As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Etapa 5. Criar o modelo de dados do DynamoDB
Objetivo
-
Criar o modelo de dados do DynamoDB.
Processo
-
O engenheiro de banco de dados identifica quantas tabelas serão necessárias para cada caso de uso. Você deve manter o mínimo de tabelas possível em uma aplicação do DynamoDB.
-
Com base nos padrões de acesso mais comuns, identifique a chave primária que pode ser de dois tipos: uma chave primária com uma chave de partição que identifica dados ou uma chave primária com uma chave de partição e uma chave de classificação. Uma chave de classificação é uma chave secundária para agrupar e organizar dados para que possam ser consultados em uma partição de forma eficiente. Você pode usar chaves de classificação para definir relacionamentos hierárquicos em seus dados que podem ser consultados em qualquer nível da hierarquia (consulte o post do blog
). -
Design de chave de partição
-
Definir a chave de partição e avaliar sua distribuição.
-
Identificar a necessidade de fragmentação de gravação para distribuir uniformemente as workloads.
-
-
Design de chaves de classificação
-
Identificar a chave de classificação.
-
Identificar a necessidade de uma chave de classificação composta.
-
Identificar a necessidade de controle de versão.
-
-
-
Com base nos padrões de acesso, identificar os índices secundários para atender aos requisitos de consulta.
-
Identifique a necessidade de índices secundários locais (LSIs). Esses são índices que possuem a mesma chave de partição da tabela base, mas uma chave de classificação diferente.
-
Para tabelas com LSIs, há um limite de tamanho de 10 GB por valor de chave de partição. Uma tabela com LSIs pode armazenar qualquer número de itens, desde que o tamanho total de qualquer valor de chave de partição não exceda 10 GB.
-
-
Identifique a necessidade de índices secundários globais (GSIs). Esses são índices com uma chave de partição e uma chave de classificação que podem ser diferentes das contidas na tabela base (consulte o post do blog
). -
Definir as projeções do índice. Considere projetar menos atributos para reduzir o tamanho dos itens gravados no índice. Nesta etapa, você deverá determinar se deseja usar o seguinte:
-
-
O engenheiro de banco de dados determina se os dados incluirão itens grandes. Nesse caso, eles projetam a solução usando compressão ou armazenando dados no Amazon Simple Storage Service (Amazon S3).
-
O engenheiro de banco de dados determina se dados de séries temporais serão necessários. Nesse caso, eles usam o padrão de design de séries temporais para modelar os dados.
-
O engenheiro de banco de dados determina se o modelo ER inclui many-to-many relacionamentos. Nesse caso, ele usa um padrão de design de lista de adjacências para modelar os dados.
Ferramentas e recursos
-
Escolher a chave de partição correta do DynamoDB
(blog da base de dados AWS) -
Práticas recomendadas para usar índices secundários no DynamoDB (documentação do DynamoDB)
-
Como criar índices secundários globais do Amazon DynamoDB
(blog da base de dados AWS)
RACI
| Usuário empresarial | Analista de negócios | Arquiteto de soluções | Engenheiro do banco de dados | Desenvolvedor de aplicações | DevOps engenheiro |
|---|---|---|---|---|---|
eu |
eu |
eu |
R/A |
Saídas
-
Esquema de tabela do DynamoDB que satisfaz seus padrões e requisitos de acesso
Exemplo
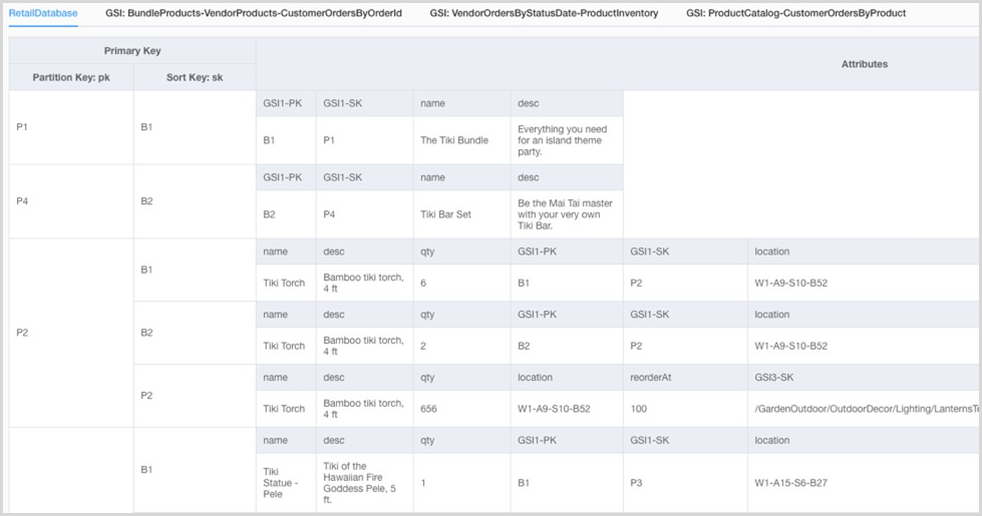
A captura de tela a seguir mostra o NoSQL Workbench.