As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Casos de uso
Veja a seguir estão os casos de uso da pesquisa vetorial.
Geração Aumentada de Recuperação (RAG)
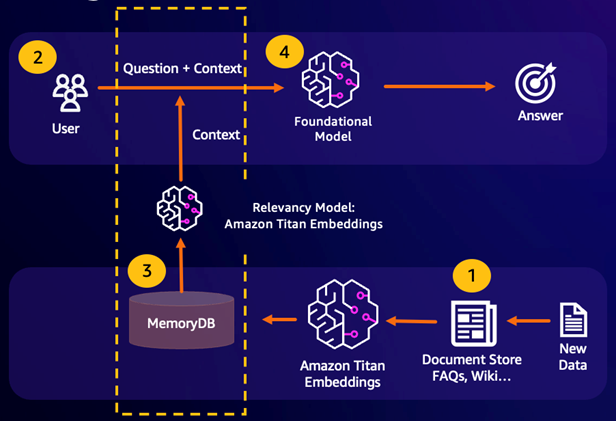
A Retrieval Augmented Generation (RAG) aproveita a pesquisa vetorial para recuperar passagens relevantes de um grande corpus de dados para ampliar um grande modelo de linguagem (LLM). Especificamente, um codificador incorpora o contexto de entrada e a consulta de pesquisa em vetores e, em seguida, usa a pesquisa aproximada do vizinho mais próximo para encontrar passagens semanticamente semelhantes. Essas passagens recuperadas são concatenadas com o contexto original para fornecer informações adicionais relevantes ao LLM a fim de retornar uma resposta mais precisa ao usuário.
Cache de semântica durável
O armazenamento em cache de semântica é um processo para reduzir os custos computacionais, armazenando resultados anteriores do FM. Ao reutilizar resultados anteriores de inferências anteriores em vez de recalculá-los, o cache semântico reduz a quantidade de computação necessária durante a inferência por meio do. FMs O MemoryDB permite um armazenamento em cache de semântica durável, o que evita a perda de dados das inferências anteriores. Isso permite que as aplicações de IA generativa respondam em menos de 10 milissegundos com respostas a perguntas anteriores que apresentam semelhança semântica, ao mesmo tempo em que reduzem os custos ao evitar inferências desnecessárias de LLM.
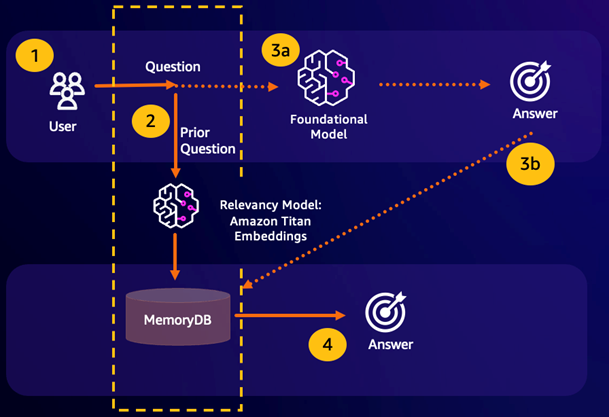
Acerto da pesquisa semântica: se a consulta de um cliente for semanticamente semelhante com base em uma pontuação de semelhança definida com uma pergunta anterior, a memória de buffer do FM (MemoryDB) retornará a resposta à pergunta anterior na etapa 4 e não chamará o FM na etapa 3. Isso evitará a latência do modelo de base (FM) e os custos incorridos, proporcionando uma experiência mais rápida para o cliente.
Erro na pesquisa semântica: se a consulta de um cliente não for semanticamente semelhante com base em uma pontuação de semelhança definida com uma consulta anterior, o cliente chamará o FM para fornecer uma resposta ao cliente na etapa 3a. A resposta gerada do FM será então armazenada como um vetor no MemoryDB para futuras consultas (etapa 3b), para minimizar os custos de FM em questões semanticamente semelhantes. Nesse fluxo, a etapa 4 não seria invocada, pois não havia uma pergunta semanticamente semelhante para a consulta original.
Detecção de fraudes
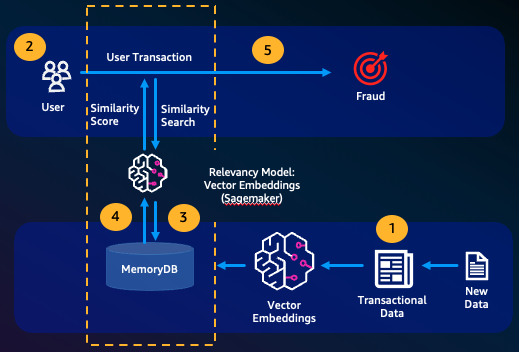
A detecção de fraudes, uma forma de detecção de anomalias, representa transações válidas como vetores enquanto compara as representações vetoriais de transações inéditas. A fraude é detectada quando essas transações inéditas têm baixa semelhança com os vetores que representam os dados transacionais válidos. Isso permite que a fraude seja detectada por meio da modelagem do comportamento normal, em vez de tentar prever todas as ocorrências possíveis de uma fraude. O MemoryDB permite que as organizações façam isso em períodos de alta throughput, com o mínimo de falsos positivos e latência de menos de 10 milissegundos.
Outros casos de uso
Os mecanismos de recomendação podem encontrar produtos ou conteúdos semelhantes aos usuários representando itens como vetores. Os vetores são criados pela análise de atributos e padrões. Com base nos padrões e atributos do usuário, novos itens não vistos podem ser recomendados aos usuários, encontrando os vetores mais semelhantes já classificados positivamente alinhados ao usuário.
Mecanismos de pesquisa de documentos representam documentos de texto como vetores densos de números, capturando o significado semântico. No momento da pesquisa, o mecanismo converte uma consulta de pesquisa em um vetor e encontra documentos com os vetores mais semelhantes a essa consulta usando a pesquisa aproximada do vizinho mais próximo. Essa abordagem de semelhança vetorial permite combinar documentos com base no significado, em vez de apenas combinar palavras-chave.
