Migrar programas do Apache Spark para o AWS Glue
O Apache Spark é uma plataforma de código aberto para workloads de computação distribuída executadas em grandes conjuntos de dados. O AWS Glue utiliza os recursos do Spark para fornecer uma experiência otimizada para ETL. Você pode migrar programas Spark para o AWS Glue para utilizar nossos recursos. O AWS Glue fornece os mesmos aprimoramentos de performance que você esperaria do Apache Spark no Amazon EMR.
Executar o código Spark
O código nativo do Spark pode ser executado em um ambiente AWS Glue pronto para uso. Os scripts muitas vezes são desenvolvidos alterando iterativamente um trecho de código, um fluxo de trabalho adequado para uma sessão interativa. No entanto, convém executar o código existente em um trabalho do AWS Glue, que permite agendar e obter consistentemente logs e métricas para cada execução de script. Você pode carregar e editar um script existente pelo console.
-
Adquira a origem de seu script. Para este exemplo, você usará um script de exemplo do repositório do Apache Spark. Exemplo de binarizador
-
No console do AWS Glue, expanda o painel de navegação do lado esquerdo e selecione ETL > Jobs (Trabalhos)
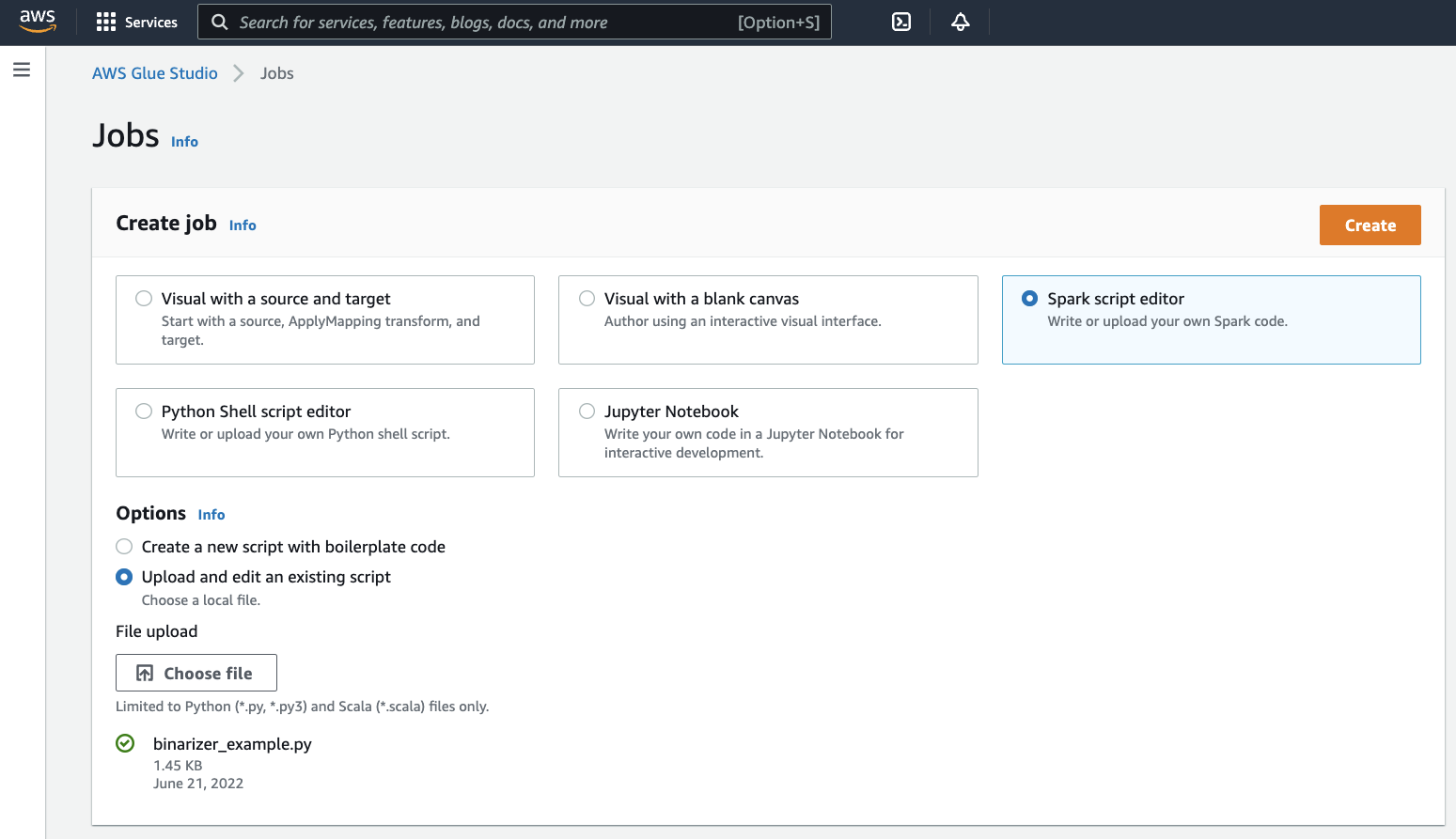
No painel Create job (Criar trabalho), selecione Spark script editor (Editor de scripts Spark). Será exibida a seção Options (Opções). Em Options (Opções), clique em Upload and edit an existing script (Carregar e editar um script existente).
Será exibida a seção File upload (Carregamento de arquivo). Em File upload (Carregamento de arquivo), clique em Choose file (Escolher arquivo). Será exibido seletor de arquivos do sistema. Navegue até o local em que você salvou
binarizer_example.py, selecione-o e confirme a seleção.Será exibido um botão Create (Criar) no cabeçalho do painel Create job (Criar trabalho). Clique.
-
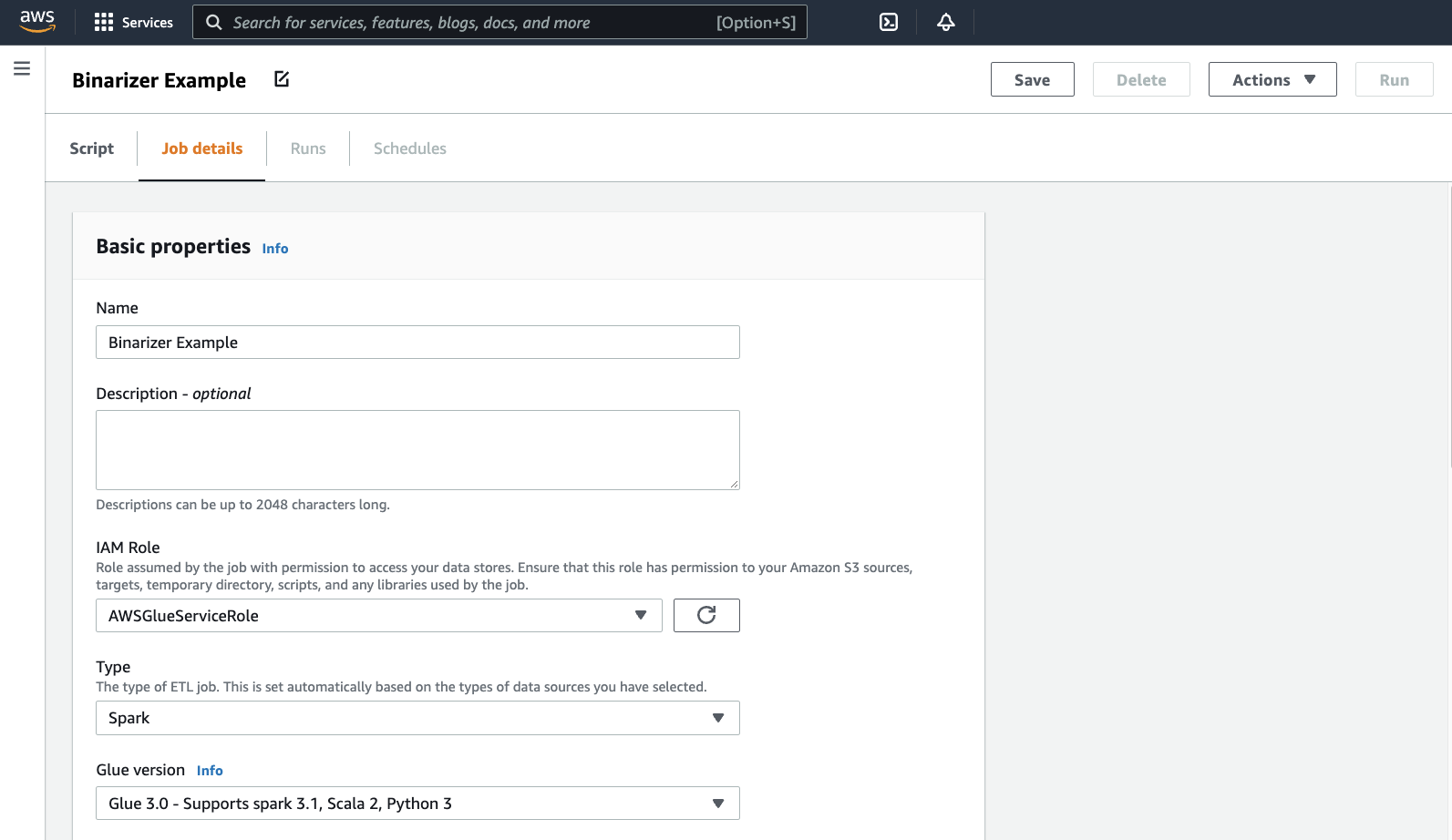
Seu navegador conduzirá até o editor de scripts. No cabeçalho, clique na guia Job details (Detalhes do trabalho). Defina o nome e o perfil do IAM. Para obter orientação sobre perfis do IAM do AWS Glue, consulteConfigurar permissões do IAM para o AWS Glue.
Opcionalmente: defina Requested number of workers (Número solicitado de operadores) para
2e Number of retries (Número de repetições) para1. Essas opções são proveitosas para executar trabalhos de produção, mas recusá-las simplificará sua experiência ao testar um recurso.Na barra de título, clique em Save (Salvar) e depois em Run (Executar)
-
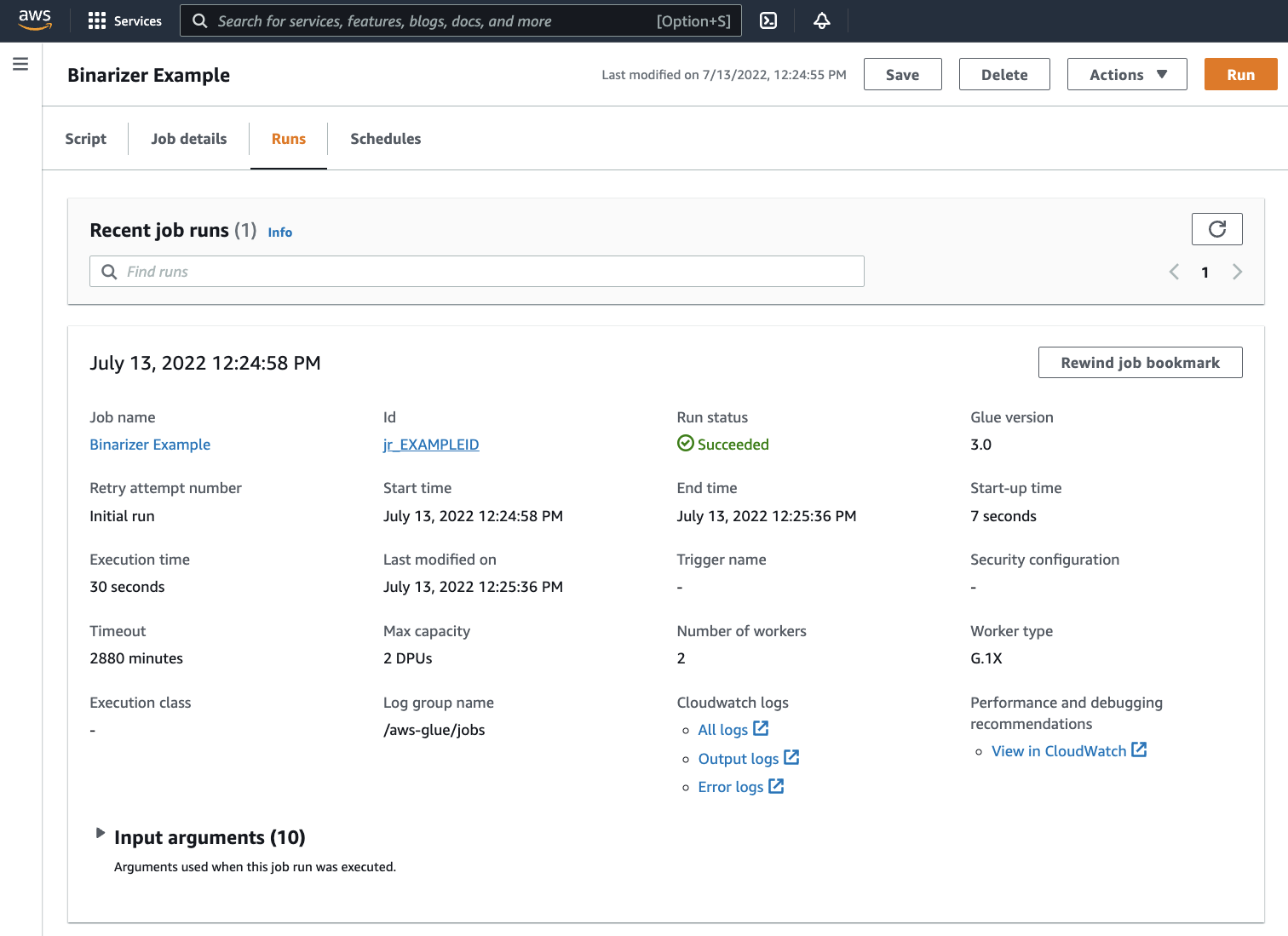
Navegue até a guia Runs (Execuções). Você verá um painel correspondente à execução do trabalho. Aguarde alguns instantes, e a página deverá atualizar automaticamente para exibir Succeeded (Êxito) em Run status (Status da execução).
-
Convém examinar sua saída para confirmar que o script Spark foi executado conforme o esperado. Esse script de amostra do Apache Spark deve gravar uma cadeia de caracteres no fluxo de saída. Você pode descobrir isso navegando até Output logs (Logs de saída) em Logs no painel para a execução bem-sucedida do trabalho. Observe o ID de execução do trabalho, que é um ID gerado no rótulo Id começando com
jr_.Isso abrirá o console do CloudWatch, definido para visualizar o conteúdo do grupo de logs padrão
/aws-glue/jobs/outputdo AWS Glue, filtrado para o conteúdo dos fluxos de logs para o ID de execução do trabalho. Cada operador terá gerado um fluxo de logs, mostrado como linhas em Log streams (Fluxos de log). Um operador deverá ter executado o código solicitado. Você precisará abrir todos os fluxos de logs para identificar o operador correto. Depois de encontrar o operador certo, você deverá ver a saída do script, como é exibido na imagem a seguir: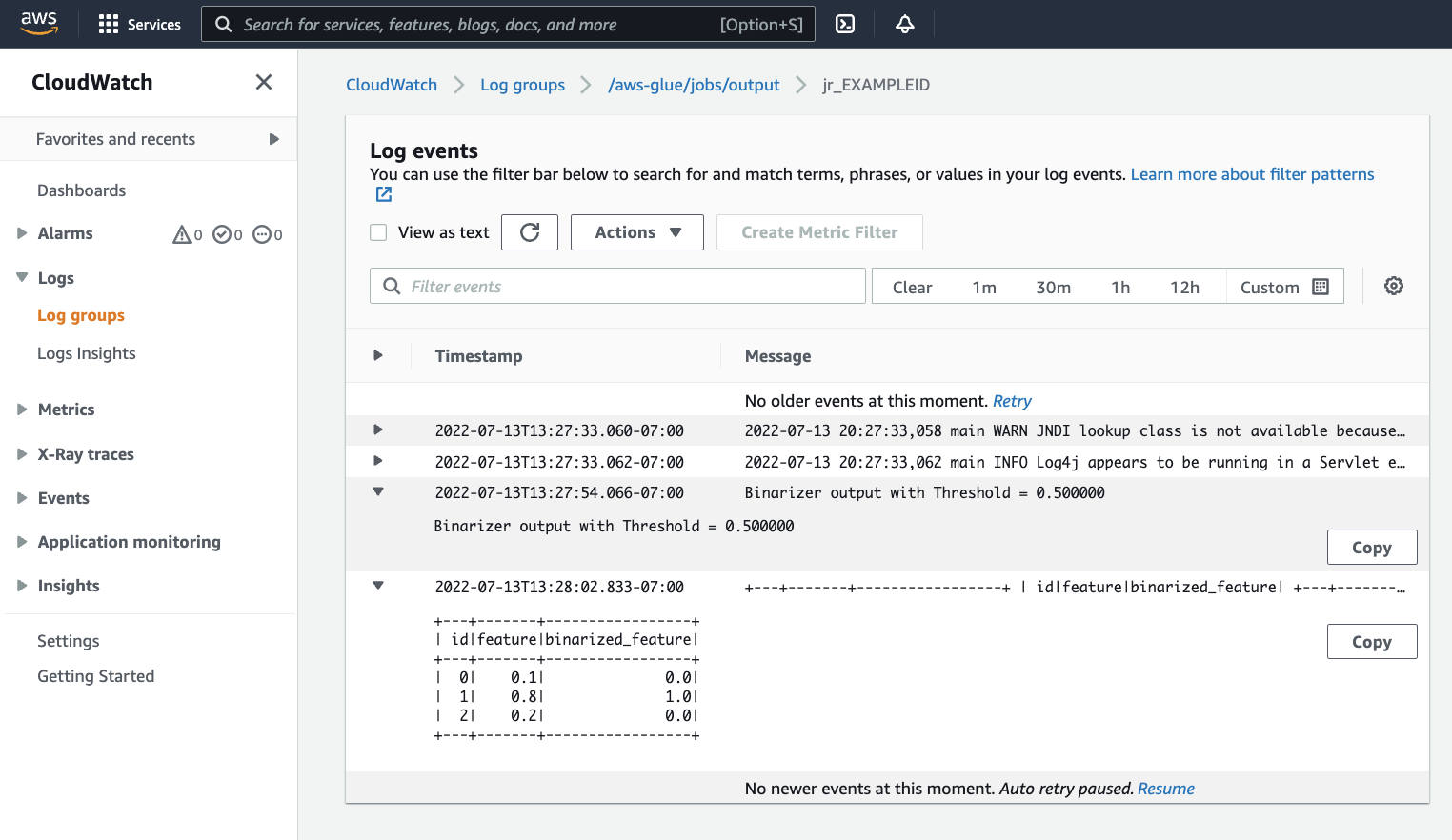
Procedimentos comuns necessários para migrar programas Spark
Avalie a compatibilidade com a versão do Spark
As versões do AWS Glue determinam a versão do Apache Spark e Python que estão disponíveis para o trabalho do AWS Glue. Você encontra nossas versões do AWS Glue e a compatibilidade delas em Versões do AWS Glue. Pode ser necessário atualizar seu programa Spark para que seja compatível com uma versão mais recente do Spark para acessar determinados recursos do AWS Glue.
Incluir bibliotecas de terceiros
Muitos programas Spark existentes terão dependências, tanto em artefatos privados como públicos. O AWS Glue é compatível com dependências de estilo JAR para trabalhos Scala, bem como dependências Wheel e Python puro para trabalhos Python.
Python: para obter informações sobre dependências do Python, consulte Usar bibliotecas Python com o AWS Glue
As dependências comuns do Python são fornecidas no ambiente do AWS Glue, inclusive a popular biblioteca Pandas--additional-python-modules. Para obter mais informações sobre argumentos de trabalho, consulte Usar parâmetros de tarefa em tarefas do AWS Glue.
Você pode fornecer dependências adicionais do Python com o argumento de trabalho --extra-py-files. Se você estiver migrando um trabalho de um programa Spark, esse parâmetro é uma boa opção, pois é funcionalmente equivalente ao sinalizador --py-files no PySpark e está sujeito às mesmas limitações. Para obter mais informações sobre o parâmetro --extra-py-files, consulte Inclusão de arquivos Python com recursos nativos do PySpark
Para novos trabalhos, é possível gerenciar dependências do Python com o argumento de trabalho --additional-python-modules. Usar esse argumento permite uma experiência mais completa de gerenciamento de dependências. Esse parâmetro é compatível com dependências do estilo Wheel, inclusive aquelas com vinculações de código nativas compatíveis com o Amazon Linux 2.
Scala
Você pode fornecer dependências adicionais do Scala com o argumento de trabalho --extra-jars. As dependências devem ser hospedadas no Amazon S3, e o valor do argumento deve ser uma lista delimitada por vírgulas de caminhos do Amazon S3 sem espaços. Talvez seja mais fácil gerenciar sua configuração reagrupando suas dependências antes de hospedá-las e configurá-las. AWS Glue As dependências JAR contêm bytecode Java, que pode ser gerado de qualquer linguagem JVM. É possível usar outras linguagens JVM, como Java, para escrever dependências personalizadas.
Gerenciar credenciais da fonte de dados
Os programas Spark existentes podem vir com configurações complexas ou personalizadas para extrair dados das fontes de dados. Fluxos de autenticação de fonte de dados comuns são compatíveis com conexões do AWS Glue. Para obter mais informações sobre conexões do AWS Glue, consulte Conectar a dados.
As conexões do AWS Glue permitem a conexão do trabalho a uma variedade de tipos de armazenamentos de dados, principalmente de duas maneiras: por meio de chamadas de método para nossas bibliotecas e definindo Additional network connection (Conexão de rede adicional) no console do AWS. Também é possível chamar o SDK da AWS de dentro do trabalho para recuperar informações de uma conexão.
Chamadas de método: as conexões do AWS Glue são totalmente integradas ao AWS Glue Data Catalog, um serviço que permite selecionar informações sobre seus conjuntos de dados, e os métodos disponíveis para interagir com conexões do AWS Glue refletem isso. Se houver uma configuração de autenticação existente que você gostaria de reutilizar, para conexões JDBC, é possível acessar a configuração de conexão do AWS Glue pelo método extract_jdbc_conf em GlueContext. Para obter mais informações, consulte extract_jdbc_conf
Configuração do console: o uso de trabalhos do AWS Glue associados a conexões do AWS Glue para configurar conexões com sub-redes da Amazon VPC. Se você gerencia diretamente seus materiais de segurança, talvez seja necessário fornecer um tipo NETWORK para Additional network connection (Conexão de rede adicional) no console do AWS para configurar o roteamento. Para obter mais informações sobre a conexão de APIs do AWS Glue, consulte API de conexões
Se seus programas Spark tiverem um fluxo de autenticação personalizado ou incomum, talvez seja necessário gerenciar seus materiais de segurança na prática. Se as conexões do AWS Glue não parecerem uma boa opção, você poderá hospedar seguramente materiais de segurança no Secrets Manager e acessá-los pelo boto3 ou pelo SDK da AWS, que são fornecidos no trabalho.
Configurar o Apache Spark
As migrações complexas geralmente alteram a configuração do Spark para acomodar suas workloads. As versões modernas do Apache Spark permitem que a configuração do runtime seja definida com o SparkSession. AWS Glue Trabalhos 3.0+ recebem SparkSession, que pode ser modificado para definir a configuração do runtime. Configuração do Apache Spark
Definir uma configuração personalizada
Os programas Spark migrados podem ser projetados de modo a ter configurações personalizadas. O AWS Glue permite que a configuração seja definida no nível do trabalho e da execução do trabalho, por meio dos argumentos do trabalho. Para obter mais informações sobre argumentos de trabalho, consulte Usar parâmetros de tarefa em tarefas do AWS Glue. É possível acessar argumentos de trabalho dentro do contexto de um trabalho por meio de nossas bibliotecas. O AWS Glue fornece uma função de utilitário que proporciona uma visão consistente entre os argumentos definidos no trabalho e os argumentos definidos na execução do trabalho. Consulte Acessar parâmetros usando getResolvedOptions em Python e APIs GlueArgParser em Scala no AWS Glue em Scala.
Migrar código Java
Conforme explicado em Incluir bibliotecas de terceiros, suas dependências podem conter classes geradas por linguagens JVM, como Java ou Scala. Suas dependências podem incluir um método main. Você pode usar um método main em uma dependência como o ponto de entrada para um trabalho Scala do AWS Glue. Isso permite escrever o método main em Java ou reutilizar um método main empacotado de acordo com seus próprios padrões de biblioteca.
Para usar um método main de uma dependência, execute este procedimento: limpe o conteúdo do painel de edição fornecendo o objeto GlueApp padrão. Forneça o nome totalmente qualificado de uma classe em uma dependência como argumento de trabalho com a chave --class. Então, você deverá ser capaz de acionar uma execução de trabalho.
Não é possível configurar a ordem ou a estrutura dos argumentos. O AWS Glue passa para o método main. Se o código existente precisar ler a configuração definida no AWS Glue, isso provavelmente causará incompatibilidade com o código anterior. Se você usar getResolvedOptions, também não terá um bom lugar para chamar esse método. Considere invocar sua dependência diretamente de um método principal gerado pelo AWS Glue. O script de ETL do AWS Glue a seguir é um exemplo disso.
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
