Aviso de fim do suporte: em 7 de outubro de 2026,AWS o suporte para o.AWS IoT Greengrass Version 1 Depois de 7 de outubro de 2026, você não poderá mais acessar os AWS IoT Greengrass V1 recursos. Para obter mais informações, visite Migrar de AWS IoT Greengrass Version 1.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Opcional: configurar o dispositivo para qualificação de ML
O IDT for AWS IoT Greengrass fornece testes de qualificação de aprendizado de máquina (ML) para validar se seus dispositivos podem realizar inferência de ML localmente usando modelos treinados na nuvem.
Para executar testes de qualificação de ML, primeiro é preciso configurar os dispositivos conforme descrito em Configure seu dispositivo para executar testes de IDT. Depois, siga as etapas deste tópico para instalar dependências para as estruturas de ML que você deseja executar.
É necessária a versão 3.1.0 ou posterior do IDT para executar testes de qualificação de ML.
Instalar dependências de estrutura do ML
Todas as dependências de estrutura do ML devem ser instaladas no diretório /usr/local/lib/python3.x/site-packages. Para certificar-se de que estão instaladas no diretório correto, é recomendado usar permissões raiz sudo ao instalar as dependências. Os ambientes virtuais não oferecem suporte a testes de qualificação.
nota
Se você estiver testando funções do Lambda executadas com conteinerização (no modo de Contêiner do Greengrass, a criação de symlinks para bibliotecas Python em /usr/local/lib/python3.x não é compatível. Para evitar erros, instale as dependências no diretório correto.
Siga as etapas para instalar as dependências na estrutura de destino:
Instalar dependências do Apache MxNet
Os testes de qualificação do IDT para esta estrutura têm as seguintes dependências:
-
Python 3.6 ou Python 3.7.
nota
Se estiver usando Python 3.6, você deve criar um symblink de Python 3.7 para binários Python 3.6. Isso configura seu dispositivo para atender ao requisito Python para AWS IoT Greengrass. Por exemplo:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
Apache MXNet v1.2.1 ou posterior.
-
NumPy. A versão deve ser compatível com sua versão do MXNet.
Instalar o MXNet
Siga as instruções na documentação do MXNet para instalar o MXNet
nota
Se o Python 2.x e o Python 3.x estiverem instalados no seu dispositivo, use o Python 3.x nos comandos executados para instalar as dependências.
Validar a instalação do MXNet
Selecione uma das opções a seguir para validar a instalação do MXNet.
Opção 1: usar SSH para o seu dispositivo e executar scripts
-
SSH para o seu dispositivo.
-
Execute o script a seguir para verificar se as dependências estão instaladas corretamente.
sudo python3.7 -c "import mxnet; print(mxnet.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"A saída imprime o número da versão e o script deve sair sem erro.
Opção 2: executar o teste de dependência de IDT
-
Certifique-se de que
device.jsonesteja configurado para qualificação de ML. Para obter mais informações, consulte Configurar device.json para qualificação de ML. -
Execute o teste de dependências para a estrutura.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id mxnet_dependency_checkO resumo do teste exibe um resultado
PASSEDparamldependencies.
Instalar TensorFlow dependências
Os testes de qualificação do IDT para esta estrutura têm as seguintes dependências:
-
Python 3.6 ou Python 3.7.
nota
Se estiver usando Python 3.6, você deve criar um symblink de Python 3.7 para binários Python 3.6. Isso configura seu dispositivo para atender ao requisito Python para AWS IoT Greengrass. Por exemplo:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
TensorFlow 1.x.
Instalando TensorFlow
Siga as instruções na TensorFlow documentação para instalar o TensorFlow 1.x com pip
nota
Se o Python 2.x e o Python 3.x estiverem instalados no seu dispositivo, use o Python 3.x nos comandos executados para instalar as dependências.
Validando a instalação TensorFlow
Escolha uma das opções a seguir para validar a TensorFlow instalação.
Opção 1: usar SSH para o seu dispositivo e executar um script
-
SSH para o seu dispositivo.
-
Execute o script a seguir para verificar se a dependência está instalada corretamente.
sudo python3.7 -c "import tensorflow; print(tensorflow.__version__)"A saída imprime o número da versão e o script deve sair sem erro.
Opção 2: executar o teste de dependência de IDT
-
Certifique-se de que
device.jsonesteja configurado para qualificação de ML. Para obter mais informações, consulte Configurar device.json para qualificação de ML. -
Execute o teste de dependências para a estrutura.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id tensorflow_dependency_checkO resumo do teste exibe um resultado
PASSEDparamldependencies.
Instale dependências do Amazon SageMaker AI Neo Deep Learning Runtime (DLR)
Os testes de qualificação do IDT para esta estrutura têm as seguintes dependências:
-
Python 3.6 ou Python 3.7.
nota
Se estiver usando Python 3.6, você deve criar um symblink de Python 3.7 para binários Python 3.6. Isso configura seu dispositivo para atender ao requisito Python para AWS IoT Greengrass. Por exemplo:
sudo ln -spath-to-python-3.6/python3.6path-to-python-3.7/python3.7 -
SageMaker AI Neo DLR.
-
numpy.
Depois de instalar as dependências de teste do DLR, é preciso compilar o modelo.
Instalar o DLR
Siga as instruções na documentação do DLR para instalar o Neo DLR
nota
Se o Python 2.x e o Python 3.x estiverem instalados no seu dispositivo, use o Python 3.x nos comandos executados para instalar as dependências.
Validar a instalação do DLR
Selecione uma das opções a seguir para validar a instalação do DLR.
Opção 1: usar SSH para o seu dispositivo e executar scripts
-
SSH para o seu dispositivo.
-
Execute o script a seguir para verificar se as dependências estão instaladas corretamente.
sudo python3.7 -c "import dlr; print(dlr.__version__)"sudo python3.7 -c "import numpy; print(numpy.__version__)"A saída imprime o número da versão e o script deve sair sem erro.
Opção 2: executar o teste de dependência de IDT
-
Certifique-se de que
device.jsonesteja configurado para qualificação de ML. Para obter mais informações, consulte Configurar device.json para qualificação de ML. -
Execute o teste de dependências para a estrutura.
devicetester_[linux | mac | win_x86-64]run-suite --group-id mldependencies --test-id dlr_dependency_checkO resumo do teste exibe um resultado
PASSEDparamldependencies.
Compilar o modelo de DLR
Você deve compilar o modelo de DLR antes de usá-lo para testes de qualificação de ML. Selecione uma das seguintes opções para saber mais detalhes:
Opção 1: usar o Amazon SageMaker AI para compilar o modelo
Siga estas etapas para usar a SageMaker IA para compilar o modelo de ML fornecido pelo IDT. Este modelo é pré-treinado com Apache MXNet.
-
Verifique se seu tipo de dispositivo é compatível com SageMaker IA. Para obter mais informações, consulte as opções do dispositivo de destino na Amazon SageMaker AI API Reference. Se o seu tipo de dispositivo não for compatível atualmente com SageMaker IA, siga as etapas emOpção 2: usar o TVM para compilar o modelo de DLR.
nota
A execução do teste DLR com um modelo compilado pela SageMaker IA pode levar de 4 a 5 minutos. Não interrompa o IDT durante esse período.
-
Faça download do arquivo tarball que contém o modelo MXNet pré-treinado e não compilado para DLR:
-
Descompacte o tarball. Esse comando gera a seguinte estrutura de diretório.

-
Mova o arquivo
synset.txtdo diretórioresnet18para outro local. Anote o novo local. Posteriormente, copie este arquivo para o diretório do modelo compilado. -
Compacte o conteúdo do diretório
resnet18.tar cvfz model.tar.gz resnet18v1-symbol.json resnet18v1-0000.params -
Faça upload do arquivo compactado em um bucket do Amazon S3 no Conta da AWS seu e siga as etapas em Compilar um modelo (console) para criar um trabalho de compilação.
-
Em Configuração de entrada, use os seguintes valores:
-
Em Configuração de dados de entrada, digite
{"data": [1, 3, 224, 224]}. -
Em Estrutura de machine learning, selecione
MXNet.
-
-
Em Configuração de saída, use os seguintes valores:
-
Em Local de saída do S3, insira o caminho para o bucket do Amazon S3 ou a pasta onde deseja armazenar o modelo compilado.
-
Em Dispositivo de destino, selecione o tipo de dispositivo.
-
-
-
Faça download do modelo compilado do local de saída especificado e descompacte o arquivo.
-
Copie
synset.txtpara o diretório do modelo compilado. -
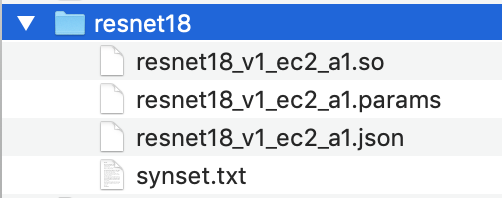
Altere o nome do diretório do modelo compilado para
resnet18.O diretório do modelo compilado deve ter a seguinte estrutura de diretório.
Opção 2: usar o TVM para compilar o modelo de DLR
Siga estas etapas para usar o TVM para compilar o modelo de ML fornecido pelo IDT. Este modelo é pré-treinado com o Apache MXNet, portanto, é necessário instalar o MXNet no computador ou dispositivo onde o modelo será compilado. Para instalar o MxNet, siga as instruções na documentação do MxNet
nota
Recomendamos que você compile o modelo no dispositivo de destino. Essa prática é opcional, mas pode ajudar a garantir a compatibilidade e mitigar possíveis problemas.
-
Faça download do arquivo tarball que contém o modelo MXNet pré-treinado e não compilado para DLR:
-
Descompacte o tarball. Esse comando gera a seguinte estrutura de diretório.
-
Siga as instruções na documentação do TVM para criar e instalar o TVM da origem para a sua plataforma
. -
Depois de criar o TVM, execute a compilação do TVM para o modelo resnet18. As etapas a seguir são baseadas no Quick Start Tutorial for Compiling Deep Learning Models
na documentação do TVM. -
Abra o arquivo
relay_quick_start.pya partir do repositório do TVM clonado. -
Atualize o código que define uma rede neural em retransmissão
. Você pode usar uma das opções a seguir: -
Opção 1: usar
mxnet.gluon.model_zoo.vision.get_modelpara obter o módulo e os parâmetros de retransmissão:from mxnet.gluon.model_zoo.vision import get_model block = get_model('resnet18_v1', pretrained=True) mod, params = relay.frontend.from_mxnet(block, {"data": data_shape}) -
Opção 2: copiar os seguintes arquivos do modelo não compilado que você baixou na etapa 1 para o mesmo diretório que o arquivo
relay_quick_start.py. Esses arquivos contêm o módulo e os parâmetros de retransmissão.-
resnet18v1-symbol.json -
resnet18v1-0000.params
-
-
-
Atualize o código que salva e carrega o módulo compilado
para usar o código a seguir. from tvm.contrib import util path_lib = "deploy_lib.so" # Export the model library based on your device architecture lib.export_library("deploy_lib.so", cc="aarch64-linux-gnu-g++") with open("deploy_graph.json", "w") as fo: fo.write(graph) with open("deploy_param.params", "wb") as fo: fo.write(relay.save_param_dict(params)) -
Crie o modelo:
python3 tutorials/relay_quick_start.py --build-dir ./modelEste comando gera os seguintes arquivos.
-
deploy_graph.json -
deploy_lib.so -
deploy_param.params
-
-
-
Copie os arquivos de modelo gerados em um diretório chamado
resnet18. Este é o diretório do modelo compilado. -
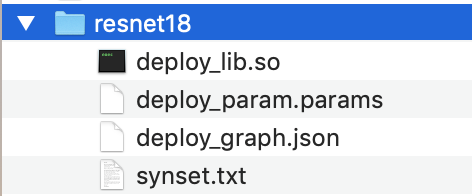
Copie o diretório do modelo compilado para o computador host. Depois, copie o arquivo
synset.txtdo modelo não compilado que você baixou na etapa 1 para o diretório do modelo compilado.O diretório do modelo compilado deve ter a seguinte estrutura de diretório.
Em seguida, configure suas AWS credenciais e seu device.json arquivo.
