho que o provedor de dados de treinamento deve concluir primeiro:
-
Os dados do provedor de dados de treinamento devem ser armazenados em uma tabela de catálogo de AWS Glue dados de interações com itens do usuário. No mínimo, os dados de treinamento devem conter uma coluna de ID de usuário, de ID de interação e de carimbo de data e hora.
-
O provedor de dados de treinamento registra os dados de treinamento com AWS Clean Rooms.
-
O provedor de dados de treinamento cria um modelo de semelhanças que pode ser compartilhado com vários provedores de dados de seed. O modelo de semelhanças é uma rede neural profunda que pode levar até 24 horas para ser treinado. Ele não é retreinado automaticamente e recomendamos que você retreine o modelo semanalmente.
-
O provedor de dados de treinamento configura o modelo de semelhanças, incluindo se deseja compartilhar métricas de relevância e a localização dos segmentos de saída do Amazon S3. O provedor de dados de treinamento pode criar vários modelos de semelhanças configurados com base em um único modelo de semelhanças.
-
O provedor de dados de treinamento associa o modelo de público configurado a uma colaboração que é compartilhada com um provedor de dados iniciais.
Esse é o fluxo de trabalho que o provedor de dados de seed deve concluir a seguir:
-
Os dados do provedor de dados iniciais podem ser armazenados em um bucket do Amazon S3 ou podem vir dos resultados da consulta.
-
O provedor de dados de seed abre a colaboração que compartilha com o provedor de dados de treinamento.
-
O provedor de dados iniciais cria um segmento de semelhanças na guia Clean Rooms ML da página de colaboração.
-
O provedor de dados de seed poderá avaliar as métricas de relevância, se elas foram compartilhadas, e exportar o segmento de semelhanças para uso fora do AWS Clean Rooms.
Como o AWS Clean Rooms ML funciona com modelos personalizados
Com o Clean Rooms ML, os membros de uma colaboração podem usar um algoritmo de modelo personalizado dockerizado que é armazenado no Amazon ECR para analisar conjuntamente seus dados. Para fazer isso, o provedor do modelo deve criar uma imagem e armazená-la no Amazon ECR. Siga as etapas no Guia do usuário do Amazon Elastic Container Registry para criar um repositório privado que conterá o modelo de ML personalizado.
Qualquer membro de uma colaboração pode ser o fornecedor do modelo, desde que tenha as permissões corretas. Todos os membros de uma colaboração podem contribuir com dados de treinamento, dados de inferência ou ambos para o modelo. Para fins deste guia, os membros que contribuem com dados são chamados de provedores de dados. O membro que cria a colaboração é o criador da colaboração, e esse membro pode ser o provedor do modelo, um dos provedores de dados ou ambos.
No nível mais alto, aqui estão as etapas que devem ser concluídas para realizar a modelagem personalizada de ML:
-
O criador da colaboração cria uma colaboração e atribui a cada membro as habilidades e a configuração de pagamento adequadas. O criador da colaboração deve atribuir a capacidade do membro de receber saídas do modelo ou receber resultados de inferência ao membro apropriado nesta etapa, pois ela não pode ser atualizada após a criação da colaboração. Para obter mais informações, consulte Criando e participando da colaboração no AWS Clean Rooms ML.
-
O provedor de modelos configura e associa seu modelo de ML em contêineres à colaboração e garante que as restrições de privacidade sejam definidas para os dados exportados. Para obter mais informações, consulte Configurando um algoritmo de modelo no AWS Clean Rooms ML.
-
Os provedores de dados contribuem com seus dados para a colaboração e garantem que suas necessidades de privacidade sejam especificadas. Os provedores de dados devem permitir que o modelo acesse seus dados. Para obter mais informações, consulte Contribuindo com dados de treinamento no AWS Clean Rooms ML e Associando o algoritmo do modelo configurado no AWS Clean Rooms ML.
-
Um membro da colaboração cria a configuração de ML, que define para onde os artefatos do modelo ou os resultados da inferência são exportados.
-
Um membro da colaboração cria um canal de entrada de ML que fornece informações para o contêiner de treinamento ou contêiner de inferência. O canal de entrada de ML é uma consulta que define os dados a serem usados no contexto do algoritmo do modelo.
-
Um membro da colaboração invoca o treinamento do modelo usando o canal de entrada de ML e o algoritmo do modelo configurado. Para obter mais informações, consulte Criação de um modelo treinado no AWS Clean Rooms ML.
-
(Opcional) O treinador de modelos invoca a tarefa de exportação do modelo e os artefatos do modelo são enviados ao receptor dos resultados do modelo. Somente membros com uma configuração de ML válida e a capacidade do membro de receber a saída do modelo podem receber artefatos do modelo. Para obter mais informações, consulte Exportação de artefatos de modelo do AWS Clean Rooms ML.
-
(Opcional) Um membro da colaboração invoca a inferência do modelo usando o canal de entrada de ML, o ARN do modelo treinado e o algoritmo do modelo configurado por inferência. Os resultados da inferência são enviados para o receptor de saída da inferência. Somente membros com uma configuração de ML válida e a capacidade do membro de receber resultados de inferência podem receber resultados de inferência.
Aqui estão as etapas que devem ser concluídas pelo fornecedor do modelo:
-
Crie uma imagem docker do Amazon ECR compatível com SageMaker IA. O Clean Rooms ML suporta somente SageMaker imagens docker compatíveis com IA.
-
Depois de criar uma imagem docker compatível com SageMaker IA, envie a imagem para o Amazon ECR. Siga as instruções no Guia do usuário do Amazon Elastic Container Registry para criar uma imagem de treinamento de contêineres.
-
Configure o algoritmo do modelo para uso em Clean Rooms ML.
-
Forneça o link do repositório Amazon ECR e todos os argumentos necessários para configurar o algoritmo do modelo.
-
Forneça uma função de acesso ao serviço que permita que o Clean Rooms ML acesse o repositório Amazon ECR.
-
Associe o algoritmo do modelo configurado à colaboração. Isso inclui fornecer uma política de privacidade que define controles para registros de contêineres, registros de falhas, CloudWatch métricas e limites sobre a quantidade de dados que podem ser exportados dos resultados do contêiner.
-
Aqui estão as etapas que devem ser concluídas pelo provedor de dados para colaborar com um modelo de ML personalizado:
-
Configure uma AWS Glue tabela existente com uma regra de análise personalizada. Isso permite que um conjunto específico de consultas pré-aprovadas ou contas pré-aprovadas use seus dados.
-
Associe sua tabela configurada a uma colaboração e forneça uma função de acesso ao serviço que possa acessar suas AWS Glue tabelas.
-
Adicione uma regra de análise de colaboração à tabela que permita que a associação do algoritmo do modelo configurado acesse a tabela configurada.
-
Depois que o modelo e os dados são associados e configurados no Clean Rooms ML, o membro com a capacidade de executar consultas fornece uma consulta SQL e seleciona o algoritmo do modelo a ser usado.
Depois que o treinamento do modelo é concluído, esse membro inicia a exportação dos artefatos de treinamento do modelo ou dos resultados de inferência. Esses artefatos ou resultados são enviados ao membro com a capacidade de receber a saída do modelo treinado. O receptor de resultados deve configurá-los MachineLearningConfiguration antes de receber a saída do modelo.
