Aviso de fim do suporte: em 31 de outubro de 2025, o suporte para o Amazon Lookout for Vision AWS será interrompido. Depois de 31 de outubro de 2025, você não poderá mais acessar o console do Lookout for Vision ou os recursos do Lookout for Vision. Para obter mais informações, visite esta postagem do blog
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Conceitos básicos do Amazon Lookout for Vision
Antes de iniciar estas instruções de introdução, recomendamos que você leiaNoções básicas sobre o Amazon Lookout for Vision.
As instruções de introdução mostram como criar um exemplo de modelo de segmentação de imagens. Se você quiser criar um exemplo de modelo de classificação de imagens, consulteConjunto de dados de classificação de imagens.
Se você quiser experimentar rapidamente um modelo de exemplo, fornecemos exemplos de imagens de treinamento e imagens de máscara. Também fornecemos um script Python que cria um arquivo manifesto de segmentação de imagens. Você usa o arquivo de manifesto para criar um conjunto de dados para seu projeto e não precisa rotular as imagens no conjunto de dados. Ao criar um modelo com suas próprias imagens, você deve rotular as imagens no conjunto de dados. Para obter mais informações, consulte Criar um conjunto de dados.
As imagens que fornecemos são de cookies normais e anômalos. Um biscoito anômalo tem uma rachadura na forma de biscoito. O modelo que você treina com as imagens prevê uma classificação (normal ou anômala) e encontra a área (máscara) das rachaduras em um biscoito anômalo, conforme mostrado no exemplo a seguir.

Tópicos
Etapa 1: criar o arquivo de manifesto e fazer upload de imagens
Neste procedimento, você clona o repositório de documentação do Amazon Lookout for Vision em seu computador. Em seguida, você usa um script Python (versão 3.7 ou superior) para criar um arquivo de manifesto e carregar as imagens de treinamento e as imagens de máscara em um local do Amazon S3 que você especificar. Você usa o arquivo de manifesto para criar seu modelo. Posteriormente, você usa imagens de teste no repositório local para testar seu modelo.
Para criar o arquivo de manifesto e fazer upload de imagens
Configure o Amazon Lookout for Vision seguindo as instruções em Configurar o Amazon Lookout for Vision Certifique-se de instalar o AWSSDK for Python
. Na AWS região em que você deseja usar o Lookout for Vision, crie um bucket do S3.
No bucket do Amazon S3, crie uma pasta chamada
getting-started.Observe o URI do Amazon S3 e o nome do recurso da Amazon (ARN) da pasta. Você os usa para configurar permissões e executar o script.
Certifique-se de que o usuário que está chamando o script tenha permissão para chamar a
s3:PutObjectoperação. Você pode usar a seguinte política. Para atribuir permissões, consulte Como atribuir permissões{ "Version": "2012-10-17", "Statement": [{ "Sid": "Statement1", "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": [ "arn:aws:s3::: ARN for S3 folder in step 4/*" ] }] }-
Verifique se você tem um perfil local nomeado
lookoutvision-accesse se o usuário do perfil tem a permissão da etapa anterior. Para obter mais informações, consulte Usando um perfil em seu computador local. -
Faça o download do arquivo zip, getting-started.zip. O arquivo zip contém o conjunto de dados de introdução e o script de configuração.
Descompacte o arquivo
getting-started.zip.No prompt de comando, faça o seguinte:
Navegue para a pasta
getting-started.-
Execute o comando a seguir para criar um arquivo de manifesto e carregar as imagens de treinamento e as máscaras de imagem para o caminho do Amazon S3 que você anotou na etapa 4.
python getting_started.pyS3-URI-from-step-4 Quando o script for concluído, anote o caminho para o
train.manifestarquivo que o script exibe depoisCreate dataset using manifest file:. O caminho deve ser similar aos3://.path to getting started folder/manifests/train.manifest
Etapa 2: Criar o modelo
Neste procedimento, você cria um projeto e um conjunto de dados usando as imagens e o arquivo de manifesto que você carregou anteriormente no seu bucket do Amazon S3. Em seguida, você cria o modelo e visualiza os resultados da avaliação do treinamento do modelo.
Como você cria o conjunto de dados a partir do arquivo de manifesto de introdução, não precisa rotular as imagens do conjunto de dados. Ao criar um conjunto de dados com suas próprias imagens, você precisa rotular as imagens. Para obter mais informações, consulte Rotulagem de imagens.
Importante
Você é cobrado pelo treinamento bem-sucedido de um modelo.
Como criar um modelo
-
Abra o console Amazon Lookout for Vision em https://console.aws.amazon.com/lookoutvision/
. Verifique se você está na mesma região da AWS em que criou o bucket do Amazon S3 em Etapa 1: criar o arquivo de manifesto e fazer upload de imagens. Na barra de navegação, escolha o nome da região exibida no momento. Depois, escolha a região para a qual pretende alternar.
-
Escolha Como começar.
Na seção Projetos, escolha Criar projeto).
-
Na página Criar política faça o seguinte:
-
Em Nome do projeto, insira
getting-started. -
Escolha Criar projeto.
-
-
Na página do projeto, na seção Como funciona, escolha Criar conjunto de dados.
Na página Criar banco de dados , faça o seguinte:
-
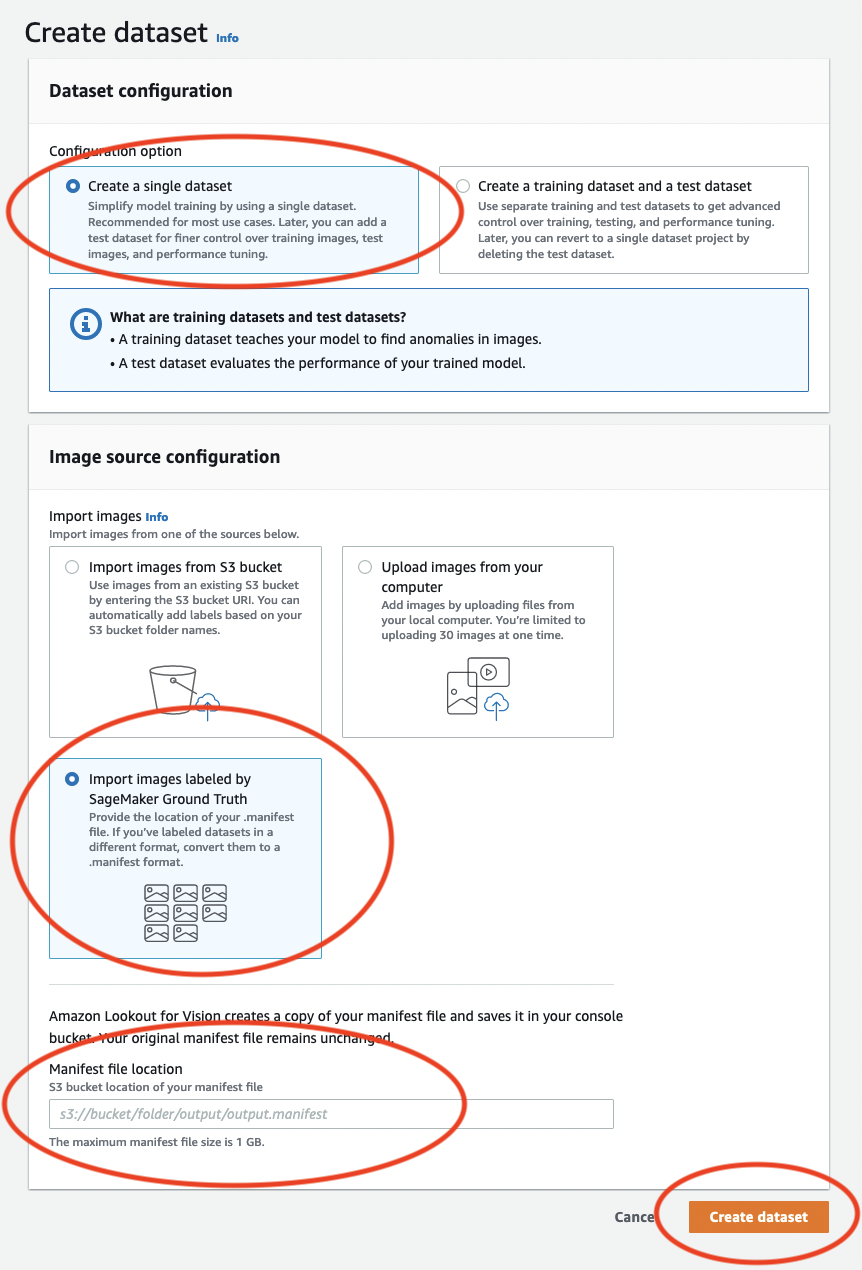
Escolha Criar um único conjunto de dados.
-
Na seção Configuração da fonte de imagem, escolha Importar imagens rotuladas pelo SageMaker Ground Truth.
-
Para a localização do arquivo.manifest, insira a localização do arquivo manifesto no Amazon S3 que você anotou na etapa 6.c. de Etapa 1: criar o arquivo de manifesto e fazer upload de imagens A localização do Amazon S3 deve ser semelhante a
s3://path to getting started folder/manifests/train.manifest -
Escolha Criar grupo de conjuntos de dados.
-
-
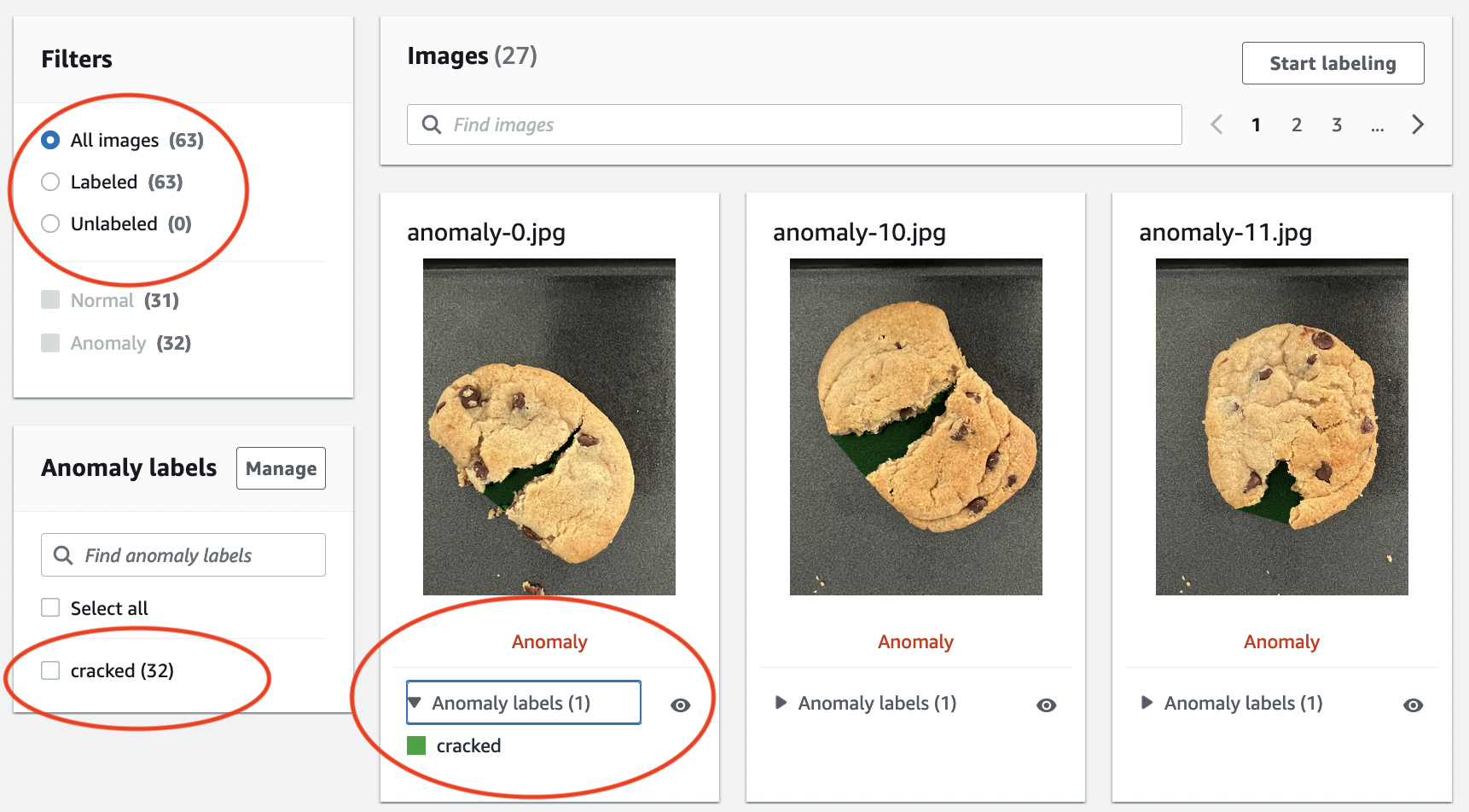
Na página de detalhes do projeto, na seção Imagens, visualize as imagens do conjunto de dados. Você pode visualizar as informações de classificação e segmentação da imagem (rótulos de máscara e anomalia) para cada imagem do conjunto de dados. Você também pode pesquisar imagens, filtrar imagens pelo status da etiqueta (etiquetada/não rotulada) ou filtrar imagens pelos rótulos de anomalia atribuídos a elas.
-
Na página de detalhes do projeto, escolha Modelo de trem.
-
Na página de detalhes do modelo do trem, escolha Modelo do trem.
-
No Você quer treinar seu modelo? caixa de diálogo, escolha Modelo do trem.
-
Na página Modelos do projeto, você pode ver que o treinamento começou. Verifique o status atual visualizando a coluna Status da versão do modelo. O treinamento do modelo leva pelo menos 30 minutos para ser concluído. O treinamento foi concluído com sucesso quando o status muda para Treinamento concluído.
-
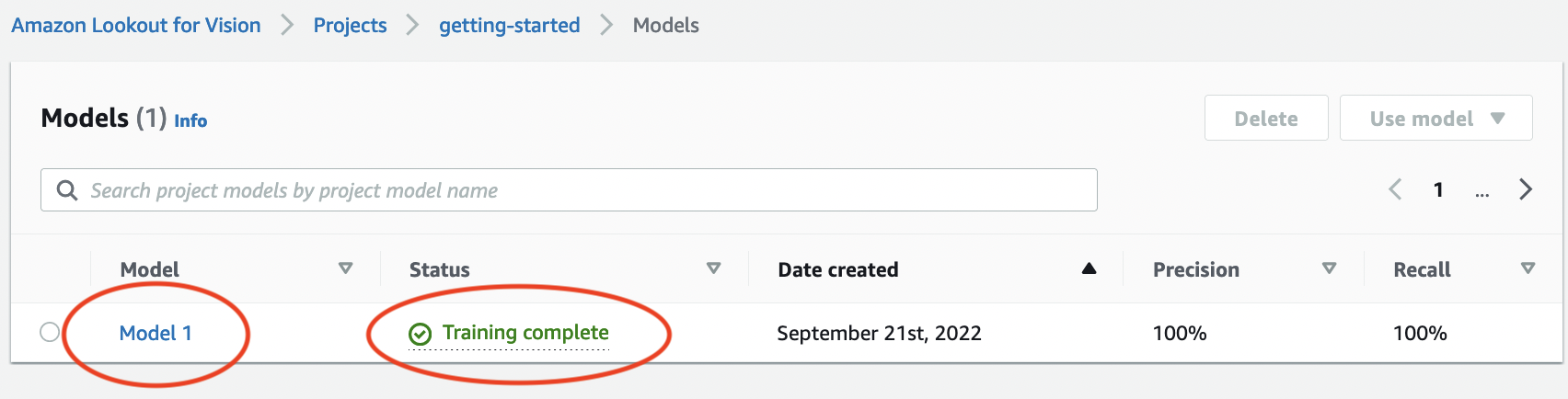
Quando o treinamento terminar, escolha o modelo Modelo 1 na página Modelos.
-
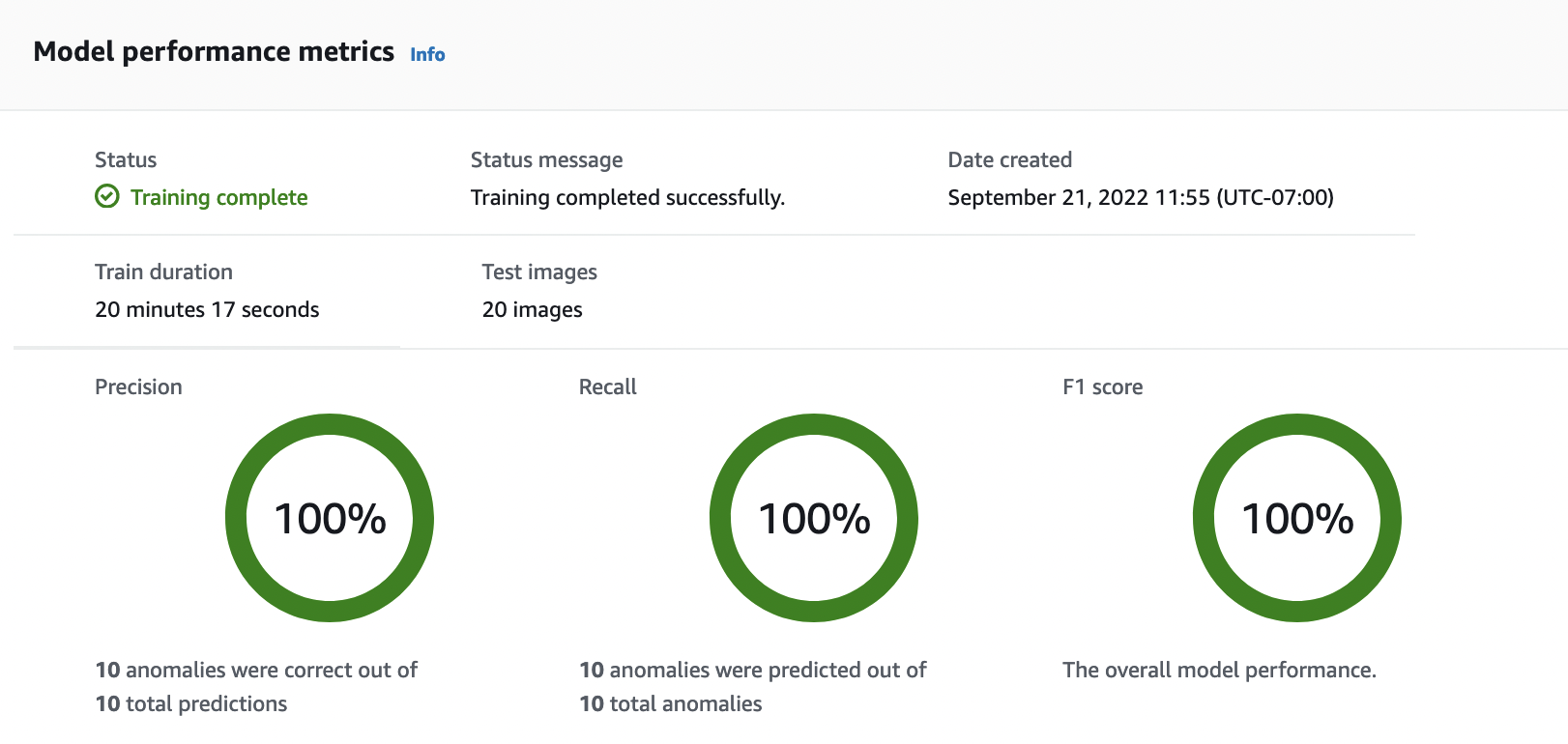
Na página de detalhes do modelo, visualize os resultados da avaliação na guia Métricas de desempenho. Existem métricas para o seguinte:
-
Métricas gerais de desempenho do modelo (precisão, recall e pontuação F1) para as previsões de classificação feitas pelo modelo.
-
Métricas de desempenho para rótulos de anomalias encontrados nas imagens de teste (média de IoU, pontuação F1)

-
Previsões para imagens de teste (classificação, máscaras de segmentação e rótulos de anomalias)
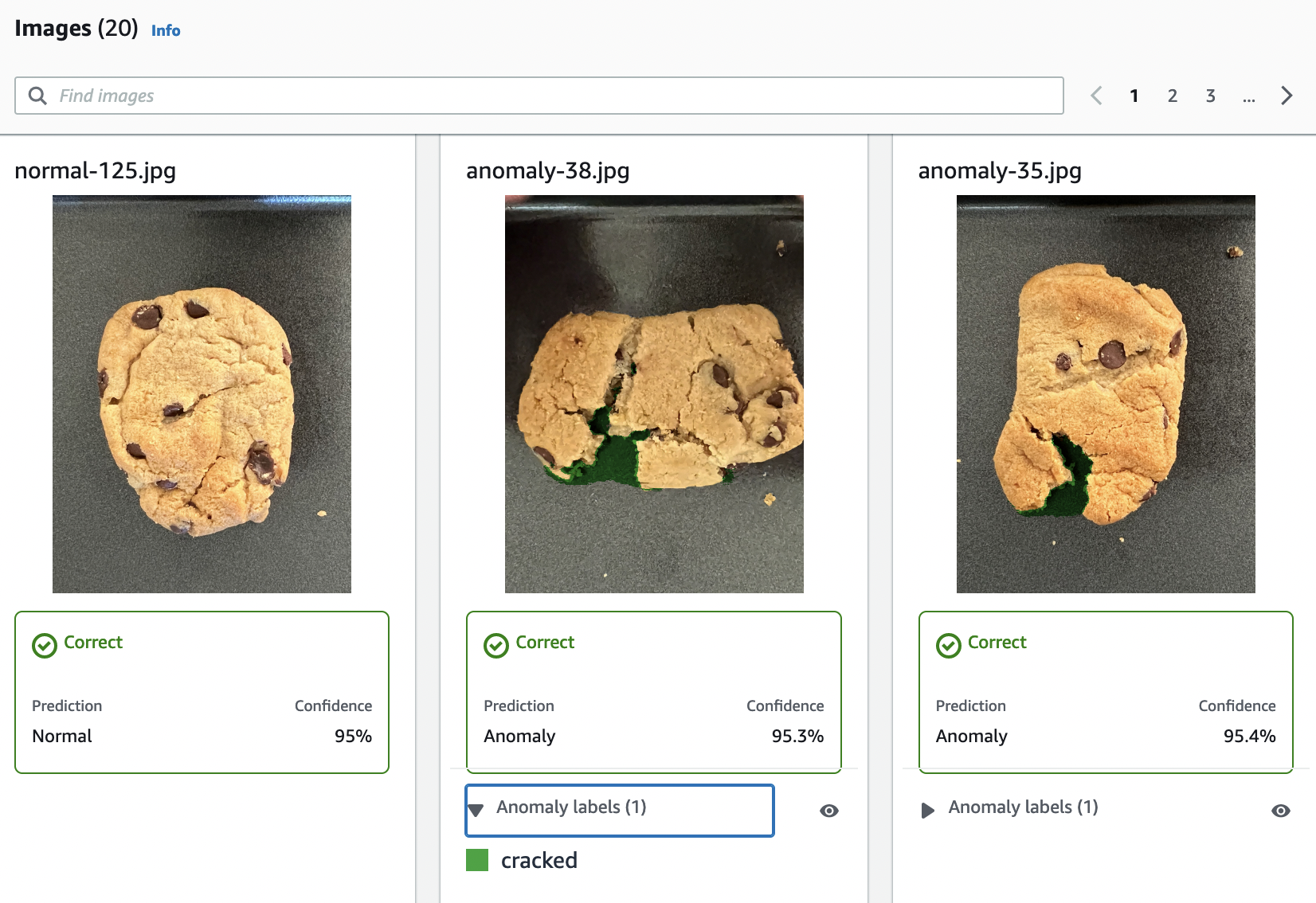
Como o treinamento do modelo não é determinístico, os resultados da avaliação podem ser diferentes dos resultados mostrados nesta página. Para obter mais informações, consulte Melhoria de um modelo do Amazon Lookout for Vision.
-
Etapa 3: iniciar o modelo
Nesta etapa, você começa a hospedar o modelo para que ele esteja pronto para analisar imagens. Para obter mais informações, consulte Executando seu modelo treinado do Amazon Lookout for Vision.
nota
Você é cobrado pela quantidade de tempo que o modelo funciona. Você interrompe seu modeloEtapa 5: interromper o modelo.
Como iniciar o modelo.
Na página de detalhes do modelo, escolha Usar modelo e, em seguida, escolha Integrar API à nuvem.
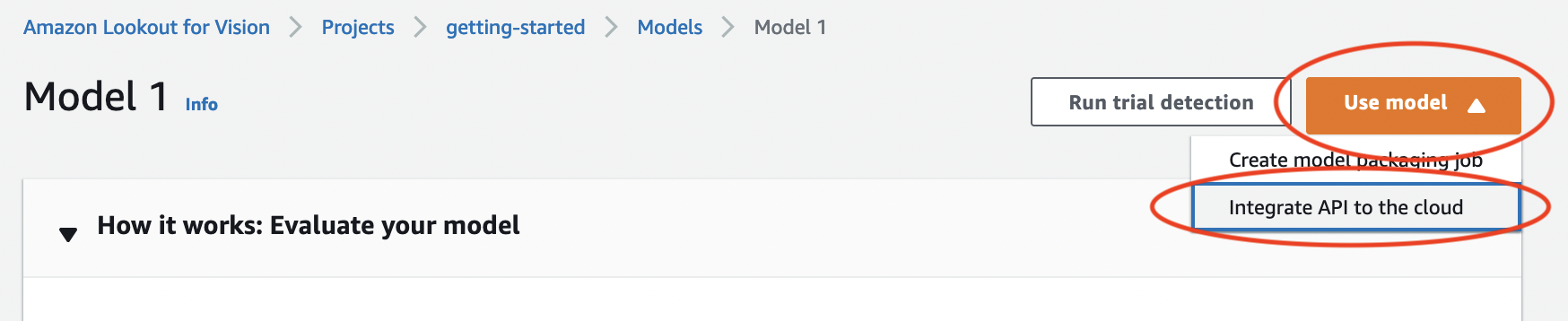
Na seção de AWS CLIcomandos, copie o
start-modelAWS CLI comando.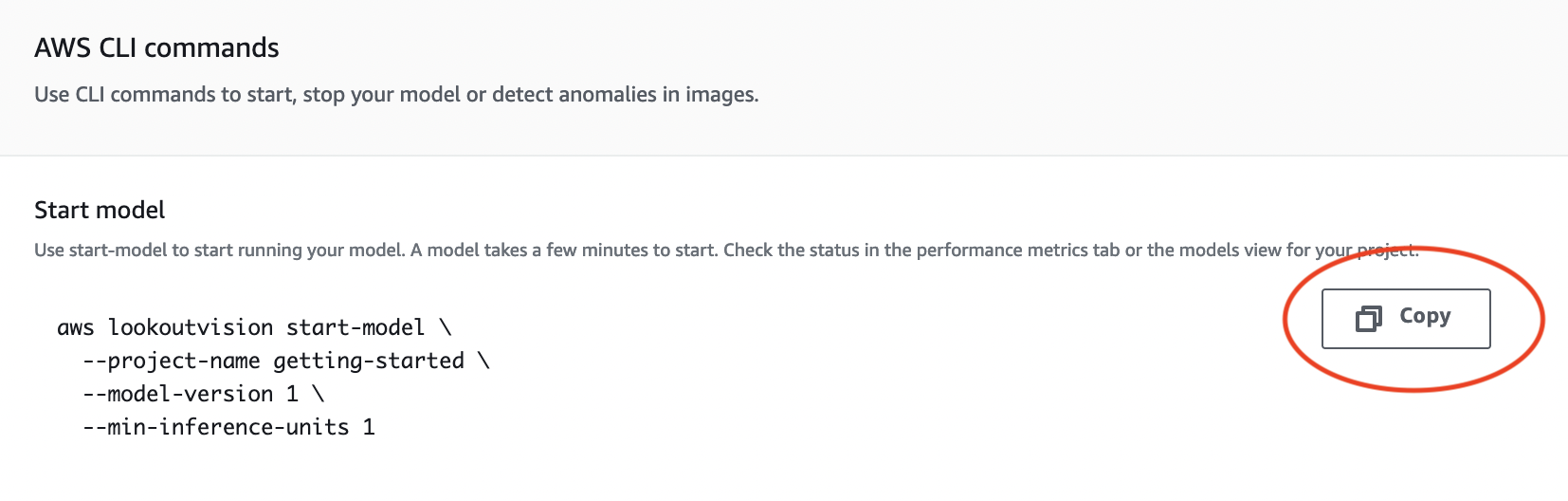
-
Certifique-se de que o AWS CLI esteja configurado para ser executado na mesma AWS região em que você está usando o console Amazon Lookout for Vision. Para alterar a AWS região que o AWS CLI usa, consulteInstale os AWS SDKS.
-
No prompt de comando, inicie o modelo digitando o
start-modelcomando. Se você estiver usando olookoutvisionperfil para obter credenciais, adicione o--profile lookoutvision-accessparâmetro. Por exemplo:aws lookoutvision start-model \ --project-name getting-started \ --model-version 1 \ --min-inference-units 1 \ --profile lookoutvision-accessSe a chamada tiver êxito, a seguinte saída será exibida:
{ "Status": "STARTING_HOSTING" } De volta ao console do , escolha Instâncias no painel de navegação.
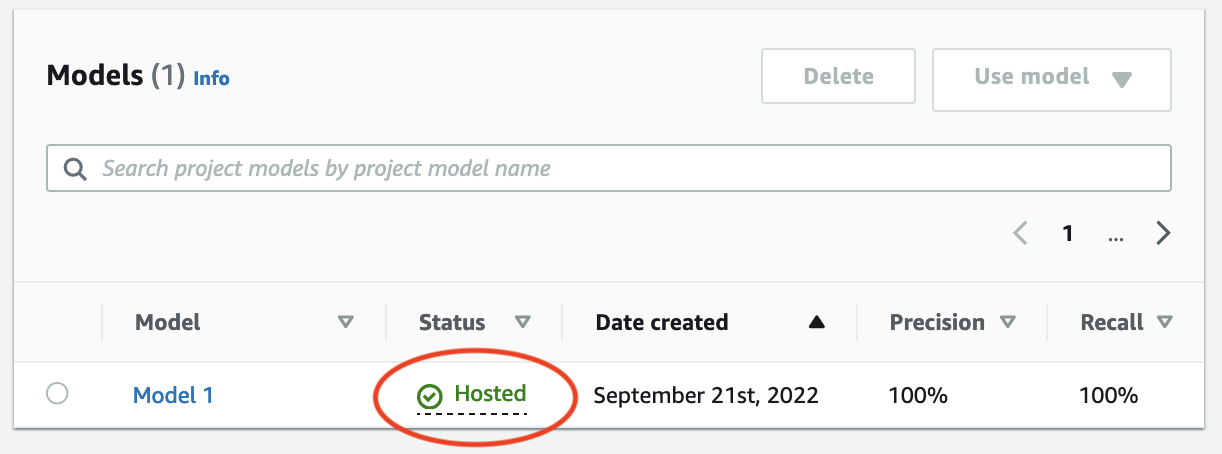
Espere até que o status do modelo (Modelo 1) na coluna Status exiba Hospedado. Se você já treinou um modelo no projeto, aguarde a conclusão da versão mais recente do modelo.
Etapa 4: Analisar uma imagem
Nesta etapa, você analisa uma imagem com o modelo. Fornecemos exemplos de imagens que você pode usar na pasta de introdução test-images no repositório de documentação do Lookout for Vision em seu computador. Para obter mais informações, consulte Detectar as anomalias de uma imagem.
Como analisar uma imagem
-
Na página Modelos, escolha o modelo Modelo 1.
-
Na página de detalhes do modelo, escolha Usar modelo e, em seguida, escolha Integrar API à nuvem.
-
Na seção de AWS CLIcomandos, copie o
detect-anomaliesAWS CLI comando.
-
No prompt de comando, analise uma imagem anômala inserindo o
detect-anomaliescomando da etapa anterior. Para o --body parâmetro, especifique uma imagem anômala da test-images pasta de introdução do seu computador. Se você estiver usando olookoutvisionperfil para obter credenciais, adicione o--profile lookoutvision-accessparâmetro. Por exemplo:aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-anomaly-1.jpg\ --profile lookoutvision-accessA saída deve ser semelhante à seguinte:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": true, "Confidence": 0.983975887298584, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 0.9818974137306213, "Color": "#FFFFFF" } }, { "Name": "cracked", "PixelAnomaly": { "TotalPercentageArea": 0.018102575093507767, "Color": "#23A436" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAAMACA......" } } -
Observe o seguinte sobre a saída:
-
IsAnomalousé um booleano para a classificação prevista.truese a imagem for anômala, caso contrário.false -
Confidenceé um valor flutuante que representa a confiança que o Amazon Lookout for Vision tem na previsão. 0 é a menor confiança, 1 é a confiança mais alta. -
Anomaliesé uma lista de anomalias encontradas na imagem.Nameé o rótulo da anomalia.PixelAnomalyinclui a área percentual total da anomalia (TotalPercentageArea) e uma cor (Color) para o rótulo da anomalia. A lista também inclui uma anomalia de “fundo” que cobre a área externa das anomalias encontradas na imagem. -
AnomalyMaské uma imagem de máscara que mostra a localização das anomalias na imagem analisada.
É possível usar as informações na resposta para exibir uma combinação da imagem analisada e da máscara de anomalia, conforme mostrado no exemplo a seguir. Para ver um código demonstrativo, consulte Exibindo informações de classificação e segmentação.

-
-
No prompt de comando, analise uma imagem normal da
test-imagespasta de introdução. Se você estiver usando olookoutvisionperfil para obter credenciais, adicione o--profile lookoutvision-accessparâmetro. Por exemplo:aws lookoutvision detect-anomalies \ --project-name getting-started \ --model-version 1 \ --content-type image/jpeg \ --body/path/to/test-images/test-normal-1.jpg\ --profile lookoutvision-accessA saída deve ser semelhante à seguinte:
{ "DetectAnomalyResult": { "Source": { "Type": "direct" }, "IsAnomalous": false, "Confidence": 0.9916400909423828, "Anomalies": [ { "Name": "background", "PixelAnomaly": { "TotalPercentageArea": 1.0, "Color": "#FFFFFF" } } ], "AnomalyMask": "iVBORw0KGgoAAAANSUhEUgAAAkAAAA....." } } -
Na saída, observe que o
falsevalor deIsAnomalousclassifica a imagem como sem anomalias. UseConfidencepara ajudar a decidir sua confiança na classificação. Além disso, aAnomaliesmatriz tem apenas o rótulo debackgroundanomalia.
Etapa 5: interromper o modelo
Nesta etapa, você deixa de hospedar o modelo. Você é cobrado pela quantidade de tempo em que seu modelo está em execução. Se você não estiver usando o modelo, interrompa. Você poderá reiniciar o modelo na próxima vez que precisar dele. Para obter mais informações, consulte Iniciar seu modelo do Amazon Lookout for Vision.
Como parar o modelo.
-
No painel de navegação, escolha Modelos.
Na página Modelos, escolha o modelo Modelo 1.
Na página de detalhes do modelo, escolha Usar modelo e, em seguida, escolha Integrar API à nuvem.
Na seção de comandos AWS CLI, copie o comando
stop-modelAWS CLI.
-
No prompt de comando, pare o modelo inserindo o
stop-modelAWS CLI comando da etapa anterior. Se você estiver usando olookoutvisionperfil para obter credenciais, adicione o--profile lookoutvision-accessparâmetro. Por exemplo:aws lookoutvision stop-model \ --project-name getting-started \ --model-version 1 \ --profile lookoutvision-accessSe a chamada tiver êxito, a seguinte saída será exibida:
{ "Status": "STOPPING_HOSTING" } De volta ao console, escolha Modelos na página de navegação à esquerda.
O modelo foi interrompido quando o status do modelo na coluna Status é Treinamento concluído.
Próximas etapas
Quando estiver pronto para criar um modelo com suas próprias imagens, comece seguindo as instruções emCriar seu projeto. As instruções incluem etapas para criar um modelo com o console Amazon Lookout for Vision e com AWS o SDK.
Se você quiser experimentar outros exemplos de conjuntos de dados, consulte Exemplos de códigos e conjuntos de dados.
