Iniciar trabalhos de ETL visual no AWS Glue Studio
Você pode usar a interface visual simples no AWS Glue Studio para criar seus trabalhos de ETL. Você pode usar a página Jobs (Trabalhos) para criar novos trabalhos. Você também pode usar um editor de scripts ou bloco e anotações para trabalhar diretamente com código no script de trabalho de ETL do AWS Glue Studio.
Na página Jobs (Trabalhos), você também pode ver todos os trabalhos que criou com o AWS Glue Studio ou o AWS Glue. Você pode exibir, gerenciar e executar seus trabalhos nessa página.
Veja também o tutorial do blog
Iniciar trabalhos no AWS Glue Studio
O AWS Glue permite criar um trabalho por meio de uma interface visual, um caderno de código interativo ou com um editor de scripts. Você pode iniciar um trabalho clicando em qualquer uma das opções ou criar um novo trabalho com base em um trabalho de exemplo.
Exemplos de trabalhos de criação de trabalho com a ferramenta de sua escolha. Por exemplo, exemplos de trabalhos permitem que você crie um trabalho ETL visual que une arquivos CSV em uma tabela de catálogo, crie um trabalho em um caderno de código interativo com o AWS Glue para Ray ou AWS Glue para Spark ao trabalhar com pandas ou crie uma tarefa em um caderno de código interativo com o SparkSQL.
Criando um trabalho no AWS Glue Studio do zero
Faça login no Console de gerenciamento da AWS e abra o console do AWS Glue Studio em https://console.aws.amazon.com/gluestudio/
. -
No painel de navegação, escolha Trabalhos.
-
Na seção Criar trabalho, escolha uma opção de configuração para o seu trabalho.
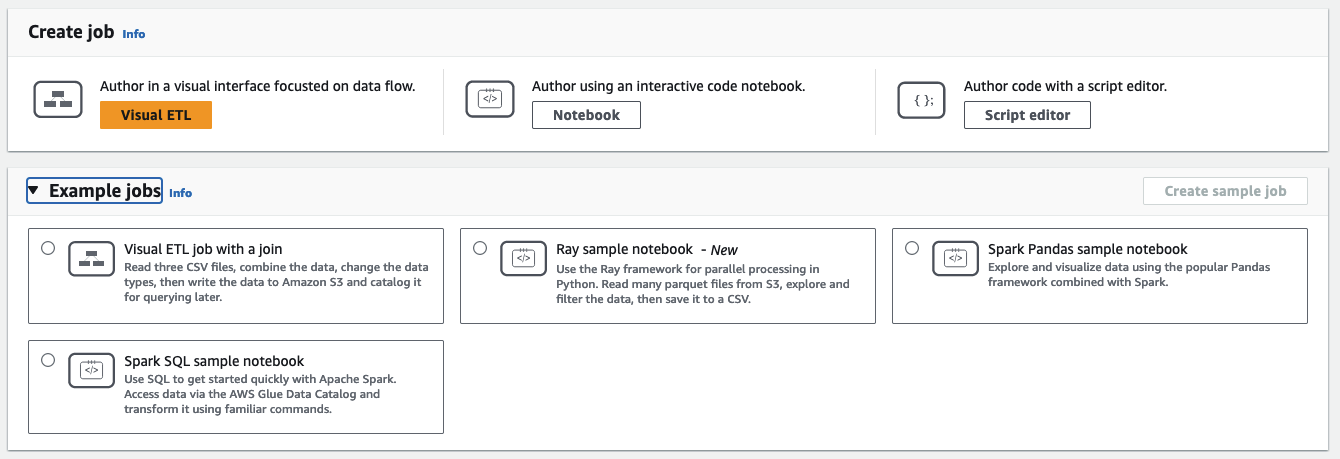
Opções para criar um trabalho do zero:
-
Visual ETL: criar em uma interface visual focada no fluxo de dados
-
Criar usando um caderno de código interativo: criar trabalhos interativamente em uma interface de caderno baseada em cadernos Jupyter
Quando seleciona esta opção, você deve fornecer informações adicionais antes de criar uma sessão de criação de caderno. Para obter mais informações sobre como especificar essas informações, consulte Conceitos básicos de cadernos no AWS Glue Studio.
-
Editor de scripts Spark: para aqueles familiarizados com programação e escrita de scripts de ETL, escolha essa opção para criar um novo trabalho de ETL do Spark. Escolha o mecanismo (Python shell, Ray, Spark (Python) ou Spark (Scala). Em seguida, escolha Começar do zero ou Carregar script. Carregar um script existente a partir de um arquivo local. Se você optar por usar o editor de scripts, não será possível usar o editor de trabalhos visual para criar ou editar seu trabalho.
Um trabalho do Spark é executado em um ambiente Apache Spark gerenciado pelo AWS Glue. Por padrão, novos scripts são codificados em Python. Para escrever um novo script em Scala, consulte Criar e editar scripts em Scala no AWS Glue Studio.
-
Criar um trabalho no AWS Glue Studio partir de um trabalho de exemplo
Você pode optar por criar um trabalho a partir de um trabalho de exemplo. Na seção Trabalhos de exemplo, escolha um trabalho de exemplo e, em seguida, escolha Criar trabalho de exemplo. A criação de um trabalho de exemplo a partir de uma das opções fornece um modelo rápido com o qual você pode trabalhar.
Faça login no Console de gerenciamento da AWS e abra o console do AWS Glue Studio em https://console.aws.amazon.com/gluestudio/
. -
No painel de navegação, escolha Trabalhos.
-
Selecione uma opção para criar um trabalho a partir de um trabalho de exemplo:
-
Trabalho de ETL visual para unir várias fontes: ler três arquivos CSV, combinar os dados, alterar os tipos de dados e, em seguida, gravar os dados no Amazon S3 e catalogá-los para consulta posterior.
-
Notebook Spark usando Pandas: explorar e visualizar dados usando a popular estrutura do Panda combinada com o Spark.
-
Caderno Spark usando SQL: usar SQL para começar a usar rapidamente o Apache Spark. Acessar dados por meio do catálogo de dados do AWS Glue e transformá-los usando comandos familiares.
-
-
Escolha Criar trabalho de exemplo.
