As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Integração com o registro de esquemas do AWS Glue
Estas seções descrevem integrações com o registro de esquemas do AWS Glue. Os exemplos nesta seção mostram um esquema com formato de dados AVRO. Para obter mais exemplos, incluindo esquemas com formato de dados JSON, consulte os testes de integração e as informações no arquivo ReadMe no repositório de código aberto do registro de esquemas do AWS Glue
Tópicos
- Caso de uso: conectar registro de esquemas ao Amazon MSK ou Apache Kafka
- Caso de uso: integração do Amazon Kinesis Data Streams ao registro de esquemas do AWS Glue
- Caso de uso: Amazon Managed Service for Apache Flink
- Caso de uso: integração com o AWS Lambda
- Caso de uso: AWS Glue Data Catalog
- Caso de uso: transmissão no AWS Glue
- Caso de uso: Apache Kafka Streams
Caso de uso: conectar registro de esquemas ao Amazon MSK ou Apache Kafka
Vamos supor que você está gravando dados em um tópico do Apache Kafka. Você pode seguir estas etapas para começar.
Crie um cluster do Amazon Managed Streaming for Apache Kafka (Amazon MSK) ou do Apache Kafka com pelo menos um tópico. Se estiver criando um cluster do Amazon MSK, você pode usar o AWS Management Console. Para obter mais informações: Conceitos básicos do uso do Amazon MSK no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
Siga o passo Instalar as bibliotecas SerDe acima.
Para criar registros de esquemas, esquemas ou versões de esquema, siga as instruções na seção Conceitos básicos do registro de esquemas deste documento.
Inicie seus produtores e consumidores para usar o registro de esquemas para gravar e ler registros de/para o tópico do Amazon MSK ou Apache Kafka. Um exemplo de código de produtor e consumidor pode ser encontrado no arquivo ReadMe
das bibliotecas Serde. A biblioteca do registro de esquemas no produtor serializará automaticamente o registro e decorará o registro com um ID de versão do esquema. Se o esquema desse registro tiver sido inserido, ou se o registro automático estiver ativado, o esquema será registrado no registro do esquemas.
O consumidor lendo do tópico do Amazon MSK ou Apache Kafka, usando a biblioteca do registro de esquemas do AWS Glue, pesquisará automaticamente o esquema no registro do esquemas.
Caso de uso: integração do Amazon Kinesis Data Streams ao registro de esquemas do AWS Glue
Essa integração requer que você tenha um fluxo de dados existente do Amazon Kinesis. Para obter mais informações, consulte Conceitos básicos do Amazon Kinesis Data Streams no Guia do desenvolvedor do Amazon Kinesis Data Streams.
Há duas maneiras de interagir com os dados em um fluxo de dados do Kinesis.
Por meio das bibliotecas do Kinesis Producer Library (KPL) e Kinesis Client Library (KCL) em Java. Suporte a várias linguagens não é fornecido.
Por maio das APIs
PutRecords,PutRecordeGetRecordsdo Kinesis Data Streams disponíveis no AWS SDK for Java.
Se você usa atualmente as bibliotecas KPL/KCL, recomendamos continuar usando esse método. Há versões atualizadas da KCL e KPL com o registro de esquemas integrado, como mostrado nos exemplos. Caso contrário, você pode usar o código de exemplo para utilizar o registro do esquemas do AWS Glue se estiver usando as APIs do KDS diretamente.
A integração do registro de esquemas só está disponível com a KPL v0.14.2 ou posterior e com a KCL v2.3 ou posterior. A integração do registro de esquemas com JSON só está disponível com a KPL v0.14.8 ou posterior e com a KCL v2.3.6 ou posterior.
Interagir com dados usando o Kinesis SDK V2
Esta seção descreve a interação com o Kinesis usando o Kinesis SDK V2
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Interagir com dados usando as bibliotecas KPL/KCL
Esta seção descreve a integração do Kinesis Data Streams com o registro de esquemas usando as bibliotecas KPL/KCL. Para obter mais informações sobre o uso da KPL/KCL, consulte Desenvolver produtores usando a biblioteca de produtor do Amazon Kinesis no Guia do desenvolvedor do Amazon Kinesis Data Streams.
Configurar o registro de esquemas na KPL
Configure a definição do esquema para os dados, o formato de dados e o nome do esquema criados no registro de esquemas do AWS Glue.
Opcionalmente, configure o objeto
GlueSchemaRegistryConfiguration.Transmita o objeto de esquema para
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Configurar a biblioteca do cliente Kinesis
Você desenvolverá seu consumidor da biblioteca do cliente Kinesis em Java. Para obter mais informações, consulte Desenvolver um consumidor da biblioteca do cliente Kinesis em Java no Guia do desenvolvedor do Amazon Kinesis Data Streams.
Crie uma instância de
GlueSchemaRegistryDeserializertransmitindo um objetoGlueSchemaRegistryConfiguration.Transmita o
GlueSchemaRegistryDeserializerpararetrievalConfig.glueSchemaRegistryDeserializer.Acesse o esquema de mensagens recebidas chamando
kinesisClientRecord.getSchema().GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Interagir com dados usando as APIs do Kinesis Data Streams
Esta seção descreve a integração do Kinesis Data Streams com o registro de esquemas usando as APIs do Kinesis Data Streams.
Atualize estas dependências do Maven:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>No produtor, adicione as informações de cabeçalho do esquema usando a API
PutRecordsouPutRecordno Kinesis Data Streams.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);No produtor, use a API
PutRecordsouPutRecordpara colocar o registro no fluxo de dados.No consumidor, remova o registro do esquema do cabeçalho e serialize um registro do esquema Avro.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Interagir com dados usando as APIs do Kinesis Data Streams
O código de exemplo a seguir usa as APIs PutRecords e GetRecords.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Caso de uso: Amazon Managed Service for Apache Flink
O Apache Flink é um framework de código aberto popular e mecanismo de processamento distribuído para computações com estado sobre fluxos de dados vinculados e não vinculados. O Amazon Managed Service for Apache Flink é um serviço totalmente gerenciado da AWS que permite a criação e o gerenciamento de aplicações do Apache Flink para processar dados de transmissão.
O Apache Flink de código aberto fornece uma série de fontes e coletores. Por exemplo, origens de dados predefinidas incluem leitura de arquivos, diretórios e soquetes e ingestão de dados de coleções e iteradores. Os conectores Apache Flink DataStream fornecem código para o Apache Flink para realizar a interface com vários sistemas de terceiros, como Apache Kafka ou Kinesis, como fontes e/ou coletores.
Para obter mais informações, consulte o Guia do desenvolvedor do Amazon Kinesis Data Analytics.
Conector Apache Flink Kafka
O Apache Flink fornece um conector de fluxo de dados Apache Kafka para leitura e gravação de dados em tópicos do Kafka com garantias do tipo exatamente uma. Consumidor Kafka do Flink, FlinkKafkaConsumer, fornece acesso à leitura de um ou mais tópicos do Kafka. O produtor Kafka do Apache Flink, FlinkKafkaProducer, permite gravar uma transmissão de registros para um ou mais tópicos do Kafka. Para obter mais informações, consulte Conector do Apache Kafka
Conector de fluxos do Kinesis do Apache Flink
O conector de transmissão de dados do Kinesis fornece acesso aos Amazon Kinesis Data Streams. O FlinkKinesisConsumer é uma origem de dados de transmissão paralelo do tipo exatamente uma vez que assina várias transmissões do Kinesis dentro da mesma região de produto da AWS e que pode manipular de forma transparente a refragmentação de transmissões enquanto o trabalho é executado. Cada subtarefa do consumidor é responsável por buscar registros de dados de vários fragmentos do Kinesis. O número de fragmentos obtidos por cada subtarefa será alterado à medida que os fragmentos forem fechados e criados pelo Kinesis. O FlinkKinesisProducer usa a Kinesis Producer Library (KPL) para colocar dados de uma transmissão do Apache Flink em uma transmissão do Kinesis. Para obter mais informações, consulte Conector do Amazon Kinesis Streams
Para obter mais informações, consulte o repositório do GitHub de registro do AWS Glue
Integração com o Apache Flink
A biblioteca SerDes fornecida com o registro de esquemas se integra com o Apache Flink. Para trabalhar com o Apache Flink, é necessário implementar as interfaces SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema e GlueSchemaRegistryAvroDeserializationSchema, que você pode vincular aos conectores Apache Flink.
Adicionar uma dependência do registro do esquemas do AWS Glue na aplicação do Apache Flink
Para configurar as dependências de integração para o registro de esquemas do AWS Glue na aplicação do Apache Flink:
Adicione a dependência ao arquivo
pom.xml.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Integração do Kafka ou do Amazon MSK com o Apache Flink
Você pode usar o Managed Service for Apache Flink, com o Kafka como fonte ou com o Kafka como coletor.
Kafka como uma fonte
O diagrama a seguir mostra a integração do Kinesis Data Streams com o Managed Service for Apache Flink com o Kafka como uma fonte.
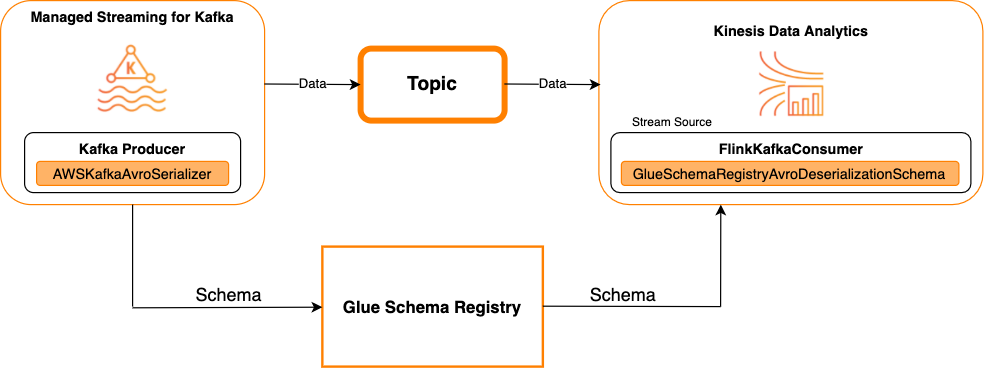
Kafka como um coletor
O diagrama a seguir mostra a integração do Kinesis Data Streams com o Managed Service for Apache Flink com o Kafka como uma coletor.
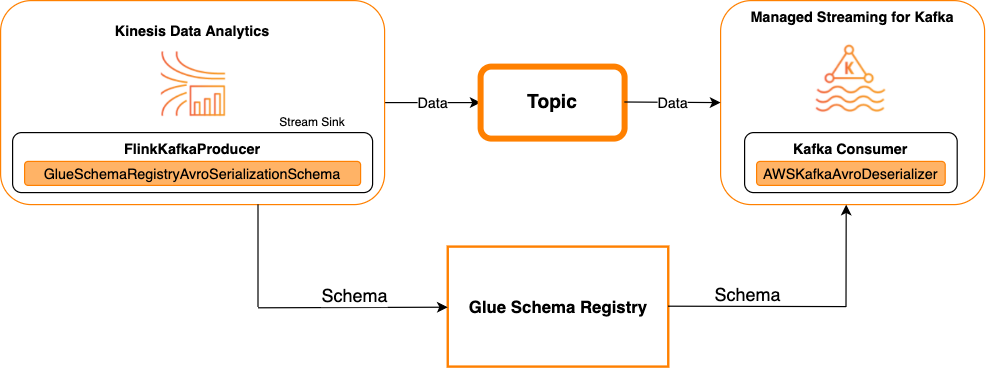
Para integrar o Kafka (ou o Amazon MSK) com o Managed Service for Apache Flink com o Kafka como uma fonte ou como um coletor, faça as alterações de código abaixo. Adicione os blocos de código em negrito ao seu respectivo código nas seções análogas.
Se o Kafka for a fonte, use o código de desserialização (bloco 2). Se o Kafka for o coletor, use o código serializador (bloco 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Integração do Kinesis Data Streams com o Apache Flink
Você pode usar o Managed Service for Apache Flink com o Kinesis Data Streams como fonte ou como coletor.
Kinesis Data Streams como uma fonte
O diagrama a seguir mostra a integração do Kinesis Data Streams com o Managed Service for Apache Flink com o Kinesis Data Streams como uma fonte.
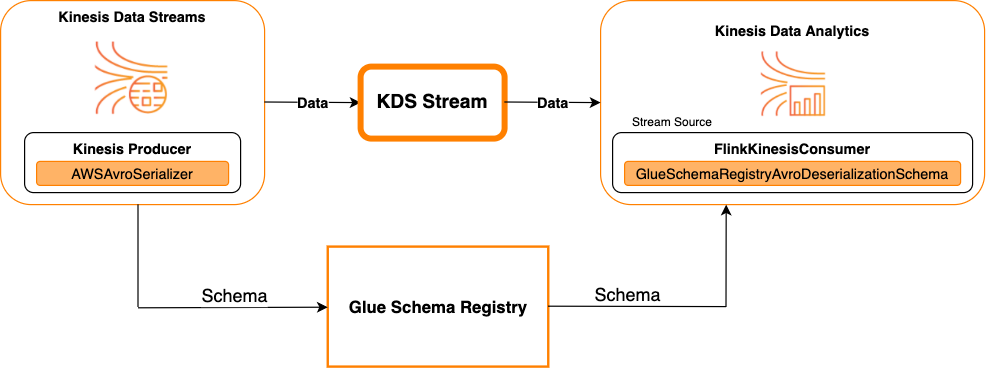
Kinesis Data Streams como um coletor
O diagrama a seguir mostra a integração do Kinesis Data Streams com o Managed Service for Apache Flink com o Kinesis Data Streams como uma coletor.
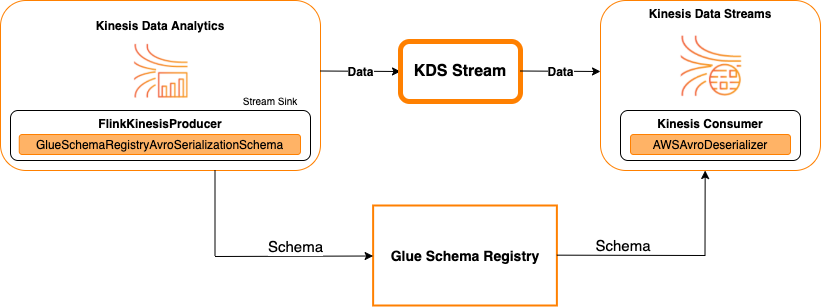
Para integrar o Kinesis Data Streams com o Managed Service for Apache Flink com o Kinesis Data Streams como uma origem ou como um coletor, faça as alterações de código abaixo. Adicione os blocos de código em negrito ao seu respectivo código nas seções análogas.
Se o Kinesis Data Streams for a fonte, use o código de desserialização (bloco 2). Se o Kinesis Data Streams for o coletor, use o código de serialização (bloco 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Caso de uso: integração com o AWS Lambda
Para usar uma função do AWS Lambda como um consumidor do Apache Kafka/Amazon MSK e desserializar mensagens codificadas em Avro usando o registro de esquemas do AWS Glue, acesse a página do MSK Labs
Caso de uso: AWS Glue Data Catalog
As tabelas do AWS Glue suportam esquemas que você pode especificar manualmente ou por referência aoregistro de esquemas do AWS Glue. O registro de esquemas se integra ao Data Catalog para permitir que você opcionalmente use esquemas armazenados no registro de esquemas ao criar ou atualizar tabelas ou partições do AWS Glue no Data Catalog. Para identificar uma definição de esquema no registro de esquemas, no mínimo, você precisa saber o ARN do esquema do qual ele faz parte. Uma versão de esquema que contém uma definição de esquema pode ser referenciada por seu UUID ou número de versão. Há sempre uma versão de esquema, a versão “mais recente”, que pode ser pesquisada sem saber seu número de versão ou UUID.
Ao chamar as operações CreateTable ou UpdateTable, você transmitirá uma estrutura TableInput que contém um StorageDescriptor, que pode ter uma SchemaReference para um esquema existente no registro de esquemas. Da mesma forma, quando você chama as APIs GetTable ou GetPartition, a resposta pode conter o esquema e a SchemaReference. Quando uma tabela ou partição é criada usando referências de esquema, o Data Catalog tenta buscar o esquema para essa referência. Caso não seja possível localizar o esquema no registro de esquemas, ele retorna um esquema vazio na reposta de GetTable. Caso contrário, a resposta possui o esquema e a referência do esquema.
Também é possível executar as ações no console do AWS Glue.
Para realizar essas operações e criar, atualizar ou exibir informações de esquema, você deve conceder ao usuário que faz a chamada um perfil do IAM que forneça permissões para a API GetSchemaVersion.
Adicionar uma tabela ou atualizar o esquema de uma tabela
A adição de uma nova tabela a partir de um esquema existente vincula a tabela a uma versão específica do esquema. Depois que as novas versões de esquema forem registradas, você poderá atualizar essa definição de tabela na página View table (Exibir tabela) no console do AWS Glue ou usando a API Ação UpdateTable (Python: update_table).
Adicionar uma tabela de um esquema existente
É possível criar uma tabela do AWS Glue a partir de uma versão de esquema no registro usando o console do AWS Glue ou a API CreateTable.
API do AWS Glue
Ao chamar a API CreateTable, você transmitirá uma TableInput que contém um StorageDescriptor que, por sua vez, contém uma SchemaReference para um esquema existente no registro de esquemas.
Console do AWS Glue
Para criar uma tabela no console do AWS Glue:
-
Faça login no AWS Management Console e abra o console do AWS Glue em https://console.aws.amazon.com/glue/
. No painel de navegação, em Data catalog (Catálogo de dados), escolha Tables (Tabelas).
No menu Add Tables (Adicionar tabelas), escolha Add table from existing schema (Adicionar tabela do esquema existente).
Configure as propriedades da tabela e o datastore de acordo com o guia do desenvolvedor do AWS Glue.
Na página Choose a Glue schema (Escolher um esquema do Glue), selecione o Registry (Registro) em que o esquema reside.
Escolha o Schema name (Nome do esquema) e selecione a Version (Versão) do esquema a ser aplicada.
Revise a pré-visualização do esquema e escolha Next (Próximo).
Revise e crie a tabela.
O esquema e a versão aplicada à tabela são exibidos na coluna Glue schema (Esquema do Glue) na lista de tabelas. Você pode exibir a tabela para ver mais detalhes.
Atualizar o esquema de uma tabela
Quando uma nova versão de esquema se torna disponível, você pode querer atualizar o esquema de uma tabela usando a API Ação UpdateTable (Python: update_table) ou o console do AWS Glue.
Importante
Ao atualizar o esquema de uma tabela existente que tenha um esquema do AWS Glue especificado manualmente, o novo esquema referenciado no registro de esquemas pode ser incompatível. Isso pode resultar na falha de seus trabalhos.
API do AWS Glue
Ao chamar a API UpdateTable, você transmitirá uma TableInput que contém um StorageDescriptor que, por sua vez, contém uma SchemaReference para um esquema existente no registro de esquemas.
Console do AWS Glue
Para atualizar o esquema de uma tabela a partir do console do AWS Glue:
-
Faça login no AWS Management Console e abra o console do AWS Glue em https://console.aws.amazon.com/glue/
. No painel de navegação, em Data catalog (Catálogo de dados), escolha Tables (Tabelas).
Exiba a tabela na lista de tabelas.
Clique em Update schema (Atualizar esquema) na caixa que informa sobre uma nova versão.
Revise as diferenças entre o esquema atual e o novo.
Escolha Show all schema differences (Mostrar todas as diferenças do esquema) para ver mais detalhes.
Escolha Save table (Salvar tabela) para aceitar a nova versão.
Caso de uso: transmissão no AWS Glue
A transmissão no AWS Glue consome dados de fontes de transmissão e executa operações de ETL antes de gravar em um coletor de saída. É possível especificar a fonte de entrada da transmissão usando uma tabela de dados ou diretamente, especificando a configuração da fonte.
A transmissão no AWS Glue oferece suporte a uma tabela do tipo Data Catalog para a fonte de transmissão criada com o esquema presente no AWS Glue Schema Registry. Você pode criar um esquema no AWS Glue Schema Registry e criar uma tabela do AWS Glue com uma fonte de transmissão usando esse esquema. Essa tabela do AWS Glue pode ser usada como entrada para um trabalho de transmissão do AWS Glue para desserialização de dados no fluxo de entrada.
É importante ressaltar que quando o esquema no AWS Glue Schema Registry muda, você precisa reiniciar o trabalho de transmissão do AWS Glue para refletir as alterações no esquema.
Caso de uso: Apache Kafka Streams
A API Apache Kafka Streams é uma biblioteca cliente para processamento e análise de dados armazenados no Apache Kafka. Esta seção descreve a integração do Apache Kafka Streams com o registro de esquemas do AWS Glue, que permite que você gerencie e imponha esquemas em suas aplicações de transmissão de dados. Para obter mais informações sobre o Apache Kafka Streams, consulte Apache Kafka Streams
Integração com as bibliotecas SerDes
Existe uma classe GlueSchemaRegistryKafkaStreamsSerde com a qual você pode configurar uma aplicação do Streams.
Código de exemplo da aplicação Kafka Streams
Para usar o registro de esquemas do AWS Glue dentro de uma aplicação Apache Kafka Streams:
Configure a aplicação Kafka Streams.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Crie uma transmissão a partir do tópico avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Processe os registros de dados (o exemplo filtra aqueles registros cujo valor de favorite_color é rosa ou onde o valor de quantidade é 15).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Grave os resultados de volta no tópico avro-output.
result.to("avro-output");Inicie a aplicação Apache Kafka Streams.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Resultados de implantação
Esses resultados mostram o processo de filtragem de registros que foram filtrados na etapa 3 como um favorite_color “rosa” ou o valor “15,0”.
Registros antes da filtragem:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Registros após a filtragem:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Caso de uso: Apache Kafka Connect
A integração do Apache Kafka Connect com o registro de esquemas do AWS Glue permite que você obtenha informações de esquema dos conectores. Os conversores Apache Kafka especificam o formato dos dados dentro do Apache Kafka e como traduzi-los em dados do Apache Kafka Connect. Cada usuário do Apache Kafka Connect precisará configurar esses conversores com base no formato em que deseja que seus dados sejam carregados do, ou armazenados no, Apache Kafka. Desta forma, você pode definir seus próprios conversores para traduzir os dados do Apache Kafka Connect para o tipo usado no registro de esquemas do AWS Glue (por exemplo: Avro) e utilizar nosso serializador para registrar seu esquema e fazer a serialização. Em seguida, os conversores também são capazes de usar nosso desserializador para desserializar os dados recebidos do Apache Kafka e convertê-los de volta em dados do Apache Kafka Connect. Um exemplo de diagrama de fluxo de trabalho é dado abaixo.
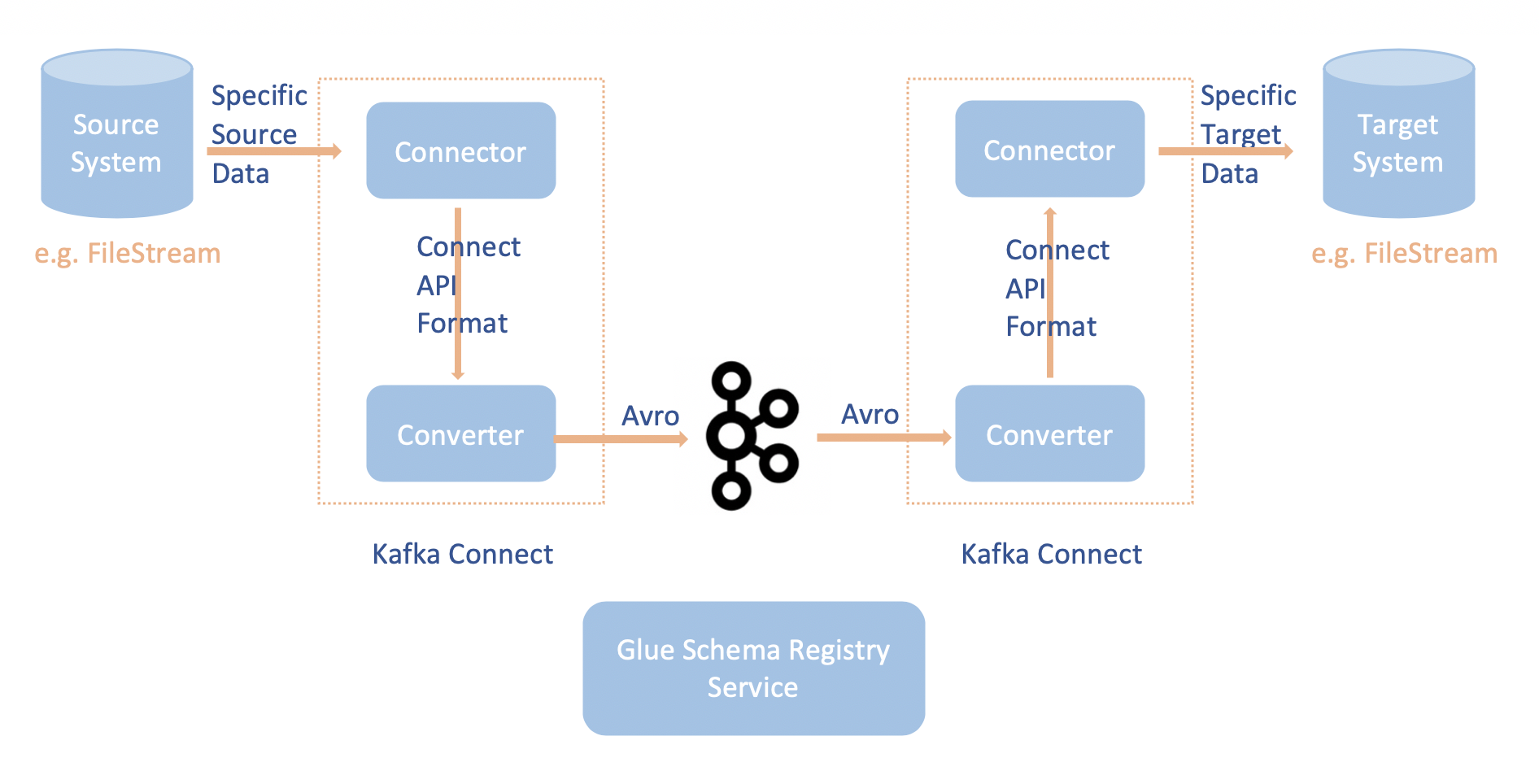
Instale o projeto
aws-glue-schema-registryclonando o repositório do Github para o registro de esquemas do AWS Glue. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesSe você planeja usar o Apache Kafka Connect no modo autônomo, atualize connect-standalone.properties usando as instruções abaixo para esta etapa. Se você planeja usar o Apache Kafka Connect no modo distribuído, atualize connect-avro-distributed.properties usando as mesmas instruções.
Adicione essas propriedades também ao arquivo de propriedades de conexão do Apache Kafka:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDAdicione o comando abaixo à seção Launch mode (Modo de execução) em kafka-run-class.sh:
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Adicione o comando abaixo à seção Launch mode (Modo de execução) em kafka-run-class.sh
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"A aparência deve ser semelhante a esta:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiSe estiver usando bash, execute os comandos abaixo para configurar seu CLASSPATH em seu bash_profile. Para qualquer outro shell, atualize o ambiente de acordo.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Opcional) Se você quiser testar com uma fonte de arquivo simples, clone o conector da fonte do arquivo.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/Na configuração do conector da fonte, edite o formato de dados para Avro, leitor de arquivos para
AvroFileReadere atualize um objeto Avro de exemplo a partir do caminho do arquivo em que você está lendo. Por exemplo:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstale o conector da fonte.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profileAtualize as propriedades do coletor em
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Inicie o conector da fonte (neste exemplo, é um conector de fonte de arquivo).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesExecute o conector do coletor (neste exemplo, é um conector de coletor de arquivos).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesPara obter um exemplo de uso do Kafka Connect, veja o script run-local-tests.sh na pasta de testes de integração no repositório do Github para o registro de esquemas do AWS Glue
.
