As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Capacidade 2. Fornecendo acesso, uso e implementação seguros às técnicas generativas de IA RAG
O diagrama a seguir ilustra os AWS serviços recomendados para a conta Generative AI para recuperação do recurso de geração aumentada (). RAG O escopo desse cenário é proteger a RAG funcionalidade.
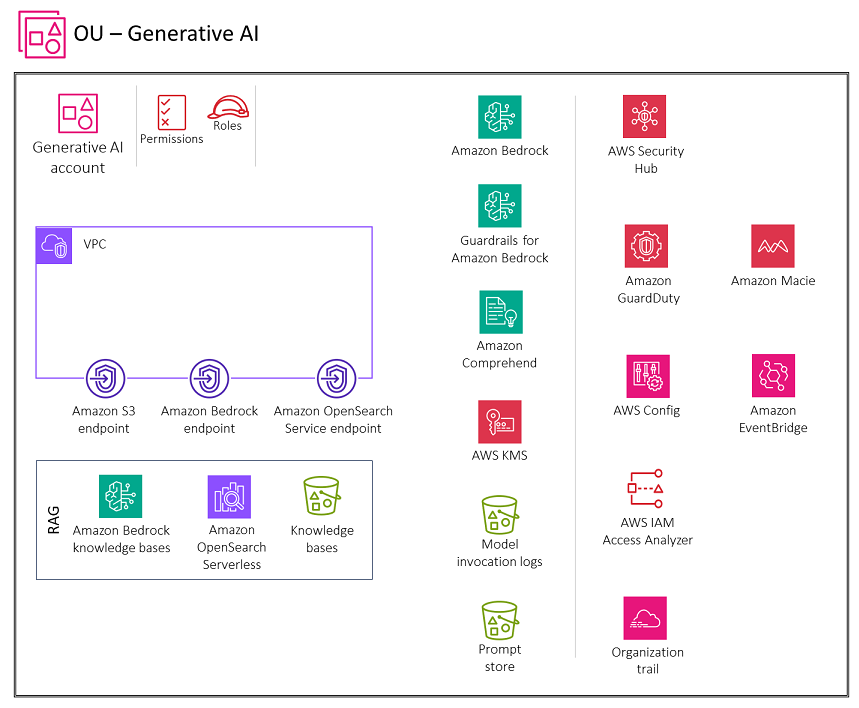
A conta Generative AI inclui serviços necessários para armazenar incorporações em um banco de dados vetorial, armazenar conversas para usuários e manter um armazenamento imediato, além de um conjunto de serviços de segurança necessários para implementar barreiras de segurança e governança de segurança centralizada. Você deve criar endpoints de gateway do Amazon S3 para os registros de invocação do modelo, o armazenamento de prompts e os buckets da fonte de dados da base de conhecimento no Amazon S3 que o ambiente está configurado para acessar. VPC Você também deve criar um endpoint do CloudWatch Logs Gateway para os CloudWatch registros que o VPC ambiente está configurado para acessar.
Lógica
A Geração Aumentada de Recuperação (RAG)
Ao conceder aos usuários acesso às bases de conhecimento do Amazon Bedrock, você deve abordar estas principais considerações de segurança:
-
Acesso seguro à invocação do modelo, bases de conhecimento, histórico de conversas e armazenamento de solicitações
-
Criptografia de conversas, armazenamento de mensagens e bases de conhecimento
-
Alertas para possíveis riscos de segurança, como injeção imediata ou divulgação de informações confidenciais
A próxima seção discute essas considerações de segurança e a funcionalidade generativa de IA.
Considerações sobre design
Recomendamos que você evite personalizar um FM com dados confidenciais (consulte a seção sobre personalização generativa do modelo de IA mais adiante neste guia). Em vez disso, use a RAG técnica para interagir com informações confidenciais. Esse método oferece várias vantagens:
-
Controle e visibilidade mais rígidos. Ao manter os dados confidenciais separados do modelo, você pode exercer maior controle e visibilidade sobre as informações confidenciais. Os dados podem ser facilmente editados, atualizados ou removidos conforme necessário, o que ajuda a garantir uma melhor governança de dados.
-
Mitigar a divulgação de informações confidenciais. RAGpermite interações mais controladas com dados confidenciais durante a invocação do modelo. Isso ajuda a reduzir o risco de divulgação não intencional de informações confidenciais, o que poderia ocorrer se os dados fossem incorporados diretamente aos parâmetros do modelo.
-
Flexibilidade e adaptabilidade. Separar dados confidenciais do modelo oferece maior flexibilidade e adaptabilidade. Conforme os requisitos de dados ou os regulamentos mudam, as informações confidenciais podem ser atualizadas ou modificadas sem a necessidade de retreinar ou reconstruir todo o modelo de linguagem.
Bases de conhecimento do Amazon Bedrock
Você pode usar as bases de conhecimento do Amazon Bedrock para criar RAG aplicativos conectando-se FMs às suas próprias fontes de dados de forma segura e eficiente. Esse recurso usa o Amazon OpenSearch Serverless como um armazenamento vetorial para recuperar informações relevantes de seus dados de forma eficiente. Os dados são então usados pelo FM para gerar respostas. Seus dados são sincronizados do Amazon S3 com a base de conhecimento, e
Considerações sobre segurança
RAGAs cargas de trabalho generativas de IA enfrentam riscos exclusivos, incluindo a exfiltração de dados de fontes de RAG dados e o envenenamento de fontes de RAG dados com injeções imediatas ou malware por agentes de ameaças. As bases de conhecimento do Amazon Bedrock oferecem controles de segurança robustos para proteção de dados, controle de acesso, segurança de rede, registro e monitoramento e validação de entrada/saída que podem ajudar a mitigar esses riscos.
Remediações
Proteção de dados
Criptografe os dados de sua base de conhecimento em repouso usando uma AWS chave gerenciada pelo cliente do Key Management Service (AWSKMS) que você cria, possui e gerencia. Ao configurar um trabalho de ingestão de dados para sua base de conhecimento, criptografe o trabalho com uma chave gerenciada pelo cliente. Se você optar por permitir que o Amazon Bedrock crie um armazenamento vetorial no Amazon OpenSearch Service para sua base de conhecimento, o Amazon Bedrock poderá passar uma AWS KMS chave de sua escolha para o Amazon OpenSearch Service para criptografia.
Você pode criptografar sessões nas quais gera respostas consultando uma base de conhecimento com uma AWS KMS chave. Você armazena as fontes de dados da sua base de conhecimento em seu bucket do S3. Se você criptografar suas fontes de dados no Amazon S3 com uma chave gerenciada pelo cliente, anexe uma política à sua função de serviço da base de conhecimento. Se o repositório vetorial que contém sua base de conhecimento estiver configurado com um segredo do AWS Secrets Manager, criptografe o segredo com uma chave gerenciada pelo cliente.
Para obter mais informações e as políticas a serem usadas, consulte Criptografia de recursos da base de conhecimento na documentação do Amazon Bedrock.
Gerenciamento de identidade e acesso
Crie uma função de serviço personalizada para bases de conhecimento do Amazon Bedrock seguindo o princípio do privilégio mínimo. Crie uma relação de confiança que permita à Amazon Bedrock assumir essa função e criar e gerenciar bases de conhecimento. Anexe as seguintes políticas de identidade à função de serviço personalizada da base de conhecimento:
-
Permissões para acessar os modelos Amazon Bedrock
-
Permissões para acessar suas fontes de dados no Amazon S3
-
Permissões para acessar seu banco de dados vetoriais no OpenSearch Service
-
Permissões para acessar seu cluster de banco de dados Amazon Aurora (opcional)
-
Permissões para acessar um banco de dados vetoriais configurado com um segredo do AWS Secrets Manager (opcional)
-
Permissões AWS para gerenciar uma AWS KMS chave para armazenamento transitório de dados durante a ingestão de dados
-
Permissões para conversar com seu documento
-
Permissões AWS para gerenciar uma fonte de dados da AWS conta de outro usuário (opcional).
As bases de conhecimento oferecem suporte a configurações de segurança para definir políticas de acesso a dados para sua base de conhecimento e políticas de acesso à rede para sua base de conhecimento privada Amazon OpenSearch Serverless. Para obter mais informações, consulte Criar uma base de conhecimento e funções de serviço na documentação do Amazon Bedrock.
Validação de entrada e saída
A validação de entradas é crucial para as bases de conhecimento do Amazon Bedrock. Use a proteção contra malware no Amazon S3 para verificar se há conteúdo malicioso nos arquivos antes de enviá-los para uma fonte de dados. Para obter mais informações, consulte a postagem do AWS blog Integrando a verificação de malware em seu pipeline de ingestão de dados com antivírus para o Amazon S3
Identifique e filtre possíveis injeções imediatas em carregamentos de usuários para fontes de dados da base de conhecimento. Além disso, detecte e edite informações de identificação pessoal (PII) como outro controle de validação de entrada em seu pipeline de ingestão de dados. O Amazon Comprehend pode ajudar a detectar e PII redigir dados em carregamentos de usuários para fontes de dados da base de conhecimento. Para obter mais informações, consulte Detecção de PII entidades na documentação do Amazon Comprehend.
Também recomendamos que você use o Amazon Macie para detectar e gerar alertas sobre possíveis dados confidenciais nas fontes de dados da base de conhecimento, a fim de melhorar a segurança e a conformidade gerais. Implemente grades de proteção para o Amazon Bedrock para ajudar a aplicar políticas de conteúdo, bloquear entradas/saídas inseguras e ajudar a controlar o comportamento do modelo com base em seus requisitos.
AWSServiços recomendados
Amazon sem OpenSearch servidor
O Amazon OpenSearch Serverless é uma configuração sob demanda e de auto-escalabilidade para o Amazon Service. OpenSearch Uma coleção OpenSearch sem servidor é um OpenSearch cluster que dimensiona a capacidade computacional com base nas necessidades do seu aplicativo. As bases de conhecimento do Amazon Bedrock usam o Amazon OpenSearch Serverless para incorporações e o Amazon
Implemente autenticação e autorização fortes para seu armazenamento vetorial OpenSearch sem servidor. Implemente o princípio do privilégio mínimo, que concede somente as permissões necessárias aos usuários e funções.
Com o controle de acesso a dados no OpenSearch Serverless, você pode permitir que os usuários acessem coleções e índices, independentemente de seus mecanismos de acesso ou fontes de rede. Você gerencia as permissões de acesso por meio de políticas de acesso a dados, que se aplicam a coleções e recursos de índice. Ao usar esse padrão, verifique se o aplicativo propaga a identidade do usuário para a base de conhecimento e se a base de conhecimento impõe seus controles de acesso baseados em funções ou atributos. Isso é obtido configurando a função de serviço da Base de Conhecimento com o princípio de privilégio mínimo e controlando rigorosamente o acesso à função.
OpenSearch O Serverless oferece suporte à criptografia do lado do servidor AWS KMS para proteger os dados em repouso. Use uma chave gerenciada pelo cliente para criptografar esses dados. Para permitir a criação de uma AWS KMS chave para armazenamento transitório de dados no processo de ingestão de sua fonte de dados, anexe uma política às suas bases de conhecimento para a função de serviço Amazon Bedrock.
O acesso privado pode ser aplicado a um ou a ambos os seguintes: VPC endpoints OpenSearch gerenciados sem servidor e serviços compatíveis, AWS como o Amazon Bedrock. Use AWS PrivateLinkpara criar uma conexão privada entre seus serviços de endpoint OpenSearch sem servidor VPC e. Use regras de política de rede para especificar o acesso ao Amazon Bedrock.
Monitore OpenSearch sem servidor usando a Amazon CloudWatch, que coleta dados brutos e os processa em métricas legíveis, quase em tempo real. OpenSearch O Serverless é integrado ao AWS CloudTrail, que captura API chamadas para o OpenSearch Serverless como eventos. OpenSearch O serviço se integra EventBridge à Amazon para notificá-lo sobre determinados eventos que afetam seus domínios. Auditores terceirizados podem avaliar a segurança e a conformidade do OpenSearch Serverless como parte de vários AWS programas de conformidade.
Amazon S3
Armazene suas fontes de dados para sua base de conhecimento em um bucket S3. Se você criptografou suas fontes de dados no Amazon S3 usando uma AWS KMS chave personalizada (recomendada), anexe uma política à sua função de serviço da base de conhecimento. Use a proteção contra malware no Amazon S3
Amazon Comprehend
O Amazon Comprehend usa processamento de linguagem natural NLP () para extrair insights do conteúdo dos documentos. Você pode usar o Amazon Comprehend para detectar e PII redigir entidades em documentos de texto em inglês ou espanhol. Integre o Amazon Comprehend ao seu pipeline de ingestão de dados
O Amazon S3 permite que você criptografe seus documentos de entrada ao criar uma análise de texto, modelagem de tópicos ou trabalho personalizado do Amazon Comprehend. O Amazon Comprehend se integra para criptografar AWS KMS os dados no volume de armazenamento das tarefas Start* e Create* e criptografa os resultados de saída das tarefas Start* usando uma chave gerenciada pelo cliente. Recomendamos que você use as chaves de contexto de condição SourceAccount global aws: SourceArn e aws: nas políticas de recursos para limitar as permissões que o Amazon Comprehend concede a outro serviço ao recurso. Use AWS PrivateLinkpara criar uma conexão privada entre seus serviços de VPC endpoint e o Amazon Comprehend. Implemente políticas baseadas em identidade para o Amazon Comprehend com o princípio do menor privilégio. O Amazon Comprehend é integrado ao, que API captura AWS CloudTrailchamadas para o Amazon Comprehend como eventos. Auditores terceirizados podem avaliar a segurança e a conformidade do Amazon Comprehend como parte AWS de vários programas de conformidade.
Amazon Macie
O Macie pode ajudar a identificar dados confidenciais em suas bases de conhecimento que são armazenados como fontes de dados, registros de invocação de modelos e armazenamento imediato em buckets do S3. Para conhecer as melhores práticas de segurança do Macie, consulte a seção Macie anterior neste guia.
AWS KMS
Use chaves gerenciadas pelo cliente para criptografar o seguinte: trabalhos de ingestão de dados para sua base de conhecimento, o banco de dados vetorial do Amazon OpenSearch Service, sessões nas quais você gera respostas a partir da consulta de uma base de conhecimento, registros de invocação de modelos no Amazon S3 e o bucket do S3 que hospeda as fontes de dados.
Use a Amazon CloudWatch e a Amazon CloudTrail conforme explicado na seção anterior de inferência do modelo.
