Monitoramento com métricas de observabilidade do AWS Glue
nota
As métricas de observabilidade do AWS Glue estão disponíveis no AWS Glue 4.0 e versões posteriores.
Use métricas de observabilidade do AWS Glue para gerar insights sobre o que está acontecendo dentro do seu AWS Glue para trabalhos do Apache Sparks para melhorar a triagem e a análise de problemas. As métricas de observabilidade são visualizadas por meio de painéis do Amazon CloudWatch e podem ser usadas para ajudar a realizar a análise da causa raiz de erros e para diagnosticar gargalos de performance. É possível reduzir o tempo gasto na depuração de problemas em escala para que você possa se concentrar em resolver problemas com mais rapidez e eficiência.
A observabilidade do AWS Glue fornece métricas do Amazon CloudWatch categorizadas nos quatro grupos a seguir:
-
Confiabilidade (ou seja, classes de erros): identifique facilmente os motivos de falha mais comuns em um determinado intervalo de tempo que você talvez queira resolver.
-
Performance (ou seja, assimetria): identifique um gargalo de performance e aplique técnicas de ajuste. Por exemplo, quando você enfrenta uma degradação de performance causada pela assimetria de um trabalho, convém ativar a execução adaptativa de consultas do Spark e ajustar o limite de junção assimétrica.
-
Throughput (ou seja, throughput por fonte/coletor): monitore as tendências de leituras e gravações de dados. Você também pode configurar alarmes do Amazon CloudWatch para anomalias.
-
Utilização de recursos (ou seja, operadores, memória e utilização de disco): encontre de forma eficiente os trabalhos com baixa utilização de capacidade. Talvez você queira habilitar o ajuste de escala automático do AWS Glue para esses trabalhos.
Conceitos básicos das métricas de observabilidade do AWS Glue
nota
As métricas novas são habilitadas por padrão no console do AWS Glue Studio.
Para configurar métricas de observabilidade no AWS Glue Studio:
-
Faça login no console do AWS Glue e escolha Trabalhos ETL no menu do console.
-
Escolha um trabalho clicando no nome do trabalho na seção Seus trabalhos.
-
Escolha a guia Job details (Detalhes do trabalho).
-
Role até a parte inferior e escolha Propriedades avançadas e, em seguida, Métricas de observabilidade do trabalho.
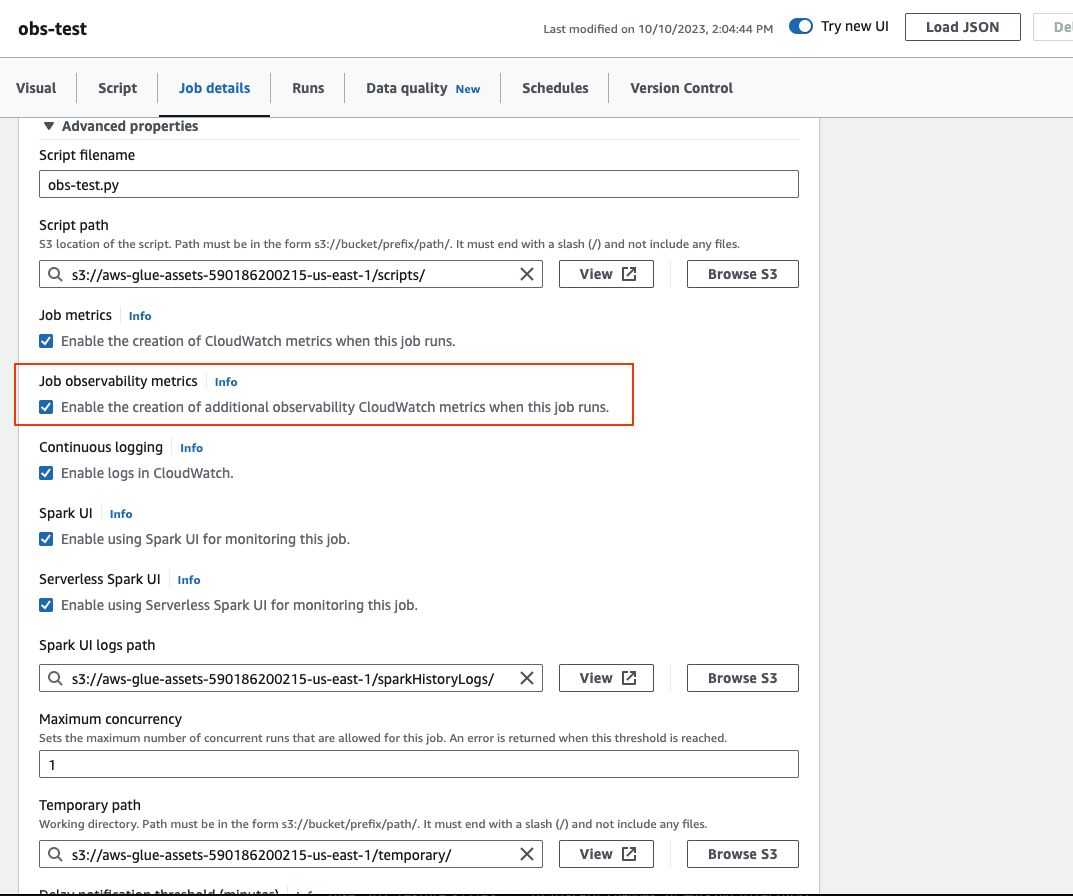
Para habilitar as métricas de observabilidade do AWS Glue usando a AWS CLI:
-
Adicione ao mapa
--default-argumentso seguinte par chave-valor no arquivo JSON de entrada:--enable-observability-metrics, true
Usar a observabilidade do AWS Glue
Como as métricas de observabilidade do AWS Glue são fornecidas por meio do Amazon CloudWatch, você pode usar o console do Amazon CloudWatch, a AWS CLI, o SDK ou a API para consultar os pontos de dados das métricas de observabilidade. Consulte Como usar a observabilidade do Glue para monitorar a utilização de recursos para reduzir custos
Usar a observabilidade do AWS Glue no console do Amazon CloudWatch
Para consultar e visualizar métricas no console do Amazon CloudWatch:
-
Abra o console do Amazon CloudWatch e escolha Todas as métricas.
-
Em Namespaces personalizados, escolha AWS Glue.
-
Escolha Métricas de observabilidade do trabalho, Métricas de observabilidade por fonte ou Métricas de observabilidade por coletor.
-
Pesquise o nome da métrica específica, o nome do trabalho, o ID da execução do trabalho e selecione-os.
-
Na guia Métricas representadas graficamente, configure a estatística, o período e outras opções preferidas.
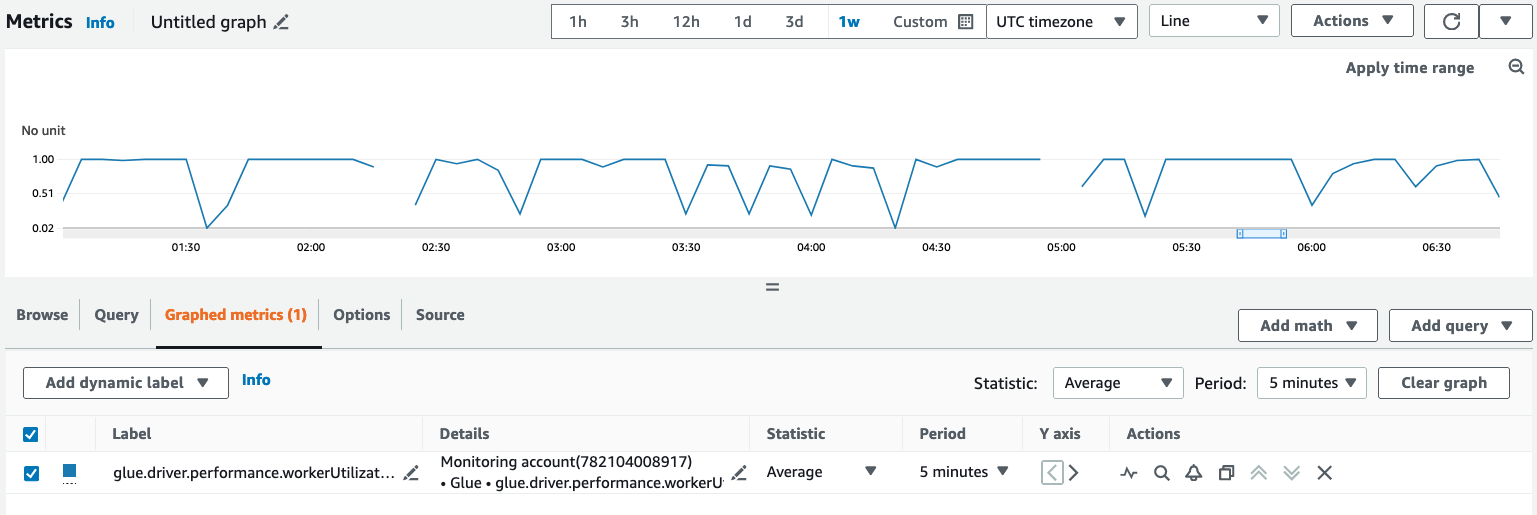
Para consultar uma métrica de observabilidade usando a AWS CLI:
-
Crie um arquivo JSON de definição métrica e substitua
your-Glue-job-nameeyour-Glue-job-run-idpelos seus.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
Execute o comando
get-metric-data:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
Métricas de observabilidade
A observabilidade do AWS Glue traça o perfil e envia as seguintes métricas do Amazon CloudWatch a cada 30 segundos. Algumas dessas métricas podem ser visíveis na página de monitoramento de execução de trabalhos do AWS Glue Studio.
| Métrica | Descrição | Categoria |
|---|---|---|
| glue.driver.skewness.stage |
Categoria métrica: job_performance Distorção na execução dos estágios do Spark: essa métrica é um indicador do quanto o tempo máximo de duração da tarefa em um determinado estágio é comparado à duração mediana da tarefa nesse estágio. Ela captura a assimetria da execução, que pode ser causada pela assimetria dos dados de entrada ou por uma transformação (por exemplo, junção assimétrica). Os valores dessa métrica estão na faixa de [0, infinito[, em que 0 significa que a razão entre o tempo máximo e a mediana de execução das tarefas, entre todas as tarefas no estágio, é menor que um determinado fator de distorção do estágio. O fator de assimetria de estágio padrão é "5" e pode ser sobrescrito via spark conf: spark.metrics.conf.driver.source.glue.jobPerformance.skewnessFactor Um valor de assimetria de estágio de 1 significa que a proporção é o dobro do fator de assimetria do estágio. O valor de assimetria do estágio é atualizado a cada 30 segundos para refletir a assimetria atual. O valor no final do estágio reflete a assimetria do estágio final. Essa métrica em nível de estágio é usada para calcular a métrica em nível de trabalho. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e observabilityGroup (job_performance) Estatísticas válidas: média, máximo, mínimo, porcentagem Unidade: Contagem |
job_performance |
| glue.driver.skewness.job |
Categoria métrica: job_performance A assimetria do trabalho é o máximo da assimetria ponderada de todos os estágios. A assimetria do estágio (glue.driver.skewness.stage) é ponderada com a duração do estágio. Isso é para evitar situações extremas quando um estágio muito assimétrico está realmente funcionando por um tempo muito curto em relação a outros estágios (e, portanto, sua assimetria não é significativa para a performance geral do trabalho e não vale a pena tentar resolver sua assimetria). Essa métrica é atualizada após a conclusão de cada estágio e, portanto, o último valor reflete a assimetria geral real do trabalho. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e observabilityGroup (job_performance) Estatísticas válidas: média, máximo, mínimo, porcentagem Unidade: Contagem |
job_performance |
| glue.succeed.ALL |
Categoria métrica: erro Número total de execuções de trabalhos com êxito para completar o quadro das categorias de falhas Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (count) e ObservabilityGroup (error) Estatística válida: SUM Unidade: Contagem |
erro |
| glue.error.ALL |
Categoria métrica: erro Número total de erros de execução de trabalho para completar o quadro das categorias de falhas Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (count) e ObservabilityGroup (error) Estatística válida: SUM Unidade: Contagem |
erro |
| glue.error.[error category] |
Categoria métrica: erro Na verdade, este é um conjunto de métricas que são atualizadas somente quando a execução de um trabalho falha. A categorização de erros ajuda na triagem e na depuração. Quando a execução de uma tarefa falha, o erro que causa a falha é categorizado e a métrica da categoria de erro correspondente é definida como 1. Isso ajuda a realizar análises de falhas ao longo do tempo, bem como a análise geral de erros de trabalhos para identificar as categorias de falhas mais comuns e começar a resolvê-las. O AWS Glue tem 28 categorias de erro, incluindo as categorias de erro OUT_OF_MEMORY (driver e executor), PERMISSION, SYNTAX e THROTTLING. As categorias de erro também incluem as categorias de erro COMPILATION, LAUNCH e TIMEOUT. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (count) e ObservabilityGroup (error) Estatística válida: SUM Unidade: Contagem |
erro |
| glue.driver.workerUtilization |
Categoria métrica: resource_utilization A porcentagem dos trabalhadores alocados que são realmente usados. Se não for bom, o ajuste de escala automático pode ajudar. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatísticas válidas: média, máximo, mínimo, porcentagem Unidade: porcentagem |
resource_utilization |
| glue.driver.memory.heap.[available | used] |
Categoria métrica: resource_utilization A memória heap disponível/usado do driver durante a execução do trabalho. Isso ajuda a entender as tendências de uso da memória, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à memória. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: bytes |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
Categoria métrica: resource_utilization A memória heap usada pelo driver (%) durante a execução do trabalho. Isso ajuda a entender as tendências de uso da memória, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à memória. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.driver.memory.non-heap.[available | used] |
Categoria métrica: resource_utilization A memória não heap disponível/usado do driver durante a execução do trabalho. Isso ajuda a entender as tendências de uso da memória, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à memória. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: bytes |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
Categoria métrica: resource_utilization A memória não heap usada pelo driver (%) durante a execução do trabalho. Isso ajuda a entender as tendências de uso da memória, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à memória. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.driver.memory.total.[available | used] |
Categoria métrica: resource_utilization A memória total do driver disponível/usada durante a execução do trabalho. Isso ajuda a entender as tendências de uso da memória, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à memória. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: bytes |
resource_utilization |
| glue.driver.memory.total.used.percentage |
Categoria métrica: resource_utilization A memória total usada pelo driver (%) durante a execução do trabalho. Isso ajuda a entender as tendências de uso da memória, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à memória. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.ALL.memory.heap.[available | used] |
Categoria métrica: resource_utilization A memória heap disponível/usada dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: bytes |
resource_utilization |
| glue.ALL.memory.heap.used.percentage |
Categoria métrica: resource_utilization A memória heap usada dos executores (%). ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.ALL.memory.non-heap.[available | used] |
Categoria métrica: resource_utilization A memória não heap disponível/usada dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: bytes |
resource_utilization |
| glue.ALL.memory.non-heap.used.percentage |
Categoria métrica: resource_utilization A memória não heap usada (%) dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.ALL.memory.total.[available | used] |
Categoria métrica: resource_utilization A memória total disponível/usada dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: bytes |
resource_utilization |
| glue.ALL.memory.total.used.percentage |
Categoria métrica: resource_utilization A memória total usada (%) dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.driver.disk.[available_GB | used_GB] |
Categoria métrica: resource_utilization O espaço em disco disponível/usado do driver durante a execução do trabalho. Isso ajuda a entender as tendências de uso do disco, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à falta de espaço em disco. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: gigabytes |
resource_utilization |
| glue.driver.disk.used.percentage] |
Categoria métrica: resource_utilization O espaço em disco disponível/usado do driver durante a execução do trabalho. Isso ajuda a entender as tendências de uso do disco, especialmente ao longo do tempo, o que pode ajudar a evitar possíveis falhas, além de depurar falhas relacionadas à falta de espaço em disco. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.ALL.disk.[available_GB | used_GB] |
Categoria métrica: resource_utilization O espaço em disco disponível/usado dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: gigabytes |
resource_utilization |
| glue.ALL.disk.used.percentage |
Categoria métrica: resource_utilization O espaço em disco disponível/usado/usado(%) dos executores. ALL significa todos os executores. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Estatística válida: média Unidade: porcentagem |
resource_utilization |
| glue.driver.bytesRead |
Categoria métrica: throughput O número de bytes lidos por fonte de entrada nessa execução de trabalho, bem como para TODAS as fontes. Isso ajuda a entender o volume de dados e suas mudanças ao longo do tempo, o que ajuda a resolver problemas como assimetria de dados. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) e Source (local da fonte de dados) Estatística válida: média Unidade: bytes |
throughput |
| glue.driver.[recordsRead | filesRead] |
Categoria métrica: throughput O número de registros/arquivos lidos por fonte de entrada nessa execução de trabalho, bem como para TODAS as fontes. Isso ajuda a entender o volume de dados e suas mudanças ao longo do tempo, o que ajuda a resolver problemas como assimetria de dados. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) e Source (local da fonte de dados) Estatística válida: média Unidade: Contagem |
throughput |
| glue.driver.partitionsRead |
Categoria métrica: throughput O número de partições lidas por fonte de entrada do Amazon S3 nessa execução de trabalho, bem como para TODAS as fontes. Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) e Source (local da fonte de dados) Estatística válida: média Unidade: Contagem |
throughput |
| glue.driver.bytesWrittten |
Categoria métrica: throughput O número de bytes gravados por coletor de saída nessa execução de trabalho, bem como para TODOS os coletores. Isso ajuda a compreender o volume de dados e como ele evolui ao longo do tempo, o que ajuda a resolver problemas como a assimetria do processamento Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) e Source (local do coletor de dados) Estatística válida: média Unidade: bytes |
throughput |
| glue.driver.[recordsWritten | filesWritten] |
Categoria métrica: throughput O número de registros/arquivos gravados por coletor de saída nessa execução de trabalho, bem como para TODOS os coletores. Isso ajuda a compreender o volume de dados e como ele evolui ao longo do tempo, o que ajuda a resolver problemas como a assimetria do processamento Dimensões válidas: JobName (o nome do trabalho do AWS Glue), JobRunId (a ID de JobRun. ou ALL), Type (gauge), ObservabilityGroup (resource_utilization) e Source (local do coletor de dados) Estatística válida: média Unidade: Contagem |
throughput |
Categorias de erros
| Categorias de erros | Descrição |
|---|---|
| COMPILATION_ERROR | Os erros surgem durante a compilação do código Scala. |
| CONNECTION_ERROR | Os erros surgem durante a conexão com um serviço/host remoto/serviço de banco de dados etc. |
| DISK_NO_SPACE_ERROR |
Os erros surgem quando não há mais espaço em disco no driver/executor. |
| OUT_OF_MEMORY_ERROR | Os erros surgem quando não há mais espaço na memória do driver/executor. |
| IMPORT_ERROR | Os erros surgem ao importar dependências. |
| INVALID_ARGUMENT_ERROR | Erros surgem quando os argumentos de entrada são inválidos/ilegais. |
| PERMISSION_ERROR | Os erros surgem quando não há permissão para serviços, dados etc. |
| RESOURCE_NOT_FOUND_ERROR |
Os erros surgem quando os dados, a localização etc. não existem. |
| QUERY_ERROR | Os erros surgem da execução da consulta do Spark SQL. |
| SYNTAX_ERROR | Os erros surgem quando há um erro de sintaxe no script. |
| THROTTLING_ERROR | Os erros surgem ao atingir a limitação de simultaneidade de serviços ou ao exceder a limitação de cotas de serviço. |
| DATA_LAKE_FRAMEWORK_ERROR | Os erros surgem de estruturas de data lake com suporte nativo do AWS Glue, como Hudi, Iceberg etc. |
| UNSUPPORTED_OPERATION_ERROR | Os erros surgem ao realizar uma operação não compatível. |
| RESOURCES_ALREADY_EXISTS_ERROR | Os erros surgem quando um recurso a ser criado ou adicionado já existe. |
| GLUE_INTERNAL_SERVICE_ERROR | Os erros surgem quando há um problema de serviço interno do AWS Glue. |
| GLUE_OPERATION_TIMEOUT_ERROR | Os erros surgem quando uma operação do AWS Glue atinge o tempo limite. |
| GLUE_VALIDATION_ERROR | Os erros surgem quando um valor exigido não pôde ser validado para um trabalho do AWS Glue. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | Os erros surgem quando o mesmo trabalho transcreve o mesmo bucket de origem e grava no mesmo destino ou em outro simultaneamente (simultaneidade >1) |
| LAUNCH_ERROR | Os erros surgem durante a fase de lançamento do trabalho do AWS Glue. |
| DYNAMODB_ERROR | Os erros genéricos surgem do serviço do Amazon DynamoDB. |
| GLUE_ERROR | Os erros genéricos surgem do serviço do AWS Glue. |
| LAKEFORMATION_ERROR | Os erros genéricos surgem do serviço do AWS Lake Formation. |
| REDSHIFT_ERROR | Os erros genéricos surgem do serviço do Amazon Redshift. |
| S3_ERROR | Os erros genéricos surgem do serviço do Amazon S3. |
| SYSTEM_EXIT_ERROR | Erro genérico de saída do sistema. |
| TIMEOUT_ERROR | Os erros genéricos surgem quando o trabalho falha devido ao tempo limite da operação. |
| UNCLASSIFIED_SPARK_ERROR | Os erros genéricos surgem do Spark. |
| UNCLASSIFIED_ERROR | Categoria de erro padrão. |
Limitações
nota
O glueContext deve ser inicializado para publicar as métricas.
Na Dimensão de origem, o valor é o caminho ou o nome da tabela do Amazon S3, dependendo do tipo de fonte. Além disso, se a origem for JDBC e a opção de consulta for usada, a string de consulta será definida na dimensão de origem. Se o valor tiver mais de 500 caracteres, ele será reduzido em 500 caracteres. Abaixo, estão as limitações do valor:
-
Os caracteres não ASCII serão removidos.
Se o nome da fonte não contiver nenhum caractere ASCII, ele será convertido para <non-ASCII input>.
Limitações e considerações sobre métricas de throughput
-
O DataFrame e o DynamicFrame baseado em DataFrame (por exemplo, JDBC, leitura de parquet no Amazon S3) são compatíveis, no entanto, o DynamicFrame baseado em RDD (por exemplo, leitura de csv, json no Amazon S3 etc.) não é compatível. Tecnicamente, todas as leituras e gravações visíveis na UI do Spark são compatíveis.
-
A métrica
recordsReadserá emitida se a fonte de dados for uma tabela de catálogo e o formato for JSON, CSV, text ou Iceberg. -
As métricas
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWritteneglue.driver.throughput.filesWrittennão estão disponíveis nas tabelas JDBC e Iceberg. -
As métricas podem estar atrasadas. Se o trabalho for concluído em cerca de um minuto, talvez não haja métricas de throughput nas métricas do Amazon CloudWatch.
