Monitorar o progresso de vários trabalhos
Você pode criar o perfil de vários trabalhos do AWS Glue e monitorar o fluxo de dados entre eles. Esse é um padrão de fluxo de trabalho comum e requer monitoramento de andamento de trabalho individual, backlog de processamento de dados, reprocessamento de dados e marcadores de trabalho.
Tópicos
Código perfilado
Neste fluxo de trabalho, você tem dois trabalhos: um de entrada e um de saída. O trabalho de entrada está programado para ser executado a cada 30 minutos usando um gatilho periódico. O trabalho de saída está programado para ser executado após cada execução bem-sucedida do trabalho de entrada. Essas tarefas agendadas são controladas usando gatilhos de trabalho.

Trabalho de entrada: esse trabalho lê dados de um local do Amazon Simple Storage Service (Amazon S3), transforma-os usando ApplyMapping e os grava em um local de preparação do Amazon S3. O código a seguir é o código perfilado para o trabalho de entrada:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": ["s3://input_path"], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": staging_path, "compression": "gzip"}, format = "json")
Trabalho de saída: esse trabalho lê a saída do trabalho de entrada no local de preparação no Amazon S3, transforma-a novamente e a grava em um destino:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "json")
Visualizar as métricas perfiladas no console do AWS Glue
O seguinte painel sobrepõe a métrica de bytes gravados do Amazon S3 do trabalho de entrada na métrica de bytes lidos do Amazon S3 no mesmo cronograma do trabalho de saída. O cronograma mostra diferentes execuções de trabalhos de entrada e saída. O trabalho de entrada (mostrado em vermelho) começa a cada 30 minutos. O trabalho de saída (mostrado em marrom) começa na conclusão do trabalho de entrada, com uma simultaneidade máxima de 1.
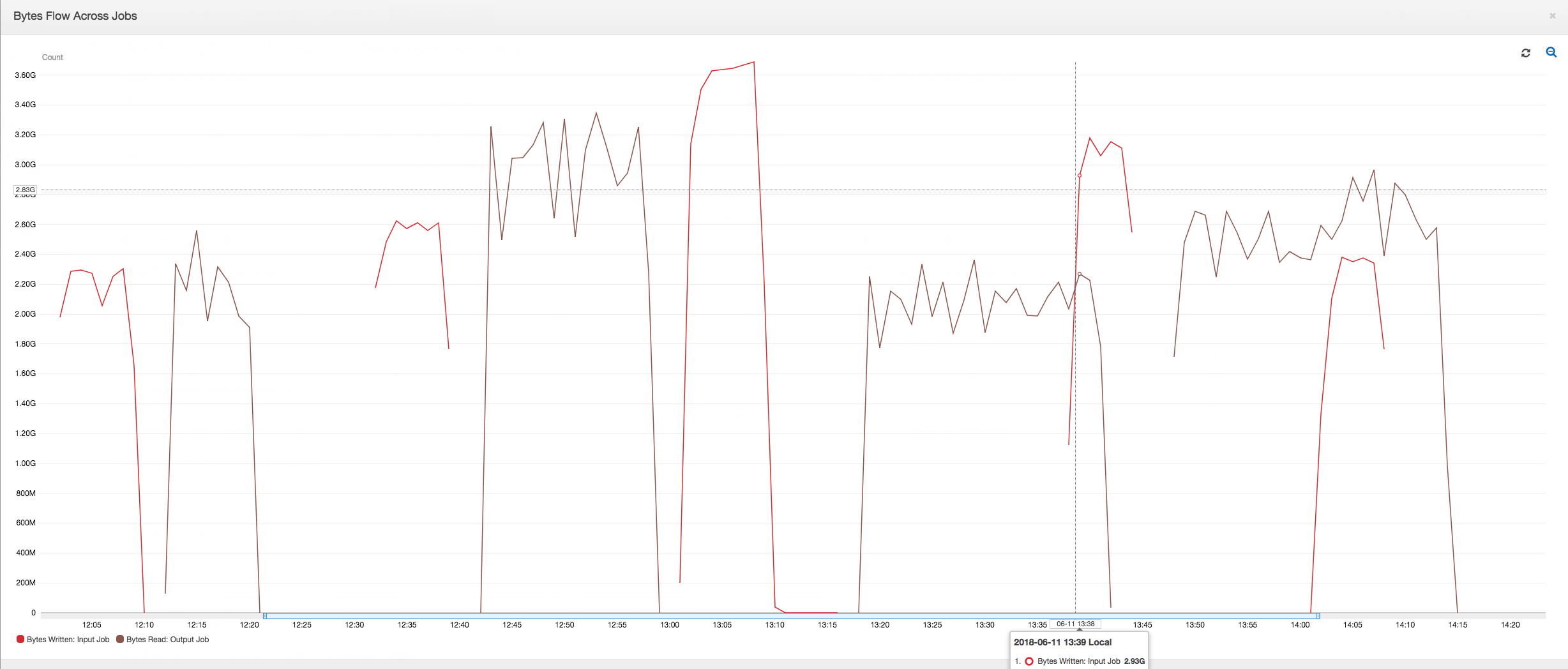
Neste exemplo, marcadores de trabalho não estão habilitados. Nenhum contexto de transformação é usado para habilitar marcadores de trabalho no código de script.
Histórico de trabalho: os trabalhos de entrada e saída têm várias execuções, conforme mostrado na guia History (Histórico), a partir do meio-dia.
O trabalho de entrada no console do AWS Glue é semelhante a este:

A imagem a seguir mostra o trabalho de saída:

Primeiras execuções de trabalho: como mostrado no gráfico de bytes de dados lidos e gravados abaixo, as primeiras execuções dos trabalhos de entrada e saída entre 12h e 12h30 mostram aproximadamente a mesma área sob as curvas. Essas áreas representam os bytes do Amazon S3 gravados pelo trabalho de entrada e os bytes do Amazon S3 lidos pelo trabalho de saída. Esses dados também são confirmados pela relação de bytes do Amazon S3 gravados (somados por 30 minutos: a frequência do acionador do trabalho de entrada). O ponto de dados da relação para a execução do trabalho de entrada que começou ao meio-dia também é 1.
O gráfico a seguir mostra a relação do fluxo de dados em todas as execuções de trabalho:
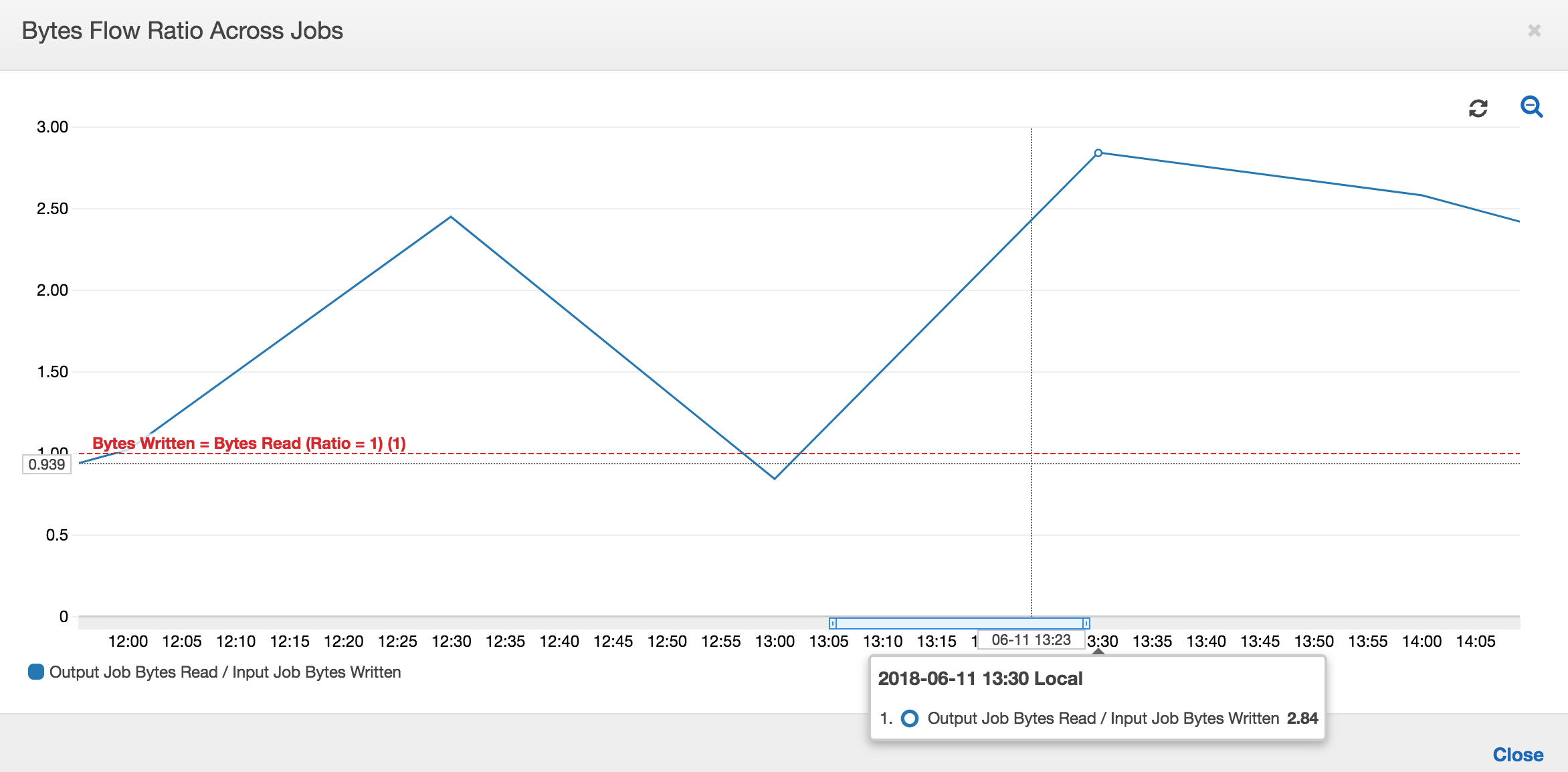
Segunda execução do trabalho: na segunda execução do trabalho, existe uma clara diferença no número de bytes lidos pelo trabalho de saída em comparação com o número de bytes gravados pelo trabalho de entrada. Compare a área sob a curva nas duas execuções do trabalho de saída, ou compare as áreas na segunda execução dos trabalhos de entrada e saída. A relação dos bytes lidos e gravados mostra que o trabalho de saída lê cerca de 2,5x os dados gravados pelo trabalho de entrada no segundo período de 30 minutos das 12h30 às 13h. Isso ocorre porque o trabalho de saída reprocessou a saída da primeira execução do trabalho de entrada porque os marcadores de trabalho não foram ativados. Uma relação acima de 1 mostra que há um backlog adicional de dados que foi processado pelo trabalho de saída.
Terceira execução do trabalho: o trabalho de entrada é bastante consistente em termos do número de bytes gravados (consulte a área sob as curvas vermelhas). No entanto, a terceira execução do trabalho de entrada foi maior que o esperado (consulte a extremidade longa da curva vermelha). Como resultado, a terceira execução do trabalho de saída iniciou com atraso. A terceira execução do trabalho processou apenas uma fração dos dados acumulados no local de preparação nos 30 minutos restantes entre 13h e 13h30. A relação do fluxo de bytes mostra que ele processou apenas 0,83 de dados gravados pela terceira execução do trabalho de entrada (consulte a relação às 13h).
Sobreposição de trabalhos de entrada e saída: a quarta execução do trabalho de entrada começou às 13h30 de acordo com a programação, antes de a terceira execução do trabalho de saída ser concluída. Existe uma sobreposição parcial entre essas duas execuções de trabalho. No entanto, a terceira execução do trabalho de saída captura apenas os arquivos listados no local de preparação do Amazon S3 quando ela começou, em torno das 13h17. Isso consiste na saída de todos os dados da primeira execução do trabalho de entrada. A taxa real às 13h30 é em torno de 2,75. A terceira execução do trabalho de saída processou cerca de 2,75x de dados gravados pela quarta execução do trabalho de entrada das 13h30 às 14h.
Como essas imagens mostram, o trabalho de saída reprocessa dados do local de preparação de todas as execuções anteriores do trabalho de entrada. Como resultado, a quarta execução do trabalho de saída é a mais longa e se sobrepõe à quinta execução do trabalho de entrada.
Corrigir o processamento de arquivos
Você deve garantir que o trabalho de saída processe apenas os arquivos que não foram processados por execuções anteriores do trabalho de saída. Para fazer isso, habilite marcadores de trabalho e defina o contexto de transformação no trabalho de saída, da seguinte forma:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json", transformation_ctx = "bookmark_ctx")
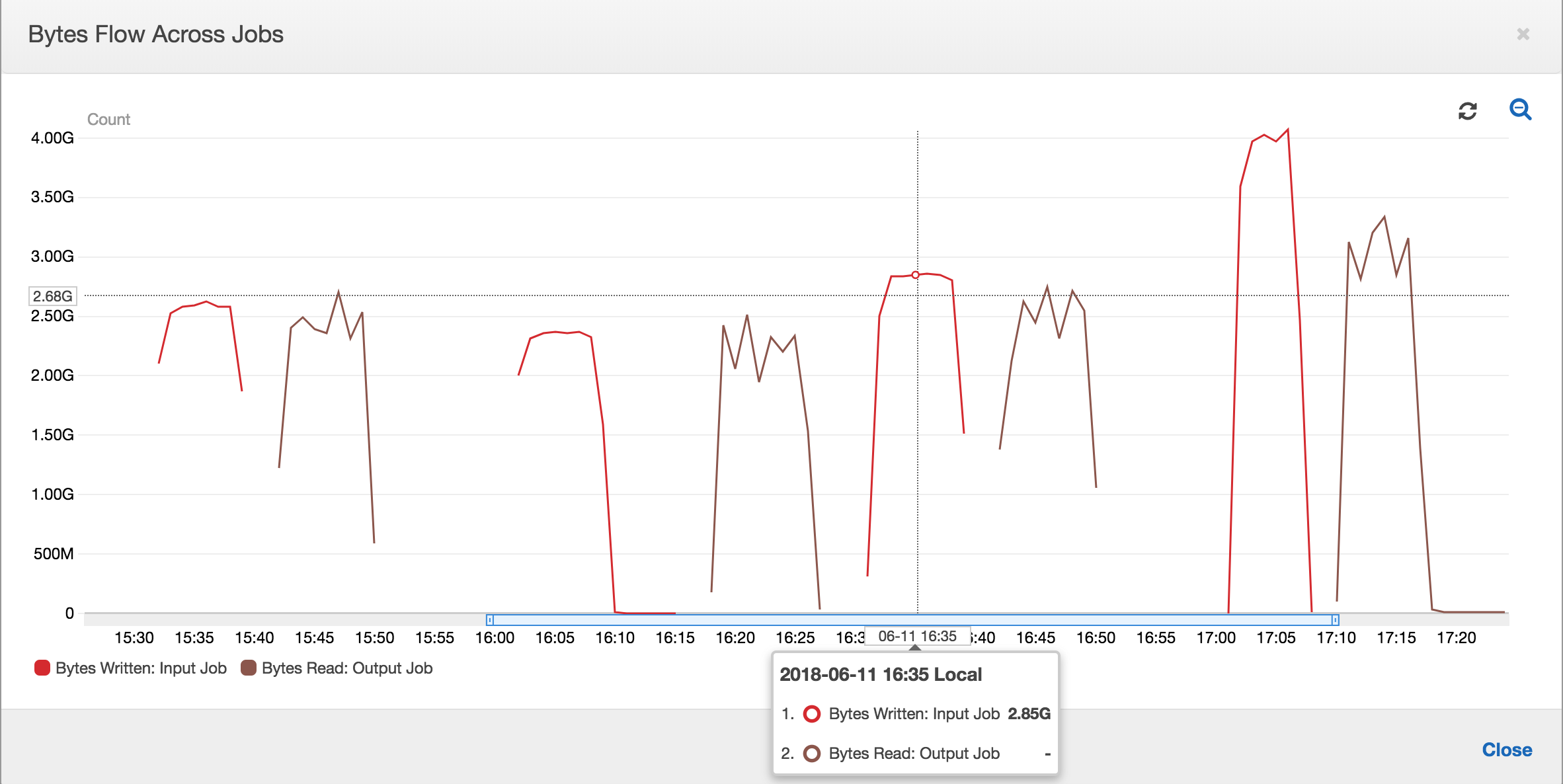
Com marcadores de trabalho ativados, o trabalho de saída não reprocessa os dados no local de preparação de todas as execuções anteriores do trabalho de entrada. Na imagem a seguir que mostra os dados lidos e gravados, a área sob a curva marrom é bastante consistente e semelhante às curvas vermelhas.
As relações de fluxo de bytes também permanecem cerca de 1 porque não há dados adicionais processados.
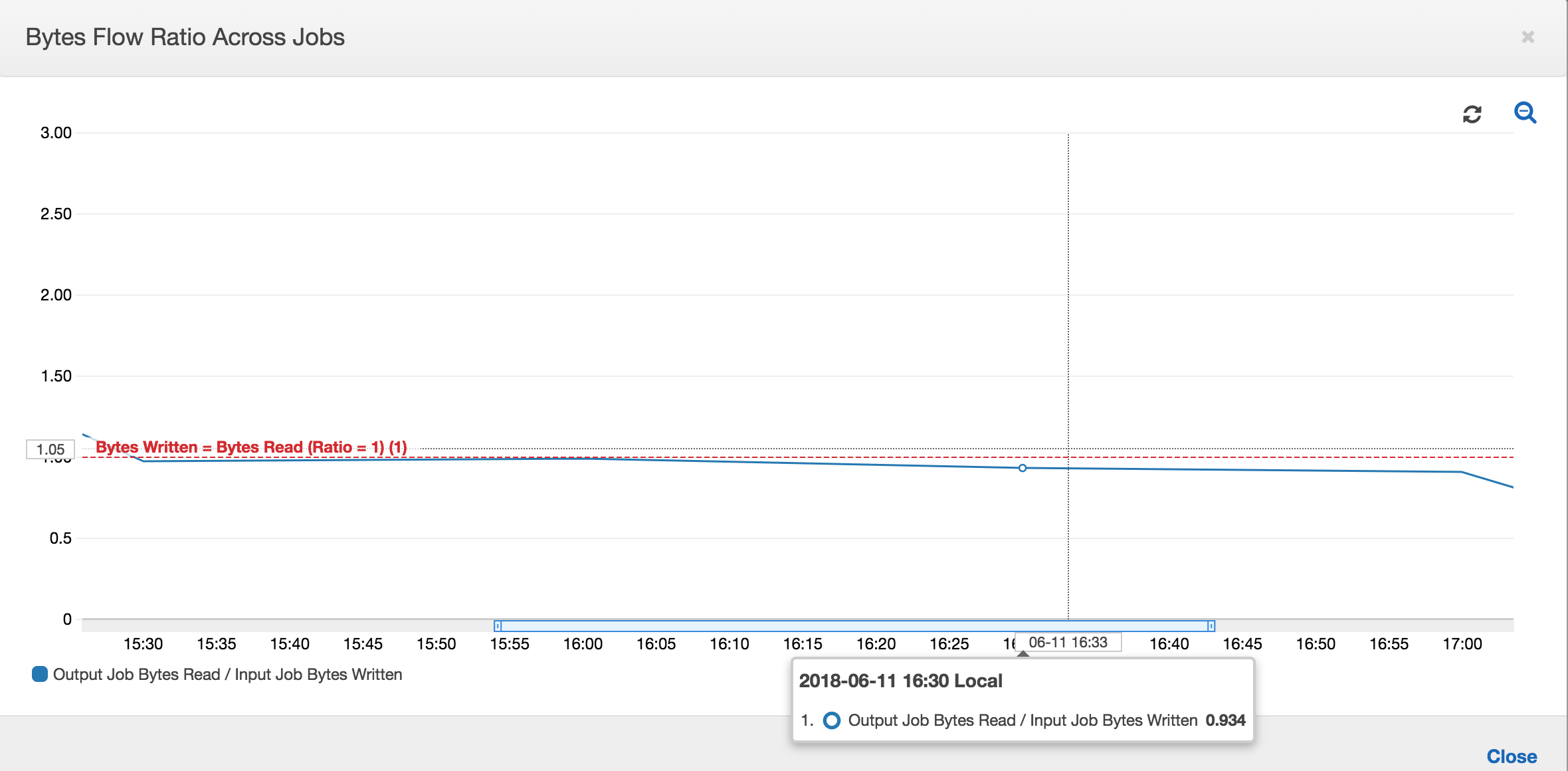
Uma execução do trabalho de saída é iniciada e captura os arquivos no local de preparação antes da próxima execução do trabalho de entrada começar a colocar mais dados no local de preparação. Desde que continue a fazer isso, ela processa apenas os arquivos capturados na execução do trabalho de entrada anterior, e a relação permanece próxima a 1.
Suponha que o trabalho de entrada leve mais tempo do que o esperado e, como resultado, o trabalho de saída capture arquivos no local de preparação de duas execuções do trabalho de entrada. A relação é maior que 1 para essa execução do trabalho de saída. No entanto, as próximas execuções do trabalho de saída não processam os arquivos que já foram processados pelas execuções anteriores do trabalho de saída.
