Usando a transformação Autobalance Processing para otimizar seu runtime
A transformação Autobalance Processing redistribui os dados entre os operadores para melhorar a performance. Isso ajuda nos casos em que os dados estão desbalanceados ou, como vêm da fonte, não permitem processamento paralelo suficiente. Isso é comum quando a fonte é compactada com gzip ou é JDBC. A redistribuição de dados tem um custo de performance módico, portanto, a otimização nem sempre compensará esse esforço se os dados já estiverem bem balanceados. Por baixo, a transformação usa a repartição do Apache Spark para reatribuir dados aleatoriamente entre um número de partições ideal para a capacidade do cluster. Para usuários avançados, é possível inserir um número de partições manualmente. Além disso, ele pode ser usado para otimizar a gravação de tabelas particionadas reorganizando os dados com base em colunas especificadas. Isso resulta em arquivos de saída mais consolidados.
-
Abra o painel Recurso e escolha Autobalance Processing para adicionar uma nova transformação ao diagrama do trabalho. O nó selecionado no momento da adição do nó será o nó superior.
-
(Opcional) Na guia Propriedades do nó, insira um nome para o nó no diagrama do trabalho. Se ainda não houver um nó pai selecionado, escolha um na lista Node parents (Nós pais) para usar como fonte de entrada para a transformação.
-
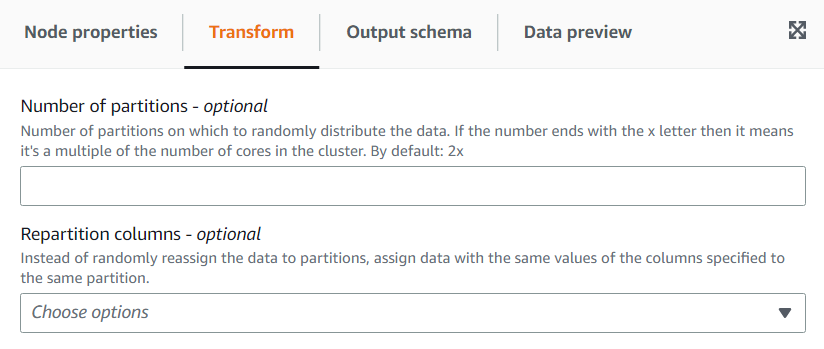
(Opcional) Na guia Transformação, você pode inserir um número de partições. Em geral, é recomendável que você deixe o sistema decidir esse valor, mas pode ajustar o multiplicador ou inserir um valor específico se precisar controlar isso. Se você for salvar os dados particionados por colunas, poderá escolher as mesmas colunas que as colunas de repartição. Dessa forma, minimizará o número de arquivos em cada partição e evitará muitos arquivos por partição, o que prejudicaria a performance das ferramentas que consultam esses dados.