As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
desempenho do Amazon FSx para Lustre
Este capítulo fornece tópicos de desempenho do Amazon FSx para Lustre, incluindo algumas dicas e recomendações importantes para maximizar o desempenho do seu sistema de arquivos.
Tópicos
Visão geral do
O Amazon FSx para Lustre, desenvolvido no Lustre, o popular sistema de arquivos de alto desempenho, oferece desempenho com aumento horizontal da escala que aumenta linearmente com o tamanho do sistema de arquivos. Os sistemas de arquivos do Lustre escalam horizontalmente entre vários discos e servidores de arquivos. Essa escalabilidade disponibiliza a todos os clientes o acesso direto aos dados armazenados em cada disco para remover muitos dos gargalos presentes nos sistemas de arquivos tradicionais. O Amazon FSx para Lustre se baseia na arquitetura escalável do Lustre para oferecer suporte a altos níveis de desempenho para um grande número de clientes.
Como funcionam os sistemas de arquivos do FSx para Lustre
Cada sistema de arquivos do FSx para Lustre consiste nos servidores de arquivos com os quais os clientes se comunicam e em um conjunto de discos anexados a cada servidor de arquivos que armazena seus dados. Cada servidor de arquivos emprega um cache em memória rápido para aprimorar a desempenho dos dados acessados com mais frequência. Dependendo da classe de armazenamento, seu servidor de arquivos pode ser provisionado com um cache de leitura do SSD opcional. Quando um cliente acessa dados que estão armazenados na memória ou no cache baseado em SSD, o servidor de arquivos não precisa lê-los usando o disco, o que reduz a latência e aumenta a quantidade total de throughput que você pode gerar. O diagrama a seguir ilustra os caminhos de uma operação de gravação, uma operação de leitura atendida usando o disco e uma operação de leitura atendida usando a memória ou o cache baseado em SSD.
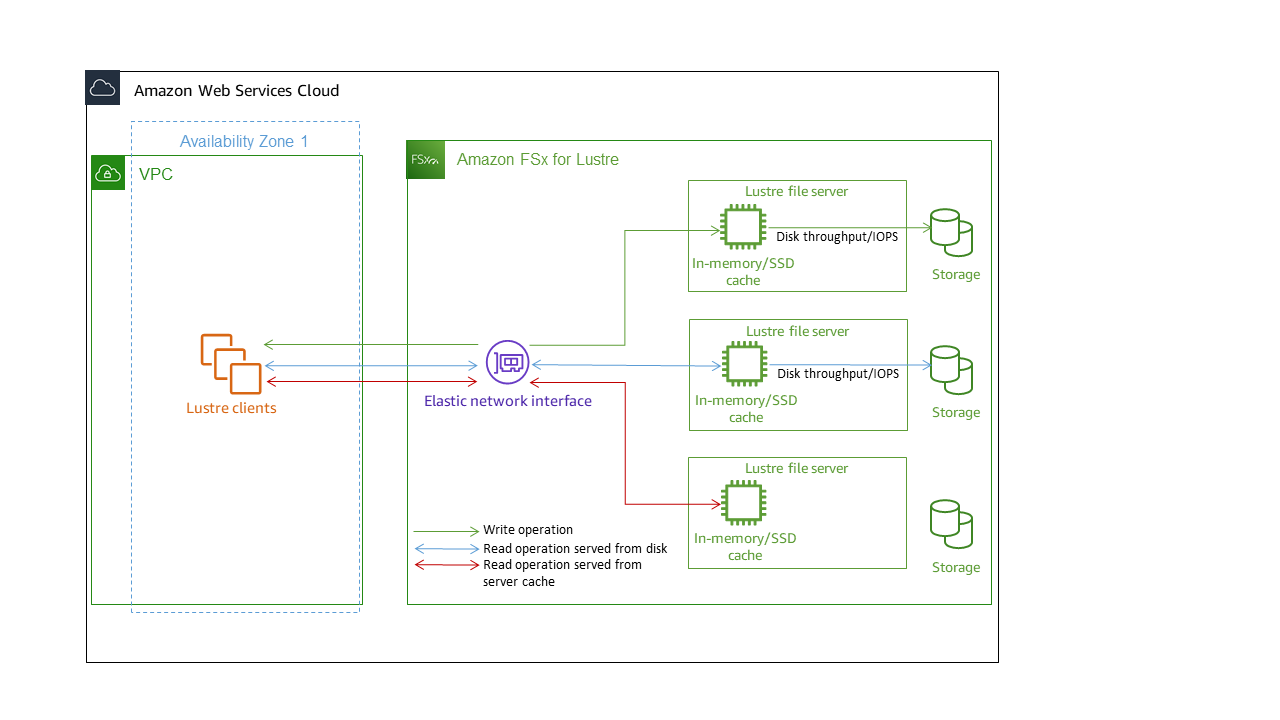
Quando você realiza a leitura de dados armazenados na memória ou no cache baseado em SSD do servidor de arquivos, a performance do sistema de arquivos é determinada pelo throughput da rede. Quando você grava dados no sistema de arquivos ou quando realiza a leitura de dados que não estão armazenados no cache em memória, a desempenho do sistema de arquivos é determinada pelo menor throughput da rede e do disco.
Para saber mais sobre o throughput de rede, o throughput de disco e as características de IOPS das classes de armazenamento SSD e HDD, consulte Características de desempenho das classes de armazenamento SSD e HDD e Características de desempenho da classe Intelligent-Tiering de armazenamento.
Desempenho de metadados do sistema de arquivos
As operações de E/S por segundo (IOPS) de metadados do sistema de arquivos determinam o número de arquivos e diretórios que você pode criar, listar, ler e excluir por segundo.
Os sistemas de arquivos Persistent 2 permitem que você provisione IOPS de metadados independentemente da capacidade de armazenamento e promova maior visibilidade sobre o número e o tipo de IOPS de metadados que as instâncias de cliente estão gerando em seu sistema de arquivos. Com sistemas de arquivos em SSD, as IOPS de metadados são provisionadas automaticamente com base na capacidade de armazenamento que você provisiona. O modo automático não é suportado em sistemas de Intelligent-Tiering arquivos.
Com os sistemas de arquivos Persistent 2 do FSx para Lustre, o número de IOPS de metadados que você provisiona e o tipo de operação de metadados determinam a taxa de operações de metadados que seu sistema de arquivos pode atender. O nível de IOPS de metadados que você provisiona determina o número de IOPS provisionadas para os discos de metadados do seu sistema de arquivos.
| Tipo de operação | Operações que você pode conduzir por segundo para cada IOPS de metadados provisionadas |
|---|---|
|
Criar, abrir e fechar arquivos |
2 |
|
Excluir arquivo |
1 |
|
Criar e renomear diretórios |
0.1 |
|
Exclusão de diretório |
0.2 |
Para sistemas de arquivos SSD, você pode optar por provisionar IOPS de metadados com o modo automático. No modo Automático, o Amazon FSx provisiona automaticamente IOPS de metadados com base na capacidade de armazenamento do seu sistema de arquivos, de acordo com a tabela abaixo:
| Capacidade de armazenamento do sistema de arquivos | IOPS de metadados incluídos no modo automático |
|---|---|
|
1.200 GiB |
1500 |
|
2.400 GiB |
3000 |
|
4.800 a 9.600 GiB |
6000 |
|
12 mil a 45.600 GiB |
12000 |
|
≥ 48000 GiB |
12 mil IOPS por 24 mil GiB |
No User-provisioned modo, você pode optar por especificar o número de IOPS de metadados a serem provisionados. Os valores válidos são os seguintes:
Para sistemas de arquivos SSD, os valores válidos são
1500,3000,6000,12000e múltiplos de12000, até um máximo de192000.Para sistemas de Intelligent-Tiering arquivos, os valores válidos são
600012000e.
Para obter informações sobre como configurar IOPS de metadados, consulte Como gerenciar desempenho de metadados. Observe que você paga pelas IOPS de metadados provisionadas acima do número padrão de IOPS de metadados para seu sistema de arquivos.
Throughput para instâncias individuais de clientes
Se você estiver criando um sistema de arquivos com mais de 10 GBps de capacidade de throughput, recomendamos habilitar o Elastic Fabric Adapter (EFA) para otimizar o throughput por instância do cliente. Para otimizar ainda mais a taxa de transferência por instância do cliente, os sistemas de EFA-enabled arquivos também oferecem suporte ao GPUDirect Storage para instâncias GPU-based do cliente EFA-enabled NVIDIA e ao ENA Express para instâncias do cliente ENA. Express-enabled
O throughput que você pode direcionar para uma única instância do cliente depende da escolha do tipo de sistema de arquivos e da interface de rede na instância do cliente.
| Tipo do sistema de arquivos | Interface de rede de instâncias de clientes | O throughput máximo por cliente, Gigabits por segundo (GBps) |
|---|---|---|
|
Não EFA-enabled |
Any |
100 Gbps* |
|
EFA-enabled |
ENA |
100 Gbps* |
|
EFA-enabled |
ENA Express |
100 Gbps |
|
EFA-enabled |
EFA |
700 Gbps |
|
EFA-enabled |
EFA com GDS |
1200 Gbps |
nota
* O tráfego entre uma instância individual de cliente e um servidor individual de armazenamento de objetos do FSx para Lustre limita-se a 5 Gbps. Consulte Endereços IP para sistemas de arquivos para saber o número de servidores de armazenamento de objetos que sustentam seu sistema de arquivos do FSx para Lustre.
Layout de armazenamento do sistema de arquivos
Todos os dados de arquivos no Lustre são armazenados em volumes de armazenamento chamados destinos de armazenamento de objetos (OSTs). Todos os metadados de arquivos, incluindo nomes de arquivos, carimbos de data/hora, permissões e muito mais, são armazenados em volumes de armazenamento chamados destinos de metadados (MDTs). Os sistemas de arquivos do Amazon FSx para Lustre são compostos por um ou mais MDTs e vários OSTs. O Amazon FSx para Lustre distribui os dados de arquivos pelos OSTs que compõem o sistema de arquivos para equilibrar a capacidade de armazenamento com o throughput e a carga de IOPS.
Para visualizar o uso de armazenamento do MDT e dos OSTs que compõem o sistema de arquivos, execute o comando apresentado a seguir em um cliente que tenha o sistema de arquivos montado.
lfs df -hmount/path
A saída deste comando é semelhante à apresentada a seguir.
exemplo
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
Distribuição de dados no sistema de arquivos
É possível otimizar a performance de throughput do seu sistema de arquivos com a distribuição de arquivos. O Amazon FSx para Lustre distribui automaticamente os arquivos entre os OSTs para garantir que os dados sejam fornecidos por todos os servidores de armazenamento. Você pode aplicar um conceito semelhante no nível do arquivo ao configurar como os arquivos são distribuídos em diversos OSTs.
O termo “distribuição” indica que os arquivos podem ser divididos em diversos fragmentos que são armazenados em diferentes OSTs. Quando um arquivo é distribuído em diversos OSTs, as solicitações de leitura ou de gravação para o arquivo são distribuídas por esses OSTs, aumentando o throughput agregado ou a IOPS que as aplicações podem gerar por meio dele.
A seguir, são apresentados os layouts padrão para sistemas de arquivos do Amazon FSx para Lustre.
Para sistemas de arquivos criados antes de 18 de dezembro de 2020, o layout padrão especifica uma contagem de distribuição de um. Isso significa que, a menos que um layout diferente seja especificado, cada arquivo criado no Amazon FSx para Lustre usando ferramentas padrão do Linux será armazenado em um único disco.
Para sistemas de arquivos criados após 18 de dezembro de 2020, o layout padrão corresponde a um layout de arquivos progressivo, no qual arquivos com tamanhos inferiores a 1 GiB são armazenados em uma distribuição e arquivos com tamanhos superiores são atribuídos a uma contagem de distribuição de cinco.
Para sistemas de arquivos criados após 25 de agosto de 2023, o layout padrão corresponde a um layout de arquivos progressivo de quatro componentes, o qual é explicado em Layouts de arquivos progressivos.
Para todos os sistemas de arquivos, independentemente da data de criação, os arquivos importados do Amazon S3 não usam o layout padrão, mas usam o layout no parâmetro do sistema de
ImportedFileChunkSizearquivos. S3-imported arquivos maiores que oImportedFileChunkSizeserão armazenados em vários OSTs com uma contagem de faixas de.(FileSize / ImportedFileChunksize) + 1O valor padrão deImportedFileChunkSizeé 1 GiB.
É possível visualizar a configuração de layout de um arquivo ou de um diretório usando o comando lfs getstripe.
lfs getstripepath/to/filename
Este comando informa a contagem de distribuição, o tamanho da distribuição e o deslocamento da distribuição de um arquivo. A contagem de distribuição corresponde ao número de OSTs para os quais o arquivo é distribuído. O tamanho da distribuição corresponde à quantidade de dados contínuos que são armazenados em um OST. O deslocamento da distribuição corresponde ao índice do primeiro OST para o qual o arquivo é distribuído.
Modificação da configuração de distribuição
Os parâmetros de layout de um arquivo são definidos quando o arquivo é criado pela primeira vez. Use o comando lfs setstripe para criar um arquivo novo e em branco com um layout especificado.
lfs setstripefilename--stripe-countnumber_of_OSTs
O comando lfs setstripe afeta somente o layout de um novo arquivo. Use-o para especificar o layout de um arquivo antes de criá-lo. Você também pode definir um layout para um diretório. Após ser definido em um diretório, esse layout é aplicado a cada novo arquivo adicionado ao diretório, mas não aos arquivos existentes. Qualquer novo subdiretório criado também herdará o novo layout, que será aplicado a qualquer novo arquivo ou diretório criado nesse subdiretório.
Para modificar o layout de um arquivo existente, use o comando lfs migrate. Este comando copia o arquivo, conforme necessário, para distribuir o conteúdo de acordo com o layout especificado no comando. Por exemplo, arquivos anexados ou aumentados em tamanho não alteram a contagem de distribuição, portanto, é necessário migrá-los para alterar o layout do arquivo. Como alternativa, é possível criar um novo arquivo usando o comando lfs setstripe para especificar o layout, copiar o conteúdo original para o novo arquivo e, em seguida, renomear o novo arquivo para substituir o arquivo original.
Pode haver casos em que a configuração de layout padrão não seja ideal para a workload. Por exemplo, um sistema de arquivos com dezenas de OSTs e um grande número de arquivos de vários gigabytes pode obter uma performance superior ao realizar a distribuição dos arquivos para mais do que o valor de contagem de distribuição padrão de cinco OSTs. Criar arquivos grandes com baixa contagem de faixas pode causar gargalos de I/O desempenho e também fazer com que os OSTs sejam preenchidos. Nesse caso, você pode criar um diretório com uma contagem de distribuição maior para esses arquivos.
Configurar um layout distribuído para arquivos grandes (especialmente arquivos maiores que um gigabyte) é importante pelos seguintes motivos:
Aprimora o throughput ao permitir que vários OSTs e seus servidores associados contribuam com IOPS, largura de banda da rede e recursos de CPU ao ler e gravar arquivos grandes.
Reduz a probabilidade de que um pequeno subconjunto de OSTs se torne um ponto de acesso que limita a performance geral da workload.
Impede que um único arquivo grande preencha um OST, possivelmente causando erros de disco cheio.
Não existe uma configuração única de layout que seja ideal para todos os casos de uso. Para obter orientações detalhadas sobre layouts de arquivo, consulte Gerenciando o layout do arquivo (distribuição) e o espaço livre
O layout distribuído é mais importante para arquivos grandes, especialmente para casos de uso em que os arquivos têm regularmente centenas de megabytes ou mais. Por esse motivo, o layout padrão para um novo sistema de arquivos atribui uma contagem de distribuição de cinco para arquivos com tamanho superior a 1 GiB.
A contagem de distribuição é o parâmetro de layout que você deve ajustar para sistemas que oferecem suporte a arquivos grandes. A contagem de distribuição especifica o número de volumes de OST que conterão fragmentos de um arquivo distribuído. Por exemplo, com uma contagem de distribuição de 2 e um tamanho da distribuição de 1 MiB, o Lustre grava fragmentos alternativos de 1 MiB de um arquivo em cada um dos 2 OSTs.
A contagem de distribuição efetiva corresponde ao menor número entre o número real de volumes de OST e o valor de contagem de distribuição especificado. É possível usar o valor especial de contagem de distribuição de
-1para indicar que as distribuições devem ser colocadas em todos os volumes de OST.A definição de uma contagem de distribuição grande para arquivos pequenos não é ideal, pois para algumas operações, o Lustre requer idas e vindas da rede para cada OST no layout, mesmo que o arquivo seja muito pequeno para consumir espaço em todos os volumes de OST.
Você pode configurar um layout de arquivo progressivo (PFL) que permite que o layout de um arquivo seja alterado com o tamanho. Uma configuração de PFL pode simplificar o gerenciamento de um sistema de arquivos que tem uma combinação de arquivos grandes e pequenos sem que você tenha necessidade de definir explicitamente uma configuração para cada arquivo. Para obter mais informações, consulte Layouts de arquivos progressivos.
Por padrão, o tamanho da distribuição é 1 MiB. A definição de um deslocamento de distribuição pode ser útil em circunstâncias especiais, mas, em geral, é melhor deixá-lo sem especificação e usar o padrão.
Layouts de arquivos progressivos
É possível especificar uma configuração de layout de arquivo progressivo (PFL) para um diretório com a finalidade de especificar diferentes configurações de distribuição para arquivos pequenos e grandes antes de preenchê-lo. Por exemplo, você pode definir um PFL no diretório de nível superior antes que os dados sejam gravados em um novo sistema de arquivos.
Para especificar uma configuração de PFL, use o comando lfs setstripe com opções -E para especificar componentes de layout para arquivos de tamanhos diferentes, como o seguinte comando:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
Este comando define quatro componentes de layout:
O primeiro componente (
-E 100M -c 1) indica um valor de contagem de distribuição de 1 para arquivos de até 100 MiB de tamanho.O segundo componente (
-E 10G -c 8) indica uma contagem de distribuição de 8 para arquivos de até 10 GiB de tamanho.O terceiro componente (
-E 100G -c 16) indica uma contagem de distribuição de 16 para arquivos de até 100 GiB de tamanho.O quarto componente (
-E -1 -c 32) indica uma contagem de distribuição de 32 para arquivos com tamanho superior a 100 GiB.
Importante
Anexar dados a um arquivo criado com um layout PFL preencherá todos os componentes do layout. Por exemplo, com o comando de quatro componentes mostrado acima, se você criar um arquivo de 1 MiB e, em seguida, adicionar dados ao final dele, o layout do arquivo será ampliado para ter uma contagem de faixas de -1, ou seja, abrangendo todos os OSTs no sistema. Isso não significa que os dados serão gravados em cada OST, mas uma operação, por exemplo, a leitura do tamanho do arquivo, enviará uma solicitação paralelamente a cada OST, adicionando uma carga de rede significativa ao sistema de arquivos.
Portanto, tome cuidado em relação a limitar a contagem de distribuição para qualquer arquivo pequeno ou médio que possa, posteriormente, ter dados anexados a ele. Como os arquivos de log geralmente são desenvolvidos com a adição de novos registros, o Amazon FSx para Lustre atribui uma contagem de distribuição padrão de um a qualquer arquivo criado no modo de acréscimo, independentemente da configuração de distribuição padrão especificada pelo diretório primário.
A configuração de PFL padrão nos sistemas de arquivos do Amazon FSx para Lustre criados após 25 de agosto de 2023 é definida com este comando:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
Os clientes com workloads que têm acesso com alta simultaneidade a arquivos médios e grandes, provavelmente, serão beneficiados com um layout com mais distribuições em tamanhos menores e distribuição em todos os OSTs para os arquivos maiores, conforme mostrado no exemplo de layout de quatro componentes.
Monitoramento da performance e do uso
A cada minuto, o Amazon FSx for Lustre emite métricas de uso de cada disco (MDT e OST) para a Amazon. CloudWatch
Para visualizar detalhes agregados de uso do sistema de arquivos, é possível consultar a estatística Sum de cada métrica. Por exemplo, a estatística Sum de DataReadBytes relata o throughput total de leitura visto por todos os OSTs em um sistema de arquivos. De forma semelhante, a estatística Sum de FreeDataStorageCapacity relata a capacidade total de armazenamento disponível para dados de arquivos no sistema de arquivos.
Para obter mais informações sobre como monitorar a desempenho do sistema de arquivos, consulte Monitorar sistemas de arquivos do Amazon FSx para Lustre.
