Você pode usar a interface do usuário Web do Apache Spark para monitorar e depurar trabalhos de ETL do AWS Glue em execução no sistema de trabalhos do AWS Glue e também aplicativos Spark em execução em endpoints de desenvolvimento do AWS Glue. A interface do usuário do Spark permite que você verifique o seguinte para cada trabalho:
-
O cronograma de eventos de cada estágio do Spark
-
Um gráfico acíclico dirigido (DAG) do trabalho
-
Planos físicos e lógicos para consultas SparkSQL
-
As variáveis de ambiente do Spark subjacentes para cada trabalho
Para obter mais informações sobre como usar a interface do usuário Web do Spark, consulte Interface do usuário Web
É possível ver a interface do usuário do Spark no console do AWS Glue. Isso está disponível quando um trabalho do AWS Glue é executado no AWS Glue 3.0 ou versões posteriores com logs gerados no formato Padrão (em vez de legado), o que é o padrão para trabalhos mais recentes. Se você tiver arquivos de log maiores que 0,5 GB, poderá ativar o suporte a logs contínuos para execuções de trabalhos em versões do AWS Glue 4.0 ou posteriores para simplificar o arquivamento, a análise e a solução de problemas de logs.
Você pode habilitar a interface do usuário do Spark usando o console do AWS Glue ou a AWS Command Line Interface (AWS CLI). Quando você habilita a interface do usuário do Spark, os trabalhos de ETL do AWS Glue e as aplicações do Spark em endpoints de desenvolvimento do AWS Glue podem fazer backup dos logs de eventos do Spark em um local especificado por você no Amazon Simple Storage Service (Amazon S3). É possível usar os logs de eventos armazenados em backup no Amazon S3 com a interface do usuário do Spark em tempo real à medida que o trabalho é executado e após a conclusão do trabalho. Enquanto os logs permanecerem no Amazon S3, a interface do usuário do Spark no console do AWS Glue poderá visualizá-los.
Permissões
Para usar a interface do usuário do Spark no console do AWS Glue, é possível usar o UseGlueStudio ou adicionar todas as APIs de serviço individuais. Todas as APIs são necessárias para aproveitar ao máximo a interface do usuário do Spark. No entanto, os usuários podem acessar os recursos da interface do usuário do Spark adicionando suas APIs de serviço à permissão do IAM para acesso refinado.
RequestLogParsing é o mais crítico, pois executa a análise dos logs. As APIs restantes destinam-se à leitura dos respectivos dados analisados. Por exemplo, GetStages fornece acesso aos dados sobre todas as etapas de um trabalho do Spark.
A lista de APIs de serviço da interface do usuário do Spark mapeadas em UseGlueStudio é mostrada no exemplo de política abaixo. A política abaixo fornece acesso para uso somente dos recursos da interface do usuário do Spark. Para adicionar mais permissões, como Amazon S3 e IAM, consulte Criar políticas personalizadas do IAM para AWS Glue Studio.
A lista de APIs de serviço da interface do usuário do Spark mapeadas em UseGlueStudio é mostrada no exemplo de política abaixo. Ao usar uma API de serviço da interface do usuário do Spark, use o seguinte namespace: glue:<ServiceAPI>.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowGlueStudioSparkUI",
"Effect": "Allow",
"Action": [
"glue:RequestLogParsing",
"glue:GetLogParsingStatus",
"glue:GetEnvironment",
"glue:GetJobs",
"glue:GetJob",
"glue:GetStage",
"glue:GetStages",
"glue:GetStageFiles",
"glue:BatchGetStageFiles",
"glue:GetStageAttempt",
"glue:GetStageAttemptTaskList",
"glue:GetStageAttemptTaskSummary",
"glue:GetExecutors",
"glue:GetExecutorsThreads",
"glue:GetStorage",
"glue:GetStorageUnit",
"glue:GetQueries",
"glue:GetQuery"
],
"Resource": [
"*"
]
}
]
}
Limitações
-
A interface do usuário do Spark no console do AWS Glue não está disponível para execuções de trabalhos que ocorreram antes de 20 de novembro de 2023, pois elas estão no formato de log legado.
-
A interface do Spark no console do AWS Glue não é compatível com logs contínuos, para o AWS Glue 4.0, como aqueles gerados por padrão em trabalhos de streaming. A soma máxima de todos os arquivos de eventos de logs acumulados gerados é 2 GB. Para trabalhos do AWS Glue sem suporte a logs contínuos, o tamanho máximo do arquivo de eventos de log suportado pelo SparkUI é de 0,5 GB.
-
A interface de usuário do Spark sem servidor não está disponível para registros de eventos do Spark armazenados em um bucket do Amazon S3 que só pode ser acessado pela sua VPC.
Exemplo: interface do usuário Web do Apache Spark
Este exemplo mostra como usar a interface do usuário do Spark para entender a performance do trabalho. As capturas de tela mostram a interface do usuário Web do Spark fornecida por um servidor de histórico autogerenciado do Spark. A interface do usuário do Spark no console do AWS Glue oferece visualizações semelhantes. Para obter mais informações sobre como usar a interface do usuário Web do Spark, consulte Interface do usuário Web
Veja a seguir um exemplo de uma aplicação Spark que lê de duas fontes de dados, realiza uma transformação de junção e a grava no Amazon S3 no formato Parquet.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import count, when, expr, col, sum, isnull
from pyspark.sql.functions import countDistinct
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'])
df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json")
df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json")
df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter')
df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/")
job.commit()A visualização do DAG a seguir mostra os diferentes estágios nesse trabalho do Spark.
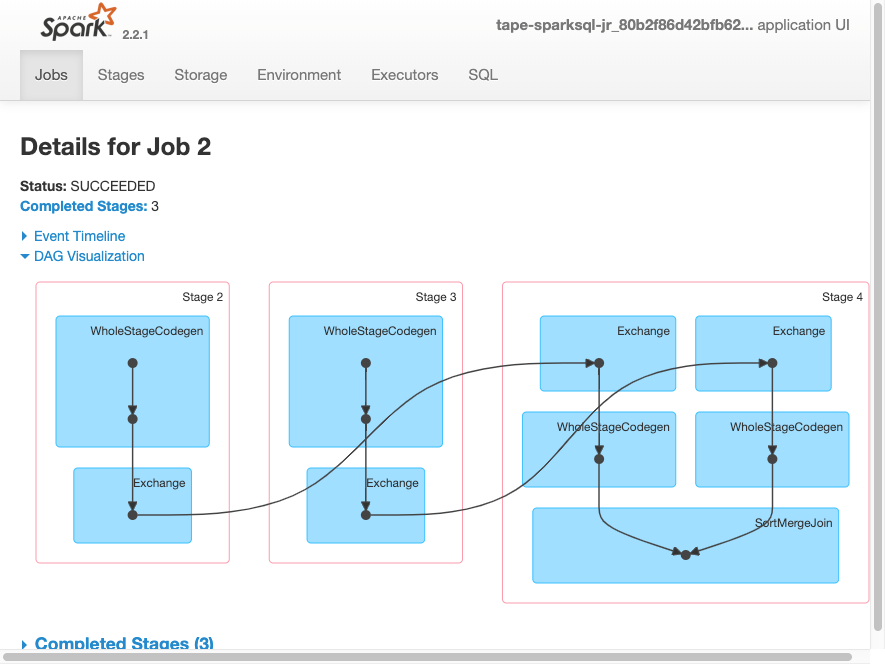
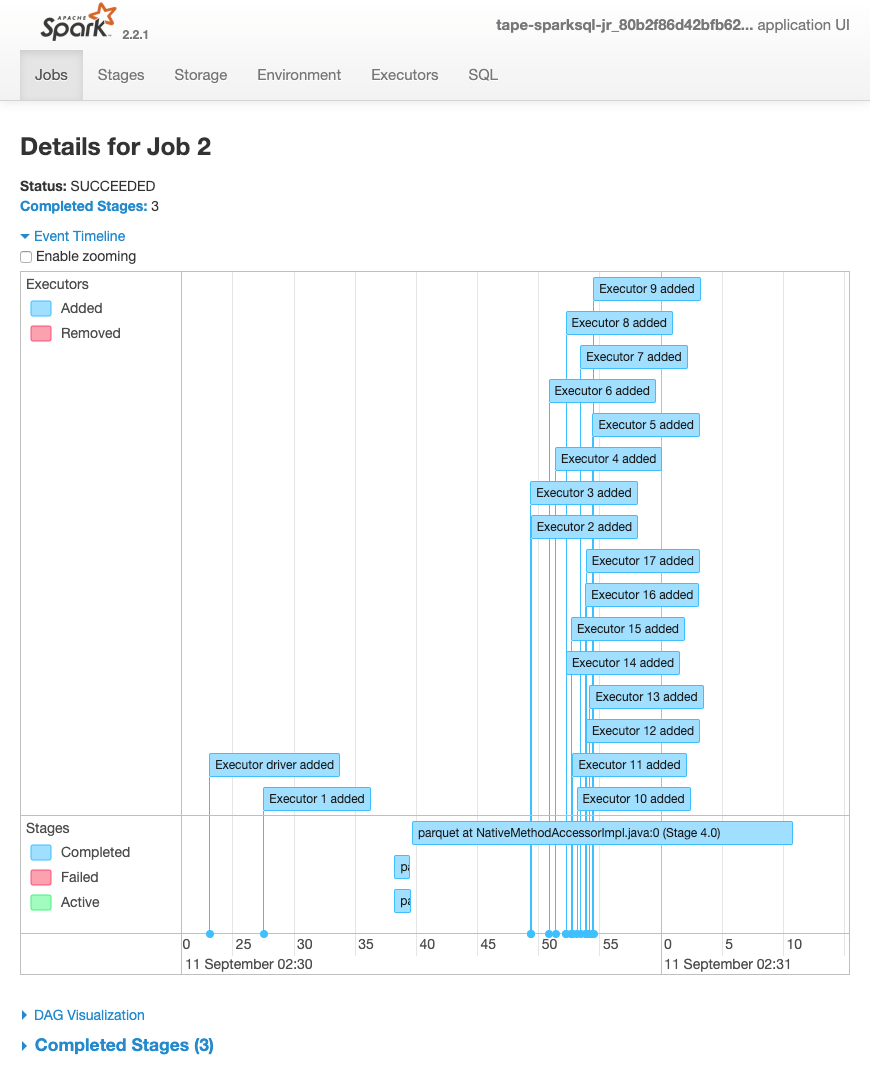
O cronograma de eventos a seguir para um trabalho mostra o início, a execução e o encerramento de diferentes executores do Spark.
A tela a seguir mostra os detalhes dos planos de consulta do SparkSQL:
-
Plano lógico examinado
-
Plano lógico analisado
-
Plano lógico otimizado
-
Plano físico para execução

Tópicos
