Detecção de anomalias no AWS Glue Data Quality
Os engenheiros gerenciam centenas de pipelines de dados ao mesmo tempo. Cada pipeline pode extrair dados de diferentes fontes e carregá-los no data lake ou em outros repositórios de dados. Para garantir a entrega de dados de alta qualidade para a tomada de decisões, eles estabelecem regras de qualidade de dados. Essas regras avaliam os dados com base em critérios fixos que refletem o estado atual dos negócios. No entanto, quando o ambiente de negócios muda, as propriedades dos dados também mudam, tornando esses critérios fixos desatualizados e resultando em baixa qualidade dos dados.
Por exemplo, um engenheiro de dados de uma empresa de varejo estabeleceu uma regra que valida que as vendas diárias devem exceder o limite de um milhão de dólares. Após alguns meses, as vendas diárias ultrapassaram dois milhões de dólares, tornando o limite obsoleto. Devido à ausência de notificação e ao esforço necessário para analisar e atualizar manualmente a regra, o engenheiro de dados não conseguiu atualizar as regras para refletir os limites mais recentes. No final do mês, os usuários corporativos observaram uma queda de 25% em suas vendas. Após muitas horas de investigação, os engenheiros de dados descobriram que um pipeline de ETL responsável por extrair dados de algumas lojas havia falhado sem gerar erros. A regra com limites desatualizados continuou operando com sucesso e sem detectar esse problema.
Como alternativa, alertas proativos capazes de detectar essas anomalias poderiam ter permitido que os usuários detectassem esse problema. Além disso, o monitoramento da sazonalidade nos negócios pode destacar problemas significativos de qualidade de dados. Por exemplo, as vendas no varejo podem ser maiores nos finais de semana e durante as festas de fim de ano, enquanto relativamente baixas nos dias de semana. A divergência desse padrão pode indicar problemas de qualidade de dados ou mudanças nas condições comerciais. As regras de qualidade de dados não são capazes de detectar padrões sazonais, pois isso requer algoritmos avançados que possam aprender com padrões anteriores que capturam a sazonalidade para detectar desvios.
Por fim, os usuários acham difícil criar e manter regras devido à natureza técnica do processo de criação de regras e ao tempo necessário para criá-las. Como resultado, eles preferem explorar os insights de dados antes de definir as regras. Os clientes precisam ter a capacidade de detectar anomalias facilmente, viabilizando a detecção proativa de problemas de qualidade de dados e a tomada de decisão com confiança.
Como funciona
nota
A detecção de anomalias só é compatível com o processo de ETL do AWS Glue. Esse recurso não é compatível com qualidade de dados baseada no Catálogo de Dados.
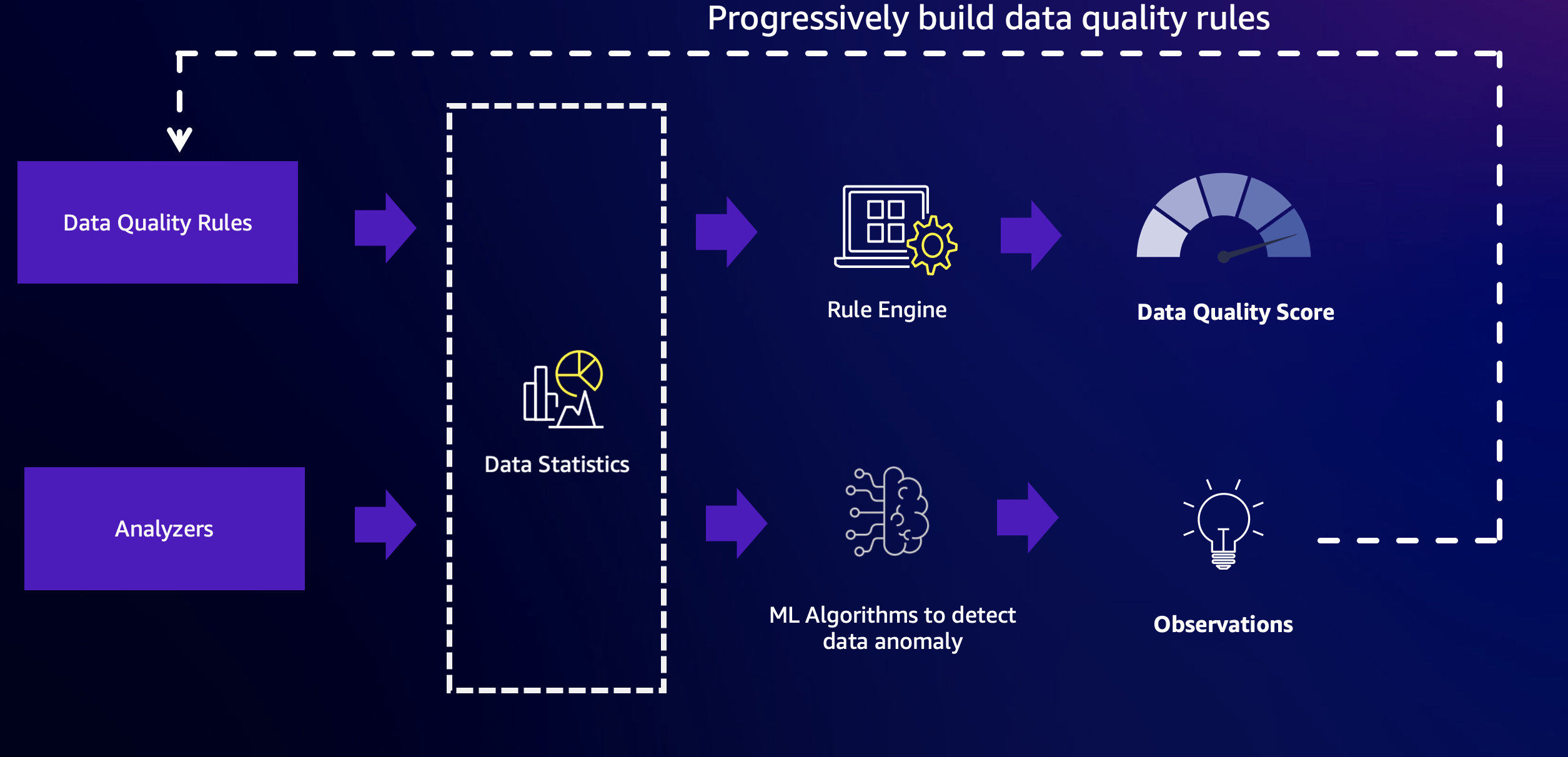
O AWS Glue Data Quality combina o poder da qualidade de dados baseada em regras e das capacidades de detecção de anomalias para fornecer dados de alta qualidade. Para começar, é necessário configurar regras e analisadores, e então habilitar a detecção de anomalias.
Regras
Regras: as regras expressam as expectativas para seus dados em uma linguagem aberta chamada de Data Quality Definition Language (DQDL). Veja um exemplo de regra abaixo. Essa regra será bem-sucedida quando não houver valores vazios ou NULL na coluna `passenger_count`:
Rules = [ IsComplete "passenger_count" ]
Analisadores
Em situações nas quais você conheça as colunas críticas, mas talvez não saiba o suficiente sobre os dados para criar regras específicas, será possível monitorar essas colunas usando analisadores. Os analisadores são uma maneira de coletar estatísticas de dados sem definir regras explícitas. Veja um exemplo de configuração de analizadores abaixo:
Analyzers = [ AllStatistics "fare_amount", DistinctValuesCount "pulocationid", RowCount ]
Neste exemplo, há três analisadores configurados:
-
O primeiro analisador, `AllStatistics “fare_amount"`, capturará todas as estatísticas disponíveis para o campo `fare_amount`.
-
O segundo Analisador, `DistinctValuesCount “pulocationid"`, capturará a contagem de valores distintos na coluna `pulocationid`.
-
O terceiro analisador, `RowCount`, capturará o número total de registros no conjunto de dados.
Os analisadores são uma maneira simples de coletar estatísticas de dados relevantes sem especificar regras complexas. Ao monitorar essas estatísticas, você pode obter insights sobre a qualidade dos dados e identificar possíveis problemas ou anomalias que possam exigir uma investigação mais aprofundada ou a criação de regras específicas.
Estatísticas de tabela
Tanto os analisadores quanto as regras no AWS Glue Data Quality coletam estatísticas de dados, também conhecidas como perfis de dados. Essas estatísticas fornecem insights sobre as características e a qualidade dos seus dados. As estatísticas coletadas são armazenadas ao longo do tempo no serviço AWS Glue, permitindo que você acompanhe e analise as alterações em seus perfis de dados.
Invocando as APIs adequadas, é possível recuperar facilmente essas estatísticas e gravá-las no Amazon S3 para análise adicional ou armazenamento de longo prazo. Essa funcionalidade permite integrar a criação de perfis de dados aos seus fluxos de trabalho de processamento de dados e aproveitar as estatísticas coletadas para vários fins, como monitoramento da qualidade dos dados e detecção de anomalias.
Ao armazenar os perfis de dados no Amazon S3, você pode aproveitar a escalabilidade, durabilidade e economia do serviço de armazenamento de objetos da Amazon. Além disso, você pode aproveitar outros serviços da AWS ou ferramentas de terceiros para analisar e visualizar os perfis de dados, permitindo que você obtenha insights mais profundos sobre a qualidade dos dados e tome decisões informadas sobre gerenciamento e governança de dados.
Veja um exemplo das estatísticas de dados armazenadas ao longo do tempo.
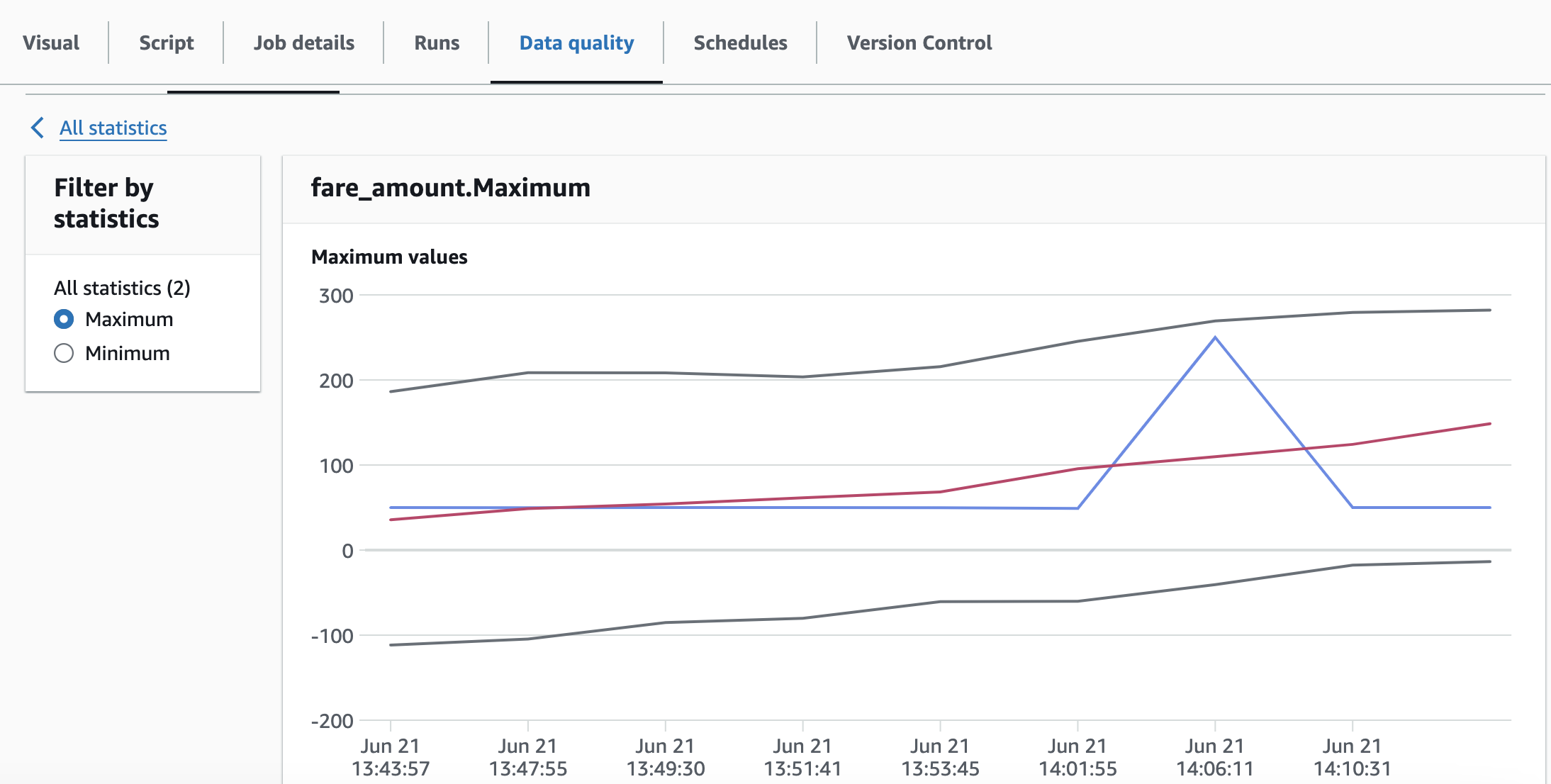
nota
O AWS Glue Data Quality coletará estatísticas apenas uma vez, mesmo que você tenha a regra e o analisador para as mesmas colunas, tornando eficiente o processo de geração de estatísticas.
Detecção de anomalias
Para detectar anomalias, o AWS Glue Data Quality requer um mínimo de três pontos de dados. Ele utiliza um algoritmo de machine learning para aprender com as tendências passadas e, em seguida, prever valores futuros. Quando o valor efetivo não estiver dentro da faixa prevista, o AWS Glue Data Quality criará uma observação de anomalias. Isso disponibilizará uma representação visual do valor efetivo e das tendências. Há quatro valores exibidos no gráfico abaixo.
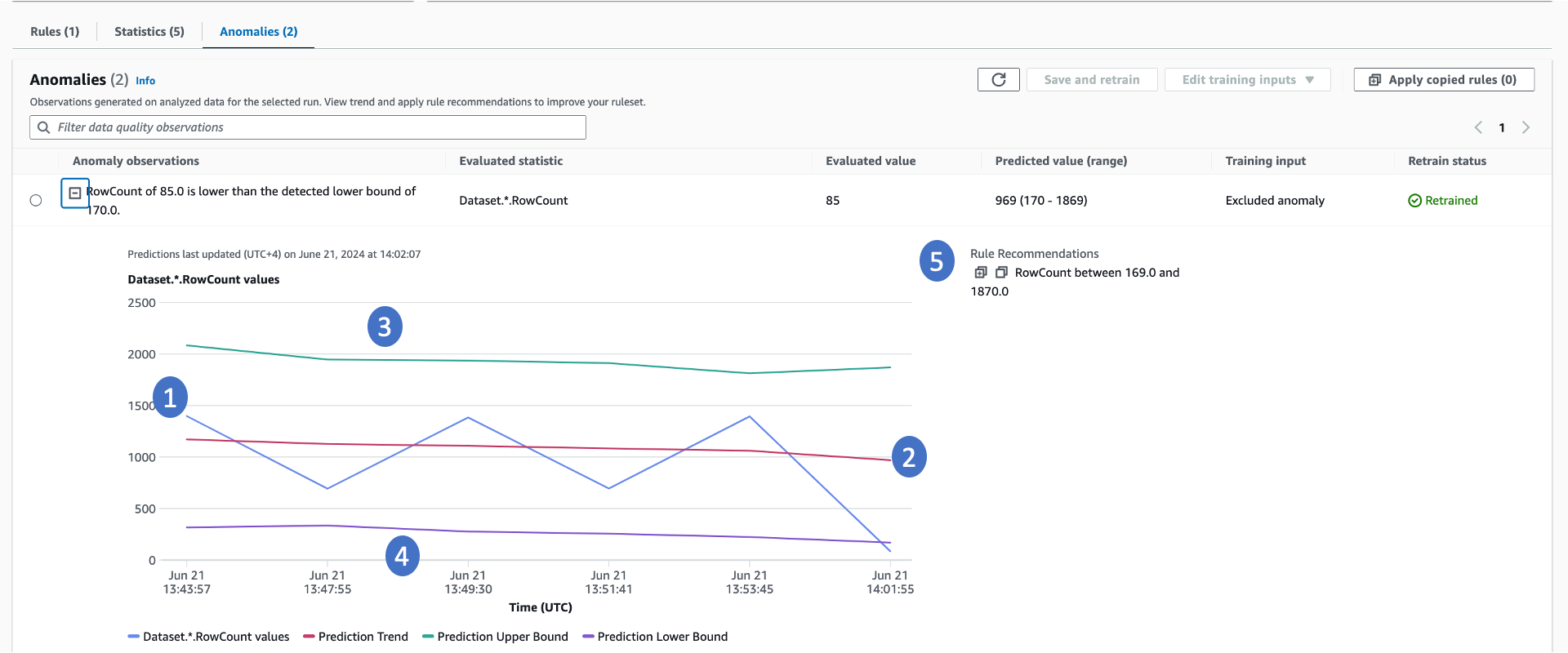
-
A estatística efetiva e sua tendência ao longo do tempo.
-
Uma tendência derivada do aprendizado com a tendência efetiva. Isso é útil para entender a direção da tendência.
-
O possível limite superior para a estatística.
-
O possível limite inferior para a estatística.
-
Regras de qualidade de dados recomendadas capazes de detectar esses problemas no futuro.
Há algumas coisas importantes a serem observadas em relação às anomalias:
-
Quando há a geração de anomalias, as pontuações de qualidade dos dados não são afetadas.
-
Quando há a detecção de uma anomalia, ela é considerada normal para execuções subsequentes. A menos que esse valor anômalo seja explicitamente excluído, o algoritmo de machine learning o considerará como uma entrada.
Retreinamento
É fundamental retreinar o modelo de detecção de anomalias para detectar as anomalias corretas. Quando há a detecção de anomalias, o AWS Glue Data Quality inclui a anomalia no modelo como um valor normal. Para garantir que a detecção de anomalias funcione com precisão, é importante fornecer feedback reconhecendo ou rejeitando a anomalia. AWS O Glue Data Quality fornece mecanismos no AWS Glue Studio e nas APIs para fornecer feedback ao modelo. Para saber mais, consulte a documentação sobre como configurar a Anomaly Detection in AWS Glue ETL pipelines.
Detalhes do algoritmo de detecção de anomalias
-
O algoritmo de detecção de anomalias examina as estatísticas dos dados ao longo do tempo. O algoritmo considera todos os pontos de dados disponíveis e ignora todas as estatísticas que tenham sido explicitamente excluídas.
-
Essas estatísticas de dados são armazenadas no serviço AWS Glue e você pode fornecer chaves do AWS KMS para criptografá-las. Consulte o Guia de segurança para saber como fornecer chaves do AWS KMS para criptografar as estatísticas do AWS Glue Data Quality.
-
O componente de tempo é crucial para o algoritmo de detecção de anomalias. O AWS Glue Data Quality determina os limites superior e inferior com base nos valores anteriores. Durante essa determinação, ele considera o componente de tempo. Os limites serão diferentes para os mesmos valores em um intervalo de 1 minuto, um intervalo de 1 hora ou um intervalo diário.
Captura da sazonalidade
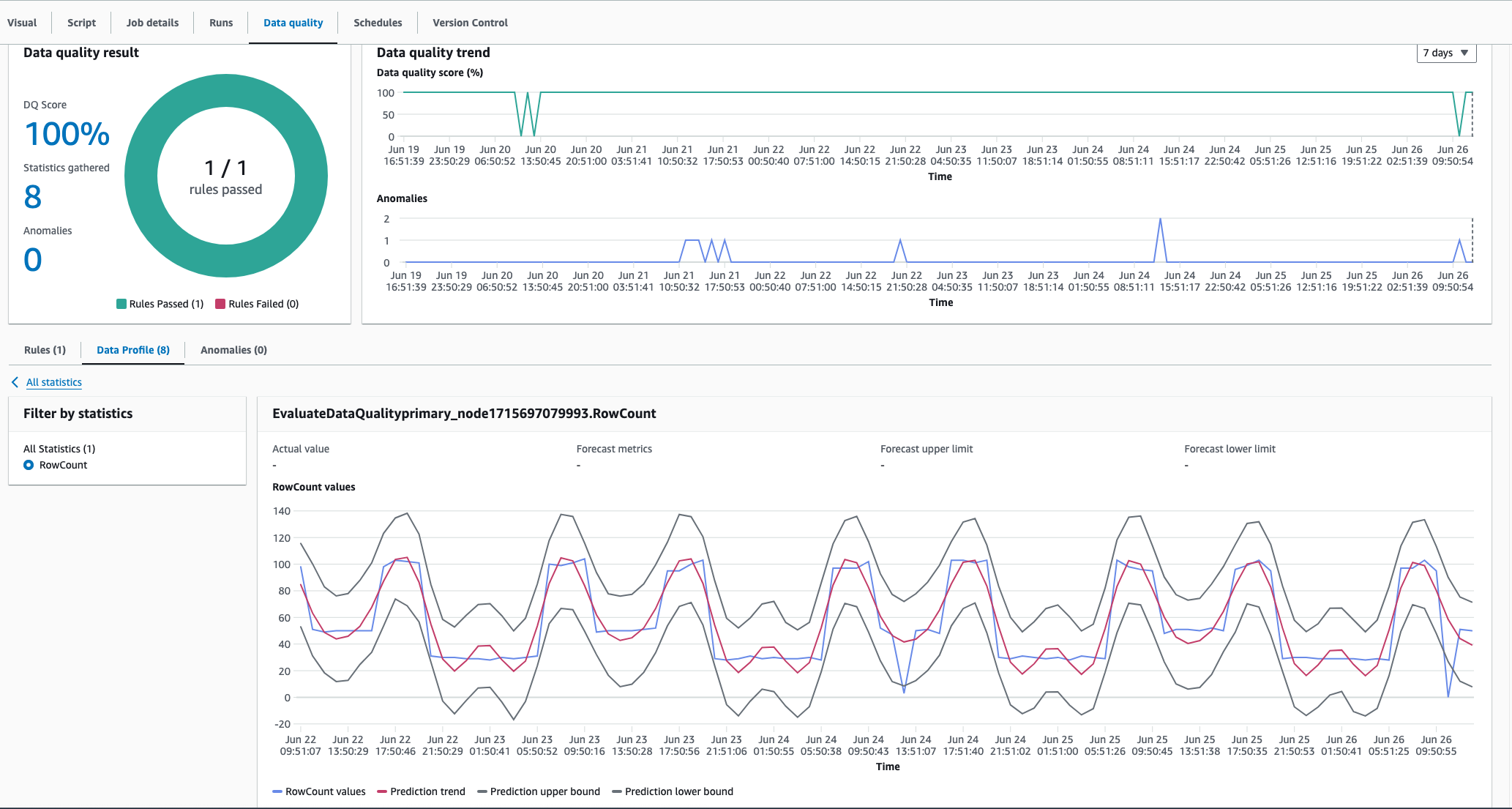
O algoritmo de detecção de anomalias do AWS Glue Data Quality pode capturar padrões sazonais. Por exemplo, ele pode entender que os padrões dos dias da semana são diferentes dos padrões dos finais de semana. É possível ver isso no exemplo abaixo, no qual o AWS Glue Data Quality detecta uma tendência sazonal nos valores dos dados. Você não precisa fazer nada específico para habilitar essa capacidade. Com o tempo, o AWS Glue Data Quality aprende tendências sazonais e detecta anomalias quando esses padrões deixam de existir.
Custo
Você receberá cobranças com base no tempo necessário para detectar anomalias. Cada estatística recebe a cobrança de 1 DPU para o tempo necessário para a detecção de anomalias. Consulte Definição de preço do AWS Glue
Considerações importantes
Não há custo para armazenar as estatísticas. No entanto, há um limite de 100.000 estatísticas por conta. Essas estatísticas serão armazenadas por no máximo 2 anos.
