As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Depurar exceções OOM e anomalias de trabalho
Você pode depurar exceções de memória insuficiente (OOM) e anomalias de trabalho no AWS Glue. As seções a seguir descrevem cenários para depuração de exceções de memória insuficiente do driver do Apache Spark ou um executor do Spark.
Depurar uma exceção OOM do driver
Nesse cenário, um trabalho do Spark está lendo um grande número de arquivos pequenos do Amazon Simple Storage Service (Amazon S3). Ele converte os arquivos no formato Apache Parquet e, em seguida, os grava no Amazon S3. O driver do Spark está sendo executado sem memória. A entrada de dados do Amazon S3 tem mais de 1 milhão de arquivos em diferentes partições do Amazon S3.
O código perfilado é assim:
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
Visualizar as métricas perfiladas no console do AWS Glue
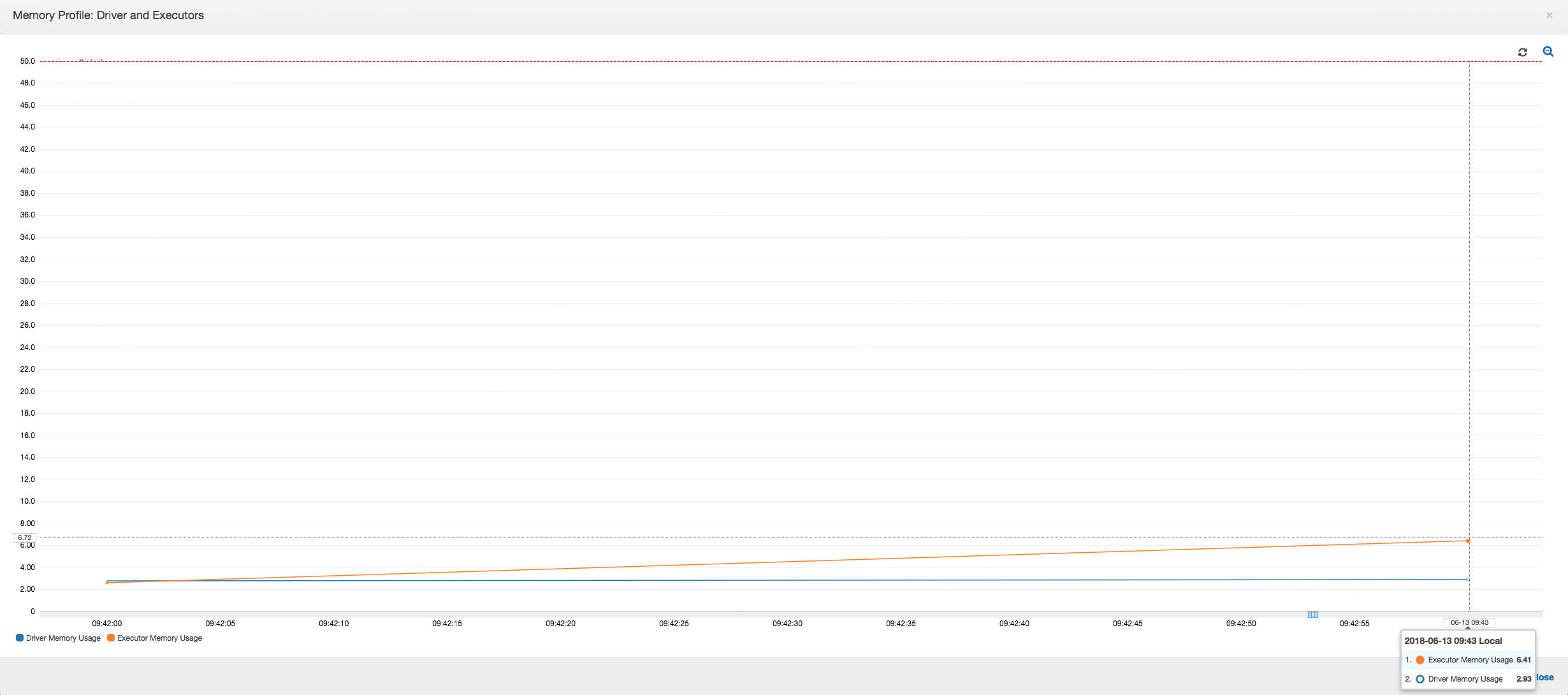
O gráfico a seguir mostra o uso de memória como uma porcentagem para o driver e executores. Esse uso é representado como um ponto de dados cuja média é calculada com base nos valores relatados no último minuto. Você pode ver no perfil de memória do trabalho que a memória do driver ultrapassa o limite de 50% de uso rapidamente. Por outro lado, a média de uso de memória em todos os executores ainda é menos de 4%. Isso mostra claramente anomalia com a execução do driver nesse trabalho do Spark.
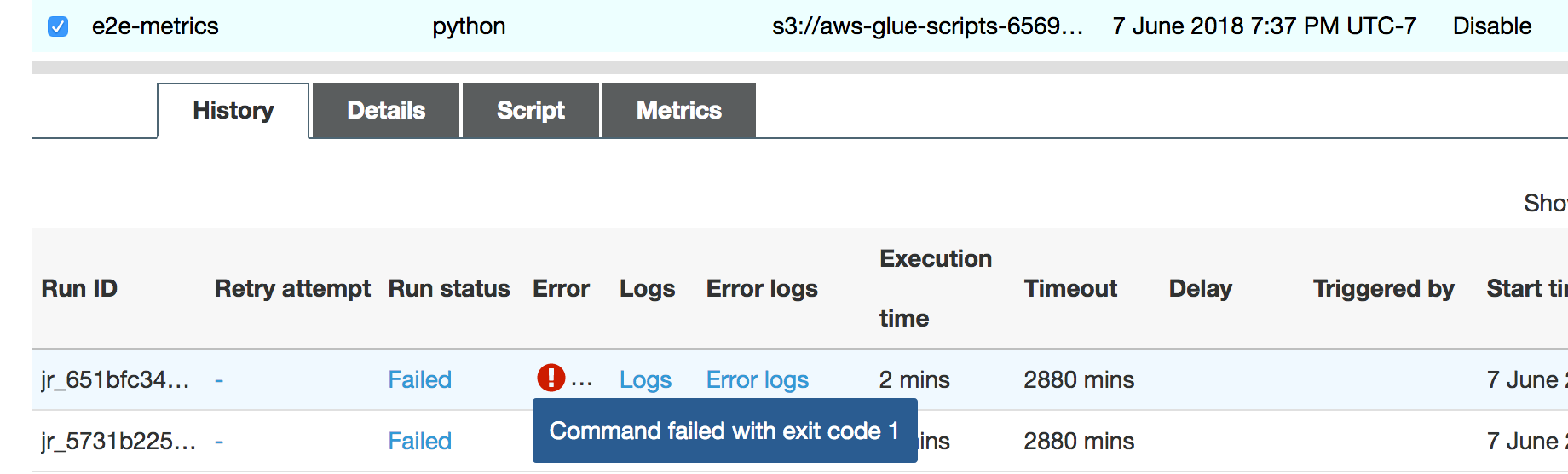
A execução do trabalho logo falha, e o seguinte erro é exibido na guia History (Histórico) no console do AWS Glue: Command Failed with Exit Code 1 (Falha do comando com código de saída 1). Essa string de erro significa que o trabalho falhou devido a um erro sistêmico, que neste caso é a falta de memória do driver.
No console, escolha o link Error logs (Logs de erro) na guia History (Histórico) para confirmar a descoberta do CloudWatch Logs sobre a OOM do driver. Procure "Error" nos logs de erro do trabalho para confirmar que foi uma exceção OOM que falhou o trabalho:
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
Na guia History (Histórico) do trabalho, escolha Logs. Você pode encontrar as seguintes evidências da execução do driver no CloudWatch Logs no início do trabalho. O driver do Spark tenta listar todos os arquivos em todos os diretórios, cria um InMemoryFileIndex e inicia uma tarefa por arquivo. Isso, por sua vez, resulta no driver do Spark precisar manter uma grande quantidade de estado na memória para rastrear todas as tarefas. Ele armazena em cache a lista completa de um grande número de arquivos para o índice na memória, o que resulta em um driver OOM.
Corrigir o processamento de vários arquivos usando agrupamento
Você pode corrigir o processamento de vários arquivos usando o recurso de agrupamento no AWS Glue. O agrupamento é habilitado automaticamente quando você usa quadros dinâmicos e quando o conjunto de dados de entrada tem um grande número de arquivos (mais de 50.000). Agrupar permite reunir vários arquivos em um grupo, e isso permite que uma tarefa processe todo o grupo em vez de um único arquivo. Como resultado, o driver do Spark armazena significativamente menos estado na memória para rastrear menos tarefas. Para obter mais informações sobre como habilitar manualmente o agrupamento para o seu conjunto de dados, consulte Ler arquivos de entrada em grupos maiores.
Para verificar o perfil de memória do trabalho do AWS Glue, crie o perfil do código a seguir com agrupamento habilitado:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
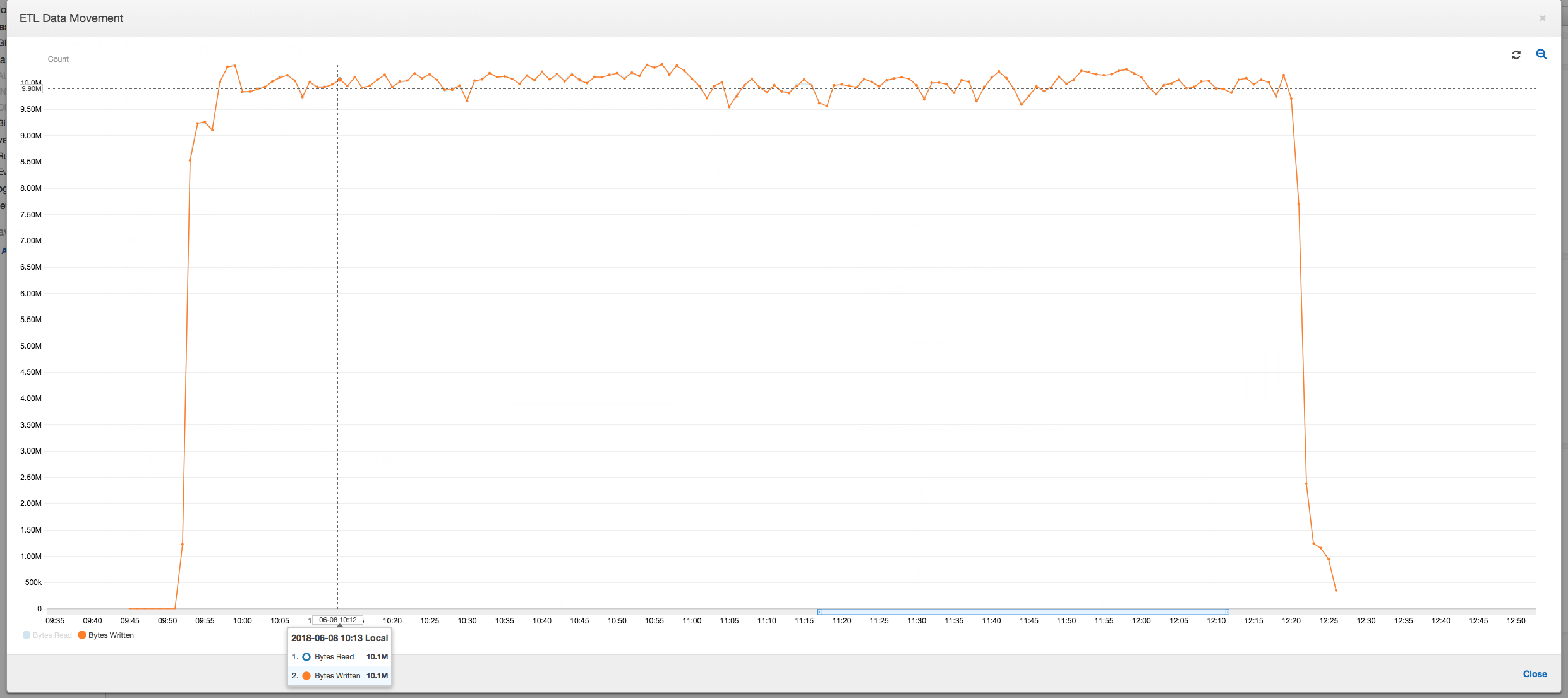
Você pode monitorar o perfil de memória e a movimentação de dados ETL no perfil de trabalho do AWS Glue.
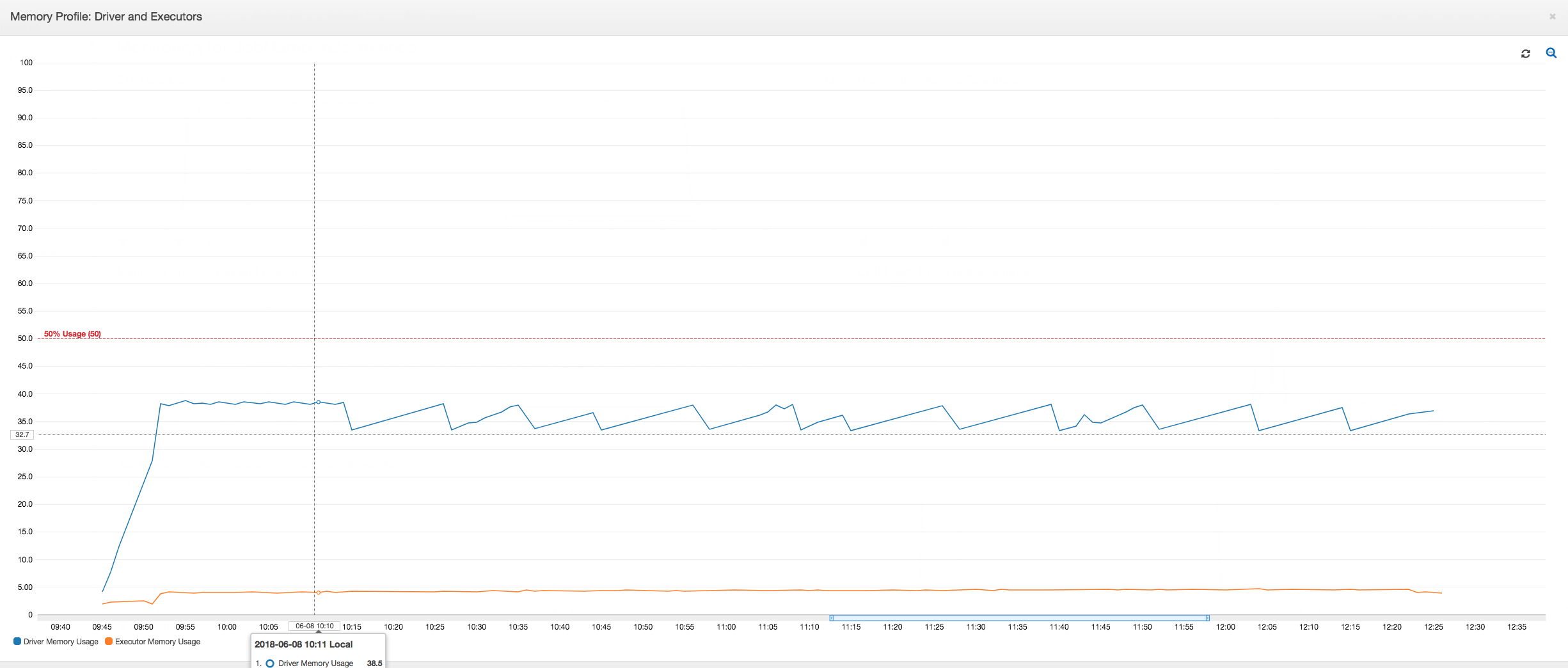
O driver é executado abaixo do limite de 50% de uso de memória ao longo de toda a duração do trabalho do AWS Glue. Os executores transmitem os dados do Amazon S3, os processam e os gravam no Amazon S3. Como resultado, eles consomem menos de 5% de memória a qualquer momento.
O perfil de movimentação de dados abaixo mostra o número total de bytes do Amazon S3 que são lidos e gravados no último minuto por todos os executores conforme o trabalho progride. Ambos seguem um padrão semelhante conforme os dados são transmitidos em todos os executores. O trabalho termina o processamento de um milhão de arquivos em menos de três horas.
Depurar uma exceção OOM do executor
Nesse cenário, você pode saber como depurar exceções OOM que podem ocorrer em executores do Apache Spark. O código a seguir usa o leitor Spark MySQL para ler uma grande tabela de cerca de 34 milhões de linhas em um dataframe do Spark. Em seguida, ele grava no Amazon S3 em formato Parquet. Você pode fornecer as propriedades da conexão e usar as configurações padrão do Spark para ler a tabela.
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
Visualizar as métricas perfiladas no console do AWS Glue
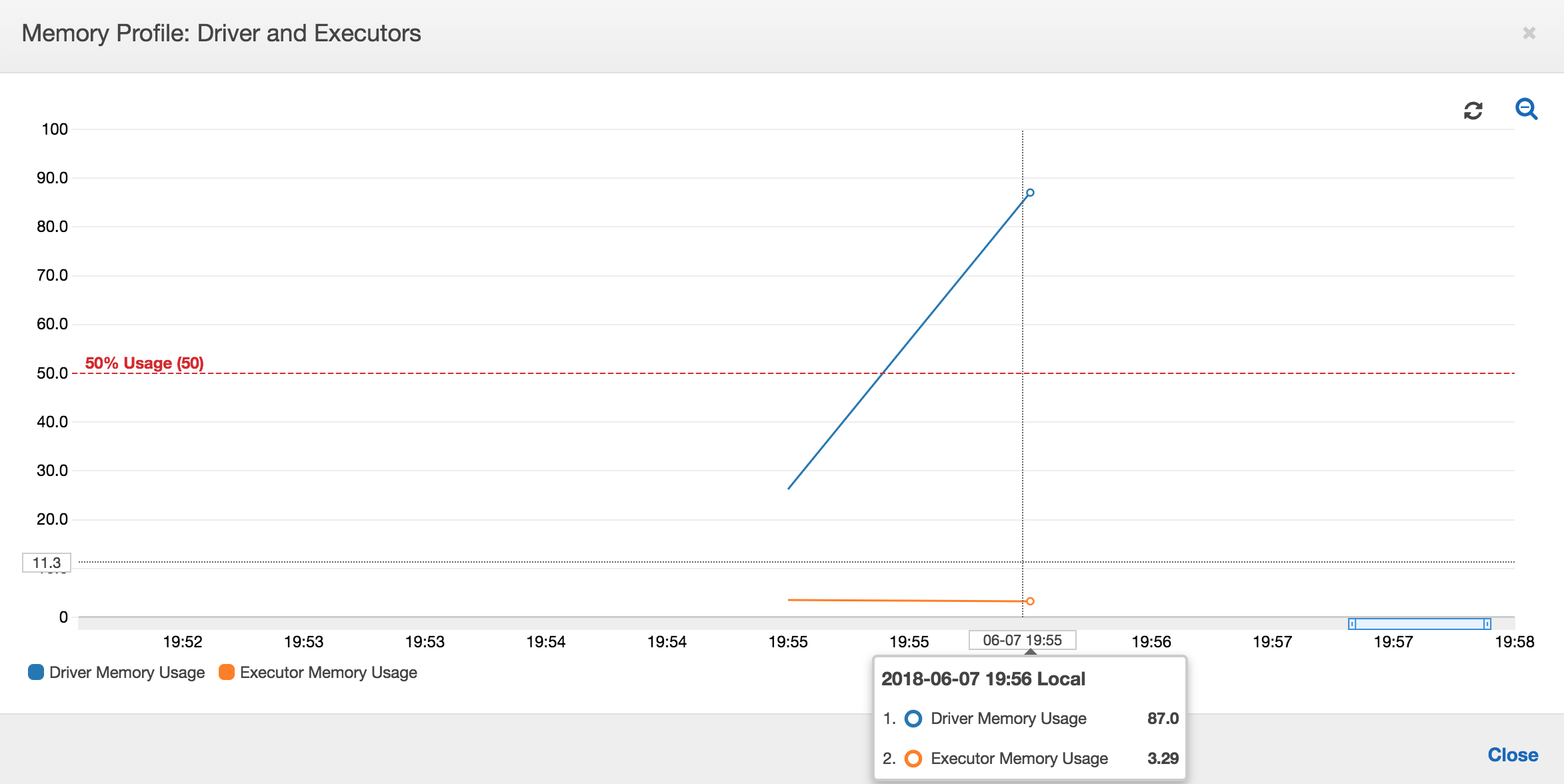
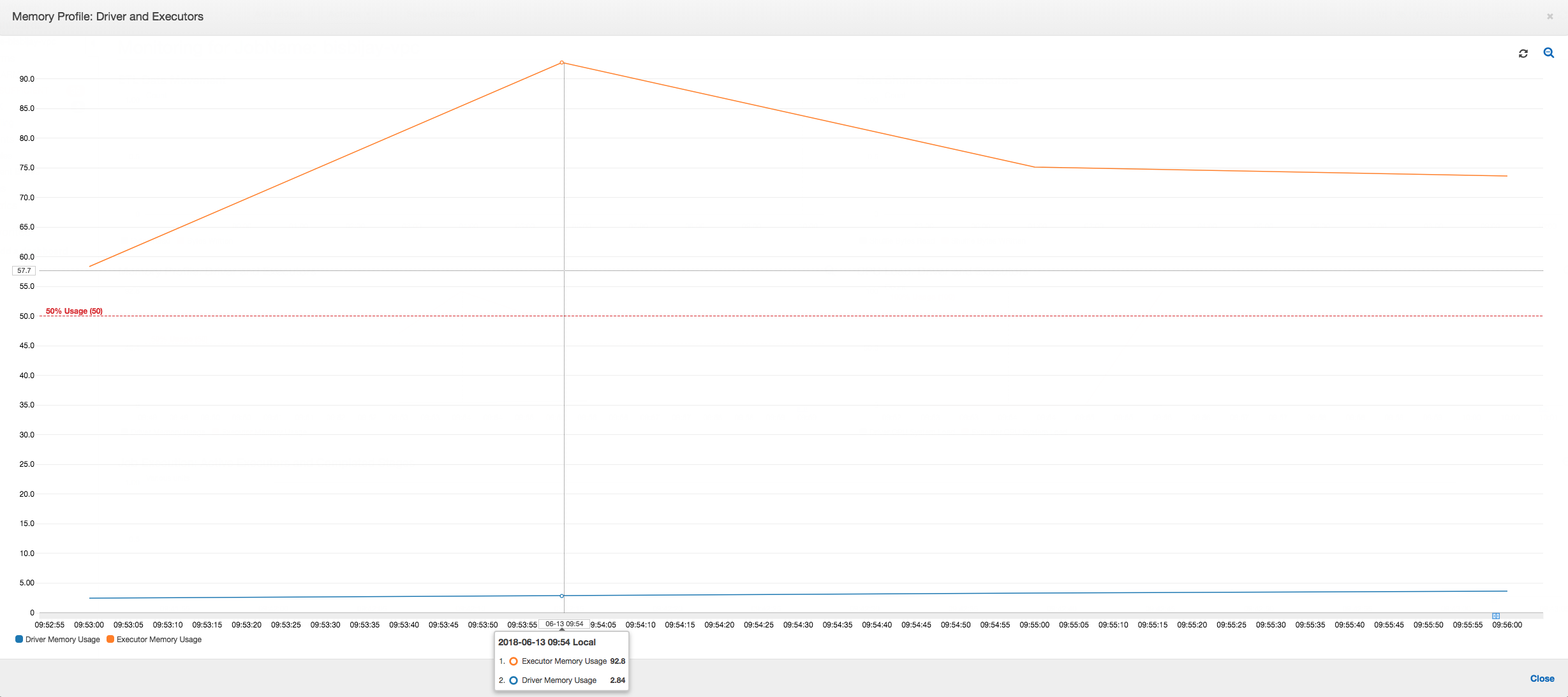
Se a inclinação do gráfico de uso de memória for positiva e ultrapassar 50%, e se ocorrer uma falha no trabalho antes que a próxima métrica seja emitida, o esgotamento da memória será uma causa provável. O seguinte gráfico mostra que, dentro de um minuto da execução, a média de uso de memória em todos os executores ultrapassa rapidamente 50%. O uso atinge até 92%, e o contêiner que executa o executor é interrompido pelo Apache Hadoop YARN.
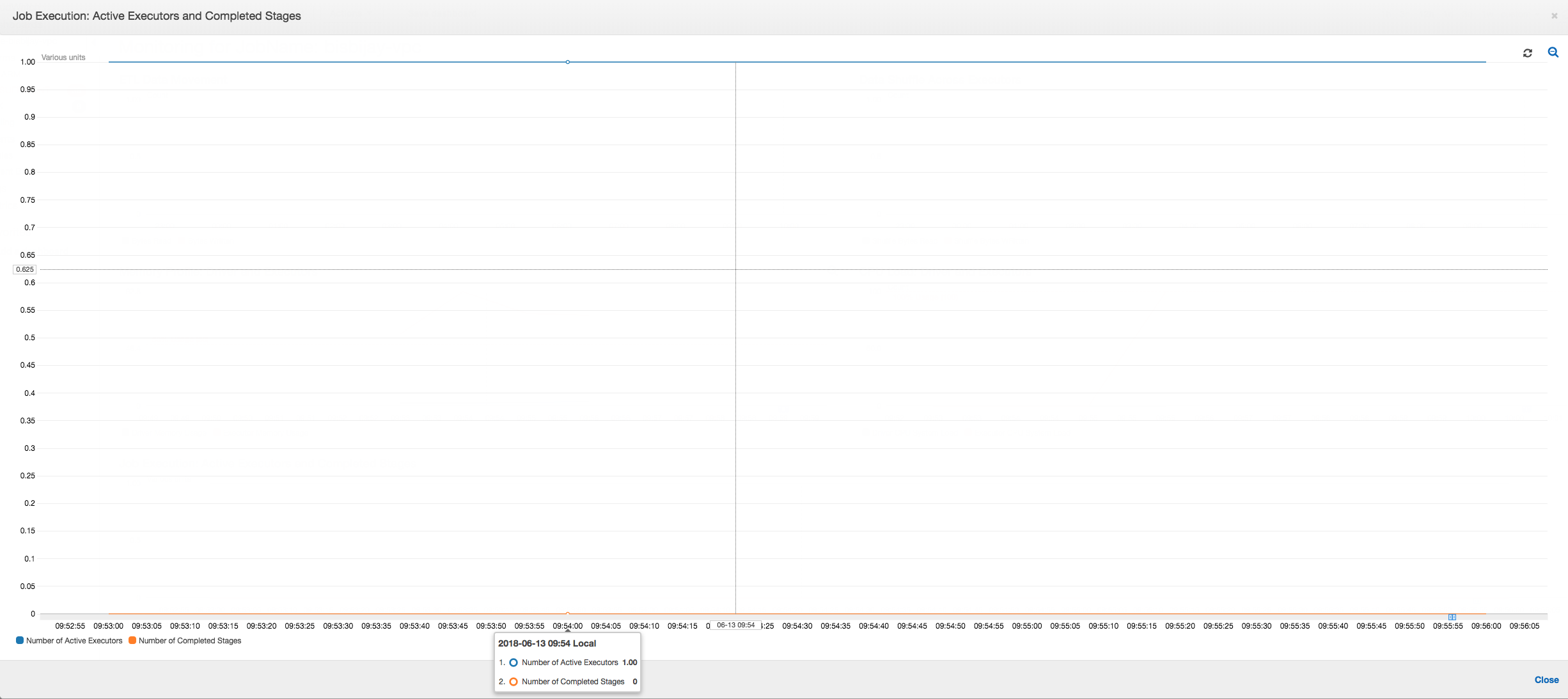
Como o seguinte gráfico mostra, há sempre um único executor em execução até o trabalho falhar. Isso ocorre porque um novo executor é iniciado para substituir o executor eliminado. As leituras da fonte de dados JDBC não são paralelizadas por padrão porque isso exigiria particionamento de tabela em uma coluna e abrir várias conexões. Como resultado, apenas um executor lê na tabela completa sequencialmente.
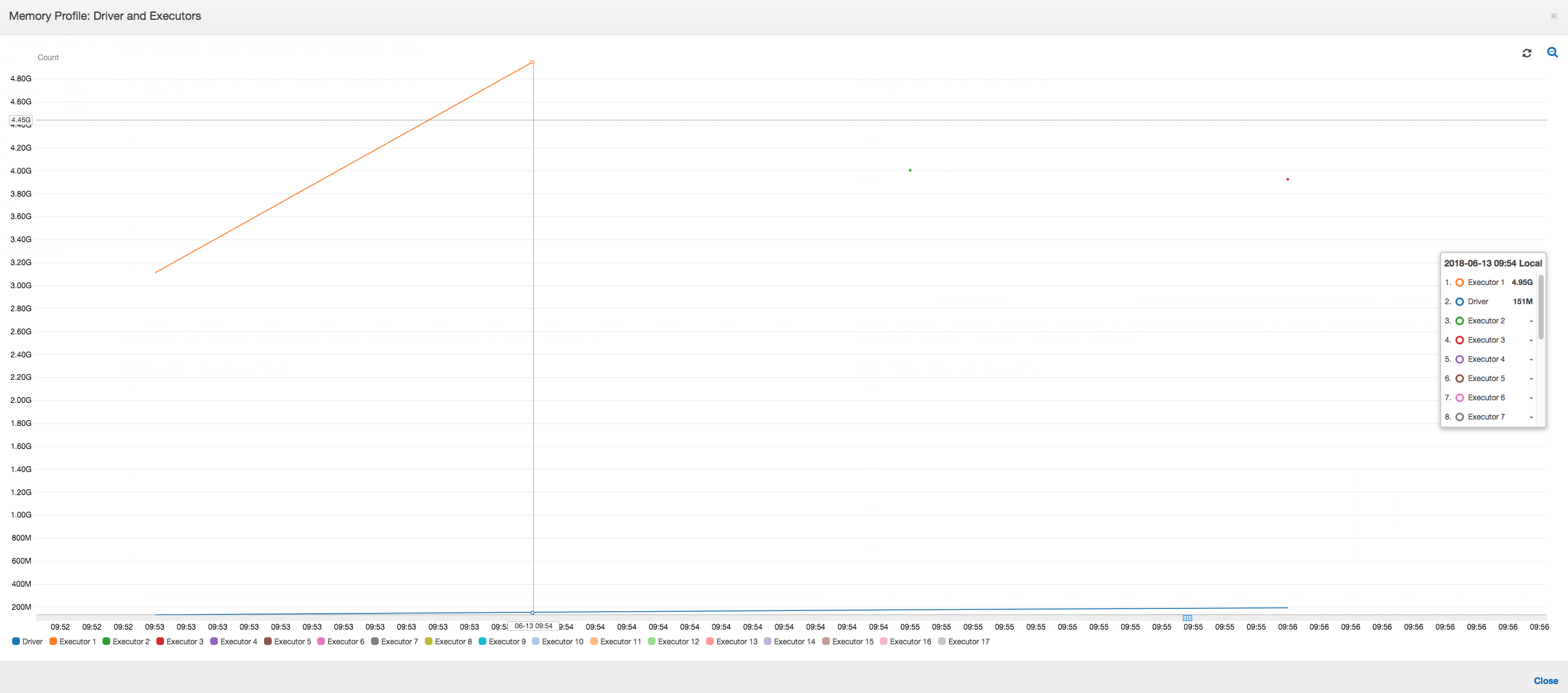
Como o seguinte gráfico mostra, o Spark tenta iniciar uma nova tarefa quatro vezes antes da falha no trabalho. Você pode ver o perfil de memória de três executores. Cada executor usa rapidamente toda sua memória. O quarto executor fica sem memória e o trabalho falha. Como resultado, a métrica não é relatada imediatamente.
Você pode confirmar na string de erro no console do AWS Glue que o trabalho falhou devido a exceções OOM, conforme mostrado na imagem a seguir.

Logs de saída de trabalho: para confirmação adicional da descoberta de uma exceção OOM de executor, consulte o CloudWatch Logs. Quando você pesquisar por Error, encontrará os quatro executores interrompidos aproximadamente na mesma janela de tempo, como mostrado no painel de métricas. Todos são encerrados pelo YARN à medida que excedem os limites de memória.
Executor 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Executor 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Executor 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Executor 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Corrigir a configuração do tamanho da busca usando quadros dinâmicos do AWS Glue
O executor ficou sem memória ao ler a tabela JDBC porque a configuração padrão para o tamanho da busca JDBC do Spark é zero. Isso significa que o driver JDBC no executor do Spark tenta buscar as 34 milhões de linhas no banco de dados em conjunto e as armazena em cache, embora o Spark transmita por meio de linhas, uma de cada vez. Com o Spark, você pode evitar esse cenário ao configurar o parâmetro de tamanho de busca como um valor padrão diferente de zero.
Você também pode corrigir esse problema usando os quadros dinâmicos do AWS Glue. Por padrão, os quadros dinâmicos usam um tamanho de busca de 1.000 linhas, que normalmente é um valor suficiente. Como resultado, o executor não consome mais de 7% da memória total. O trabalho do AWS Glue é concluído em menos de dois minutos com apenas um único executor. Embora usar quadros dinâmicos do AWS Glue seja a abordagem recomendada, também é possível definir o tamanho de busca usando a propriedade fetchsize do Apache Spark. Consulte o Guia do Spark SQL, DataFrames e conjuntos de dados
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Métricas perfiladas normais: a memória do executor com quadros dinâmicos do AWS Glue jamais excede o limite seguro, conforme mostrado na imagem a seguir. Ele transmite nas linhas do banco de dados e armazena em cache apenas 1.000 linhas no driver JDBC a qualquer momento. Não ocorre uma exceção de falta de memória.