Aviso de fim do suporte: em 7 de outubro de 2026,AWS o suporte para o.AWS IoT Greengrass Version 1 Depois de 7 de outubro de 2026, você não poderá mais acessar os AWS IoT Greengrass V1 recursos. Para obter mais informações, visite Migrar de AWS IoT Greengrass Version 1.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Configurações de exportação para suporte Nuvem AWS destinos
User-defined As funções Lambda são usadas StreamManagerClient no SDK AWS IoT Greengrass principal para interagir com o gerenciador de streams. Quando uma função do Lambda cria um fluxo ou atualiza um fluxo, ela passa um objeto MessageStreamDefinition que representa as propriedades do fluxo, incluindo a definição de exportação. O objeto ExportDefinition contém as configurações de exportação definidas para o fluxo. O gerenciador de fluxo usa essas configurações de exportação para determinar onde e como exportar o fluxo.
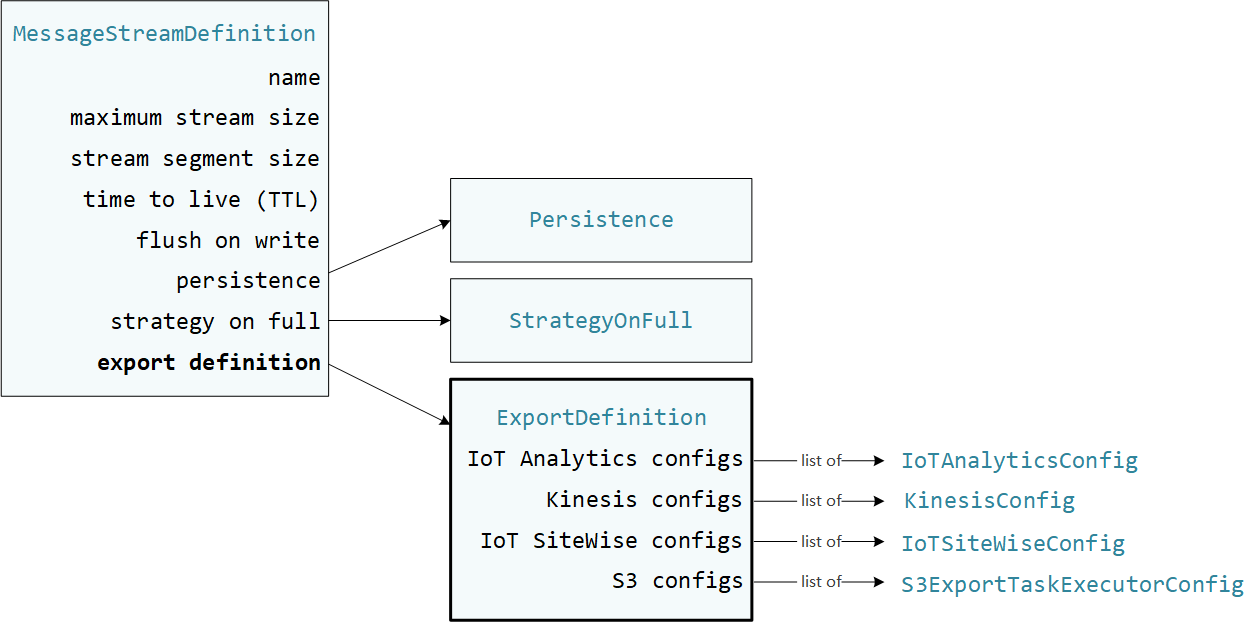
É possível definir zero ou mais configurações de exportação em um fluxo, incluindo várias configurações de exportação para um único tipo de destino. Por exemplo, você pode exportar um fluxo para dois canais do AWS IoT Analytics e um fluxo de dados do Kinesis.
Para tentativas de exportação malsucedidas, o gerenciador de fluxo tenta continuamente exportar dados para a Nuvem AWS em intervalos de até cinco minutos. Não há um limite máximo para o número de novas tentativas.
nota
O StreamManagerClient também fornece um destino alvo que você pode usar para exportar fluxos para um servidor HTTP. Este destino deve ser usado apenas para fins de teste. Ele não é estável e nem compatível para uso em ambientes de produção.
Nuvem AWS Destinos compatíveis
Você é responsável pela manutenção desses Nuvem AWS recursos.
AWS IoT Analytics canais
O gerenciador de fluxo suporta exportações automáticas para AWS IoT Analytics. AWS IoT Analytics permite realizar análises avançadas em seus dados para ajudar a tomar decisões comerciais e melhorar os modelos de aprendizado de máquina. Para obter mais informações, consulte O que é AWS IoT Analytics? no Guia do AWS IoT Analytics usuário.
No SDK AWS IoT Greengrass principal, suas funções do Lambda usam IoTAnalyticsConfig o para definir a configuração de exportação para esse tipo de destino. Para mais informações, consulte a referência do SDK para seu idioma de destino:
-
IoTAnalyticsConfig
no SDK do Python -
IoTAnalyticsConfig
no Java SDK -
IoTAnalyticsConfig
no Node.js SDK
Requisitos
Esse destino de exportação tem os seguintes requisitos:
-
Os canais-alvo AWS IoT Analytics devem estar no mesmo Conta da AWS grupo e Região da AWS no grupo Greengrass.
-
O Função do grupo do Greengrass. deve conceder a permissão
iotanalytics:BatchPutMessagepara os canais de destino. Por exemplo:É possível conceder acesso granular ou condicional aos recursos, por exemplo, usando um esquema de nomeação
*curinga. Para obter mais informações, consulte Adicionando e removendo políticas do IAM no Guia do usuário do IAM.
Exportando para AWS IoT Analytics
Para criar um fluxo que exporta para AWS IoT Analytics, suas funções do Lambda criam um fluxo com uma definição de exportação que inclui um ou mais IoTAnalyticsConfig objetos. Esse objeto define as configurações de exportação, como canal de destino, tamanho do lote, intervalo do lote e prioridade.
Quando suas funções do Lambda recebem dados de dispositivos, elas acrescentam mensagens que contêm um blob de dados ao fluxo de destino.
Em seguida, o gerenciador de fluxo exporta os dados com base nas configurações de lote e na prioridade definidas nas configurações de exportação do fluxo.
Amazon Kinesis Data Streams
O gerenciador de fluxos é compatível com exportações automáticas para o Amazon Kinesis Data Streams. O Kinesis Data Streams é comumente usado para agregar dados de alto volume e carregá-los em um data warehouse ou cluster de redução de mapas. Para obter mais informações, consulte O que é o Amazon Kinesis Data Streams? no Guia do desenvolvedor do Amazon Kinesis.
No SDK AWS IoT Greengrass principal, suas funções do Lambda usam KinesisConfig o para definir a configuração de exportação para esse tipo de destino. Para mais informações, consulte a referência do SDK para seu idioma de destino:
-
KinesisConfig
no SDK do Python -
KinesisConfig
no Java SDK -
KinesisConfig
no Node.js SDK
Requisitos
Esse destino de exportação tem os seguintes requisitos:
-
Os streams de destino no Kinesis Data Streams devem estar no mesmo grupo Conta da AWS e no grupo Greengrass Região da AWS .
-
O Função do grupo do Greengrass. deve conceder a permissão
kinesis:PutRecordspara os fluxos de dados de destino. Por exemplo:É possível conceder acesso granular ou condicional aos recursos, por exemplo, usando um esquema de nomeação
*curinga. Para obter mais informações, consulte Adicionando e removendo políticas do IAM no Guia do usuário do IAM.
Exportação do Kinesis Data Streams
Para criar um fluxo que exporte para o Kinesis Data Streams, suas funções do Lambda criam um fluxo com uma definição de exportação que inclui um ou mais objetos KinesisConfig. Esse objeto define as configurações de exportação, como fluxo de dados, tamanho do lote, intervalo do lote e prioridade.
Quando suas funções do Lambda recebem dados de dispositivos, elas acrescentam mensagens que contêm um blob de dados ao fluxo de destino. Em seguida, o gerenciador de fluxo exporta os dados com base nas configurações de lote e na prioridade definidas nas configurações de exportação do fluxo.
O gerenciador de fluxo gera uma UUID exclusiva e aleatória como chave de partição para cada registro carregado no Amazon Kinesis.
AWS IoT SiteWise propriedades do ativo
O gerenciador de fluxo suporta exportações automáticas para AWS IoT SiteWise. AWS IoT SiteWise permite coletar, organizar e analisar dados de equipamentos industriais em grande escala. Para obter mais informações, consulte O que é AWS IoT SiteWise? no Guia do AWS IoT SiteWise usuário.
No SDK AWS IoT Greengrass principal, suas funções do Lambda usam IoTSiteWiseConfig o para definir a configuração de exportação para esse tipo de destino. Para mais informações, consulte a referência do SDK para seu idioma de destino:
-
IoTSiteWiseConfig
no SDK do Python -
IoTSiteWiseConfig
no Java SDK -
IoTSiteWiseConfig
no Node.js SDK
nota
AWS também fornece oConector IoT SiteWise, que é uma solução pré-criada que você pode usar com OPC-UA fontes.
Requisitos
Esse destino de exportação tem os seguintes requisitos:
-
As propriedades do ativo alvo em AWS IoT SiteWise devem estar no mesmo Conta da AWS grupo e Região da AWS no grupo Greengrass.
nota
Para ver a lista de regiões que AWS IoT SiteWise oferecem suporte, consulte AWS IoT SiteWise endpoints e cotas na Referência AWS geral.
-
O Função do grupo do Greengrass. deve conceder a permissão
iotsitewise:BatchPutAssetPropertyValuepara as propriedades do ativo do destino. O exemplo de política a seguir usa a chave de condiçãoiotsitewise:assetHierarchyPathpara conceder acesso a um ativo raiz de destino e seus ativos secundários. É possível remover oConditionda política para conceder acesso a todos os seus ativos AWS IoT SiteWise , ou especificar ARNs para determinados ativos.É possível conceder acesso granular ou condicional aos recursos, por exemplo, usando um esquema de nomeação
*curinga. Para obter mais informações, consulte Adicionando e removendo políticas do IAM no Guia do usuário do IAM.Para obter informações de segurança importantes, consulte a BatchPutAssetPropertyValue autorização no Guia AWS IoT SiteWise do usuário.
Exportando para AWS IoT SiteWise
Para criar um fluxo que exporta para AWS IoT SiteWise, suas funções do Lambda criam um fluxo com uma definição de exportação que inclui um ou mais IoTSiteWiseConfig objetos. Esse objeto define as configurações de exportação, como tamanho do lote, intervalo do lote e prioridade.
Quando suas funções do Lambda recebem dados de propriedades de ativos de dispositivos, elas anexam mensagens que contêm os dados ao fluxo de destino. As mensagens são JSON-serialized PutAssetPropertyValueEntry objetos que contêm valores de propriedades para uma ou mais propriedades do ativo. Para obter mais informações, consulte Anexar mensagem para destinos de exportação do AWS IoT SiteWise .
nota
Quando você envia dados para AWS IoT SiteWise, seus dados devem atender aos requisitos da BatchPutAssetPropertyValue ação. Para obter mais informações, consulte BatchPutAssetPropertyValue na Referência de APIs do AWS IoT SiteWise .
Em seguida, o gerenciador de fluxo exporta os dados com base nas configurações de lote e na prioridade definidas nas configurações de exportação do fluxo.
Você pode ajustar as configurações do gerenciador de fluxo e a lógica da função do Lambda para criar sua estratégia de exportação. Por exemplo:
-
Para exportações quase em tempo real, defina configurações baixas de tamanho de lote e intervalo e anexe os dados ao fluxo quando forem recebidos.
-
Para otimizar o agrupamento em lotes, mitigar as restrições de largura de banda ou minimizar os custos, suas funções do Lambda podem agrupar os pontos de dados de timestamp-quality-value (TQV) recebidos para uma única propriedade do ativo antes de anexar os dados ao fluxo. Uma estratégia é agrupar entradas para até 10 (dez) combinações diferentes de propriedade e ativo, ou aliases de propriedade, em uma mensagem, em vez de enviar mais de uma entrada para a mesma propriedade. Isso ajuda o gerenciador de fluxo a permanecer dentro das cotas do AWS IoT SiteWise.
Objetos do Amazon S3
O gerenciador de fluxo é compatível com exportações automáticas para o Amazon S3. É possível utilizar o Amazon S3 para armazenar e recuperar grandes volumes de dados. Para obter mais informações, consulte O que é o Amazon S3? no Guia do desenvolvedor do Amazon Simple Storage Service.
No SDK AWS IoT Greengrass principal, suas funções do Lambda usam S3ExportTaskExecutorConfig o para definir a configuração de exportação para esse tipo de destino. Para mais informações, consulte a referência do SDK para seu idioma de destino:
-
S3ExportTaskExecutorConfig
no SDK do Python -
S3ExportTaskExecutorConfig
no Java SDK -
S3ExportTaskExecutorConfig
no Node.js SDK
Requisitos
Esse destino de exportação tem os seguintes requisitos:
-
Os buckets do Amazon S3 de destino devem estar no mesmo grupo Conta da AWS do Greengrass.
-
Se a conteinerização padrão para o grupo do Greengrass for contêiner do Greengrass, você deverá definir o parâmetro STREAM_MANAGER_READ_ONLY_DIRS para usar um diretório de arquivos de entrada que esteja sob
/tmpou não faça parte do sistema de arquivos raiz. -
Se uma função do Lambda em execução no modo de contêiner do Greengrass gravar arquivos de entrada no diretório de arquivos de entrada, você deverá criar um recurso de volume local para o diretório e montar o diretório no contêiner com permissões de gravação. Isso garante que os arquivos sejam gravados no sistema de arquivos raiz e sejam visíveis fora do contêiner. Para obter mais informações, consulte Acesso aos recursos locais com funções e conectores do Lambda.
-
O Função do grupo do Greengrass. deve conceder as permissões a seguir para os buckets de destino. Por exemplo:
É possível conceder acesso granular ou condicional aos recursos, por exemplo, usando um esquema de nomeação
*curinga. Para obter mais informações, consulte Adicionando e removendo políticas do IAM no Guia do usuário do IAM.
Exportar para o Amazon S3
Para criar um fluxo que exporte para o Amazon S3, suas funções do Lambda usam o objeto S3ExportTaskExecutorConfig para configurar a política de exportação. A política define as configurações de exportação, como o limite e a prioridade de upload em várias partes. Para exportações do Amazon S3, o gerenciador de fluxo carrega dados que ele lê de arquivos locais no dispositivo principal. Para iniciar um upload, suas funções do Lambda anexam uma tarefa de exportação ao fluxo de destino. A tarefa de exportação contém informações sobre o arquivo de entrada e o objeto de destino do Amazon S3. O gerenciador de fluxo executa tarefas na sequência em que elas são anexadas ao fluxo.
nota
O bucket de destino já deve existir no seu Conta da AWS. Se um objeto para a chave especificada não existir, o gerenciador de fluxo criará o objeto para você.
Esse fluxo de alto nível é mostrado no diagrama a seguir.
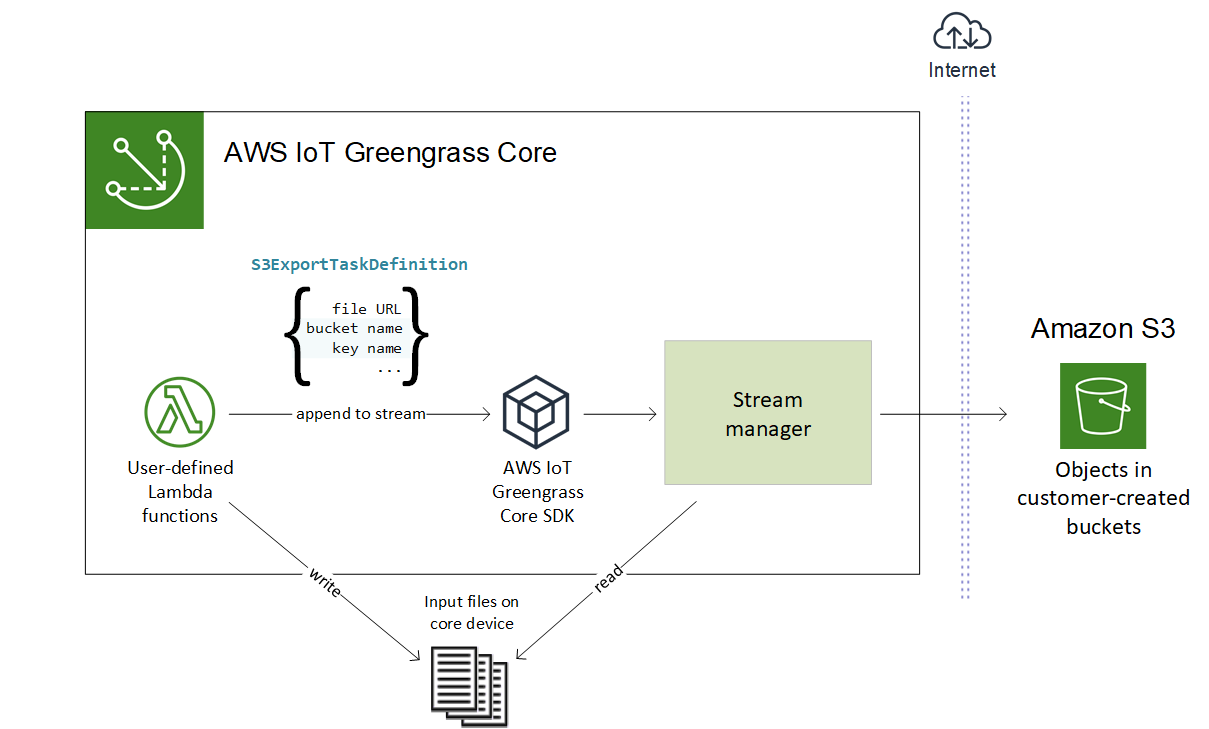
O gerenciador de fluxo usa a propriedade de limite de upload de várias partes, a configuração do tamanho mínimo das partes e o tamanho do arquivo de entrada para determinar como fazer upload dos dados. O limite de upload de várias partes deve ser maior que o tamanho mínimo das partes. Se você quiser fazer upload de dados em paralelo, pode criar vários fluxos.
As chaves que especificam seus objetos de destino do Amazon S3 podem incluir DateTimeFormatter cadeias de caracteres Java!{timestamp: É possível usar esses espaços reservados de data e hora para particionar dados no Amazon S3 com base na hora em que os dados do arquivo de entrada foram carregados. Por exemplo, o nome da chave a seguir é resolvido para um valor como value}my-key/2020/12/31/data.txt.
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
nota
Se você quiser monitorar o status de exportação de um fluxo, primeiro crie um fluxo de status e, em seguida, configure o fluxo de exportação para usá-lo. Para obter mais informações, consulte Monitorar tarefas de exportação.
Gerenciar dados de entrada
Você pode criar códigos que os aplicativos de IoT usam para gerenciar o ciclo de vida dos dados de entrada. O exemplo de fluxo de trabalho a seguir mostra como você pode usar as funções do Lambda para gerenciar esses dados.
-
Um processo local recebe dados de dispositivos ou periféricos e, em seguida, grava os dados em arquivos em um diretório no dispositivo principal. Esses são os arquivos de entrada para o gerenciador de fluxo.
nota
Para determinar se você deve configurar o acesso ao diretório de arquivos de entrada, consulte o parâmetro STREAM_MANAGER_READ_ONLY_DIRS.
O processo no qual o gerenciador de fluxo é executado herda todas as permissões do sistema de arquivos da identidade de acesso padrão do grupo. O gerenciador de fluxo deve ter permissão para acessar os arquivos de entrada. Você pode usar o comando
chmod(1)para alterar a permissão dos arquivos, se necessário. -
Uma função do Lambda verifica o diretório e anexa uma tarefa de exportação ao fluxo de destino quando um novo arquivo é criado. A tarefa é um JSON-serialized
S3ExportTaskDefinitionobjeto que especifica a URL do arquivo de entrada, o bucket e a chave de destino do Amazon S3 e metadados opcionais do usuário. -
O gerenciador de fluxo lê o arquivo de entrada e exporta os dados para o Amazon S3 na ordem das tarefas anexadas. O bucket de destino já deve existir no seu Conta da AWS. Se um objeto para a chave especificada não existir, o gerenciador de fluxo criará o objeto para você.
-
A função do Lambda lê mensagens de um fluxo de status para monitorar o status da exportação. Depois que as tarefas de exportação forem concluídas, a função do Lambda poderá excluir os arquivos de entrada correspondentes. Para obter mais informações, consulte Monitorar tarefas de exportação.
Monitorar tarefas de exportação
Você pode criar códigos que os aplicativos de IoT usam para monitorar o status das suas exportações do Amazon S3. Suas funções do Lambda devem criar um fluxo de status e, em seguida, configurar o fluxo de exportação para gravar atualizações de status no fluxo de status. Um único fluxo de status pode receber atualizações de status de vários fluxos que são exportados para o Amazon S3.
Primeiro, crie um fluxo para usar como fluxo de status. É possível configurar as políticas de tamanho e retenção do fluxo para controlar a vida útil das mensagens de status. Por exemplo:
-
Defina
PersistencecomoMemoryse você não quiser armazenar as mensagens de status. -
Defina
StrategyOnFullcomoOverwriteOldestDatapara que as novas mensagens de status não sejam perdidas.
Em seguida, crie ou atualize o fluxo de exportação para usar o fluxo de status. Especificamente, defina a propriedade de configuração de status da configuração de exportação S3ExportTaskExecutorConfig do fluxo. Isso faz com que o gerenciador de fluxo grave mensagens de status sobre as tarefas de exportação para o fluxo de status. No objeto StatusConfig, especifique o nome do fluxo de status e o nível de detalhe. Os valores com suporte a seguir variam do menos detalhado (ERROR) ao mais detalhado (TRACE). O padrão é INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
O exemplo de fluxo de trabalho a seguir mostra como as funções do Lambda podem usar um fluxo de status para monitorar o status de exportação.
-
Conforme descrito no fluxo de trabalho anterior, uma função do Lambda anexa uma tarefa de exportação a um fluxo configurado para gravar mensagens de status sobre tarefas de exportação em um fluxo de status. A operação de append retorna um número de sequência que representa a ID da tarefa.
-
Uma função do Lambda lê mensagens sequencialmente do fluxo de status e, em seguida, filtra as mensagens com base no nome do fluxo e na ID da tarefa ou com base em uma propriedade da tarefa de exportação do contexto da mensagem. Por exemplo, a função do Lambda pode filtrar pela URL do arquivo de entrada da tarefa de exportação, que é representada pelo objeto
S3ExportTaskDefinitionno contexto da mensagem.Os códigos de status a seguir indicam que uma tarefa de exportação atingiu um estado concluído:
-
Success. O upload foi concluído com êxito. -
Failure. O gerenciador de fluxo encontrou um erro, por exemplo, o bucket especificado não existe. Depois de resolver o problema, você pode reanexar a tarefa de exportação ao fluxo. -
Canceled. A tarefa foi interrompida porque a definição de fluxo ou exportação foi excluída ou a vida útil (TTL) da tarefa expirou.
nota
A tarefa também pode ter um status de
InProgressouWarning. O gerenciador de fluxo emite avisos quando um evento retorna um erro que não afeta a execução da tarefa. Por exemplo, uma falha na limpeza de um upload parcial interrompido retorna um aviso. -
-
Depois que as tarefas de exportação forem concluídas, a função do Lambda poderá excluir os arquivos de entrada correspondentes.
O exemplo a seguir mostra como uma função do Lambda pode ler e processar mensagens de status.
