As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Gerenciamento de permissões em conjuntos de dados que usam repositórios de dados externos
Com a federação de metadados do AWS Glue Data Catalog (federação do catálogo de dados), você pode conectar o catálogo de dados a repositórios externos que armazenam metadados para seus dados do Amazon S3 e gerenciar com segurança as permissões de acesso aos dados usando o AWS Lake Formation. Você não precisa migrar os metadados do repositório externo para o catálogo de dados.
O Catálogo de Dados oferece um repositório centralizado de metadados que facilita o gerenciamento e a descoberta de dados em sistemas diferentes. Quando sua organização gerencia dados no catálogo de dados, você pode usar AWS Lake Formation para controlar o acesso aos seus conjuntos de dados no Amazon S3.
nota
Atualmente, oferecemos suporte somente à federação de repositórios do Apache Hive (versão 3 e superior).
Para configurar a federação do Data Catalog, fornecemos um aplicativo AWS Serverless Application Model (AWS SAM) chamado GlueDataCatalogFederation-HiveMetastore
A implementação de referência é fornecida no GitHub como um projeto de código aberto em Federação AWS Glue Data Catalog - Hive Metastore
O aplicativo AWS SAM cria e implanta os seguintes recursos que são necessários para conectar o catálogo de dados ao repositório do Hive:
Uma função do AWS Lambda: hospeda a implementação do serviço de federação que realiza a comunicação entre o Catálogo de Dados e o repositório do Hive. O AWS Glue invoca essa função do Lambda para recuperar objetos de metadados do repositório do Hive.
Amazon API Gateway — O endpoint de conexão do seu repositório do Hive que atua como um proxy para rotear todas as invocações para a função do Lambda.
Um perfil do IAM: um perfil com as permissões necessárias para criar a conexão entre o Catálogo de Dados e o repositório do Hive.
Conexão do AWS Glue: um tipo de Amazon API Gateway de conexão do AWS Glue que armazena o endpoint do Amazon API Gateway e um perfil do IAM para invocá-lo.
Quando você consulta tabelas, o serviço AWS Glue faz uma chamada em runtime para o repositório do Hive e busca os metadados. A função do Lambda atua como um tradutor entre o Repositório do Hive e o catálogo de dados.
Após estabelecer a conexão, para sincronizar os metadados na repositório do Hive com o catálogo de dados, você precisa criar um banco de dados federado no catálogo de dados usando as informações da conexão do repositório do Hive, e mapear esse banco de dados para o banco de dados do Hive. Um banco de dados é chamado de banco de dados federado quando aponta para uma entidade fora do catálogo de dados.
É possível aplicar as permissões do Lake Formation usando o controle de acesso baseado em tags e o método de recurso nomeado no banco de dados federado e compartilhá-lo entre várias Contas da AWS, o AWS Organizations e unidades organizacionais (UOs). Você também pode compartilhar o banco de dados federado diretamente com as entidades principais do IAM de outra conta.
Você pode definir permissões refinadas no nível de coluna, linha e célula usando os filtros de dados do Lake Formation nas tabelas externas do Hive. É possível usar o Amazon Athena, o Amazon Redshift ou o Amazon EMR para consultar as tabelas externas do Hive gerenciadas pelo Lake Formation.
Para obter mais informações sobre compartilhamento de dados entre contas e filtragem de dados, consulte:
Etapas de alto nível da federação de metadados do catálogo de dados
-
Você cria usuários e perfis do IAM que têm as permissões apropriadas para implantar a aplicação do AWS SAM e criar bancos de dados federados.
-
Você registra o local dos dados do Amazon S3 com o Lake Formation selecionando a opção
Enable Data Catalog federationpara conjuntos de dados que usam um repositório externo do Hive. Você define as configurações do aplicativo do AWS SAM (nome da conexão do AWS Glue, URL para o repositório do Hive e parâmetros da função do Lambda) e implanta o aplicativo do AWS SAM.
-
O aplicativo do AWS SAM implanta os recursos necessários para conectar o repositório externo do Hive ao catálogo de dados.
-
Para aplicar as permissões do Lake Formation no banco de dados e nas tabelas do Hive, você cria um banco de dados no Catálogo de Dados usando as informações de conexão do repositório do Hive e associa esse banco de dados ao banco de dados do Hive.
Conceda permissões nos bancos de dados federados às entidades principais da sua conta ou de outra conta.
nota
Você pode conectar o Data Catalog a um repositório externo do Hive, criar bancos de dados federados e executar consultas e scripts do ETL em bancos de dados e tabelas do Hive sem aplicar as permissões do Lake Formation. Para dados de origem no Amazon S3 que não estão registrados no Lake Formation, o acesso é determinado pelas políticas de permissões do IAM para ações do Amazon S3 e do AWS Glue.
Para conhecer as limitações, consulte Considerações e limitações do compartilhamento de dados de armazenamento de metadados do Hive.
Tópicos
Fluxo de trabalho
O diagrama a seguir mostra o fluxo de trabalho para conectar o AWS Glue Data Catalog a um repositório externo do Hive.
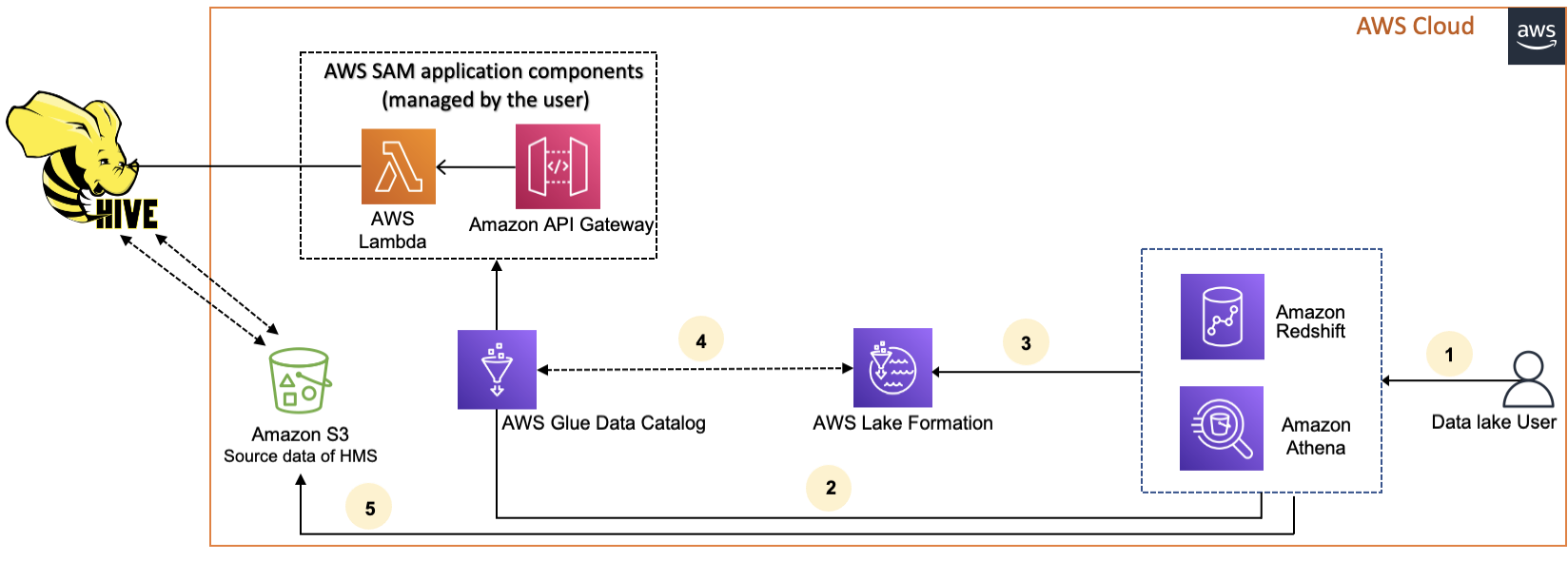
-
Uma entidade principal envia uma consulta usando um serviço integrado, como Athena ou Redshift Spectrum.
O serviço integrado faz uma chamada para o Catálogo de Dados para obter os metadados, que, por sua vez, chama o endpoint de repositórios de dados do Hive disponível no Amazon API Gateway e recebe respostas às solicitações de metadados.
-
O serviço integrado envia a solicitação ao Lake Formation para verificar as informações e credenciais da tabela para acessar a tabela.
-
O Lake Formation autoriza a solicitação e fornece credenciais temporárias para o aplicativo integrado, que permite o acesso aos dados.
Ao usar as credenciais temporárias recebidas do Lake Formation, o serviço integrado lê os dados do Amazon S3 e compartilha os resultados com a entidade principal.
