As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Treine seu primeiro modelo do AWS DeepRacer
Este passo a passo demonstra como treinar seu primeiro modelo no AWS DeepRacer.
Treine um modelo de aprendizagem de reforço usando o console do AWS DeepRacer
Saiba onde encontrar o botão Criar modelo no console do AWS DeepRacer para iniciar sua jornada de treinamento de modelos.
Para treinar um modelo de aprendizagem por reforço
-
Se esta é a primeira vez que você usa o AWS DeepRacer, escolha Create model na página inicial do serviço ou selecione Iniciar sob o título Aprendizado por reforço no painel de navegação principal.
-
Na página Conceitos básicos do aprendizado por reforço, na Etapa 2: Criar um modelo e corrida, escolha Criar modelo.
Ou, se preferir, escolha Seus modelos no título Aprendizado por reforço no painel de navegação principal. Na página Your models (Seus modelos), selecione Create model (Criar modelo).
Especifique o nome do modelo e o ambiente
Dê um nome ao seu modelo e saiba como escolher a pista de simulação certa para você.
Para especificar o nome do modelo e o ambiente
-
Na página Criar modelo, em Detalhes do treinamento insira um nome para seu modelo.
-
Opcionalmente, adicione uma descrição para a tarefa de treinamento.
-
Para saber mais sobre outras tags opcionais, consulte AWS DeepRacer.Marcação
-
Em Simulação do ambiente, escolha uma pista para servir como ambiente de treinamento para seu agente do AWS DeepRacer. Em Direção da pista, escolha Sentido horário ou anti-horário. Em seguida, escolha Next (Próximo).
Para a sua primeira corrida, escolha uma pista com uma forma simples e curvas suaves. Em iterações posteriores, você pode escolher pistas mais complexas para melhorar progressivamente seus modelos. Para treinar um modelo para determinado evento de corrida, escolha a pista mais semelhante à pista do evento.
-
Na parte inferior da página, selecione Próximo.
Escolha um tipo de corrida e um algoritmo de treinamento
O console do AWS DeepRacer tem três tipos de corrida e dois algoritmos de treinamento disponíveis. Saiba quais são apropriados para seu nível de habilidade e suas metas de treinamento.
Para escolher um tipo de corrida e um algoritmo de treinamento
-
Na página Criar modelo, em Tipo de corrida, selecione Avaliação de tempo, Desvio de objetos ou Confronto direto com bots.
Para sua primeira corrida, recomendamos escolher Avaliação de tempo. Para obter orientação sobre como otimizar a configuração do sensor do seu agente para esse tipo de corrida, consulte Personalize o treinamento do AWS DeepRacer para testes de contrarrelógio.
-
Para corridas posteriores, você pode escolher Desvio de objetos para contornar obstáculos estacionários colocados em locais fixos ou aleatórios ao longo da pista escolhida. Para obter mais informações, consulte Personalizar o treinamento do AWS DeepRacer para pistas com desvio de objetos.
-
Escolha Local fixo para gerar caixas em locais fixos designados pelo usuário nas duas faixas da pista ou selecione Local aleatório para gerar objetos que são distribuídos aleatoriamente pelas duas faixas no início de cada episódio de sua simulação de treinamento.
-
Em seguida, escolha um valor para o Número de objetos em uma pista.
-
Se você escolher Localização fixa, poderá ajustar o posicionamento de cada objeto na pista. Para Posicionamento da faixa, escolha entre a faixa interna e a externa. Por padrão, os objetos são distribuídos uniformemente pela pista. Para alterar a distância entre a linha de partida e a linha de chegada de um objeto, insira uma porcentagem dessa distância entre 7 e 90 no campo Localização (%) entre o início e o fim.
-
-
Para corridas mais ambiciosas, escolha Corridas mano a mano para correr contra até quatro veículos robôs que se movem a uma velocidade constante. Para saber mais, consulte Personalize o treinamento do AWS DeepRacer para corridas head-to-bot.
-
Em Escolha o número de veículos bot, selecione com quantos veículos bot você deseja que seu agente treine.
-
Em seguida, escolha a velocidade em milímetros por segundo na qual você deseja que os veículos bots percorram a pista.
-
Outra opção é marcar a caixa Ativar mudanças de faixa para permitir que os veículos robôs mudem de faixa aleatoriamente a cada 1-5 segundos.
-
-
Em Algoritmo de treinamento e hiperparâmetros, escolha o algoritmo Ator-crítica suave (SAC) ou Otimização de política proximal (PPO) (. No console do AWS DeepRacer, os modelos de SAC devem ser treinados em espaços de ação contínuos. Os modelos de PPO podem ser treinados em espaços de ação contínua ou discreta.
-
Em Algoritmo e hiperparâmetros de treinamento, use os valores de hiperparâmetros padrão como estão.
Mais tarde, para melhorar o desempenho do treinamento, expanda Hyperparameters (Hiperparâmetros) e modifique os valores padrão dos hiperparâmetros da seguinte forma:
-
Para Gradient descent batch size (Tamanho de lote da descida de gradiente), escolha as opções disponíveis.
-
Para Number of epochs (Número de epochs), defina um valor válido.
-
Para Learning rate (Taxa de aprendizado), defina um valor válido.
-
Para o valor alfa do SAC (somente algoritmo do SAC), defina um valor válido.
-
Para Entropy (Entropia), defina um valor válido.
-
Para Discount factor (Fato de desconto), defina um valor válido.
-
Para Loss type (Tipo de perda), escolha as opções disponíveis.
-
Para Number of experience episodes between each policy-updating iteration (Número de episódios de experiência entre cada iteração de atualização de política), defina um valor válido.
Para obter mais informações sobre hiperparâmetros, consulte Ajustar sistematicamente os hiperparâmetros.
-
-
Escolha Next (Próximo).
Defina o espaço de ação
Na página Definir espaço de ação, se você optou por treinar com o algoritmo Ator-crítica suave (SAC), seu espaço de ação padrão é o Espaço de ação contínuo. Se você optou por treinar com o algoritmo Otimização de Política Proximal (PPO), escolha entre Espaço de ação contínuo e Espaço de ação discreta. Para saber mais sobre como cada espaço de ação e algoritmo molda a experiência de treinamento do agente, consulte Espaço de ação e função de recompensa do AWS DeepRacer.
-
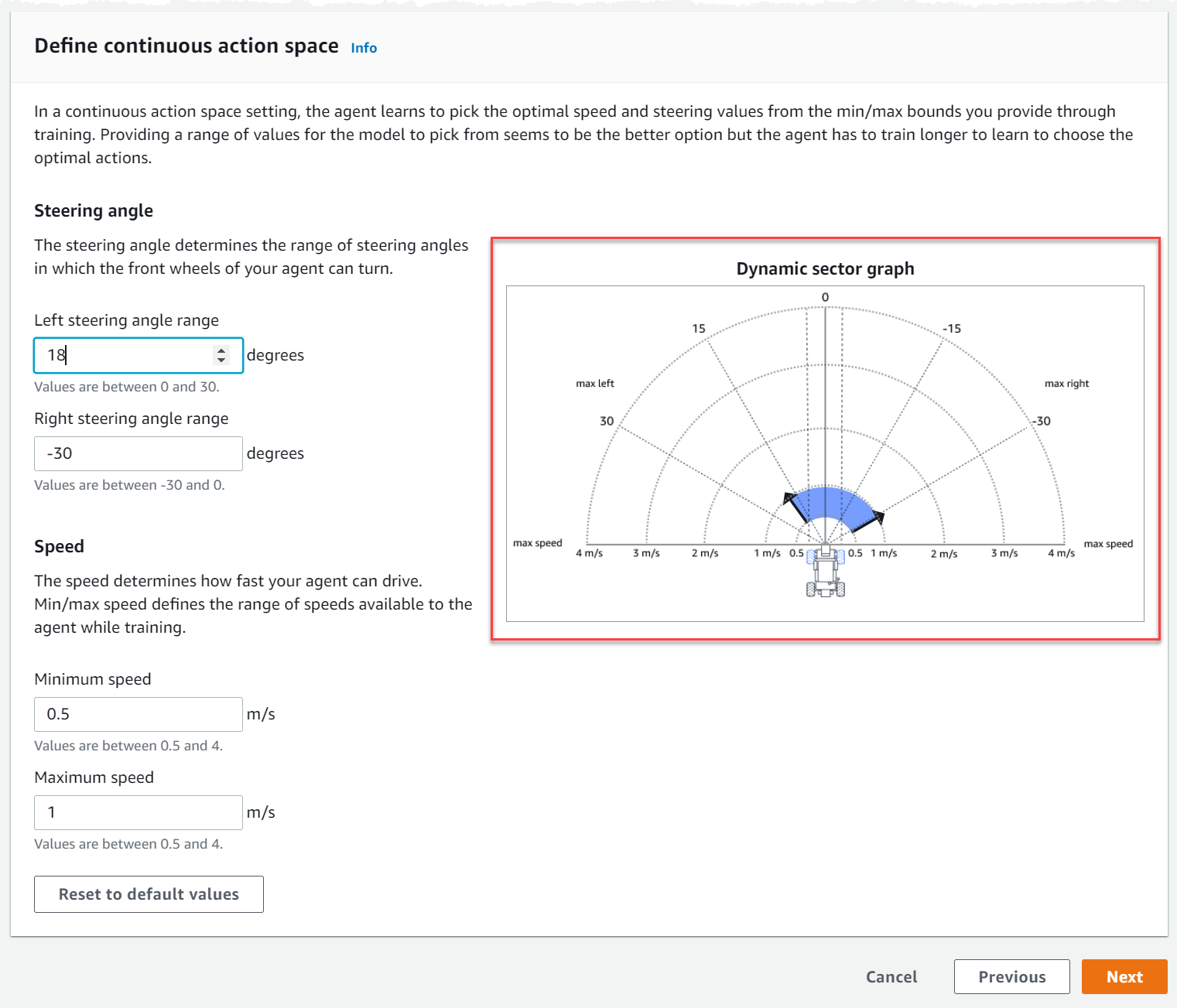
Em Definir espaço de ação contínuo, escolha os graus do intervalo do Ângulo direção à esquerda e do Ângulo de direção à direita.
Tente inserir graus diferentes para cada intervalo de ângulo de direção e observe a visualização de sua mudança de intervalo para representar suas escolhas no Gráfico dinâmico do setor.
-
Em Velocidade, insira uma velocidade mínima e máxima para seu agente em milímetros por segundo.
Observe como suas alterações são refletidas no Gráfico dinâmico do setor.
-
Opcionalmente, escolha Redefinir para valores padrão para limpar valores indesejados. Incentivamos testar valores diferentes no gráfico para experimentar e aprender.
-
Escolha Next (Próximo).
-
Escolha um valor para a Granularidade do ângulo de direção na lista suspensa.
-
Escolha um valor em graus entre 1 e 30 para o Ângulo máximo de direção do seu agente.
-
Selecione um valor para a Granularidade de velocidade na lista suspensa.
-
Escolha um valor em milímetros por segundo entre 0,1-4 para a velocidade máxima do seu agente.
-
Use as configurações de ação padrão na Lista de ações ou, opcionalmente, ative a Configuração avançada para ajustar suas configurações. Ao selecionar Anterior ou desativar a Configuração avançada após ajustar os valores, as alterações serão perdidas.
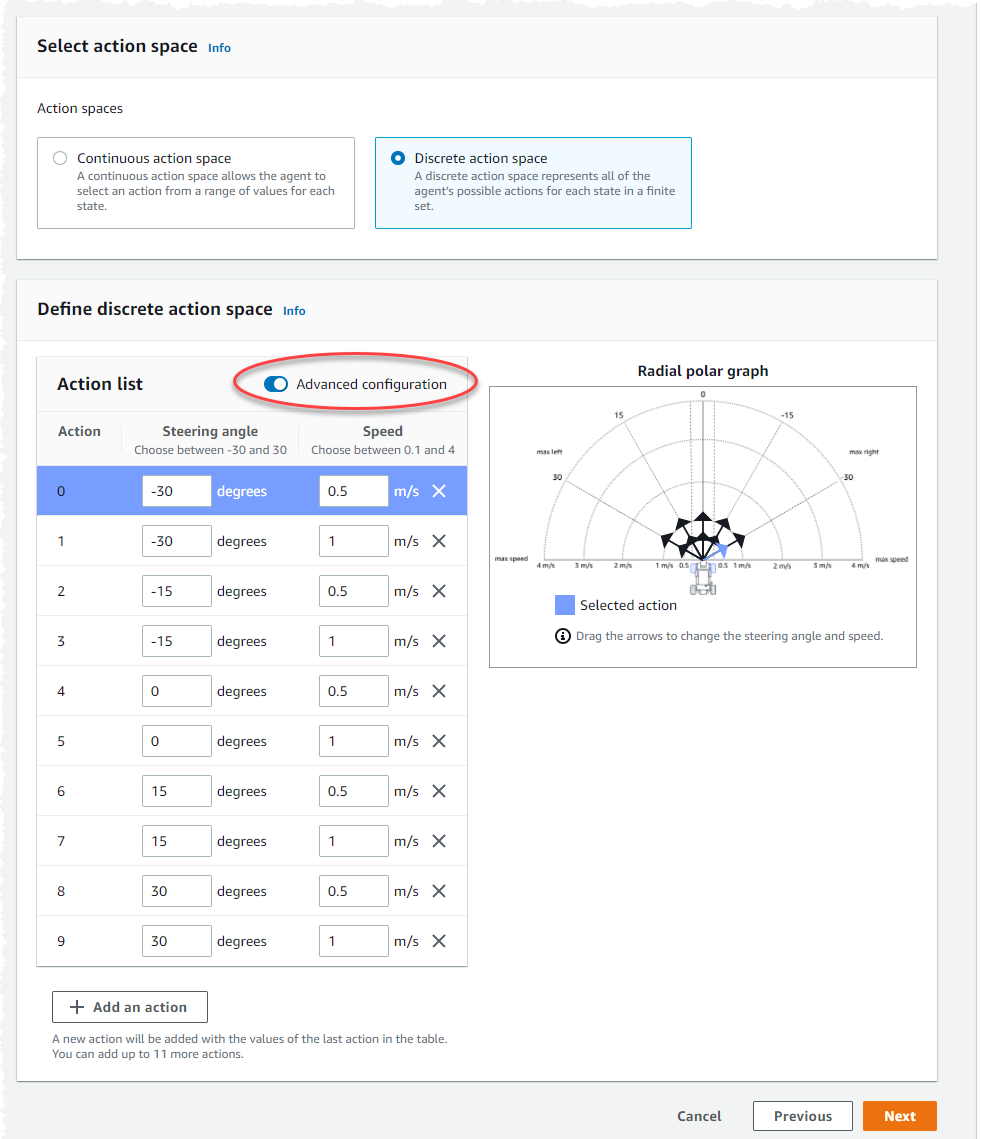
-
Insira um valor em graus entre -30 e 30 na coluna Ângulo de direção.
-
Insira um valor entre 0,1 e 4 em milímetros por segundo para até nove ações na coluna Velocidade.
-
Você também pode selecionar Adicionar uma ação para aumentar o número de linhas na lista de ações.
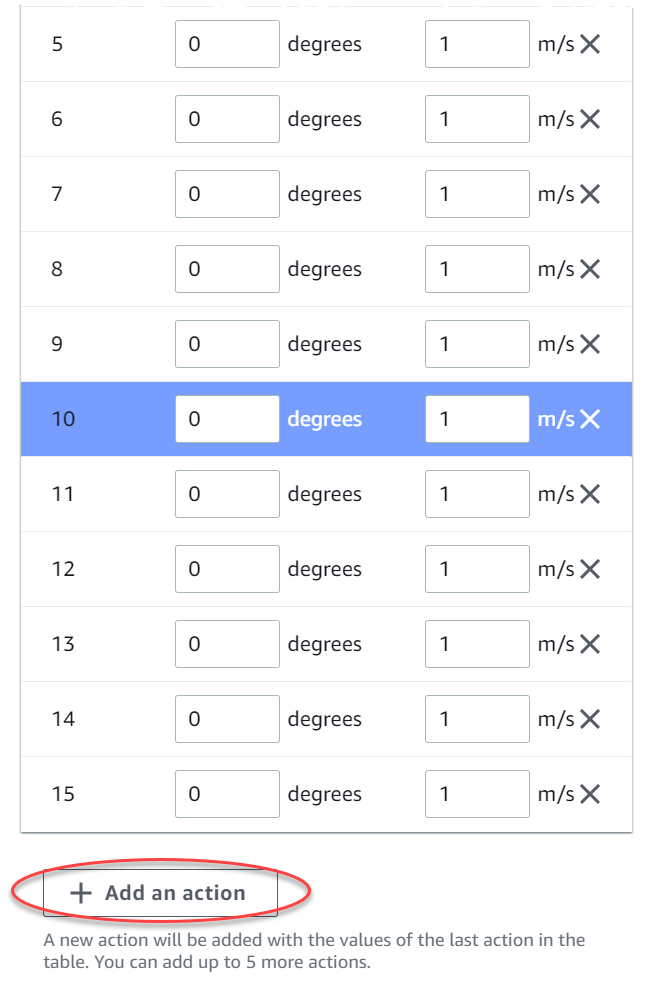
-
Ou selecione X em uma linha para removê-la.
-
-
Escolha Next (Próximo).
Escolha um carro virtual
Saiba como começar a usar carros virtuais. Ganhe novos carros personalizados, pinturas e modificações competindo na Divisão aberta todos os meses.
Para escolher um carro virtual
-
Na página Escolha o shell do veículo e a configuração do sensor, escolha um shell que seja compatível com seu tipo de corrida e espaço de ação. Se você não tiver um carro adequado na garagem, acesse Sua garagem no título Aprendizado por reforço no painel de navegação principal para criar um.
Para o treinamento de Avaliação de tempo, a configuração padrão do sensor e a câmera de lente única do DeepRacer Original são tudo o que você precisa, mas todas as outras configurações de shells e sensores funcionam desde que o espaço de ação corresponda. Para obter mais informações, consulte Personalize o treinamento do AWS DeepRacer para testes de contrarrelógio.
Para o treinamento para Desvio de objetos, câmeras estéreo são úteis, mas uma única câmera também pode ser usada para desviar de obstáculos estacionários em locais fixos. Um sensor LiDAR é opcional. Consulte Espaço de ação e função de recompensa do AWS DeepRacer.
Para o treinamento Confronto direto com bots, além de uma única câmera ou câmera estéreo, uma unidade LiDAR é ideal para detectar e evitar pontos cegos ao ultrapassar outros veículos em movimento. Para saber mais, consulte Personalize o treinamento do AWS DeepRacer para corridas head-to-bot.
-
Escolha Next (Próximo).
Personalizar sua função de recompensa
A função de recompensa é uma parte importante do aprendizado por reforço. Aprenda a usá-la para incentivar seu carro (agente) a realizar ações específicas ao explorar a pista (ambiente). Assim como você incentivaria ou não certos comportamentos em um animal de estimação, você pode usar essa ferramenta para incentivar seu carro a terminar uma volta o mais rápido possível e evitar que ele saia da pista ou colida com objetos.
Para personalizar sua função de recompensa
-
Na página Create model (Criar modelo), em Reward function (Função de recompensa), use o exemplo de função de recompensa padrão como está para seu primeiro modelo.
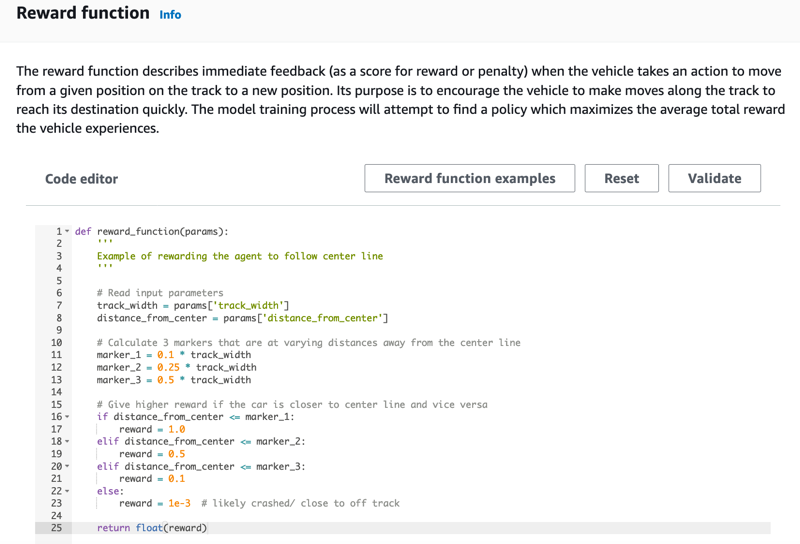
Posteriormente, você pode escolher Reward function examples (Exemplos de função de recompensa) para selecionar outra função de exemplo e escolher Use code (Usar código) para aceitar a função de recompensa selecionada.
Para começar, há três de funções de exemplo. Elas ilustram como seguir o centro da pista (padrão), como manter o agente dentro das margens da pista, como evitar a condução em ziguezague e como evitar colisão com obstáculos estacionários ou outros veículos em movimento.
Para saber mais sobre a função de recompensa, consulte Referência da função de DeepRacer recompensa da AWS.
-
Em Condições de interrupção, deixe o valor padrão de Tempo máximo como está ou defina um novo valor para encerrar a tarefa de treinamento, para ajudar a evitar tarefas de treinamento de longa duração (e possíveis fugitivos).
Ao experimentar na fase inicial do treinamento, você deve começar com um valor pequeno para esse parâmetro e treinar progressivamente para valores maiores de tempo.
-
Em Enviar automaticamente para o AWS DeepRacer, Enviar este modelo para o AWS DeepRacer automaticamente após a conclusão do treinamento e ter a chance de ganhar prêmios é marcado por padrão. Você pode também deixar de inserir seu modelo selecionando a caixa de seleção.
-
Em Requisitos da Liga, selecione seu País de residência e aceite os termos e condições marcando a caixa.
-
Selecione Criar modelo para começar a criar o modelo e provisionar a instância do trabalho de treinamento.
-
Após o envio, observe seu trabalho de treinamento sendo inicializado e executado.
O processo de inicialização leva alguns minutos para alterar o status de Inicializando para Em andamento.
-
Veja o Reward graph (Gráfico de recompensas) e o Simulation video stream (Streaming do vídeo de simulação) para observar o progresso do seu trabalho de treinamento. Você pode selecionar o botão de atualização ao lado de Reward graph (Gráfico de recompensas) periodicamente para atualizar o Reward graph (Gráfico de recompensas) até que o trabalho de treinamento seja concluído.
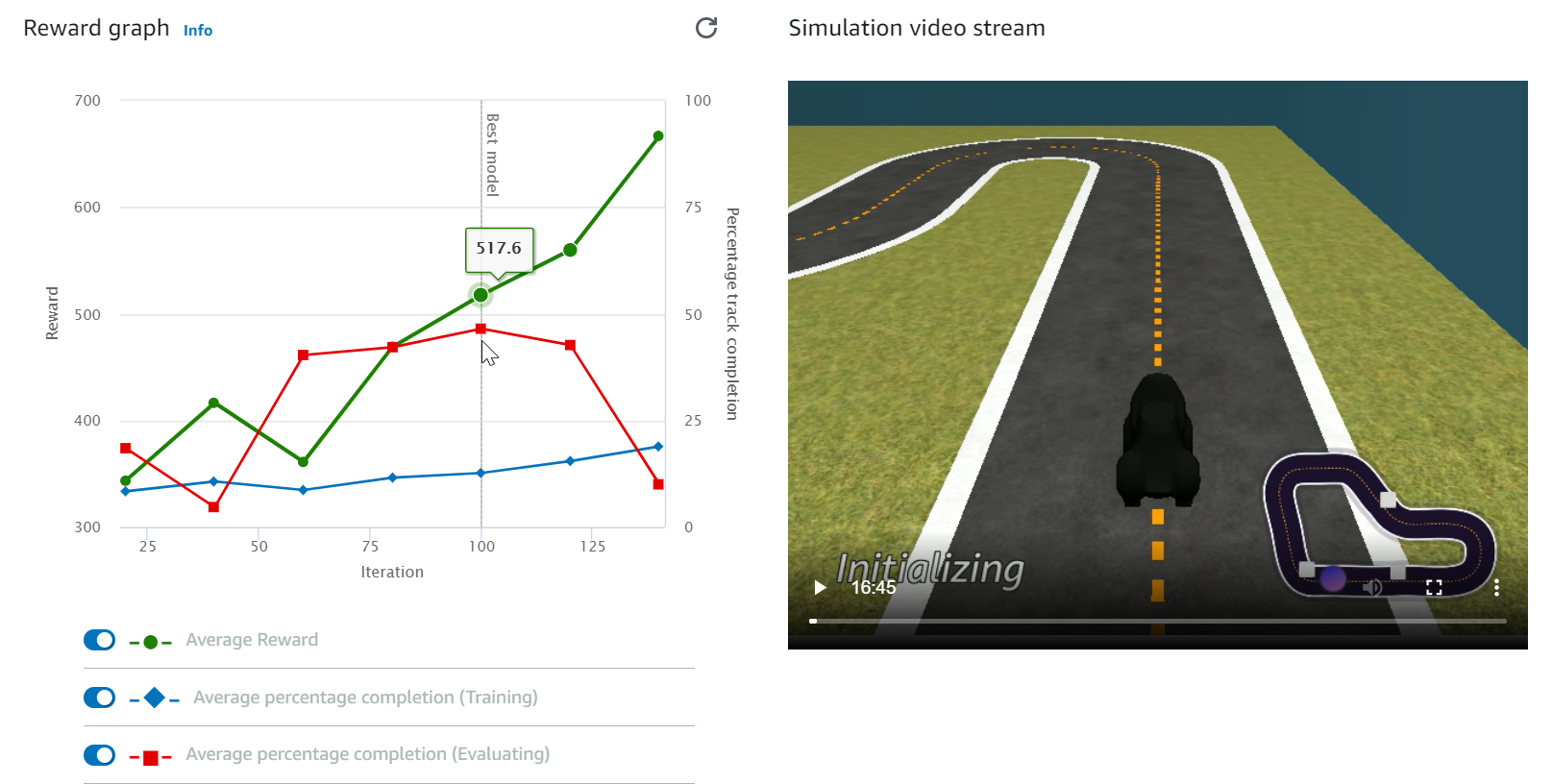
O trabalho de treinamento está sendo executado na Nuvem AWS DeepRacer, AWSportanto, você não precisa manter o console do AWS DeepRacer aberto durante o treinamento. Você pode voltar ao console para verificar seu modelo a qualquer momento enquanto o trabalho estiver em andamento.
Se a janela Streaming de vídeo de simulação ou a exibição do Gráfico de recompensas deixar de responder, atualize a página do navegador para que o andamento do treinamento seja atualizado.
