As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Solução de problemas da Amazon DataZone
Se você encontrar problemas de acesso negado ou dificuldades semelhantes ao trabalhar com a Amazon, DataZone consulte os tópicos desta seção.
Solução de problemas de permissões do AWS Lake Formation para a Amazon DataZone
Esta seção contém as instruções de solução de problemas que podem ocorrer ao Configurar as permissões do Lake Formation para a Amazon DataZone.
| Mensagem de erro no Portal de Dados | Resolução |
|---|---|
|
Não é possível assumir o perfil de acesso a dados. |
Esse erro é exibido quando a Amazon DataZone não consegue assumir o AmazonDataZoneGlueDataAccessRoleque você usou para habilitá-lo DefaultDataLakeBlueprintem sua conta. Para corrigir o problema, acesse o console AWS do IAM na conta em que seu ativo de dados existe e verifique se ele AmazonDataZoneGlueDataAccessRoletem a relação de confiança correta com o responsável pelo DataZone serviço principal da Amazon. Para obter mais informações, consulte AmazonDataZoneGlueAccess- <region>- <domainId>. |
|
O perfil de acesso a dados não tem as permissões necessárias para ler os metadados do ativo que você está tentando assinar. |
Esse erro é exibido quando a Amazon assume DataZone com sucesso a AmazonDataZoneGlueDataAccessRolefunção, mas a função não tem as permissões necessárias. Para corrigir o problema, acesse o console AWS do IAM na conta em que seu ativo de dados existe e verifique se a função está AmazonDataZoneGlueManageAccessRolePolicyanexada. Para obter mais informações, consulte AmazonDataZoneGlueAccess- <region>- <domainId>. |
|
O ativo é um link de recurso. A Amazon DataZone não oferece suporte a assinaturas de links de recursos. |
Esse erro é exibido quando o ativo que você está tentando publicar na Amazon DataZone é um link de recurso para uma tabela do AWS Glue. |
|
O ativo não é gerenciado pela AWS Lake Formation. |
Esse erro indica que as permissões do AWS Lake Formation não são aplicadas ao ativo que você deseja publicar. Isso ocorre nos casos a seguir.
|
|
O perfil Acesso a Dados não tem as permissões necessárias do Lake Formation para conceder acesso a esse ativo. |
Esse erro indica que o AmazonDataZoneGlueDataAccessRoleque você está usando para habilitar o DefaultDataLakeBlueprintem sua conta não tem as permissões necessárias para que DataZone a Amazon gerencie as permissões no ativo publicado. Você pode resolver o problema adicionando o AmazonDataZoneGlueDataAccessRolecomo administrador do AWS Lake Formation ou concedendo as seguintes permissões ao AmazonDataZoneGlueDataAccessRoleativo que você deseja publicar.
|
Solução de problemas de vinculação de ativos DataZone de linhagem da Amazon com conjuntos de dados upstream
Esta seção contém instruções de solução de problemas que você pode encontrar com a DataZone linhagem da Amazon. Em alguns dos AWS Glue eventos de execução de linhagem aberta relacionados ao Amazon Redshift, você pode ver que a linhagem de ativos não está vinculada a um conjunto de dados upstream. Este tópico explica os cenários e algumas abordagens para reduzir problemas. Para obter mais informações sobre linhagem, consulte Linhagem de dados na Amazon DataZone.
SourceIdentifier no nó de linhagem
O atributo sourceIdentifier em um nó de linhagem representa os eventos que acontecem em um conjunto de dados. Para obter mais informações, consulte Atributos principais em nós de linhagem.
O nó de linhagem representa todos os eventos que acontecem no conjunto de dados ou no trabalho correspondente. O nó de linhagem contém um atributo “sourceIdentifier” que contém o identificador do conjunto de dados/trabalho correspondente. Como oferecemos suporte a eventos de linhagem aberta, o valor sourceIdentifier é preenchido por padrão como a combinação de “namespace” e “nome” para um conjunto de dados, trabalho e execução de trabalhos.
Para AWS recursos como AWS Glue o Amazon Redshift, sourceIdentifier seriam a tabela AWS Glue ARN e a tabela Redshift a ARNs partir da qual a DataZone Amazon construirá o evento de execução e outros detalhes da seguinte forma:
nota
Em AWS, o ARN contém informações como AccountID, região, banco de dados e tabela para cada recurso.
OpenLineage O evento desses conjuntos de dados contém o nome do banco de dados e da tabela.
A região é capturada na faceta “environment-properties” de uma execução. Se não estiver presente, o sistema usa a região a partir das credenciais do chamador.
AccountId é obtido das credenciais do chamador.
SourceIdentifier sobre os ativos dentro DataZone
AssetCommonDetailForm tem um atributo chamado “sourceIdentifier” que representa o identificador do conjunto de dados que o ativo representa. Para que os nós de linhagem de ativos sejam vinculados a um conjunto de dados upstream, o atributo precisa ser preenchido com o valor correspondente ao do nó do conjunto de dados sourceIdentifier. Se os ativos forem importados por fonte de dados, o fluxo de trabalho será preenchido automaticamente sourceIdentifier como ARN da tabela AWS Glue ARN/Redshift table ARN, enquanto outros ativos (incluindo ativos personalizados) criados por meio da CreateAsset API devem ter esse valor preenchido pelo chamador.
Como a Amazon DataZone constrói o SourceIdentifier a partir do OpenLineage evento?
Para ativos do Redshift AWS Glue e do Redshift, o sourceIdentifier é construído a partir do Glue e do Redshift. ARNs Veja como a Amazon o DataZone constrói:
AWS Glue ARN
O objetivo é construir um OpenLineage evento em que o nó da linhagem de saída sourceIdentifier seja:
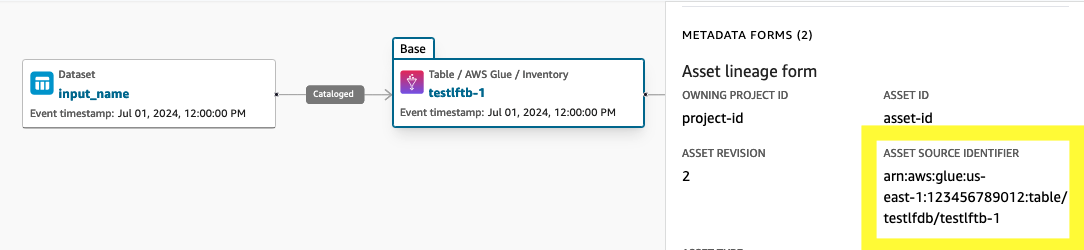
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
Para determinar se uma execução está usando dados de AWS Glue, procure a presença de determinadas palavras-chave na environment-properties faceta. Especificamente, se houver algum desses campos designados, o sistema presume que a RunEvent é proveniente de AWS Glue.
GLUE_VERSION
GLUE_COMMAND_CRITERIA
GLUE_PYTHON_VERSION
"run": { "runId":"4e3da9e8-6228-4679-b0a2-fa916119fthr", "facets":{ "environment-properties":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet", "environment-properties":{ "GLUE_VERSION":"3.0", "GLUE_COMMAND_CRITERIA":"glueetl", "GLUE_PYTHON_VERSION":"3" } } }
Para uma AWS Glue execução, você pode usar o nome da symlinks faceta para obter o nome do banco de dados e da tabela, que podem ser usados para construir o ARN.
Preciso ter certeza de que o nome é databaseName.tableName:
"symlinks": { "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers":[ { "namespace":"s3://object-path", "name":"testlfdb.testlftb-1", "type":"TABLE" } ] }
Exemplo de evento COMPLETE:
{ "eventTime":"2024-07-01T12:00:00.000000Z", "producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/glue", "schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent", "eventType":"COMPLETE", "run": { "runId":"4e3da9e8-6228-4679-b0a2-fa916119fthr", "facets":{ "environment-properties":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet", "environment-properties":{ "GLUE_VERSION":"3.0", "GLUE_COMMAND_CRITERIA":"glueetl", "GLUE_PYTHON_VERSION":"3" } } } }, "job":{ "namespace":"namespace", "name":"job_name", "facets":{ "jobType":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/glue", "_schemaURL":"https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet", "processingType":"BATCH", "integration":"glue", "jobType":"JOB" } } }, "inputs":[ { "namespace":"namespace", "name":"input_name" } ], "outputs":[ { "namespace":"namespace.output", "name":"output_name", "facets":{ "symlinks":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers":[ { "namespace":"s3://object-path", "name":"testlfdb.testlftb-1", "type":"TABLE" } ] } } } ] }
Com base no evento OpenLineage enviado, o nó sourceIdentifier da linhagem de saída será:
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
O nó de linhagem de saída será conectado ao nó de linhagem de um ativo, onde o do ativo é sourceIdentifier:
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1

Amazon Redshift, ARN
O objetivo é construir um OpenLineage evento em que o nó da linhagem de saída sourceIdentifier seja:
arn:aws:redshift:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
O sistema determina se uma entrada ou saída é armazenada no Redshift com base no namespace. Particularmente, se o namespace começar com redshift:// ou contiver as cadeias de caracteres redshift-serverless.amazonaws.com ou redshift.amazonaws.com, ele é um recurso Redshift.
"outputs": [ { "namespace":"redshift://workgroup-20240715.123456789012.us-east-1.redshift.amazonaws.com:5439", "name":"tpcds_data.public.dws_tpcds_7" } ]
Observe que o namespace precisa estar no seguinte formato:
provider://{cluster_identifier}.{region_name}:{port}
Para redshift-serverless:
"outputs": [ { "namespace":"redshift://workgroup-20240715.123456789012.us-east-1.redshift-serverless.amazonaws.com:5439", "name":"tpcds_data.public.dws_tpcds_7" } ]
Isso resulta no sourceIdentifier a seguir
arn:aws:redshift-serverless:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Com base no OpenLineage evento enviado, o nó de linhagem sourceIdentifier a ser mapeado para um nó de linhagem a jusante (ou seja, uma saída do evento) é:
arn:aws:redshift-serverless:us-e:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Esse é o mapeamento que ajuda você a visualizar a linhagem de um ativo no catálogo.
Abordagem alternativa
Quando nenhuma das condições acima for atendida, o sistema usa o namespace/name para construir sourceIdentifier:
"inputs": [ { "namespace":"arn:aws:redshift:us-east-1:123456789012:table", "name":"workgroup-20240715/tpcds_data/public/dws_tpcds_7" } ], "outputs": [ { "namespace":"arn:aws:glue:us-east-1:123456789012:table", "name":"testlfdb/testlftb-1" } ]
Solucionando a falta de upstream para o nó de linhagem de ativos
Se você não vê o upstream do nó da linhagem do ativo, faça o seguinte para solucionar o motivo pelo qual ele não está vinculado ao conjunto de dados:
Invoque
GetAssetenquanto fornece odomainIde oassetId:aws datazone get-asset --domain-identifier <domain-id> --identifier <asset-id>A resposta é exibida da seguinte maneira:
{ ..... "formsOutput": [ ..... { "content": "{\"sourceIdentifier\":\"arn:aws:glue:eu-west-1:123456789012:table/testlfdb/testlftb-1\"}", "formName": "AssetCommonDetailsForm", "typeName": "amazon.datazone.AssetCommonDetailsFormType", "typeRevision": "6" }, ..... ], "id": "<asset-id>", .... }Invoque
GetLineageNodepara obter o nósourceIdentifierda linhagem do conjunto de dados. Como não há como obter diretamente o nó de linhagem para o nó do conjunto de dados correspondente, você pode começar com a execuçãoGetLineageNodedo trabalho:aws datazone get-lineage-node --domain-identifier <domain-id> --identifier <job_namespace>.<job_name>/<run_id> if you are using the getting started scripts, job name and run ID are printed in the console and namespace is "default". Otherwise you can get these values from run event content.A resposta do exemplo é semelhante à seguinte:
{ ..... "downstreamNodes": [ { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "afymge5k4v0euf" } ], "formsOutput": [ <some forms corresponding to run and job> ], "id": "<system generated node-id for run>", "sourceIdentifier": "default.redshift.create/2f41298b-1ee7-3302-a14b-09addffa7580", "typeName": "amazon.datazone.JobRunLineageNodeType", .... "upstreamNodes": [ { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "6wf2z27c8hghev" }, { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "4tjbcsnre6banb" } ] }Invoque
GetLineageNodenovamente passando o identificador do downstream/upstream nó (que você acha que deveria estar vinculado ao nó do ativo), pois ele corresponde ao conjunto de dados:Exemplo de comando usando o exemplo de resposta acima:
aws datazone get-lineage-node --domain-identifier <domain-id> --identifier afymge5k4v0eufOs detalhes do nó de linhagem correspondentes ao conjunto de dados: afymge5k4v0euf são retornados
{ ..... "domainId": "dzd_cklzc5s2jcr7on", "downstreamNodes": [], "eventTimestamp": "2024-07-24T18:08:55+08:00", "formsOutput": [ ..... ], "id": "afymge5k4v0euf", "sourceIdentifier": "arn:aws:redshift:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7", "typeName": "amazon.datazone.DatasetLineageNodeType", "typeRevision": "1", .... "upstreamNodes": [ ... ] }Compare o nó
sourceIdentifierdesse conjunto de dados e a resposta deGetAsset. Se não estiverem vinculados, eles não corresponderão e, portanto, não estarão visíveis na interface de usuário da linhagem.
Cenários e mitigações incompatíveis
A seguir estão os cenários comumente conhecidos em que eles não coincidem e as possíveis mitigações:
Causa raiz: as tabelas estão presentes em uma conta diferente da conta de DataZone domínio da Amazon.
Atenuação: você pode invocar a operação PostLineageEvent por meio de uma conta associada. Como accountId a criação do ARN é selecionada a partir das credenciais do chamador, você pode assumir o perfil na conta que contém as tabelas ao executar o script de introdução ou invocar PostLineageEvent. Isso ajudará na construção ARNs correta e na vinculação com os nós do ativo.
Causa raiz: o ARN para Redshift table/views contém Redshift/Redshift-Serverless com base no namespace e nos atributos de nome das informações do conjunto de dados correspondente no evento de execução. OpenLineage
Atenuação: como não há uma forma determinística de saber se o nome fornecido pertence ao cluster ou ao grupo de trabalho, usamos a seguinte heurística:
Se o “nome” correspondente ao conjunto de dados contiver "
redshift-serverless.amazonaws.com“, usaremos redshift-serverless como parte do ARN, caso contrário, o padrão será “redshift”.O que foi dito acima significa que os aliases nos nomes dos grupos de trabalho não funcionarão.
Causa-raiz: os conjuntos de dados upstream não estão vinculados corretamente para ativos personalizados.
Atenuação: preencha o sourceIdentifier no ativo invocando CreateAsset/CreateAssetRevision que corresponda ao do sourceIdentifier do nó do conjunto de dados (que seria <namespace>/<name> para nós personalizados).
