Aprimoramento de kernels com comandos magic no EMR Studio
Visão geral
O EMR Studio e os Cadernos do EMR oferecem suporte para comandos magic. Comandos Magic, ou magics, são aprimoramentos fornecidos pelo kernel do IPython para ajudar na execução e na análise dos dados. O IPython é um ambiente de shell interativo desenvolvido com Python.
O Amazon EMR também oferece suporte ao Sparkmagic, que é um pacote que fornece kernels relacionados ao Spark (kernels do PySpark, do SparkR e do Scala) com comandos magic específicos e que usa o Livy no cluster para enviar trabalhos do Spark.
Você pode usar comandos magic, desde que tenha um kernel do Python em seu Caderno do EMR. De forma semelhante, qualquer kernel relacionado ao Spark oferece suporte aos comandos do Sparkmagic.
Os comandos Magic, também chamados de magics, têm duas variedades:
-
Linhas magics: esses comandos magic são indicados por um prefixo
%único e operam em uma única linha de código. -
Células magics: esses comandos magic são indicados por um prefixo
%%duplo e operam em várias linhas de código.
Para saber todos os magics disponíveis, consulte Listar os comandos magic e Sparkmagic.
Considerações e limitações
-
O EMR Serverless não oferece suporte
%%shpara execução despark-submit. Ele não é compatível com os magics de Cadernos EMR. -
Os clusters do Amazon EMR no EKS não oferecem suporte a comandos Sparkmagicpara o EMR Studio. Isso ocorre porque os kernels Spark que você usa com endpoints gerenciados são integrados ao Kubernetes e não são suportados pelo Sparkmagic e pelo Livy. Você pode definir a configuração do Spark diretamente no objeto SparkContext como uma solução alternativa, como demonstra o exemplo a seguir.
spark.conf.set("spark.driver.maxResultSize", '6g') -
Os seguintes comandos e ações magic são proibidos pela AWS:
-
%alias -
%alias_magic -
%automagic -
%macro -
Modificar
proxy_usercom%configure -
Modificar
KERNEL_USERNAMEcom%envou%set_env
-
Listar os comandos magic e Sparkmagic
Use os seguintes comandos para listar os comandos magic disponíveis:
-
%lsmagiclista todas as funções magic disponíveis no momento. -
%%helplista as funções magic relacionadas ao Spark disponíveis no momento e fornecidas pelo pacote Sparkmagic.
Use %%configure para configurar o Spark
Um dos comandos mais úteis do Sparkmagic é o comando %%configure, que configura os parâmetros de criação da sessão. Ao usar as configurações conf, você pode definir qualquer configuração do Spark mencionada na documentação de configuração do Apache Spark
exemplo Adição de arquivo em JAR externo aos Cadernos do EMR do repositório do Maven ou do Amazon S3
Você pode usar a abordagem apresentada a seguir para adicionar uma dependência de arquivo em JAR externo a qualquer kernel relacionado ao Spark compatível com Sparkmagic.
%%configure -f {"conf": { "spark.jars.packages": "com.jsuereth:scala-arm_2.11:2.0,ml.combust.bundle:bundle-ml_2.11:0.13.0,com.databricks:dbutils-api_2.11:0.0.3", "spark.jars": "s3://amzn-s3-demo-bucket/my-jar.jar" } }
exemplo : Configuração do Hudi
Você pode usar o editor de caderno para configurar seu Caderno do EMR para usar o Hudi.
%%configure { "conf": { "spark.jars": "hdfs://apps/hudi/lib/hudi-spark-bundle.jar,hdfs:///apps/hudi/lib/spark-spark-avro.jar", "spark.serializer": "org.apache.spark.serializer.KryoSerializer", "spark.sql.hive.convertMetastoreParquet":"false" } }
Use o %%sh para executar o spark-submit
A %%sh magic executa comandos de shell em um subprocesso em uma instância do cluster anexado. Normalmente, você usaria um dos kernels relacionados ao Spark para executar aplicações do Spark em seu cluster anexado. No entanto, se desejar usar um kernel do Python para enviar uma aplicação do Spark, você pode usar a magic apresentada a seguir, substituindo o nome do bucket pelo nome do seu bucket em letras minúsculas.
%%sh spark-submit --master yarn --deploy-mode cluster s3://amzn-s3-demo-bucket/test.py
Neste exemplo, o cluster precisa de acesso ao local s3:// ou o comando falhará.amzn-s3-demo-bucket/test.py
Você pode usar qualquer comando do Linux com a %%sh magic. Se você desejar executar qualquer comando do Spark ou do YARN, use uma das seguintes opções para criar um usuário do Hadoop emr-notebook e conceder permissões ao usuário para executar os comandos:
-
Você pode criar explicitamente um novo usuário ao executar os comandos a seguir.
hadoop fs -mkdir /user/emr-notebook hadoop fs -chown emr-notebook /user/emr-notebook -
Você pode ativar a representação do usuário no Livy, que cria o usuário automaticamente. Consulte Habilitação da representação do usuário para monitorar a atividade de usuários e trabalhos do Spark Para mais informações.
Use %%display para visualizar dataframes do Spark
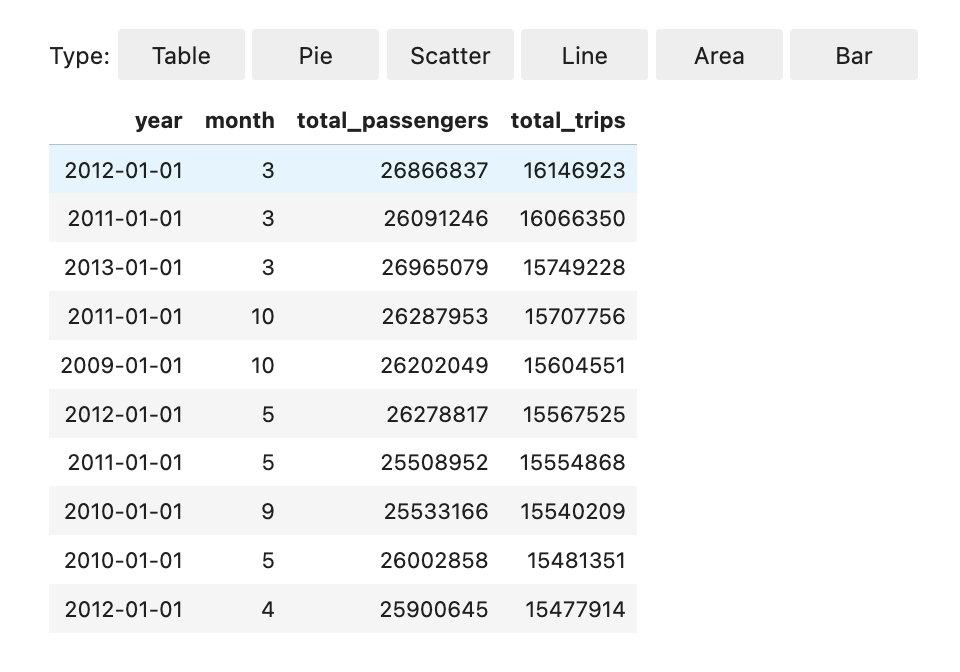
Você pode usar o %%display magic para visualizar um dataframe do Spark. Para usar essa magic, execute o comando apresentado a seguir.
%%display df
Escolha visualizar os resultados em formato de tabela, como mostra a imagem a seguir.
Você também pode optar por visualizar os dados com cinco tipos de gráficos. Suas opções incluem gráficos circular, de dispersão, de linha, de área e de barras.
Uso da magic dos Cadernos do EMR
O Amazon EMR fornece as seguintes magics dos Cadernos do EMR, que você pode usar com kernels baseados em Python3 e em Spark:
-
%mount_workspace_dir: monta seu diretório do Workspace em seu cluster para que você possa importar e executar códigos de outras aplicações em seu Workspace.nota
Com
%mount_workspace_dir, somente o kernel do Python 3 pode acessar seus sistemas de arquivos locais. Os executores do Spark não terão acesso ao diretório montado com este kernel. -
%umount_workspace_dir: desmonta seu diretório do Workspace do seu cluster. -
%generate_s3_download_url: gera um link de download temporário na saída do seu caderno para um objeto do Amazon S3.
Pré-requisitos
Antes de instalar as magics dos Cadernos do EMR, conclua as seguintes tarefas:
-
Certifique-se de que seu Perfil de serviço para instâncias do EC2 do cluster (perfil de instância do EC2) tenha acesso de leitura para o Amazon S3. O
EMR_EC2_DefaultRolecom a política gerenciadaAmazonElasticMapReduceforEC2Roleatende a esse requisito. Se você usar uma política ou um perfil personalizado, certifique-se de que ele tenha as permissões do S3 necessárias.nota
As magics dos Cadernos do EMR é executada em um cluster como o usuário do caderno e usa o perfil de instância do EC2 para interagir com o Amazon S3. Quando você monta um diretório do Workspace em um cluster do EMR, todos os Workspaces e Cadernos do EMR com permissão para serem anexados a esse cluster podem acessar o diretório montado.
Por padrão, os diretórios são montados somente para leitura. Embora
s3fs-fuseegoofyspermitam montagens de leitura e de gravação, recomendamos fortemente que você não modifique os parâmetros de montagem para montar diretórios no modo de leitura e de gravação. Se você permitir o acesso de gravação, todas as alterações realizadas no diretório serão gravadas no bucket do S3. Para evitar a exclusão ou a substituição acidentais, você pode habilitar o versionamento para seu bucket do S3. Para saber mais, consulte Usando o versionamento em buckets do S3. -
Execute um dos scripts apresentados a seguir em seu cluster para instalar as dependências para as magics dos Cadernos do EMR. Para executar um script, é possível Usar ações de bootstrap personalizadas ou seguir as instruções em Run commands and scripts on an Amazon EMR cluster quando já tiver um cluster em execução.
Você pode escolher qual dependência instalar. Tanto o s3fs-fuse
quanto o goofys são ferramentas do FUSE (Filesystem in Userspace) que permitem montar um bucket do Amazon S3 como um sistema de arquivos local em um cluster. A ferramenta s3fsoferece uma experiência semelhante à POSIX. A ferramentagoofysé uma boa opção quando você prefere performance em vez de um sistema de arquivos compatível com a POSIX.A série Amazon EMR 7.x usa o Amazon Linux 2023, que não é compatível com repositórios EPEL. Caso esteja executando o Amazon EMR 7.x, siga as instruções do s3fs-fuse do GitHub
para instalar s3fs-fuse. Caso use as séries 5.x ou 6.x, use os comandos a seguir para instalars3fs-fuse.#!/bin/sh # Install the s3fs dependency for EMR Notebooks magics sudo amazon-linux-extras install epel -y sudo yum install s3fs-fuse -yOU
#!/bin/sh # Install the goofys dependency for EMR Notebooks magics sudo wget https://github.com/kahing/goofys/releases/latest/download/goofys -P /usr/bin/ sudo chmod ugo+x /usr/bin/goofys
Instale as magics dos Cadernos do EMR
nota
Com as versões 6.0 a 6.9.0 e 5.0 a 5.36.0 do Amazon EMR, somente as versões 0.2.0 e superiores do pacote emr-notebooks-magics oferecem suporte à magic do %mount_workspace_dir.
Conclua as etapas a seguir para instalar as magics dos Cadernos do EMR.
-
Em seu caderno, execute os comandos apresentados a seguir para instalar o pacote
emr-notebooks-magics. %pip install boto3 --upgrade %pip install botocore --upgrade %pip install emr-notebooks-magics --upgrade -
Reinicie o kernel para carregar as magics dos Cadernos do EMR.
-
Verifique a instalação com o comando a seguir, que deve exibir o texto de ajuda de saída para
%mount_workspace_dir.%mount_workspace_dir?
Montagem de um diretório do Workspace com %mount_workspace_dir
A magic do %mount_workspace_dir permite montar o diretório do Workspace em seu cluster do EMR para que você possa importar e executar outros arquivos, módulos ou pacotes armazenados no diretório.
O exemplo apresentado a seguir monta todo o diretório do Workspace em um cluster e especifica o argumento opcional <--fuse-type>
%mount_workspace_dir .<--fuse-type goofys>
Para verificar se o diretório do Workspace está montado, use o exemplo a seguir para exibir o diretório de trabalho atual com o comando ls. A saída deve exibir todos os arquivos em seu Workspace.
%%sh ls
Quando você terminar de fazer as alterações no Workspace, poderá desmontar o diretório do Workspace com o seguinte comando:
nota
O diretório do Workspace permanece montado em seu cluster mesmo quando o Workspace é interrompido ou desanexado. Você deve desmontar explicitamente o diretório do Workspace.
%umount_workspace_dir
Download de um objeto do Amazon S3 com %generate_s3_download_url
O comando generate_s3_download_url cria um URL assinado previamente para um objeto armazenado no Amazon S3. Você pode usar o URL assinado previamente para fazer download do objeto em sua máquina local. Por exemplo, você pode executar generate_s3_download_url para fazer download do resultado de uma consulta SQL que seu código grava no Amazon S3.
Por padrão, o URL assinado previamente é válido por 60 minutos. Você pode alterar o tempo de expiração ao especificar um número de segundos para o sinalizador --expires-in. Por exemplo, --expires-in 1800 cria um URL válido por 30 minutos.
O exemplo apresentado a seguir gera um link de download para um objeto ao especificar o caminho completo do Amazon S3: s3://EXAMPLE-DOC-BUCKET/path/to/my/object
%generate_s3_download_urls3://EXAMPLE-DOC-BUCKET/path/to/my/object
Para saber mais sobre como usar generate_s3_download_url, execute o comando a seguir para exibir o texto de ajuda.
%generate_s3_download_url?
Execução de um caderno no modo descentralizado com %execute_notebook
Com a magic do %execute_notebook, você pode executar outro caderno no modo descentralizado e visualizar a saída de cada célula executada. Essa magic requer permissões adicionais para o perfil de instância que o Amazon EMR e o Amazon EC2 compartilham. Para obter mais detalhes sobre como conceder permissões adicionais, execute o comando %execute_notebook?.
Durante um trabalho de execução prolongada, seu sistema pode entrar em repouso devido à inatividade ou pode perder temporariamente a conectividade com a Internet. Isso pode interromper a conexão entre o seu navegador e o servidor Jupyter. Nesse caso, você poderá perder a saída das células que executou e enviou usando o servidor Jupyter.
Se você executar o caderno no modo descentralizado com a magic do %execute_notebook, os Cadernos do EMR capturarão a saída das células que foram executadas, mesmo se a rede local sofrer interrupções. Os Cadernos do EMR salvam a saída de forma incremental em um novo caderno com o mesmo nome do caderno que você executou. Em seguida, os Cadernos do EMR colocam o caderno em uma nova pasta no Workspace. As execuções descentralizadas ocorrem no mesmo cluster e usam o perfil de serviço EMR_Notebook_DefaultRole, mas argumentos adicionais podem alterar os valores padrão.
Para executar um caderno no modo descentralizado, use o seguinte comando:
%execute_notebook<relative-file-path>
Para especificar um ID de cluster e um perfil de serviço para uma execução descentralizada, use o seguinte comando:
%execute_notebook<notebook_name>.ipynb --cluster-id <emr-cluster-id> --service-role <emr-notebook-service-role>
Quando o Amazon EMR e o Amazon EC2 compartilham um perfil de instância, o perfil requer as seguintes permissões adicionais:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "elasticmapreduce:StartNotebookExecution", "elasticmapreduce:DescribeNotebookExecution", "ec2:DescribeInstances" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": "arn:aws:iam::<AccoundId>:role/EMR_Notebooks_DefaultRole" } ] }
nota
Para usar a magic do %execute_notebook, instale a versão 0.2.3 ou superior do pacote emr-notebooks-magics.
