Best practices for managing many-to-many relationships in DynamoDB tables
Adjacency lists are a design pattern that is useful for modeling many-to-many relationships in Amazon DynamoDB. More generally, they provide a way to represent graph data (nodes and edges) in DynamoDB.
Adjacency list design pattern
When different entities of an application have a many-to-many relationship between them, the relationship can be modeled as an adjacency list. In this pattern, all top-level entities (synonymous to nodes in the graph model) are represented using the partition key. Any relationships with other entities (edges in a graph) are represented as an item within the partition by setting the value of the sort key to the target entity ID (target node).
The advantages of this pattern include minimal data duplication and simplified query patterns to find all entities (nodes) related to a target entity (having an edge to a target node).
A real-world example where this pattern has been useful is an invoicing system where
invoices contain multiple bills. One bill can belong in multiple invoices. The partition key
in this example is either an InvoiceID or a BillID.
BillID partitions have all attributes specific to bills. InvoiceID
partitions have an item storing invoice-specific attributes, and an item for each
BillID that rolls up to the invoice.
The schema looks like the following.

Using the preceding schema, you can see that all bills for an invoice can be queried using the primary key on the table. To look up all invoices that contain a part of a bill, create a global secondary index on the table's sort key.
The projections for the global secondary index look like the following.

Materialized graph pattern
Many applications are built around understanding rankings across peers, common relationships between entities, neighbor entity state, and other types of graph style workflows. For these types of applications, consider the following schema design pattern.



The preceding schema shows a graph data structure that is defined by a set of data
partitions containing the items that define the edges and nodes of the graph. Edge items
contain a Target and a Type attribute. These attributes are used as
part of a composite key name "TypeTarget" to identify the item in a partition in the primary
table or in a second global secondary index.
The first global secondary index is built on the Data attribute. This
attribute uses global secondary index-overloading as described earlier to index several
different attribute types, namely Dates, Names, Places,
and Skills. Here, one global secondary index is effectively indexing four
different attributes.
As you insert items into the table, you can use an intelligent sharding strategy to distribute item sets with large aggregations (birthdate, skill) across as many logical partitions on the global secondary indexes as are needed to avoid hot read/write problems.
The result of this combination of design patterns is a solid datastore for highly efficient real-time graph workflows. These workflows can provide high-performance neighbor entity state and edge aggregation queries for recommendation engines, social-networking applications, node rankings, subtree aggregations, and other common graph use cases.
If your use case isn't sensitive to real-time data consistency, you can use a scheduled Amazon EMR process to populate edges with relevant graph summary aggregations for your workflows. If your application doesn't need to know immediately when an edge is added to the graph, you can use a scheduled process to aggregate results.
To maintain some level of consistency, the design could include Amazon DynamoDB Streams and AWS Lambda to process edge updates. It could also use an Amazon EMR job to validate results on a regular interval. This approach is illustrated by the following diagram. It is commonly used in social networking applications, where the cost of a real-time query is high and the need to immediately know individual user updates is low.
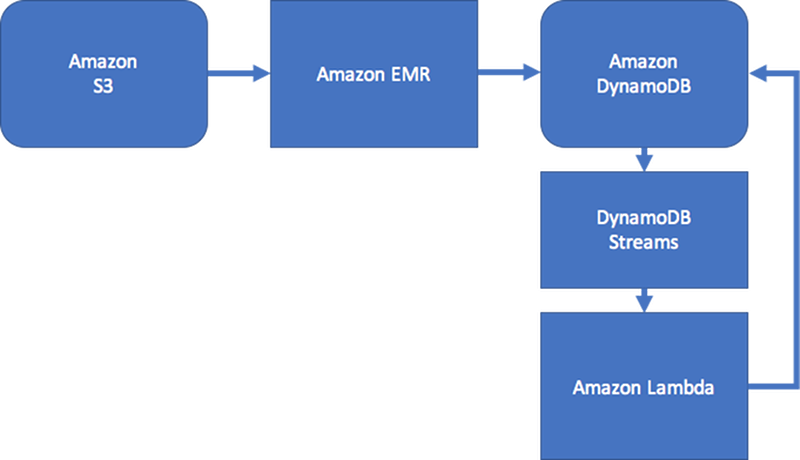
IT service-management (ITSM) and security applications generally need to respond in real time to entity state changes composed of complex edge aggregations. Such applications need a system that can support real-time multiple node aggregations of second- and third-level relationships, or complex edge traversals. If your use case requires these types of real-time graph query workflows, we recommend that you consider using Amazon Neptune to manage these workflows.
Note
If you need to query highly connected datasets or execute queries that need to traverse multiple nodes (also known as multi-hop queries) with millisecond latency, you should consider using Amazon Neptune. Amazon Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with millisecond latency.
