As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Desenvolva assistentes avançados baseados em bate-papo com IA generativa usando RAG e prompting ReAct
Criado por Praveen Kumar Jeyarajan (AWS), Jundong Qiao (AWS), Kara Yang (AWS), Kiowa Jackson (AWS), Noah Hamilton (AWS) e Shuai Cao (AWS)
Repositório de códigos: genai-bedrock-chatbot | Ambiente: PoC ou piloto | Tecnologias: aprendizado de máquina e IA; bancos de dados DevOps; sem servidor |
Serviços da AWS: Amazon Bedrock; Amazon ECS; Amazon Kendra; AWS Lambda |
Resumo
Uma empresa típica tem 70% de seus dados presos em sistemas isolados. Você pode usar assistentes generativos baseados em bate-papo com inteligência artificial para descobrir insights e relacionamentos entre esses silos de dados por meio de interações em linguagem natural. Para tirar o máximo proveito da IA generativa, os resultados devem ser confiáveis, precisos e incluir os dados corporativos disponíveis. Assistentes bem-sucedidos baseados em bate-papo dependem do seguinte:
Modelos generativos de IA (como Anthropic Claude 2)
Vetorização da fonte de dados
Técnicas avançadas de raciocínio, como a ReAct estrutura
, para estimular o modelo
Esse padrão fornece abordagens de recuperação de dados de fontes de dados como buckets do Amazon Simple Storage Service (Amazon S3), AWS Glue e Amazon Relational Database Service (Amazon RDS). O valor é obtido a partir desses dados intercalando a Geração Aumentada de Recuperação (RAG) com métodos. chain-of-thought Os resultados apoiam conversas complexas com assistentes baseadas em bate-papo que se baseiam na totalidade dos dados armazenados de sua empresa.
Esse padrão usa SageMaker manuais e tabelas de dados de preços da Amazon como exemplo para explorar os recursos de um assistente generativo baseado em bate-papo com IA. Você criará um assistente baseado em bate-papo que ajudará os clientes a avaliar o SageMaker serviço respondendo a perguntas sobre preços e recursos do serviço. A solução usa uma biblioteca Streamlit para criar o aplicativo de front-end e a LangChain estrutura para desenvolver o back-end do aplicativo alimentado por um modelo de linguagem grande (LLM).
As consultas ao assistente baseado em bate-papo são atendidas com uma classificação inicial de intenção para encaminhamento para um dos três fluxos de trabalho possíveis. O fluxo de trabalho mais sofisticado combina orientação consultiva geral com análises complexas de preços. Você pode adaptar o padrão para se adequar aos casos de uso corporativo, corporativo e industrial.
Pré-requisitos e limitações
Pré-requisitos
AWS Command Line Interface (AWS CLI) instalada e configurada
Kit de ferramentas do AWS Cloud Development Kit (AWS CDK) 2.114.1 ou posterior instalado e configurado
Familiaridade básica com Python e AWS CDK
Git
instalado Python 3.11 ou posterior
instalado e configurado (para obter mais informações, consulte a seção Ferramentas) Uma conta ativa da AWS inicializada usando o AWS CDK
Acesso aos modelos Amazon Titan e Anthropic Claude ativado no serviço Amazon Bedrock
Credenciais de segurança da AWS, inclusive
AWS_ACCESS_KEY_ID, configuradas corretamente em seu ambiente de terminal
Limitações
LangChain não suporta todos os LLM para streaming. Os modelos Anthropic Claude são compatíveis, mas os modelos do AI21 Labs não.
Essa solução é implantada em uma única conta da AWS.
Essa solução pode ser implantada somente nas regiões da AWS onde o Amazon Bedrock e o Amazon Kendra estão disponíveis. Para obter informações sobre disponibilidade, consulte a documentação do Amazon Bedrock e do Amazon Kendra.
Versões do produto
Python versão 3.11 ou posterior
Streamlit versão 1.30.0 ou posterior
Streamlit-chat versão 0.1.1 ou posterior
LangChain versão 0.1.12 ou posterior
AWS CDK versão 2.132.1 ou posterior
Arquitetura
Pilha de tecnologias de destino
Amazon Athena
Amazon Bedrock
Amazon Elastic Container Service (Amazon ECS)
AWS Glue
AWS Lambda
Amazon S3
Amazon Kendra
Elastic Load Balancing
Arquitetura de destino
O código do AWS CDK implantará todos os recursos necessários para configurar o aplicativo assistente baseado em chat em uma conta da AWS. O aplicativo assistente baseado em bate-papo mostrado no diagrama a seguir foi projetado para responder às consultas SageMaker relacionadas dos usuários. Os usuários se conectam por meio de um Application Load Balancer a uma VPC que contém um cluster do Amazon ECS que hospeda o aplicativo Streamlit. Uma função Lambda de orquestração se conecta ao aplicativo. As fontes de dados do bucket do S3 fornecem dados para a função Lambda por meio do Amazon Kendra e do AWS Glue. A função Lambda se conecta ao Amazon Bedrock para responder consultas (perguntas) de usuários assistentes baseados em bate-papo.

A função Lambda de orquestração envia a solicitação de prompt do LLM para o modelo Amazon Bedrock (Claude 2).
O Amazon Bedrock envia a resposta do LLM de volta para a função Lambda de orquestração.
Fluxo lógico dentro da função Lambda de orquestração
Quando os usuários fazem uma pergunta por meio do aplicativo Streamlit, ele invoca diretamente a função Lambda de orquestração. O diagrama a seguir mostra o fluxo lógico quando a função Lambda é invocada.
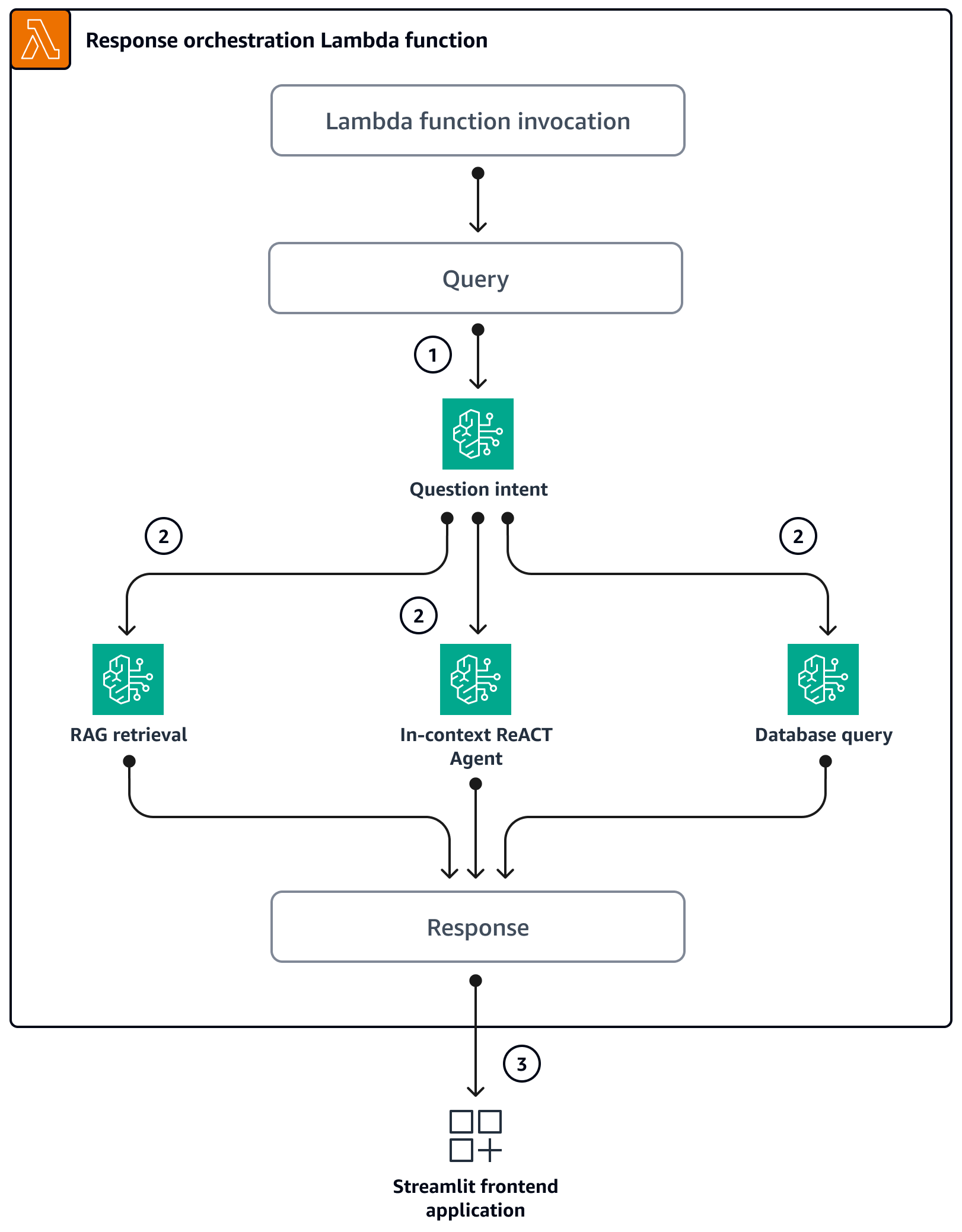
Etapa 1 — A entrada
query(pergunta) é classificada em uma das três intenções:Perguntas gerais de SageMaker orientação
Perguntas gerais SageMaker sobre preços (treinamento/inferência)
Perguntas complexas relacionadas SageMaker a preços
Etapa 2 — A entrada
queryinicia um dos três serviços:RAG Retrieval service, que recupera o contexto relevante do banco de dados vetoriais Amazon Kendrae chama o LLM por meio do Amazon Bedrock para resumir o contexto recuperado como resposta. Database Query service, que usa o LLM, os metadados do banco de dados e as linhas de amostra das tabelas relevantes para converter aqueryentrada em uma consulta SQL. O serviço Database Query executa a consulta SQL no banco de dados de SageMaker preços por meio do Amazon Athenae resume os resultados da consulta como resposta. In-context ReACT Agent service, que divide a entradaqueryem várias etapas antes de fornecer uma resposta. O agente usaRAG Retrieval serviceeDatabase Query servicecomo ferramentas para recuperar informações relevantes durante o processo de raciocínio. Depois que os processos de raciocínio e ações são concluídos, o agente gera a resposta final como resposta.
Etapa 3 — A resposta da função Lambda de orquestração é enviada ao aplicativo Streamlit como saída.
Ferramentas
Serviços da AWS
O Amazon Athena é um serviço de consultas interativas que permite analisar dados diretamente no Amazon Simple Storage Service (Amazon S3) usando SQL padrão.
O Amazon Bedrock é um serviço totalmente gerenciado que disponibiliza modelos básicos (FMs) de alto desempenho das principais startups de IA e da Amazon para seu uso por meio de uma API unificada.
O AWS Cloud Development Kit (AWS CDK) é uma estrutura de desenvolvimento de software que ajuda você a definir e provisionar a infraestrutura da Nuvem AWS em código.
A AWS Command Line Interface (AWS CLI) é uma ferramenta de código aberto que permite que você interaja com serviços da AWS usando comandos no shell da linha de comando.
O Amazon Elastic Container Service (Amazon ECS) é um serviço de gerenciamento de contêineres escalável e rápido que facilita a execução, a interrupção e o gerenciamento de contêineres em um cluster.
O AWS Glue é um serviço de extração, transformação e carregamento (ETL) totalmente gerenciado. Ele ajuda você a categorizar de forma confiável, limpar, enriquecer e mover dados de forma confiável entre armazenamento de dados e fluxos de dados. Esse padrão usa um crawler do AWS Glue e uma tabela do Catálogo de Dados do AWS Glue.
O Amazon Kendra é um serviço de pesquisa inteligente que usa processamento de linguagem natural e algoritmos avançados de aprendizado de máquina para retornar respostas específicas às perguntas de pesquisa de seus dados.
O AWS Lambda é um serviço de computação que ajuda você a executar código sem exigir provisionamento ou gerenciamento de servidores. Ele executa o código somente quando necessário e dimensiona automaticamente, assim, você paga apenas pelo tempo de computação usado.
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos baseado na nuvem que ajuda você a armazenar, proteger e recuperar qualquer quantidade de dados.
O Elastic Load Balancing (ELB) distribui o tráfego de entrada de aplicativos ou de rede em vários destinos. Por exemplo, é possível distribuir o tráfego entre instâncias, contêineres e endereços IP do Amazon Elastic Compute Cloud (Amazon EC2) em uma ou mais Zonas de disponibilidade.
Repositório de código
O código desse padrão está disponível no GitHub genai-bedrock-chatbot
O repositório de código contém os seguintes arquivos e pastas:
assetspasta — Os ativos estáticos, o diagrama de arquitetura e o conjunto de dados públicocode/lambda-containerpasta — O código Python que é executado na função Lambdacode/streamlit-apppasta — O código Python que é executado como imagem de contêiner no Amazon ECStestspasta — Os arquivos Python que são executados para testar a unidade das construções do AWS CDKcode/code_stack.py— O AWS CDK constrói arquivos Python usados para criar recursos da AWSapp.py— O AWS CDK empilha arquivos Python usados para implantar recursos da AWS na conta de destino da AWSrequirements.txt— A lista de todas as dependências do Python que devem ser instaladas para o AWS CDKrequirements-dev.txt— A lista de todas as dependências do Python que devem ser instaladas para que o AWS CDK execute o pacote de testes unitárioscdk.json: o arquivo de entrada para fornecer os valores necessários para gerar recursos
Observação: o código do AWS CDK usa construções L3 (camada 3) e políticas do AWS Identity and Access Management (IAM) gerenciadas pela AWS para implantar a solução. |
Práticas recomendadas
O exemplo de código fornecido aqui é somente para uma demonstração proof-of-concept (PoC) ou piloto. Se você quiser levar o código para a produção, certifique-se de usar as seguintes práticas recomendadas:
O índice Amazon Kendra Enterprise Edition está ativado.
Configure o monitoramento e o alerta para a função do Lambda. Para obter mais informações, consulte Monitorar e solucionar problemas de funções do Lambda. Para obter as melhores práticas gerais ao trabalhar com funções do Lambda, consulte a documentação da AWS.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Exporte variáveis para a conta e a região da AWS em que a pilha será implantada. | Para fornecer credenciais da AWS para o AWS CDK usando variáveis de ambiente, execute os seguintes comandos.
| DevOps engenheiro, AWS DevOps |
Configurar o perfil da AWS CLI. | Para configurar o perfil da AWS CLI para a conta, siga as instruções na documentação da AWS. | DevOps engenheiro, AWS DevOps |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Clone o repositório na sua máquina local. | Para clonar o repositório, execute o comando a seguir no seu terminal.
| DevOps engenheiro, AWS DevOps |
Configurar o ambiente virtual Python e instalar as dependências necessárias. | Para ativar o ambiente virtual do Python, execute os comandos a seguir.
Para configurar as dependências necessárias, execute o comando a seguir.
| DevOps engenheiro, AWS DevOps |
Configure o ambiente do AWS CDK e sintetize o código do AWS CDK. |
| DevOps engenheiro, AWS DevOps |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Provisione o acesso ao modelo Claude. | Para habilitar o acesso ao modelo Anthropic Claude para sua conta da AWS, siga as instruções na documentação do Amazon Bedrock. | AWS DevOps |
Implante recursos na conta. | Para implantar recursos na conta da AWS usando o AWS CDK, faça o seguinte:
Após a implantação bem-sucedida, você pode acessar o aplicativo assistente baseado em bate-papo usando a URL fornecida na seção CloudFormation Saídas. | AWS DevOps, DevOps engenheiro |
Execute o AWS Glue Crawler e crie a tabela do Data Catalog. | Um AWS Glue Crawler é usado para manter o esquema de dados dinâmico. A solução cria e atualiza partições na tabela do AWS Glue Data Catalog executando o rastreador sob demanda. Depois que os arquivos do conjunto de dados CSV forem copiados no bucket do S3, execute o crawler AWS Glue e crie o esquema da tabela do catálogo de dados para teste:
Observação: o código do AWS CDK configura o crawler AWS Glue para ser executado sob demanda, mas você também pode programá-lo para ser executado periodicamente. | DevOps engenheiro, AWS DevOps |
Inicie a indexação de documentos. | Depois que os arquivos forem copiados no bucket do S3, use o Amazon Kendra para rastreá-los e indexá-los:
| AWS DevOps, DevOps engenheiro |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Remova os recursos da AWS. | Depois de testar a solução, limpe os recursos:
| DevOps engenheiro, AWS DevOps |
Solução de problemas
| Problema | Solução |
|---|---|
O AWS CDK retorna erros. | Para obter ajuda com problemas do AWS CDK, consulte Solução de problemas comuns do AWS CDK. |
Recursos relacionados
Mais informações
Comandos do AWS CDK
Ao trabalhar com o AWS CDK, lembre-se dos seguintes comandos úteis:
Lista todas as pilhas no aplicativo
cdk lsEmite o modelo sintetizado da AWS CloudFormation
cdk synthImplanta a pilha na sua conta e região padrão da AWS
cdk deployCompara a pilha implantada com o estado atual
cdk diffAbre a documentação do AWS CDK
cdk docsExclui a CloudFormation pilha e remove os recursos implantados da AWS
cdk destroy
