Monitoring device status updates in DynamoDB
This use case talks about using DynamoDB to monitor device status updates (or changes in device state) in DynamoDB.
Use case
In IoT use-cases (a smart factory for instance) many devices need to be monitored by operators and they periodically send their status or logs to a monitoring system. When there is a problem with a device, the status for the device changes from normal to warning. There are different log levels or statuses depending on the severity and type of abnormal behavior in the device. The system then assigns an operator to check on the device and they may escalate the problem to their supervisor if needed.
Some typical access patterns for this system include:
-
Create log entry for a device
-
Get all logs for a specific device state showing the most recent logs first
-
Get all logs for a given operator between two dates
-
Get all escalated logs for a given supervisor
-
Get all escalated logs with a specific device state for a given supervisor
-
Get all escalated logs with a specific device state for a given supervisor for a specific date
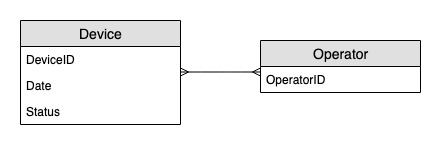
Entity relationship diagram
This is the entity relationship diagram (ERD) we'll be using for monitoring device status updates.
Access patterns
These are the access patterns we'll be considering for monitoring device status updates.
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
Schema design evolution
Step 1: Address access patterns 1
(createLogEntryForSpecificDevice) and 2
(getLogsForSpecificDevice)
The unit of scaling for a device tracking system would be individual devices. In this
system, a deviceID uniquely identifies a device. This makes
deviceID a good candidate for the partition key. Each device sends
information to the tracking system periodically (say, every five minutes or so). This
ordering makes date a logical sorting criterion and therefore, the sort key. The sample
data in this case would look something like this:

To fetch log entries for a specific device, we can perform a query operation with partition key DeviceID="d#12345".
Step 2: Address access pattern 3
(getWarningLogsForSpecificDevice)
Since State is a non-key attribute, addressing access pattern 3 with the
current schema would require a filter
expression. In DynamoDB, filter expressions are applied after data is read using
key condition expressions. For example, if we were to fetch warning logs for
d#12345, the query operation with partition key
DeviceID="d#12345" will read four items from the above table and then
filter out the one item without the warning status.
This approach is not efficient at scale. A filter expression can be a good way to
exclude items that are queried if the ratio of excluded items is low or the query is
performed infrequently. However, for cases where many items are retrieved from a table
and the majority of the items are filtered out, we can continue evolving our table
design so it runs more efficiently.
Let's change how to handle this access pattern by using composite sort keys. You can import
sample data from DeviceStateLog_3.jsonState#Date. This sort key is the composition of the attributes
State, #, and Date. In this example,
# is used as a delimiter. The data now looks something like this:

To fetch only warning logs for a device, the query becomes more targeted with this
schema. The key condition for the query uses partition key
DeviceID="d#12345" and sort key State#Date begins_with
“WARNING”. This query will only read the relevant three items with the
warning state.
Step 3: Address access pattern 4
(getLogsForOperatorBetweenTwoDates)
You can import DeviceStateLog_4.jsonOperator attribute was added
to the DeviceStateLog table with example data.

Since Operator is not currently a partition key, there is no way to
perform a direct key-value lookup on this table based on OperatorID. We’ll
need to create a new item collection
with a global secondary index on OperatorID. The access pattern requires a
lookup based on dates so Date is the sort key attribute for the global secondary index (GSI). This is what the GSI now looks
like:

For access pattern 4 (getLogsForOperatorBetweenTwoDates), you can query
this GSI with partition key OperatorID=Liz and sort key Date
between 2020-04-11T05:58:00 and 2020-04-24T14:50:00.

Step 4: Address access patterns 5
(getEscalatedLogsForSupervisor) 6
(getEscalatedLogsWithSpecificStatusForSupervisor), and 7
(getEscalatedLogsWithSpecificStatusForSupervisorForDate)
We’ll be using a sparse index to address these access patterns.
Global secondary indexes are sparse by default, so only items in the base table that contain primary key attributes of the index will actually appear in the index. This is another way of excluding items that are not relevant for the access pattern being modeled.
You can import DeviceStateLog_6.jsonEscalatedTo attribute was
added to the DeviceStateLog table with example data. As mentioned earlier,
not all of the logs gets escalated to a supervisor.

You can now create a new GSI where EscalatedTo is the partition key and
State#Date is the sort key. Notice that only items that have both
EscalatedTo and State#Date attributes appear in the
index.

The rest of the access patterns are summarized as follows:
All access patterns and how the schema design addresses them are summarized in the table below:
| Access pattern | Base table/GSI/LSI | Operation | Partition key value | Sort key value | Other conditions/filters |
|---|---|---|---|---|---|
| createLogEntryForSpecificDevice | Base table | PutItem | DeviceID=deviceId | State#Date=state#date | |
| getLogsForSpecificDevice | Base table | Query | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = False |
| getWarningLogsForSpecificDevice | Base table | Query | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| getLogsForOperatorBetweenTwoDates | GSI-1 | Query | Operator=operatorName | Date between date1 and date2 | |
| getEscalatedLogsForSupervisor | GSI-2 | Query | EscalatedTo=supervisorName | ||
| getEscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | Query | EscalatedTo=supervisorName | State#Date begins_with "state1#" | |
| getEscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | Query | EscalatedTo=supervisorName | State#Date begins_with "state1#date1" |
Final schema
Here are the final schema designs. To download this schema design as a JSON file, see
DynamoDB Examples
Base table

GSI-1

GSI-2

Using NoSQL Workbench with this schema design
You can import this final schema into NoSQL Workbench, a visual tool that provides data modeling, data visualization, and query development features for DynamoDB, to further explore and edit your new project. Follow these steps to get started:
-
Download NoSQL Workbench. For more information, see Download NoSQL Workbench for DynamoDB.
-
Download the JSON schema file listed above, which is already in the NoSQL Workbench model format.
-
Import the JSON schema file into NoSQL Workbench. For more information, see Importing an existing data model.
-
Once you've imported into NOSQL Workbench, you can edit the data model. For more information, see Editing an existing data model.
