Conexões do Redshift
Você pode usar o AWS Glue para Spark para ler e gravar tabelas nos bancos de dados do Amazon Redshift. Ao se conectar aos bancos de dados do Amazon Redshift, o AWS Glue move dados pelo Amazon S3 para obter o throughput máximo usando os comandos COPY e UNLOAD do Amazon Redshift SQL. No AWS Glue 4.0 e posteriores, você pode usar a integração do Amazon Redshift para Apache Spark para ler e gravar com otimizações e atributos específicos do Amazon Redshift além dos disponíveis ao fazer a conexão por meio das versões anteriores.
Saiba como o AWS Glue está tornando mais fácil do que nunca para os usuários do Amazon Redshift migrar para o AWS Glue para integração de dados e ETL com tecnologia sem servidor.
Configurar conexões do Redshift
Para usar clusters do Amazon Redshift no AWS Glue, você precisará de alguns pré-requisitos:
-
Um diretório do Amazon S3 a ser usado para armazenamento temporário ao ler e gravar no banco de dados.
-
Uma Amazon VPC que permita a comunicação entre o cluster do Amazon Redshift, o trabalho do AWS Glue e o diretório do Amazon S3.
-
Permissões apropriadas do IAM no trabalho do AWS Glue e no cluster do Amazon Redshift.
Configurar perfis do IAM
Configurar o perfil para o cluster do Amazon Redshift
O cluster do Amazon Redshift precisa poder ler e gravar no Amazon S3 para se integrar com os trabalhos do AWS Glue. Para permitir isso, você pode associar perfis do IAM ao cluster do Amazon Redshift ao qual você deseja se conectar. Seu perfil deve ter uma política que permita ler e gravar no diretório temporário do Amazon S3. Seu perfil deve ter uma relação de confiança que permita ao serviço redshift.amazonaws.com AssumeRole.
Para associar um perfil do IAM ao Amazon Redshift
Pré-requisitos: um bucket ou diretório do Amazon S3 usado para o armazenamento temporário de arquivos.
-
Identifique quais permissões do Amazon S3 o cluster do Amazon Redshift precisará ter. Ao mover dados entre um cluster do Amazon Redshift, os trabalhos do AWS Glue emitem instruções COPY e UNLOAD no Amazon Redshift. Se o trabalho modificar uma tabela no Amazon Redshift, o AWS Glue também emitirá instruções CREATE LIBRARY. Para obter informações sobre as permissões específicas do Amazon S3 necessárias para o Amazon Redshift executar essas instruções, consulte a documentação do Amazon Redshift: Amazon Redshift: Permissões para acessar outros recursos da AWS.
No console do IAM, crie uma política do IAM com as permissões necessárias. Para obter informações sobre a criação de uma política, consulte Criação de políticas do IAM.
No console do IAM, crie um perfil e uma relação de confiança que permita ao Amazon Redshift assumir o perfil. Siga as instruções na documentação do IAM Para criar um perfil para um serviço da AWS (console)
Quando solicitado a escolher um caso de uso de um serviço da AWS, escolha "Redshift: personalizável".
Quando solicitado a anexar uma política, escolha a política que você definiu anteriormente.
nota
Para obter mais informações sobre a configuração de perfis para o Amazon Redshift, consulte Autorizar o Amazon Redshift a acessar outros serviços da AWS em seu nome na documentação do Amazon Redshift.
No console do Amazon Redshift, associe o perfil ao seu cluster do Amazon Redshift. Siga as instruções na documentação do Amazon Redshift.
Selecione a opção realçada no console do Amazon Redshift para definir esta configuração:
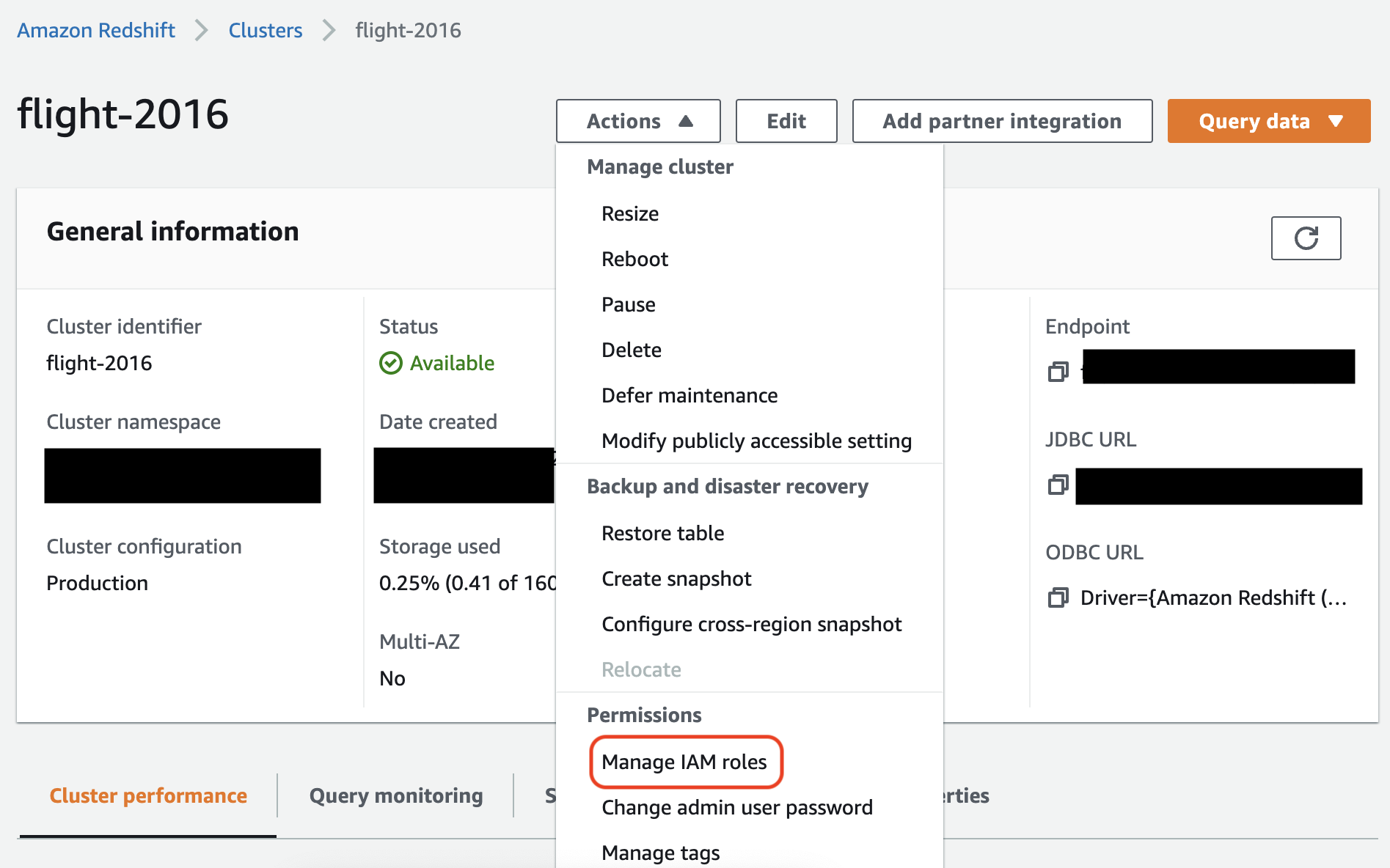
nota
Por padrão, o AWS Glue transmite credenciais temporárias do Amazon Redshift que são criadas usando o perfil que você especificou para executar o trabalho. Não recomendamos usar esses parâmetros para especificar credenciais. Por motivos de segurança, essas credenciais expiram após 1 hora.
Configurar o perfil para o trabalho do AWS Glue
O trabalho do AWS Glue precisa de um perfil para acessar o bucket do Amazon S3. Você não precisa de permissões do IAM para o cluster do Amazon Redshift, seu acesso é controlado pela conectividade no Amazon VPC e por suas credenciais do banco de dados.
Configurar a Amazon VCP
Para configurar o acesso aos armazenamentos de dados do Amazon Redshift
Faça login no AWS Management Console e abra o console do Amazon Redshift em https://console.aws.amazon.com/redshiftv2/
. -
No painel de navegação à esquerda, escolha Clusters.
-
Escolha o nome de cluster que você deseja acessar no AWS Glue.
-
Na seção Cluster Properties (Propriedades do cluster), escolha um grupo de segurança em VPC security groups (Grupos de segurança da VPC) para permitir que o AWS Glue o utilize. Anote o nome do security group que você escolheu para referência futura. Escolher o grupo de segurança abre a lista Security Groups (Grupos de segurança) do console do Amazon EC2.
-
Escolha o security group a ser modificado e navegue até a guia Inbound.
-
Adicione uma regra de autorreferência para permitir que os componentes do AWS Glue se comuniquem. Especificamente, adicione ou confirme que existe uma regra de Type
All TCP, que Protocol éTCP, Port Range inclui todas as portas e Source e Group ID apresentam o mesmo nome de security group.O regra de entrada tem aparência semelhante a esta:
Tipo Protocolo Intervalo de portas Origem Todos os TCP
TCP
0–65535
database-security-group
Por exemplo:
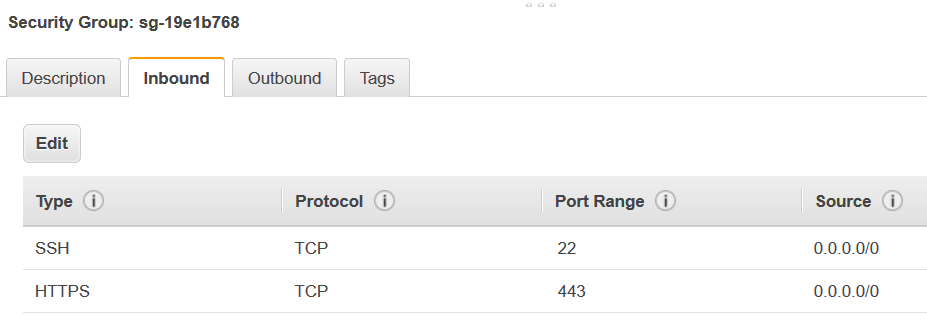
-
Adicione também uma regra para o tráfego de saída. Abra o tráfego de saída a todas as portas, por exemplo:
Tipo Protocolo Intervalo de portas Destino Todo o tráfego
ALL
ALL
0.0.0.0/0
Ou crie uma regra de autorreferência em que Type (Tipo) é
All TCP, Protocol (Protocolo) éTCP, Port Range (Intervalo de portas) inclui todas as portas e cujo Destination (Destino) é o mesmo nome de security group de Group ID (ID de grupo). Se você estiver usando um endpoint da VPC do Amazon S3, adicione também uma regra HTTPS para acesso ao Amazon S3. Os3-prefix-list-idé necessário na regra do grupo de segurança para permitir o tráfego da VPC para o endpoint da VPC do Amazon S3.Por exemplo:
Tipo Protocolo Intervalo de portas Destino Todos os TCP
TCP
0–65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
Configurar o AWS Glue
Você precisará criar uma conexão do catálogo de dados do AWS Glue que forneça informações de conexão com a Amazon VPC.
Para configurar a conectividade da Amazon VPC do Amazon Redshift com o AWS Glue no console
-
Crie uma conexão do catálogo de dados seguindo as etapas em:Adicionar uma conexão do AWS Glue. Depois de criar a conexão, guarde o nome da conexão,
connectionName, para a próxima etapa.Ao selecionar um tipo de conexão, selecione Amazon Redshift.
Ao selecionar um cluster do Redshift, selecione seu cluster pelo nome.
Forneça informações de conexão padrão para um usuário do Amazon Redshift em seu cluster.
As configurações do Amazon VPC serão definidas automaticamente.
nota
Você precisará fornecer
PhysicalConnectionRequirementsmanualmente para a Amazon VPC ao criar uma conexão do Amazon Redshift por meio do SDK da AWS. -
Na configuração do trabalho do AWS Glue, forneça
connectionNamecomo uma conexão de rede adicional.
Exemplo: leitura de tabelas do Amazon Redshift
Você pode ler nos clusters do Amazon Redshift e ambientes do Amazon Redshift sem servidor.
Pré-requisitos: uma tabela do Amazon Redshift que você deseja ler. Siga as etapas da seção anterior Configurar conexões do Redshift e, depois disso, você deverá ter o URI do Amazon S3 para um diretório temporário, ).temp-s3-dir, e um perfil do IAM, rs-role-name, (na conta role-account-id
Exemplo: gravaçr em tabelas do Amazon Redshift
Você pode ler dos clusters do Amazon Redshift e em ambientes do Amazon Redshift sem servidor.
Pré-requisitos: um cluster do Amazon Redshift e siga as etapas da seção anterior. Configurar conexões do Redshift. Depois disso, você deverá ter o URI do Amazon S3 para um diretório temporário, temp-s3-dir e um perfil do IAM, rs-role-name, (na conta role-account-id). Você também precisará de um DynamicFrame cujo conteúdo você deseja gravar no banco de dados.
Referência da opções de conexão do Amazon Redshift
As opções básicas de conexão usadas em todas as conexões JDBC do AWS Glue para configurar informações como url, user e password são consistentes em todos os tipos de JDBC. Para obter mais informações sobre os parâmetros padrão de JDBC consulte Referência de opções de conexão JDBC.
O tipo de conexão do Amazon Redshift tem algumas opções adicionais de conexão:
-
"redshiftTmpDir": (obrigatório) o caminho do Amazon S3 onde dados temporários podem ser preparados ao serem copiados para fora do banco de dados. -
"aws_iam_role": (opcional) o ARN de um perfil do IAM. O trabalho AWS Glue passará esse perfil para o cluster do Amazon Redshift para conceder ao cluster as permissões necessárias para concluir as instruções do trabalho.
Opções adicionais de conexão disponíveis no AWS Glue 4.0+
Você também pode transmitir opções para o novo conector do Amazon Redshift por meio das opções de conexão do AWS Glue. Para obter uma lista completa das opções de conectores compatíveis, consulte a seção de Parâmetros do Spark SQL em Amazon Redshift integration for Apache Spark (Integração do Amazon Redshift for Apache Spark).
Para sua conveniência, reiteramos algumas novas opções aqui:
| Nome | Obrigatório | Padrão | Descrição |
|---|---|---|---|
| autopushdown |
Não | VERDADEIRO | Aplica pushdown de predicados e consultas capturando e analisando os planos lógicos do Spark para operações SQL. As operações são traduzidas em uma consulta SQL e executadas no Amazon Redshift para melhorar a performance. |
| autopushdown.s3_result_cache |
Não | FALSE | Armazena a consulta SQL para descarregar dados do mapeamento de caminhos do Amazon S3 na memória para que a mesma consulta não precise ser executada novamente na mesma sessão do Spark. Só é possível quando o |
| unload_s3_format |
Não | PARQUET | PARQUET - descarrega os resultados da consulta no formato Parquet. TEXT - descarrega os resultados da consulta em formato de texto delimitado por barras. |
| sse_kms_key |
Não | N/D | A chave do AWS SSE-KMS a ser usada para criptografia durante as operações, de |
| extracopyoptions |
Não | N/D | Uma lista de opções extras para anexar ao comando Observe que, como essas opções são anexadas ao fim do comando |
| csvnullstring (experimental) |
Não | NULL | O valor da string a ser gravado para nulos ao usar o |
Esses novos parâmetros podem ser usados como se segue.
Novas opções para melhoria de performance
O novo conector introduz algumas novas opções de melhoria de performance:
-
autopushdown: habilitado por padrão. -
autopushdown.s3_result_cache: desabilitado por padrão. -
unload_s3_format:PARQUETpor padrão.
Para obter informações sobre como usar essas opções, consulte Amazon Redshift integration for Apache Spark (Integração do Amazon Redshift for Apache Spark). Recomendamos que você não ative o
autopushdown.s3_result_cache quando tiver operações mistas de leitura e gravação, pois os resultados em cache podem conter informações obsoletas. A opção unload_s3_format é definida como PARQUET por padrão para o comando UNLOAD, para melhorar a performance e reduzir o custo de armazenamento. Para usar o comportamento padrão do comando UNLOAD, redefina a opção como TEXT.
Nova opção de criptografia para leitura
Por padrão, os dados na pasta temporária usada pelo AWS Glue ao ler dados da tabela do Amazon Redshift são criptografados usando a criptografia SSE-S3. Para usar as chaves gerenciadas pelo cliente do AWS Key Management Service (AWS KMS) para criptografar dados, você pode configurar ("sse_kms_key"
→ kmsKey) em que ksmKey é a ID da chave do AWS KMS, em vez da opção de configuração antiga ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") no AWS Glue versão 3.0.
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
Compatibilidade com a URL JDBC baseada no IAM
O novo conector é compatível com uma URL JDBC baseada no IAM para que você não precise passar um usuário/senha ou um segredo. Com uma URL JDBC baseada no IAM, o conector usa o perfil de runtime de trabalho para acessar a fonte de dados do Amazon Redshift.
Etapa 1: anexar a seguinte política mínima exigida ao perfil de runtime AWS Glue.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": [ "arn:aws:redshift:<region>:<account>:dbgroup:<cluster name>/*", "arn:aws:redshift:*:<account>:dbuser:*/*", "arn:aws:redshift:<region>:<account>:dbname:<cluster name>/<database name>" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "redshift:DescribeClusters", "Resource": "*" } ] }
Etapa 2: usar a URL do JDBC baseado em IAM como se segue. Especifique uma nova opção DbUser com o nome de usuário do Amazon Redshift com o qual você está se conectando.
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
nota
Atualmente, um DynamicFrame é compatível apenas com uma URL JDBC baseada no IAM com um
DbUser no fluxo de trabalho GlueContext.create_dynamic_frame.from_options.
Migrar do AWS Glue versão 3.0 para a versão 4.0
No AWS Glue 4.0, trabalhos de ETL têm acesso a um novo conector do Amazon Redshift Spark e um novo driver JDBC com opções e configurações diferentes. O novo conector e o novo driver do Amazon Redshift foram criados pensando em performance e mantêm a consistência transacional dos dados. Esses produtos estão documentados na documentação do Amazon Redshift. Para obter mais informações, consulte:
Restrição de nomes e identificadores de tabelas/colunas
O novo conector e driver do Amazon Redshift Spark têm um requisito mais restrito para o nome da tabela do Redshift. Para obter mais informações, consulte Nomes e identificadores para definir o nome da tabela do Amazon Redshift. O fluxo de trabalho de marcadores de trabalho pode não funcionar com um nome de tabela que não corresponda às regras e com determinados caracteres, como espaço.
Se você tiver tabelas antigas com nomes que não estão em conformidade com as regras de nomes e identificadores e tiver problemas com marcadores (trabalhos que reprocessam dados de tabelas antigas do Amazon Redshift), recomendamos que você renomeie as tabelas. Para obter mais informações, consulte Exemplos de ALTER TABLE.
Alteração de tempformat padrão no Dataframe
O conector Spark versão 3.0 da AWS Glue usa como padrão o tempformat para CSV ao gravar no Amazon Redshift. Para ser consistente, no AWS Glue versão 3.0, o
DynamicFrame ainda tem como padrão que o tempformat use CSV. Se você já usou APIs de Dataframe do Spark diretamente com o conector do Amazon Redshift Spark, você pode definir explicitamente o tempformat como CSV nas opções DataframeReader/Writer. Caso contrário, o padrão para tempformat é AVRO no novo conector Spark.
Alteração de comportamento: mapeie o tipo de dados REAL do Amazon Redshift para o tipo de dados do FLOAT do Spark, em vez de DOUBLE
No AWS Glue versão 3.0, o Amazon Redshift REAL é convertido em um tipo
DOUBLE do Spark. O novo conector do Amazon Redshift Spark atualizou o comportamento para que o tipo
REAL do Amazon Redshift seja convertido para o tipo FLOAT do Spark e vice-versa. Se você tiver um caso de uso antigo em que ainda desejar que o tipo REAL do Amazon Redshift seja mapeado para um tipo DOUBLE do Spark, poderá usar a seguinte solução alternativa:
-
Para um
DynamicFrame, mapeie o tipoFloatpara um tipoDoublecomDynamicFrame.ApplyMapping. Para umDataframe, você precisa usarcast.
Exemplo de código:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
